












目次
Target
Data Factory に関する投稿となります。
Azure Data Factory は、サーバーレスで豊富なコネクタを揃えた Azure のフルマネージドサービスとなります。また、昨年の Ignite で発表のあった Microsoft Fabric の一般提供により、Data Factory の利用が可能となりました。
本稿は、Azure Data Factory および Data Factory in Microsoft Fabric の機能と設計要素を自己研鑽、調査検証を背景に執筆を致しました。
製品導入をご検討中の方、また Data Factory 設計者向けの記事となりますので、少しでもご参考に頂けると幸いです。
Introduction
本稿では、下記の順序に沿って記載を致します。
- Azure Data Factory のインフラストラクチャについて記載をしました。ここではData Factory の位置付けと共に、統合ランタイム、ネットワーク、リソースの作成プロセスとデプロイについて記載をしています。
- Azure Data Factory のコネクターについて記載を致しました。また、Fabric Data Factory のコネクタとの違いについても調査内容を記載しています。
- Azure Data Factory のオブジェクトとその関連性について記載をしています。
- データフローについて言及しています。ここでは各処理の設定項目を CDC、式ビルダ―、デバッグなどに触れながら確認していきます。
- パイプラインの詳細設定について触れています。画面から確認を行っていきます。
その他、アーキテクチャ、パラメーター、ガバナンス、監視、Data Factory in Microsoft Fabric の利用、移行モデルや、オープンソースとの統合、Airflow 統合等については次回記載を予定しています。
Infrastracture
Azure Data Factory は、PaaS として機能する Microsoft Azure のフルマネージドサービスとなります。リソースグループの中に、一意なインスタンスとしてリソースを保持、管理します。2018 年以降バージョン V2 が存在し、現在では V2 のみ利用がサポートされます。
