
目次
Introduction
Databricks と dbt core を使用して、簡易的なデータモデリングを行う内容となります。dbt core の導入に重点を置き、Databricks ワークスペースは事前に準備した状態から開始手順を記載していきます。
なお、本稿は Databricks dbt プロジェクトと Unity Catalog のベストプラクティスとして記載されている内容とは異なり、dbt Cloud の使用は行っておりません。あくまで個人検証として記したものである点をご理解いただければと存じます。
What dbt Core ?
dbt core とは、 SQL でデータ変換やモデリングが行えるオープンソースリポジトリです。多様な機能を用いて、ローカル開発環境上からデータウェアハウスに対して、操作する事が出来ます。

dbt は ELT プロセスにおける Transform として機能します。
BI による分析、レポーティングは、日々業務の中で、データアナリストが可変性の高いなデータを分析します。dbt core は、格納されたデータベース、データマートに対してコードベースに処理を行う事を可能にします。
dbtでは、SQL で書かれたデータの抽出を行い、レポートのソースとなるデータ作成します。これを「model」と呼んでいます。モデルに書かれたクエリは dbt 処理によりデータの抽出、変換、作成やアップデートが実行されます。
なお、dbt のmodel における ベストプラクティス は、ダウンストリームモデルが基本です。Staging 、Intermediate、Marts ディレクトリ等に区分けをして、モデルとなる sql を順次作っていく方式となります。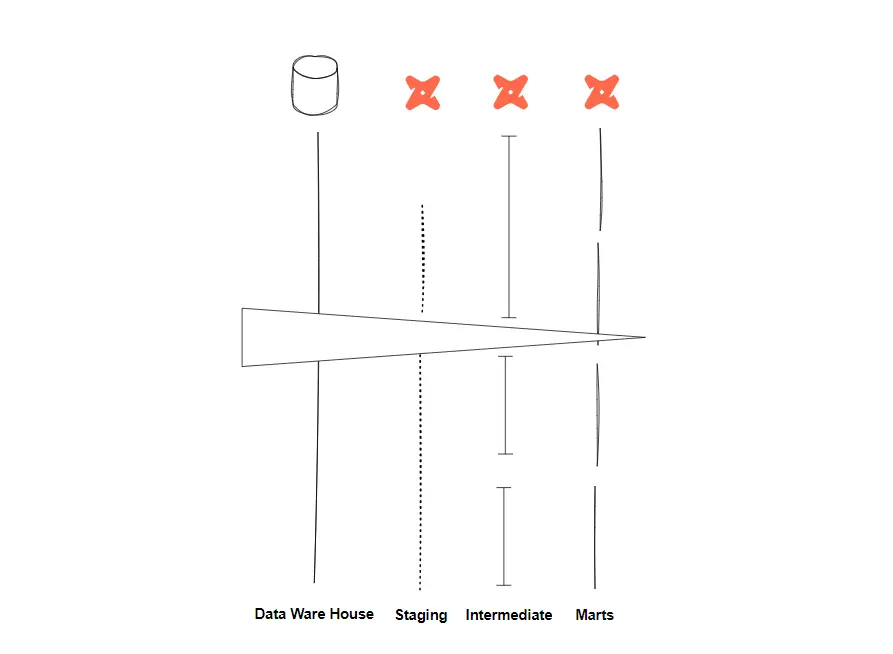
今回は、この「model」を簡易的に作成する事を目的としているため、1つだけ作成をするものとします。
Let's Try
Preset
今回は、Databricks 向けに以下の環境を使用していますが、dbt core がサポートしているプラットフォーム、ローカル環境があれば、特に dbt core を使用するにあたる制限はありません。なお、Git 環境での作業は、必要に応じてとなります。本稿では最後に少しだけ使用しています。
Databricks on AWS / WSL for ubuntu / Azure DevOps
Install dbt Core and dbt init
bash ターミナルから作業を行っていきます。install には pip を使用して実施します。完了したら、PATH が通っているか確認した後、 --version コマンドが結果が返ってきたら問題ありません。
dbt core には databricks アダプタ が存在します。今回はこれを使用して、Databricks への接続を実施しますので、上記 dbt core とは別途インストールを実行します。
インストール後に、再度 dbt --version を実行し、 plugin へ spark と databricks のバージョンが表示されれば、問題なくインストールが完了しています。なお、インストール済の Plugin があれば、それらも表示されます。
$ pip install dbt-core
$ dbt --version
Core:
- installed: 1.7.4
- latest: 1.7.4 - Up to date!
$ pip install dbt-databricks
$ dbt --version
Core:
- installed: 1.7.4
- latest: 1.7.4 - Up to date!
Plugins:
- spark: 1.7.1 - Up to date!
- databricks: 1.7.3 - Up to date!
- synapse: 1.3.2
- postgres: 1.5.0
- sqlserver: 1.3.2
任意のディレクトリを作成し、そのディレクト上から dbt init を実行します。dbt init は初期化するコマンドであり、後続に入れる名前 <project-name> がプロジェクト名にあたりますので任意で問題ありません。
$ dbt init <project-name>dbt init コマンドの実行後は対話式の入力を行う必要があります。plugin に沿って入力する項目が異なるため、以下に databricks を選択した場合の対話情報を記載致します。
$ dbt init dbt_databricks
Running with dbt=1.7.4
Your new dbt project "dbt_databricks" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profile
One more thing: Need help?
Don't hesitate to reach out to us via GitHub issues or on Slack:
https://community.getdbt.com/
Happy modeling!
利用するデータベースを選択します。選択肢はインストール済みのプラグインです。
ここでは、databricks となる 2 を入力します。 databricks のプラグインをインストールすると、spark パッケージも不随してきますが、databricks パッケージは、Databricks 用に最適化された spark のフォークのため、databricks を利用する事が勧められているようです。
Setting up your profile. Which database would you like to use?
[1] spark
[2] databricks
[3] synapse
[4] postgres
[5] sqlserver
> Enter a number: 2
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)続いて、host および http_path を入力します。これらは、Databricks ワークスペース上から確認ができます。今回は SQL ウェアハウスを使用しますので、SQL ウェアハウスの接続の詳細 から情報を確認します。
host (yourorg.databricks.com): xxxx
http_path (HTTP Path): /sql/1.0/warehouses/xxxxxxxx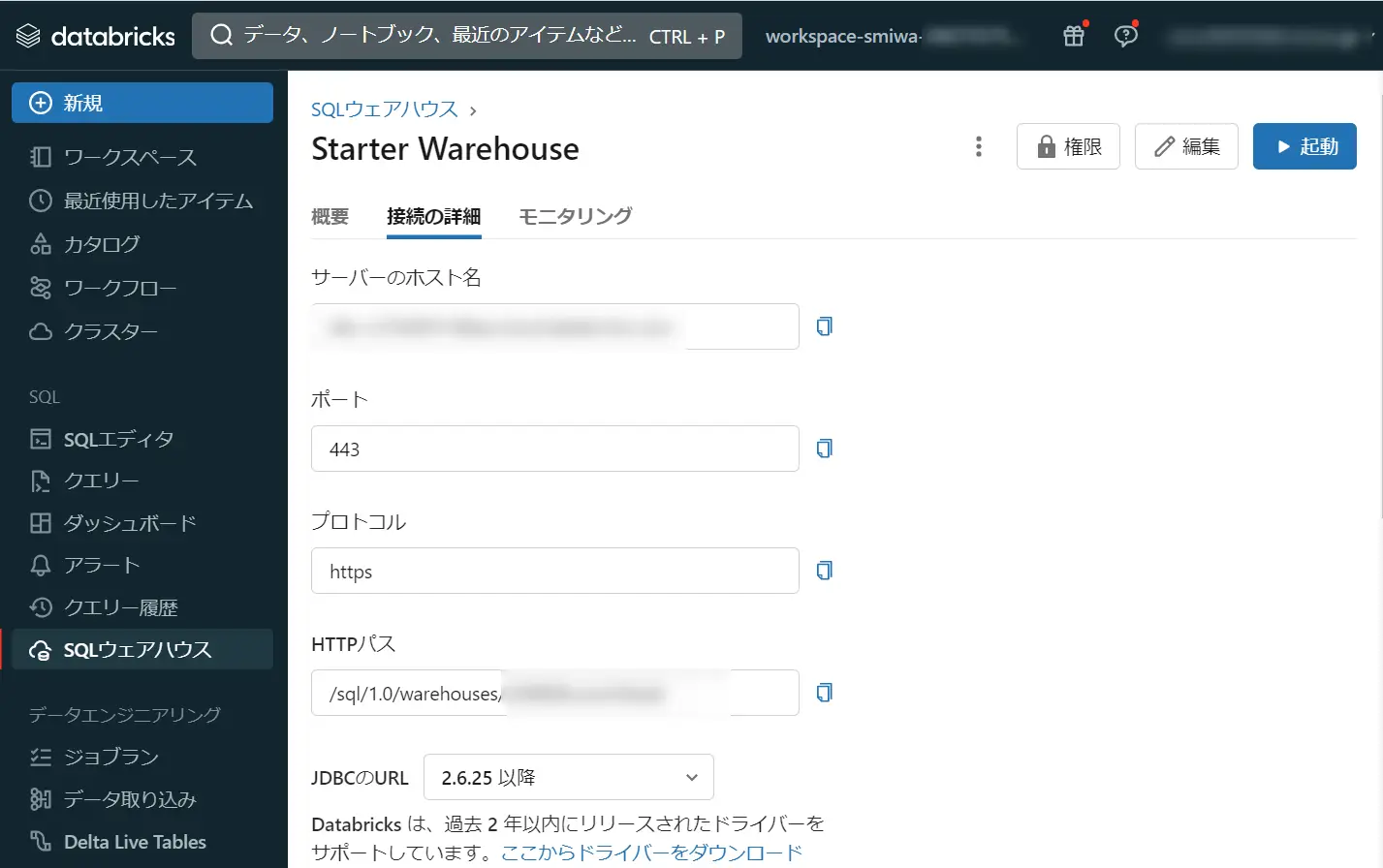
その後、Unity Catalog の利用可否を入力する事になります。今回は Unity Catalog 上のマネージドテーブルを使用しますので、1 を入力します。
Desired access token option (enter a number):
[1] use Unity Catalog
[2] not use Unity Catalog
> Desired unity catalog option (enter a number): 1
最後に、対象の catalog 名 、schema 名、dbt が利用するスレッド数(デフォルトは1) を入力し、 init のコマンド結果が返ります。
catalog (initial catalog): main
schema (default schema that dbt will build objects in): default
threads (1 or more) [1]: 1dbt connection databricks
dbt init が完了したら、プロジェクトディレクトリが作成されます。各ディレクトリ毎に役割がありますが、今回は models のみ使用します。
$ tree
.