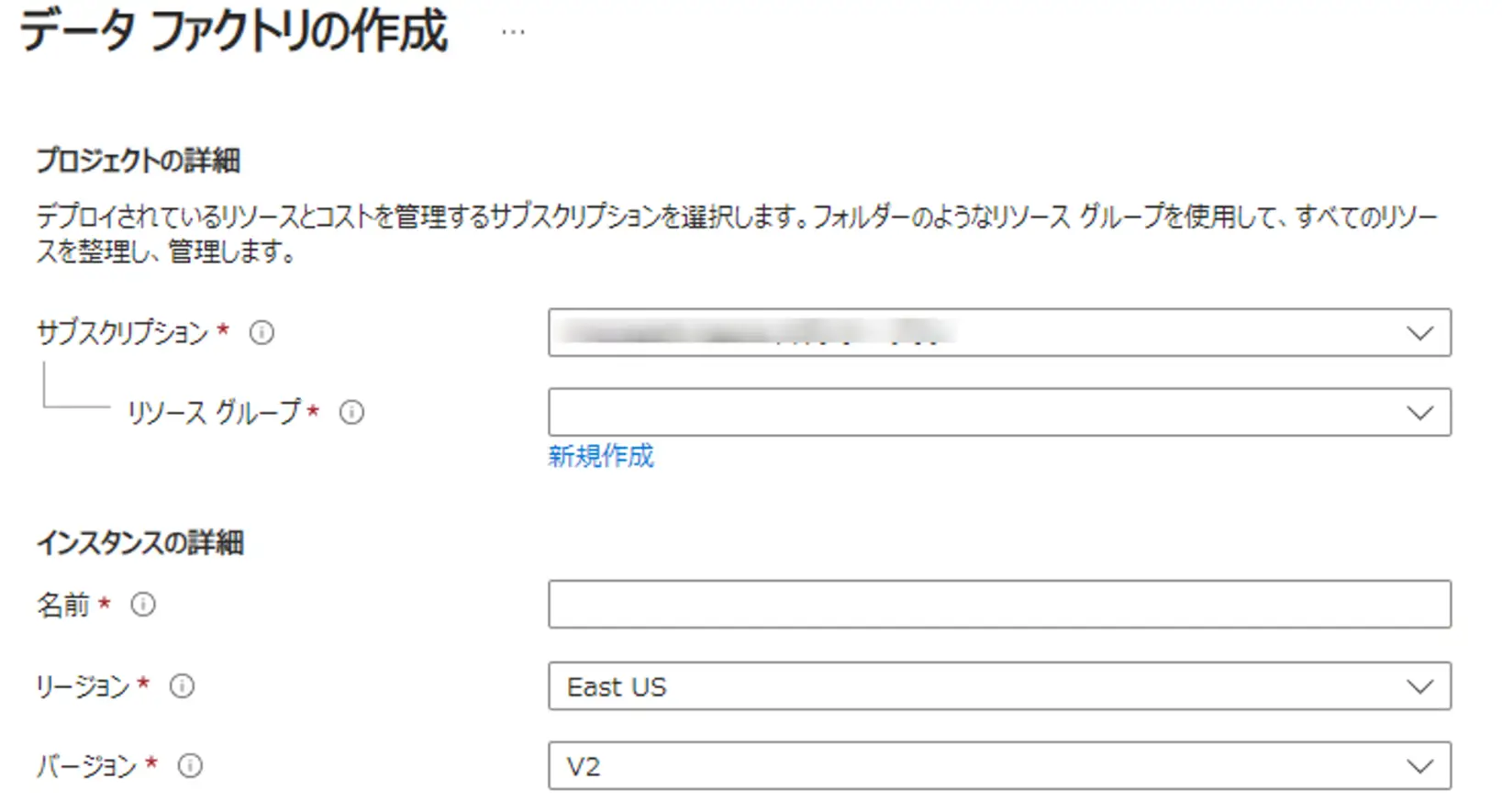
Azure Data Factory は、データアクセスを行い、変換、加工、集計等の処理を経て、データ転送を行うサービスです。このため、データアクセスでは、いくつかのオプションを元に、接続を行う必要があります。ここからネットワークについて理解すべく、データアクセスについて触れていきます。
Integration Runtimes
データアクセスに触れるために統合ランタイムについて記載をします。
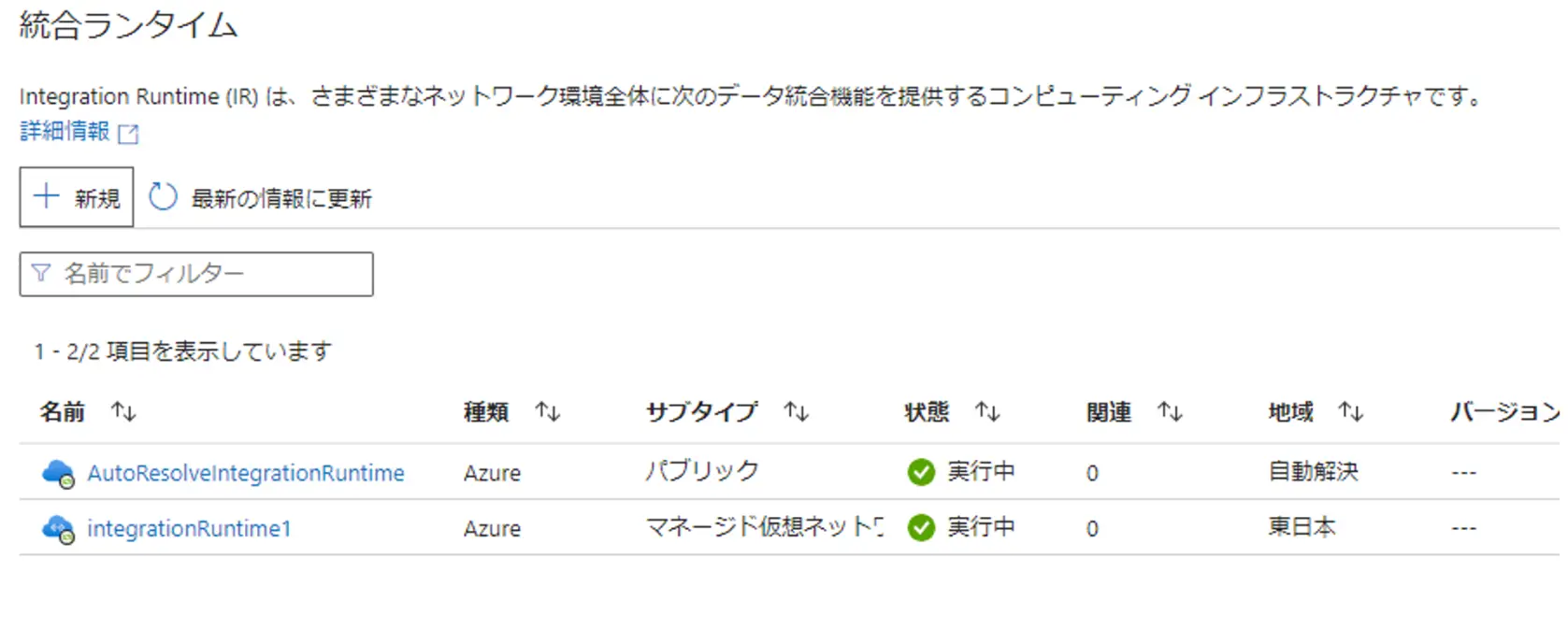
Azure Data Factory には、いくつかの統合ランタイムが存在します。これらは、後述のマネージドネットワークやコネクタ、リンクドサービスと関与し、適切な採択が必要な部分です。
- Azure Integration Runtime (Azure IR / AutoResolveIntegrationRuntime)
- Azure-SSIS