├── README.md
├── analyses
├── dbt_packages
├── dbt_project.yml
├── logs
│ └── dbt.log
├── macros
├── models
│ └── example
│ ├── schema.yml
│ └── xxxx.sql
│ └── xxxx.sql
├── seeds
├── snapshots
├── target
│ ├── compiled
│ │ └── dbtdatabricks
│ │ └── models
│ │ └── example
│ │ └── xxxx.sql
│ ├── graph.gpickle
│ ├── graph_summary.json
│ ├── manifest.json
│ ├── partial_parse.msgpack
│ ├── run
│ │ └── dbtdatabricks
│ │ └── models
│ │ └── example
│ │ └── xxxx.sql
│ ├── run_results.json
│ └── semantic_manifest.json
└── tests
先述の dbt init の対話で入力した値は、profiles.yml へ書き込みを行います。また、これらは、 ~/.dbt 配下にありますので、先述の dbt_profile.yml とは異なります。
$ cat ~/.dbt/profiles.yml
your_profile_name:
outputs:
dev:
type: databricks
catalog: main
schema: [schema name]
host: [xxx.databrickshost.com]
http_path: [/sql/your/http/path]
token: [dapiXXXXXXXXXXXXXXXXXXXXXXX]
threads: [1 or more]
target: dev
Databricks 上から個人用アクセストークン認証を使用する場合は、サービスプリンシパルに所属する、個人用アクセストークンの作成が推奨されています。これを取得して、Token_value の値を 上記 token へ入力します。
その後、dbt debug コマンドを使用して、接続確認を実施します。ここでは、いくつか出力結果が表示されますが、最後 Connection test: [OK connection ok] が表示されれば、無事接続が完了しています。
$ dbt debug
Running with dbt=1.7.4
dbt version: 1.7.4
python version: 3.9.16
python path: /root/micromamba/bin/python
os info: Linux-5.10.16.3-microsoft-standard-WSL2-x86_64-with-glibc2.35
Using profiles dir at /root/.dbt
Using profiles.yml file at /root/.dbt/profiles.yml
Using dbt_project.yml file at /dbt_databricks/dbt_project.yml
adapter type: databricks
adapter version: 1.7.3
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
host: xxxx.databricks.com
http_path: /sql/1.0/warehouses/xxx
catalog: main
schema: default
Registered adapter: databricks=1.7.3
Connection test: [OK connection ok]
All checks passed!