- Self Hosted Integration Runtime(SHIR)
- Linked Self-Hosted Integration Runtime
統合ランタイムは、データアクセスを行う対象のリソースへアクセスするためのコンピューティングです。言い換えると Data Factory 自らがデータストアやウェアハウス等に直接的なアクセスを行わない設計になっているかと思います。
Azure Integration Runtime (Azure IR / AutoResolveIntegrationRuntime)
Azure Integration Runtime(Azure IR) は、コンピューティングが Azure 環境に自動でホストされ、Azure の PaaSサービスとの通信を行うために利用されます。サポートされる項目は、URL の Azure IR がサポートにチェックがついている対象となります。
Azure IR が使用する IP は、リージョンによって異なり、後述のDataFlow が使用するサイズを作成時に選択する事が可能です。これは処理のパフォーマンスに関与します。
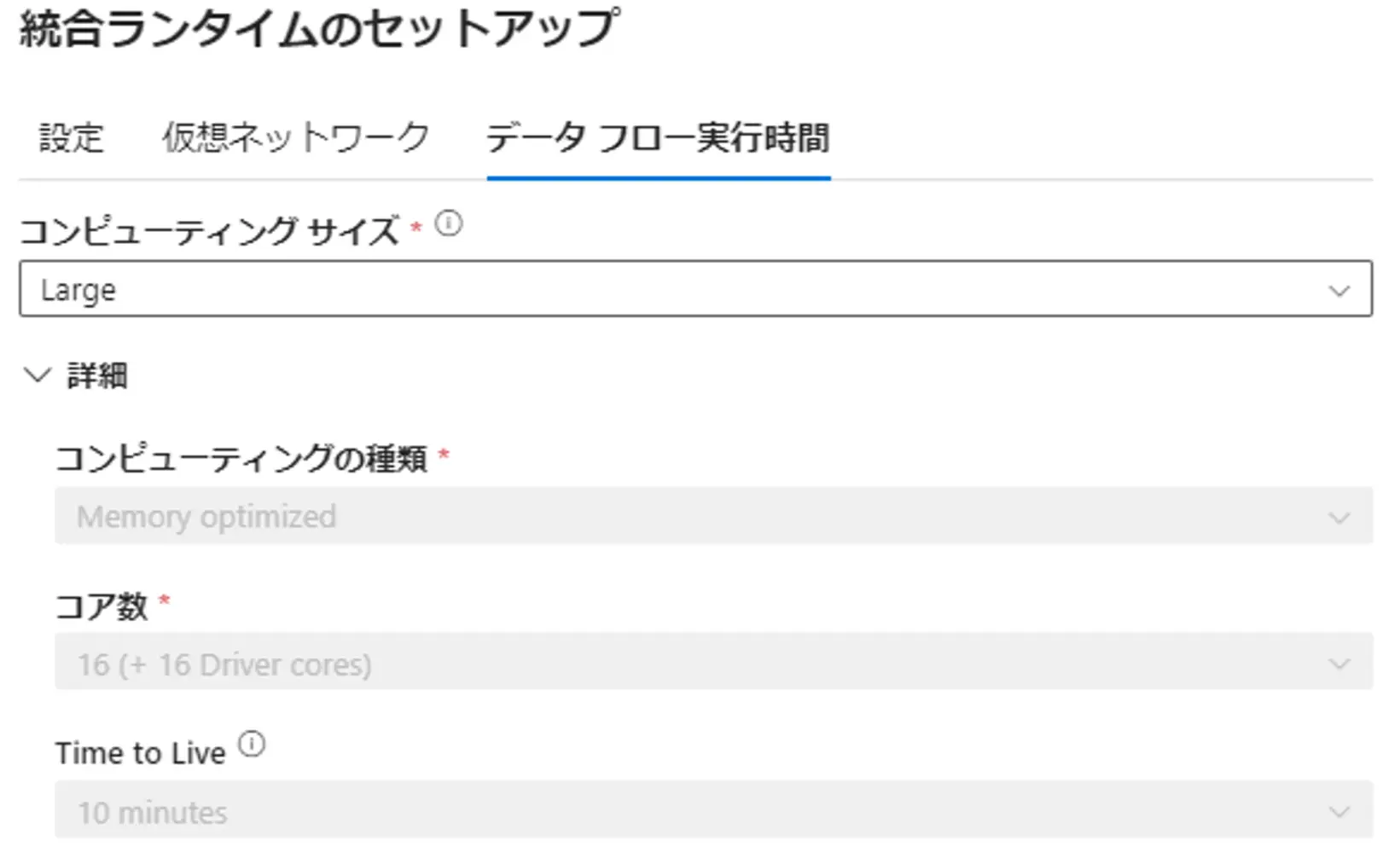
Azure Data Factory のインスタンスの作成時に指定する、 Azure IR(AutoResolveIntegrationRuntime) を有効化すると、Azure IRと同義の統合ランタイムが作成されます。これはリージョンの指定が無い自動解決(ターゲットに近いリージョンを検知)を行う Azure IR となります。
Azure-SSIS IR
Azure-SSIS IRは、Azure SQL Databaseまたは、Azure SQL Managed Instance をホストとして、SSISカタログにデプロイされたパッケージの実行をしたり、ファイルシステムにデプロイされたパッケージを実行出来るランタイムです。これは既存のSSISワークロードがある場合に有効なランタイムです。
パブリックネットワークあるいはプライベートネットワーク内 Azure VM にフルマネージドのクラスターとしてプロビジョングされ、開始停止が柔軟に行えるものです。
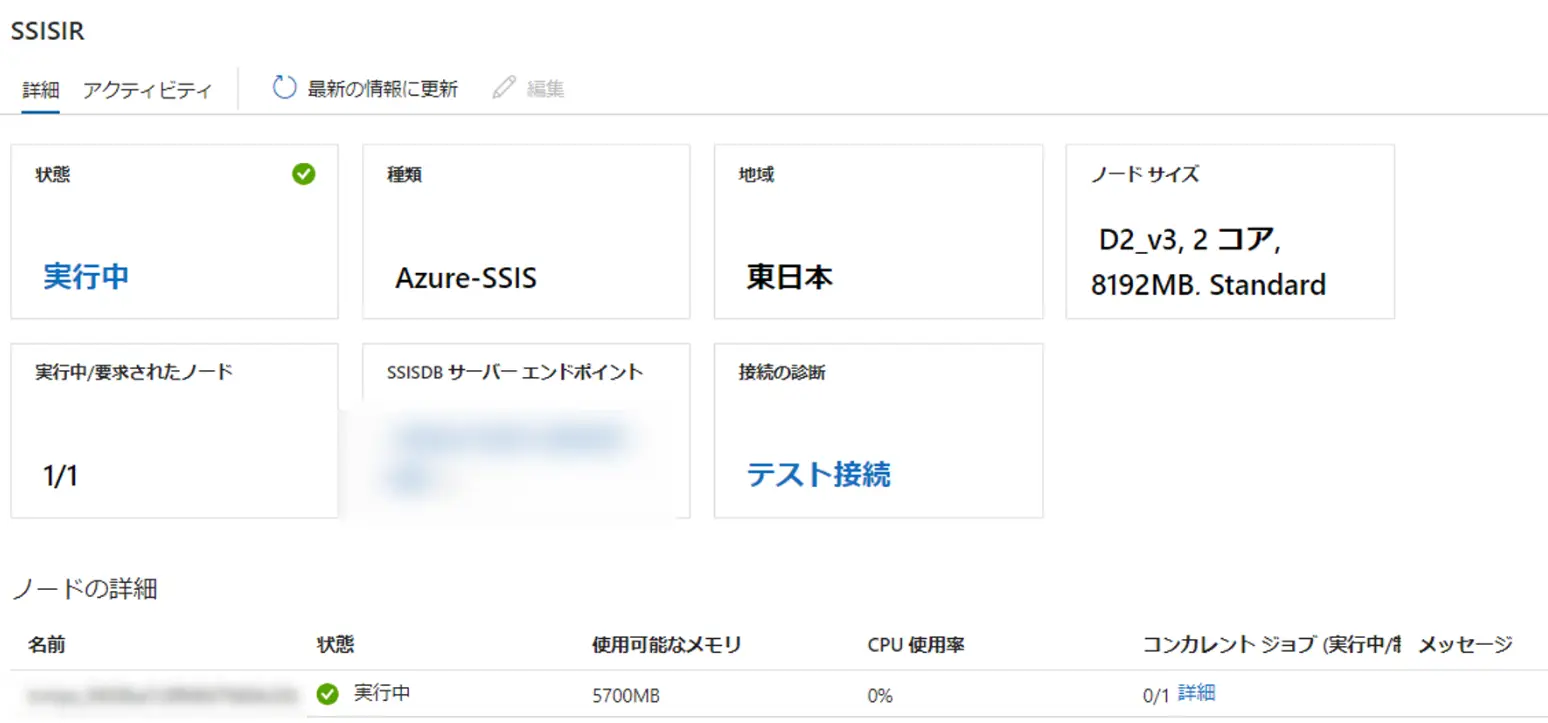
SSISパッケージの実行は、後述のパイプラインから実行が可能で、指定のファイルシステムから、パッケージのデプロイが可能となります。
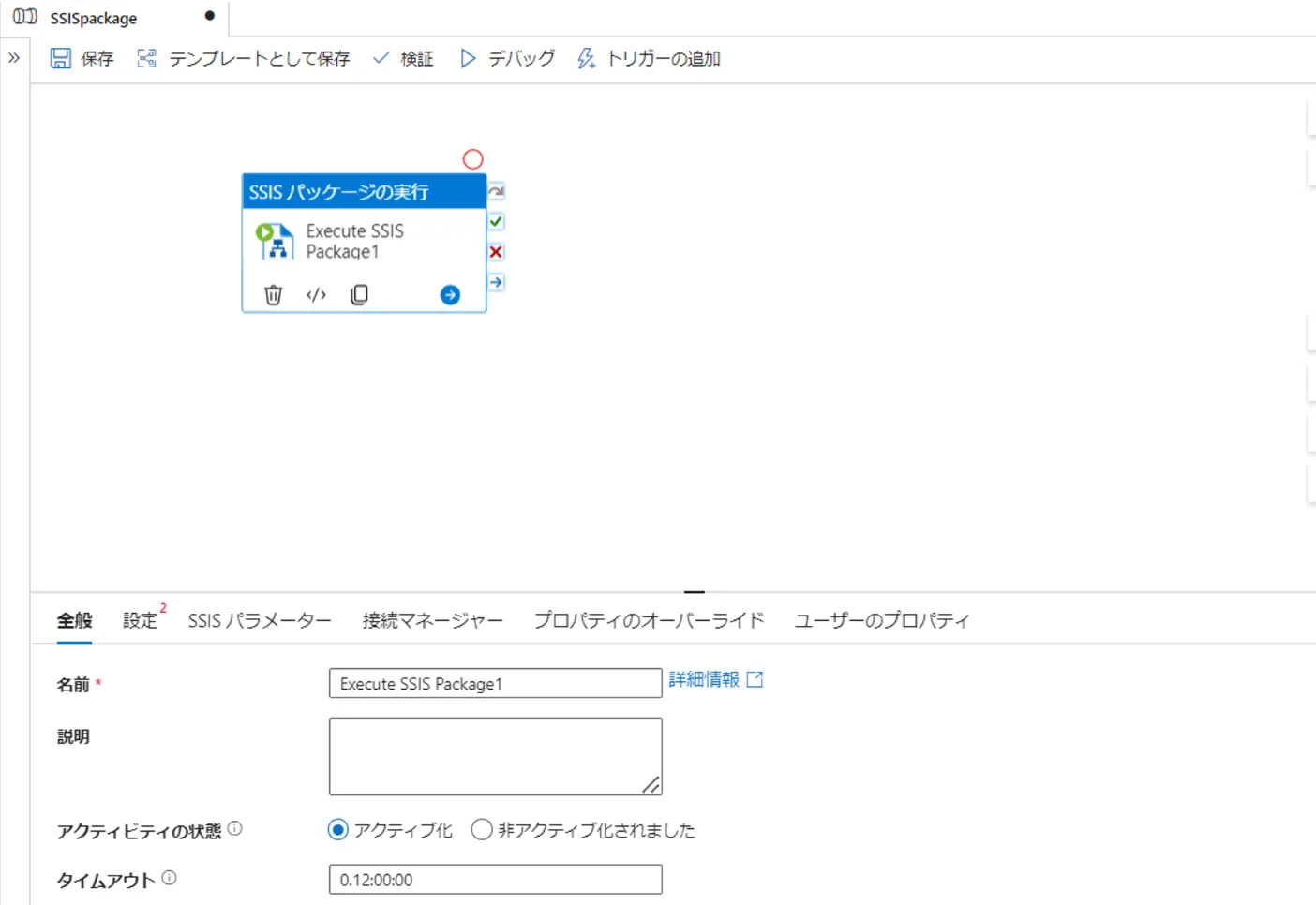
作成手順はこちらとなります。
Self Hosted Integration Runtime(SHIR)
セルフホステッド統合ランタイム(SHIR)とは、自己管理しているオンプレミスサーバーやVM上に、自身でランタイムを導入して、キー認証により Data Factory へ登録する事で機能します。
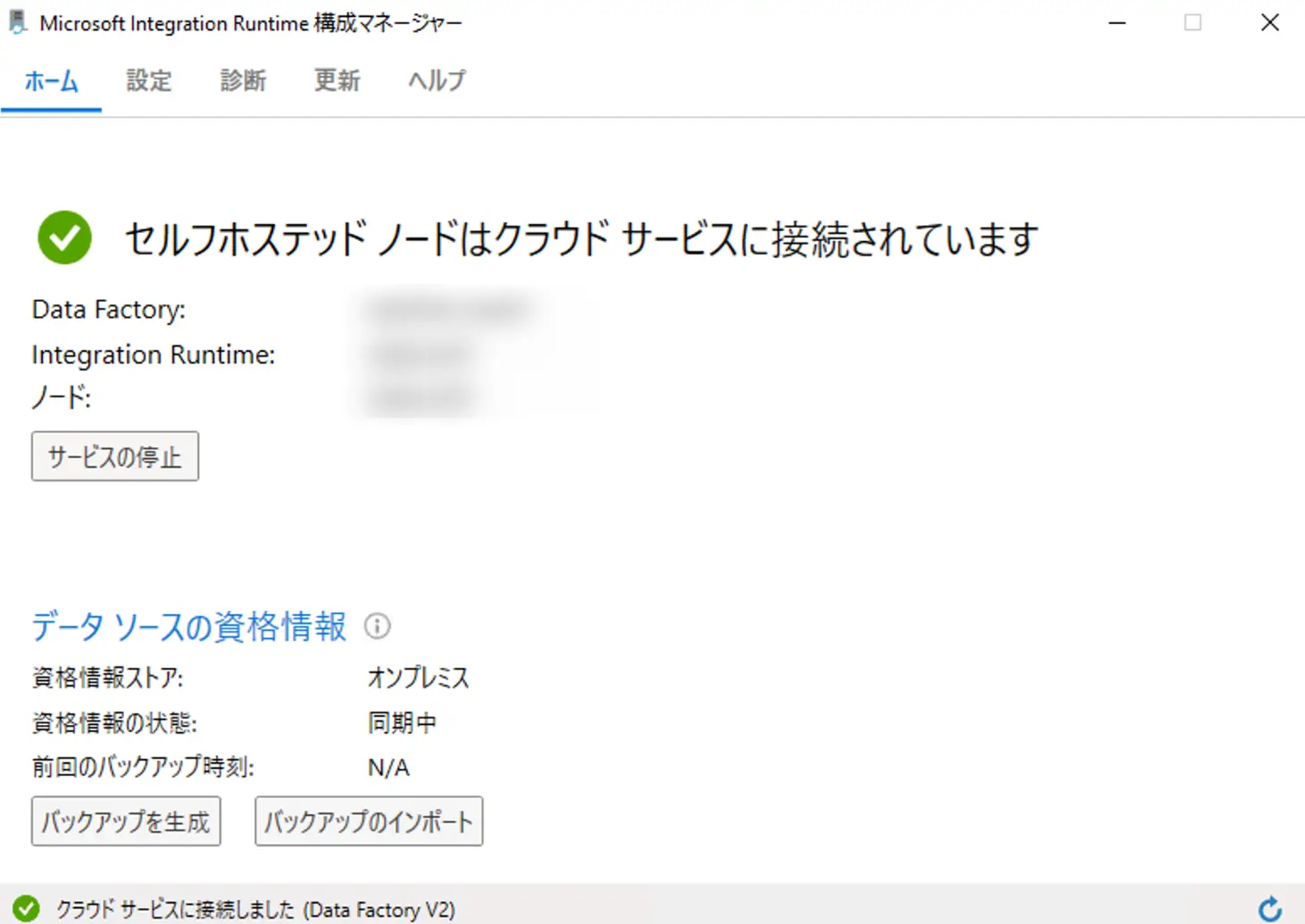
基本的には、直接の通信経路がないプライベート ネットワーク環境で、ファイアウォール内のオンプレミス環境か仮想プライベート ネットワーク内に導入を行い、HTTPベースの送信により接続を確保します。
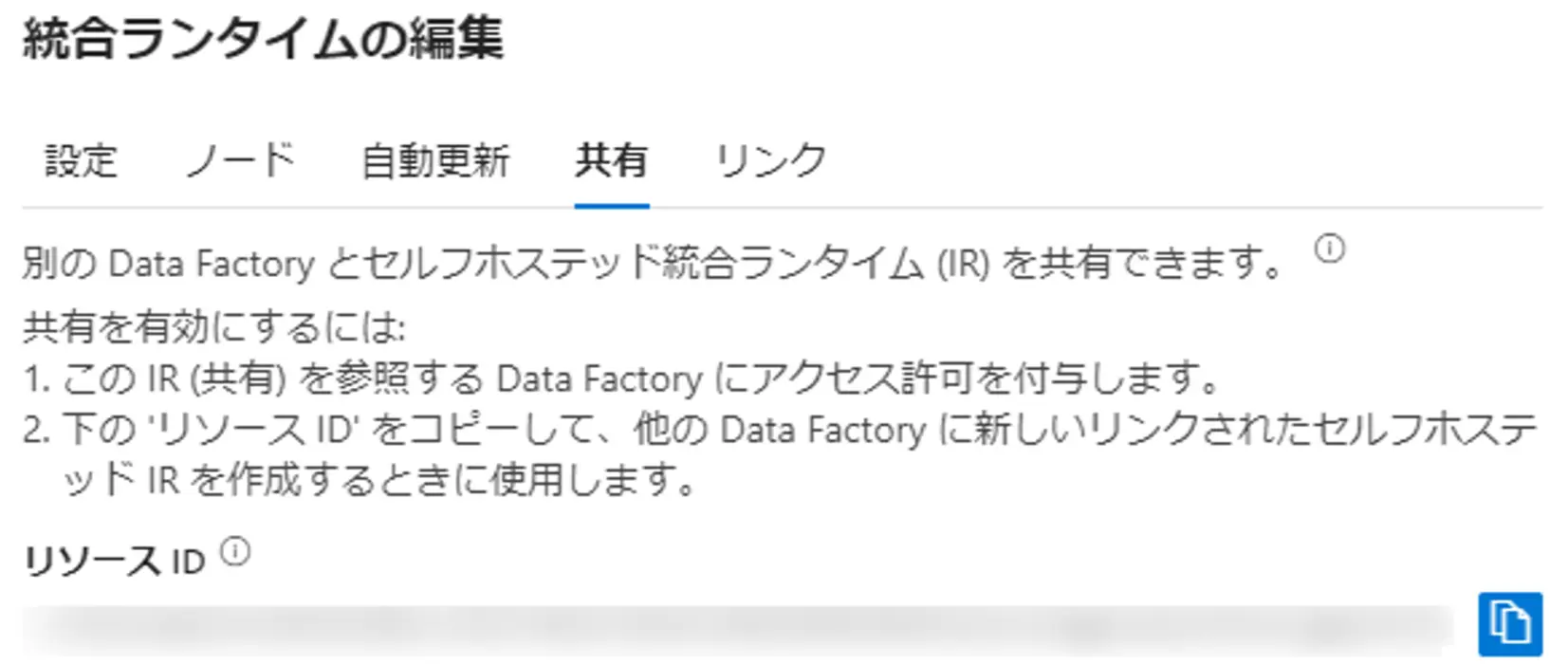