Create models and run
接続が完了したら、models の作成に入ります。models のディレクトリ内に <任意のモデル名> .sql ファイルを作成します。これがモデルにあたります。
dbt における model の実行により作成されるオブジェクトは、 Materializations によって決まります。具体的には、Table / VIEW / Incremental / ephemeral / materialized view で、デフォルトは VIEW となります。先述のベストプラクティスでは、レイヤ毎に推奨される Materializations は決まっていますが、今回は、Table を作成します。
作成した sql ファイルの例です。
{{ config( materialized='table', file_format='delta') }}
select * from sample_table;
モデルの構成には、いくつかのパターンがあり、このうち、マクロ を .sql に直に設定する事により、単一のモデル毎の構成が可能となります。また、上記 materialized に設定された内容は、作成するオブジェクトの種別で、Table を指定します。そして、ファイルフォーマットを delta で指定します。
dbt におけるモデルは select 文で宣言されます。後述の dbt run コマンドにより、この例では、 sample_table の全ての内容を元に <任意のモデル名> のtable が作成される事になります。
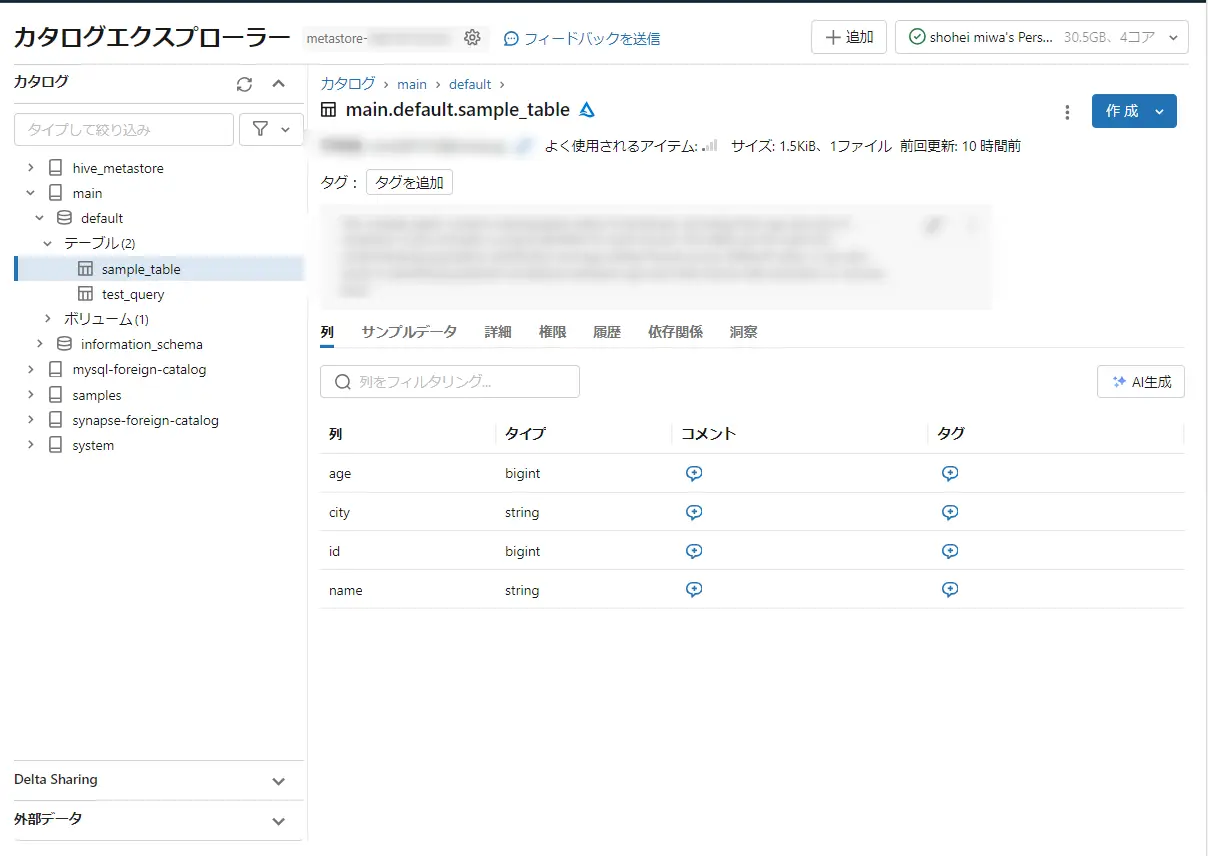
そして、sample_table とは、Databricks の Unity Catalog に作成されているテーブル名です。
では、sql ファイルの保存が終わると、dbt run コマンドを実行します。dbt run コマンドを実行する前に、dbt_profile.yml 上に定義された models 内の構成情報をコメントアウトします。
# models:
# dbt_databricks:
# Config indicated by + and applies to all files under models/example/
# example:
# +materialized: view
dbt init で初期化した際に、複数の sql ファイルが生成されているため、 dbt run で実行するファイルを指定します。実行後に出力結果の最後に Completed successfully と出力されると成功です。
$ dbt run --model models/example/sample_table_2.sql
.
.
1 of 1 START sql table model default.sample_table_2 ............................ [RUN]
1 of 1 OK created sql table model default.sample_table_2 ....................... [OK in 48.77s]
Finished running 1 table model in 0 hours 0 minutes and 55.25 seconds (55.25s).
Completed successfully
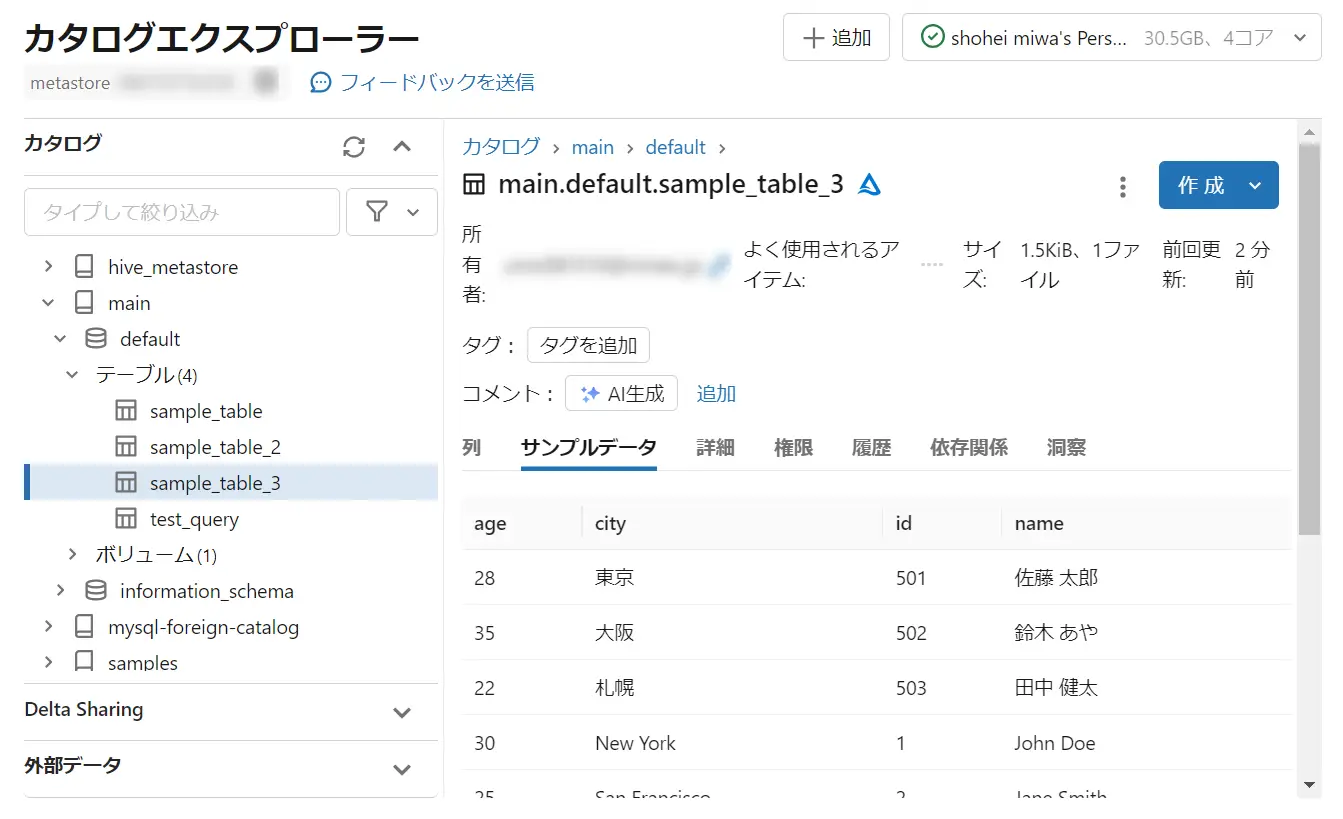
Databricks のカタログエクスプローラーから確認してみると、sample_table_2 の実テーブルが作成されている事が分かります。今回の .sql ファイルでは、条件指定をしていないので、今回はsample_table の copyに近しい結果となりました。
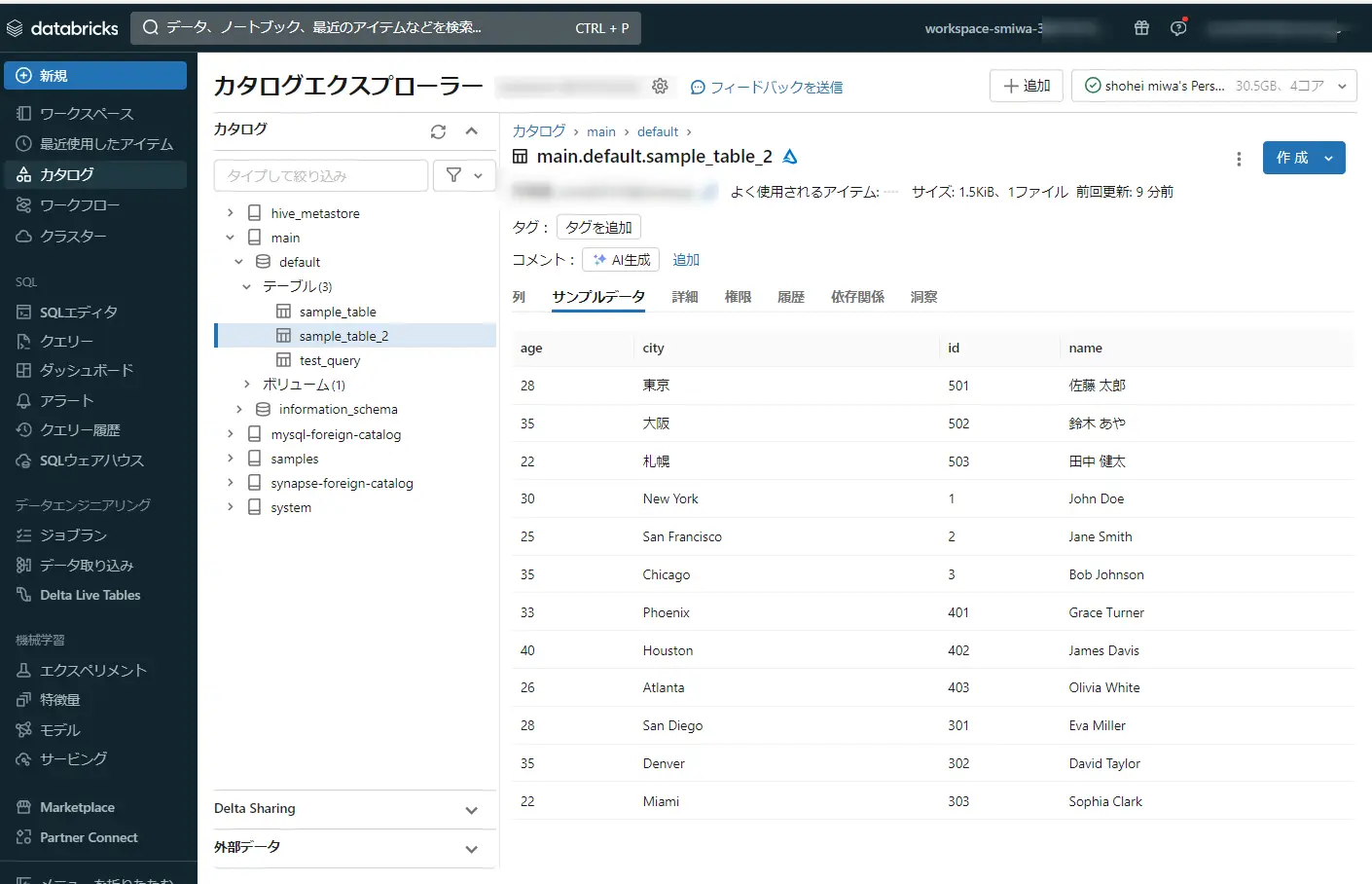
モデルの作成作業は以上となります。
dbt core integration Databricks job