Linked Self-Hosted Integration Runtime
Azure Data Factory はインスタンス毎に統合ランタイムをリソース情報として保有し、管理します。セルフホステッド統合ランタイムが登録された Data Factory インスタンスと共有して別の Data Factory が同じセルフホステッドランタイムを使用する場合、リンクドセルフホステッド統合ランタイムを使用する事が出来ます。共有元のリソースIDを共有先の統合ランタイムに指定する事で利用が可能となります。
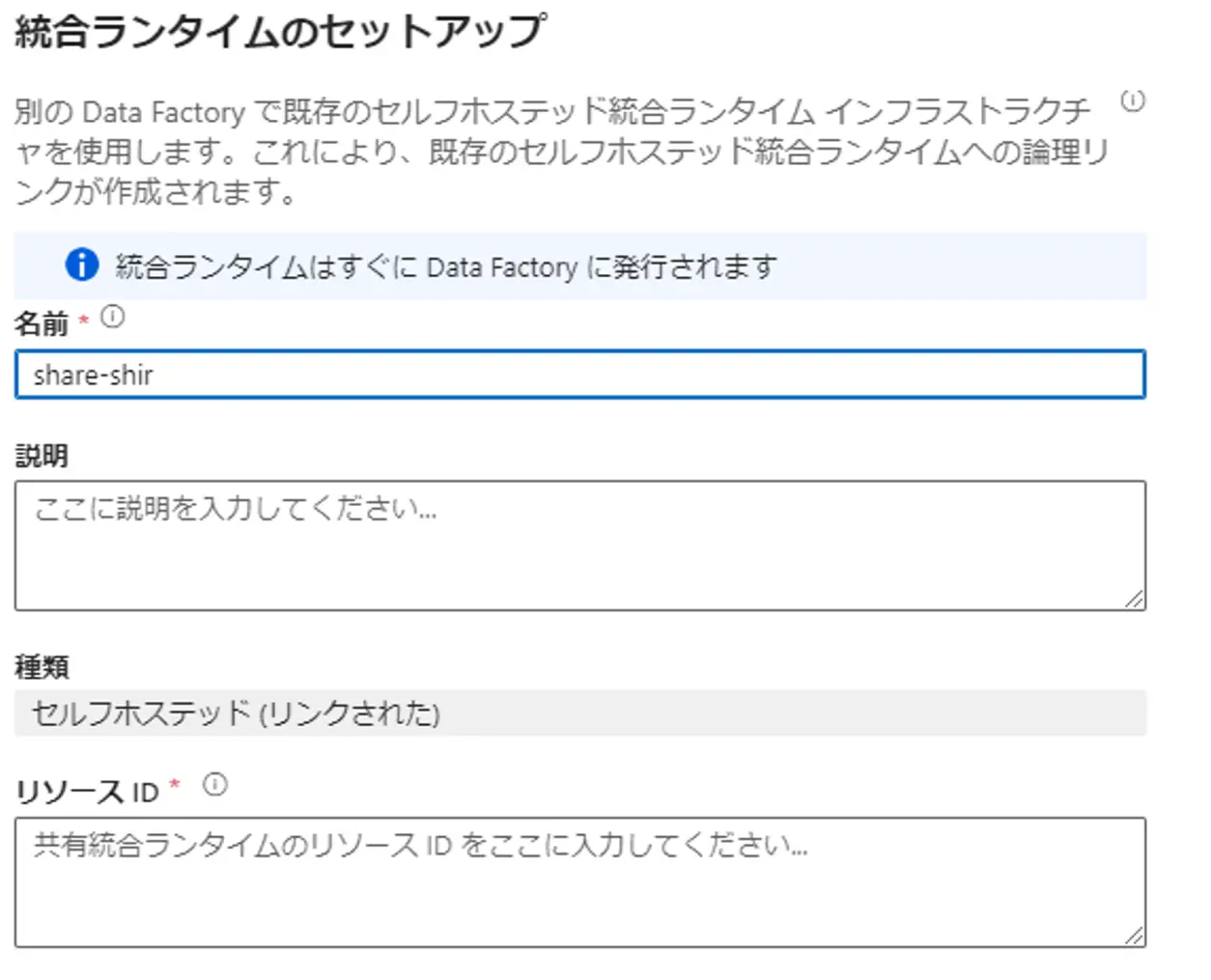
distinction
なお、後述のパイプラインでは、統合ランタイムの利用判別が要求されるケースがあります。この方式については、記載の通りとなります。
1 つのアクティビティが複数の種類の統合ランタイムに関連付けられる場合は、そのどちらかに解決されます。 セルフホステッド統合ランタイムは、マネージド仮想ネットワークが使用されている Azure Data Factory や Synapse ワークスペースのインスタンス内の Azure 統合ランタイムよりも優先されます。 そして、後者はグローバル Azure 統合ランタイムよりも優先されます。