Databricks におけるジョブは、 dbt core プロジェクトを選択する事が可能で、git リポジトリ上のファイルに対して、指定された dbtタスクを実行出来ます。
これを行う場合、Databricks ワークスペースが git 連携している必要があります、今回は連携先に Azure DevOps を指定しています。
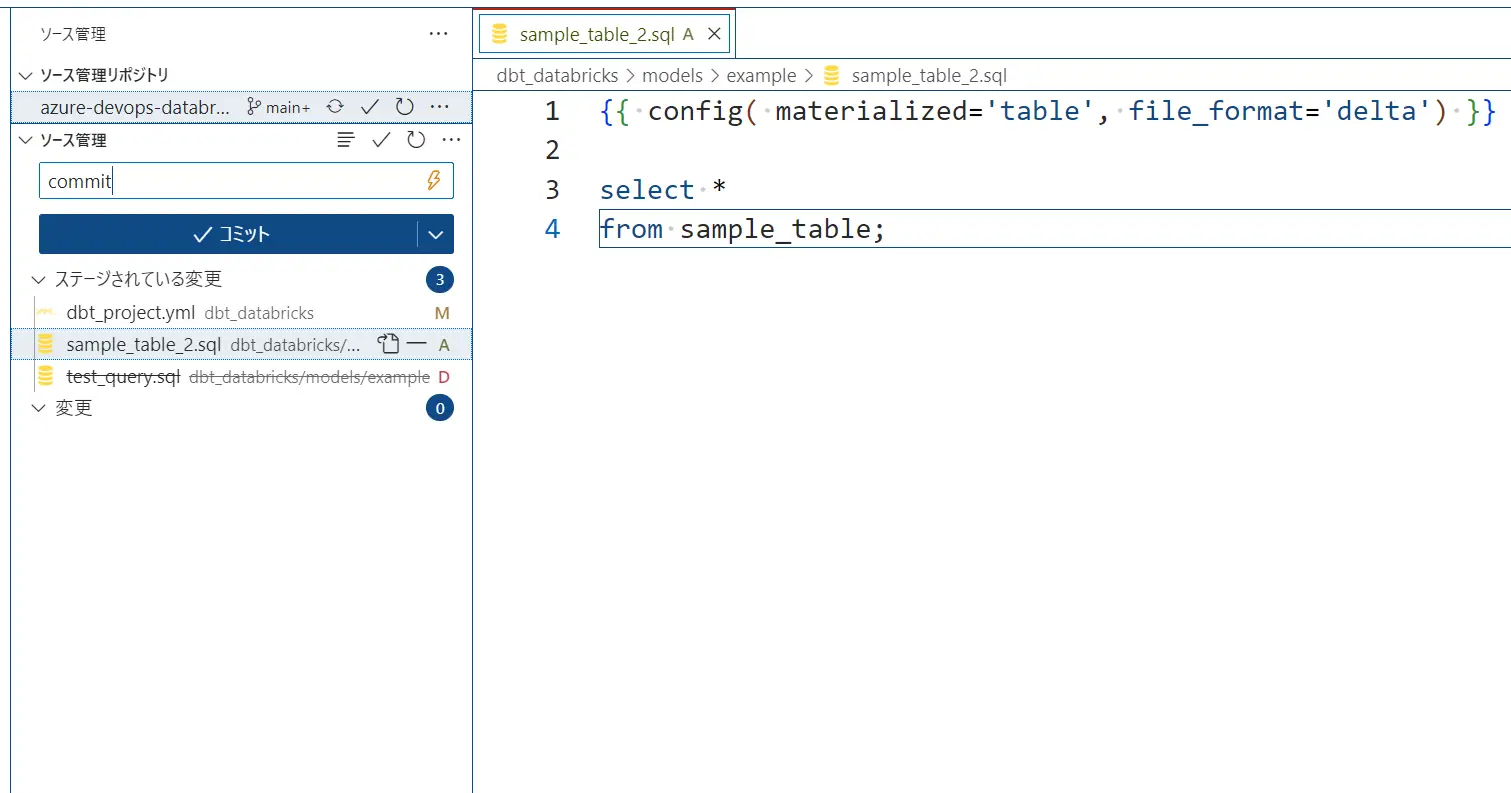
先ほどの、プロジェクトディレクトリを git リポジトリとして登録し、ローカルから一度プッシュします。
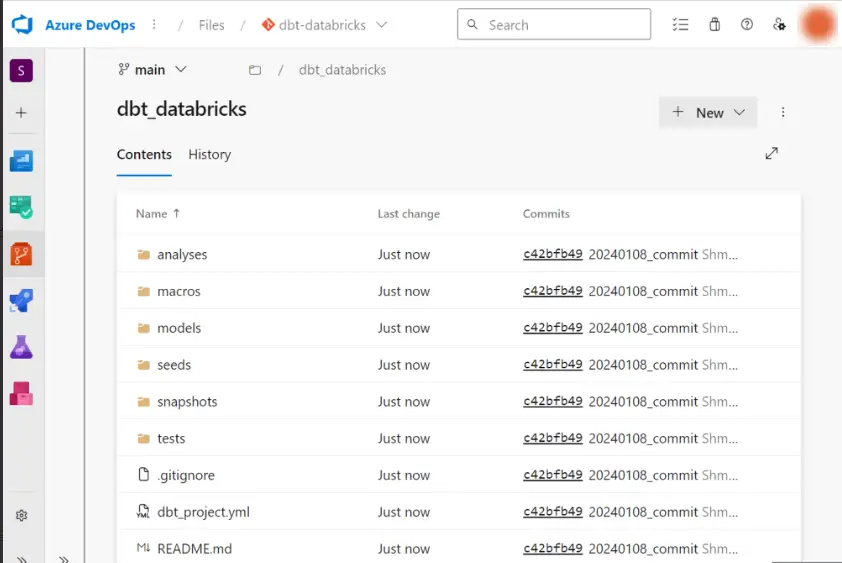
ここから、Databricks ワークスペース上で作業を行いますが、単純な設定要件であれば非常にシンプルです。新規でジョブを作成し、タスクの設定上の種類にて dbt を選択します。あとは、git 連携したプロバイダや、プロジェクトディレクトリ、ジョブを介して実行したい dbt コマンド等をここで設定して作成します。今回確認すべきなのは、dbt run が含まれている事です。
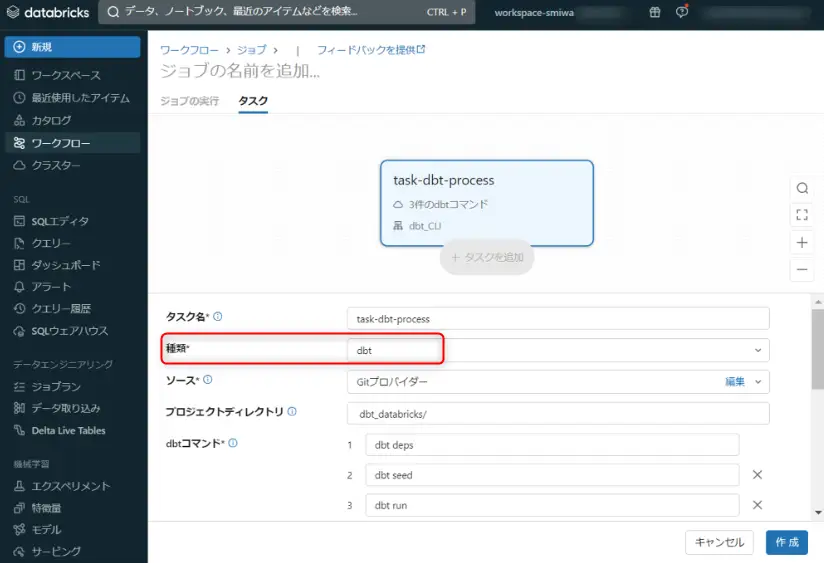
では、最後に、ローカルから新規作成した sample_table_3.sql を作成して、dbt run をせずにローカルから Azure DevOps へプッシュします。そして、databricks CLI から Databricks のジョブを即時実行します。
databricks jobs run-now <job-id>
ジョブの成功と、テーブルの作成が確認できました。
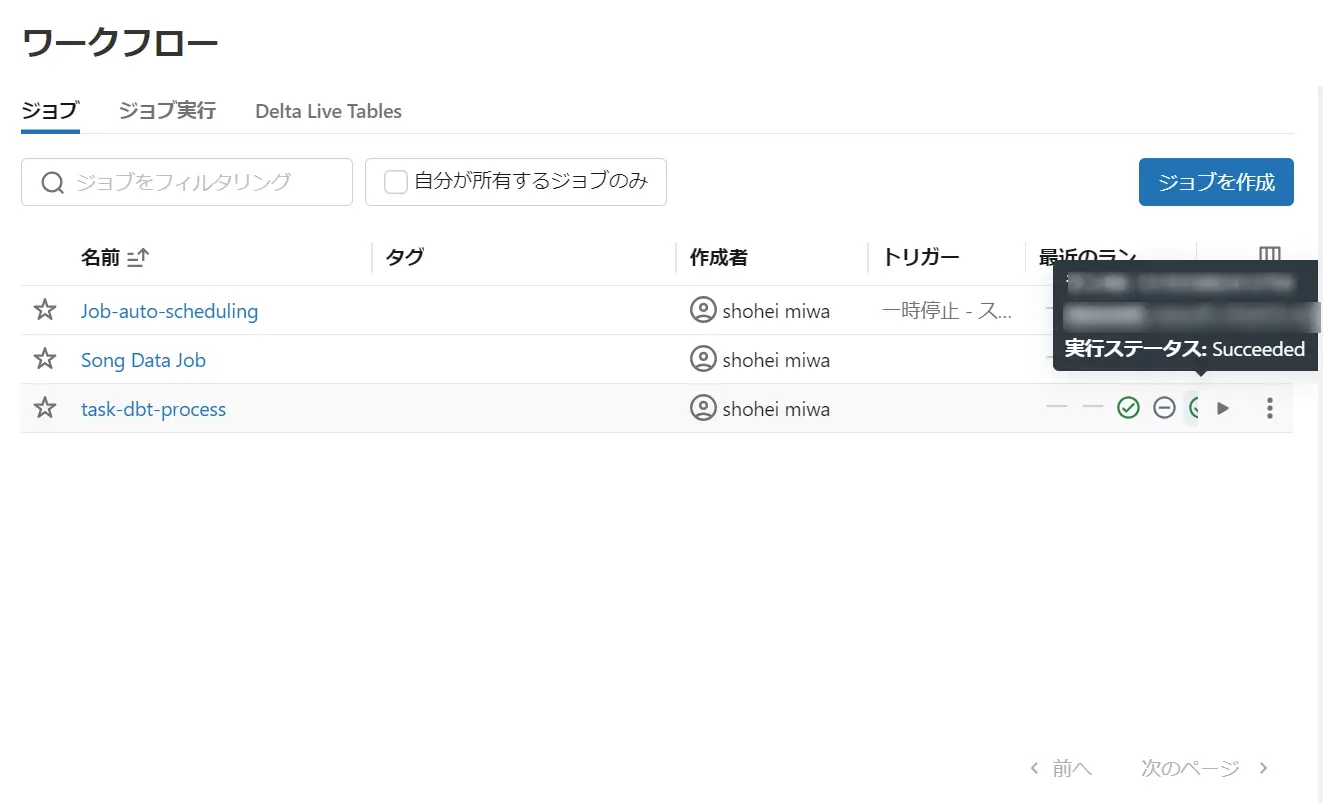
dbt のジョブ実行はローカル上で開発を行った後に考慮する必要があるステップの1つかと思います。例えば、Github Actions や Azure DevOps パイプラインなどで実行するケースも考えられるかと思います。その上で、Databricks と dbt のジョブ統合は、便利なユースケースを考えられるかもしれません。
以上となります。
本稿は検証手順となりますので、公式ドキュメントを改めてご確認の上、実装をお願いいたします。
最後まで御覧いただきましてありがとうございました。

この記事をシェアする