Private Link and Managed Network
Private Link についてです。Azure Data Factory では、先述の通り、パブリックエンドポイントを使用するか、プライベートエンドポイントを使用するか選択が可能です。
Data Factory が、プライベートエンドポイントを使用する場合、Azure private Link を使用して、セルフホステッド統合ランタイムと Azure Data Factory が、 Azure 内部でセキュアな通信を確保します。
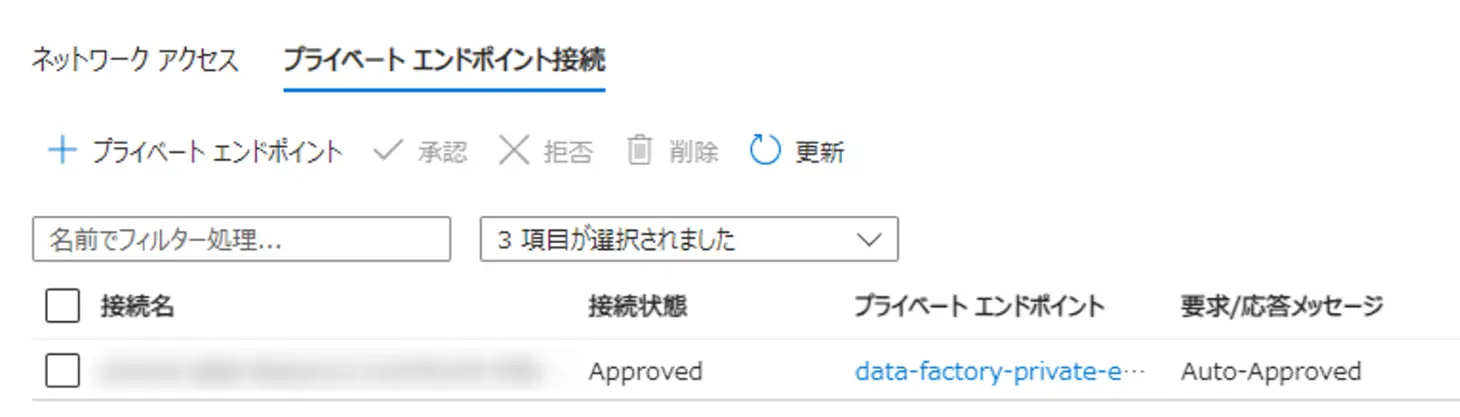
プライベート エンドポイント経由の Data Factory への接続は、Data Factory のセルフホステッド統合ランタイムにのみ適用され、セルフホステッド統合ランタイムは、オンプレミスあるいはAzure 仮想ネットワークいずれかで機能している必要があります。
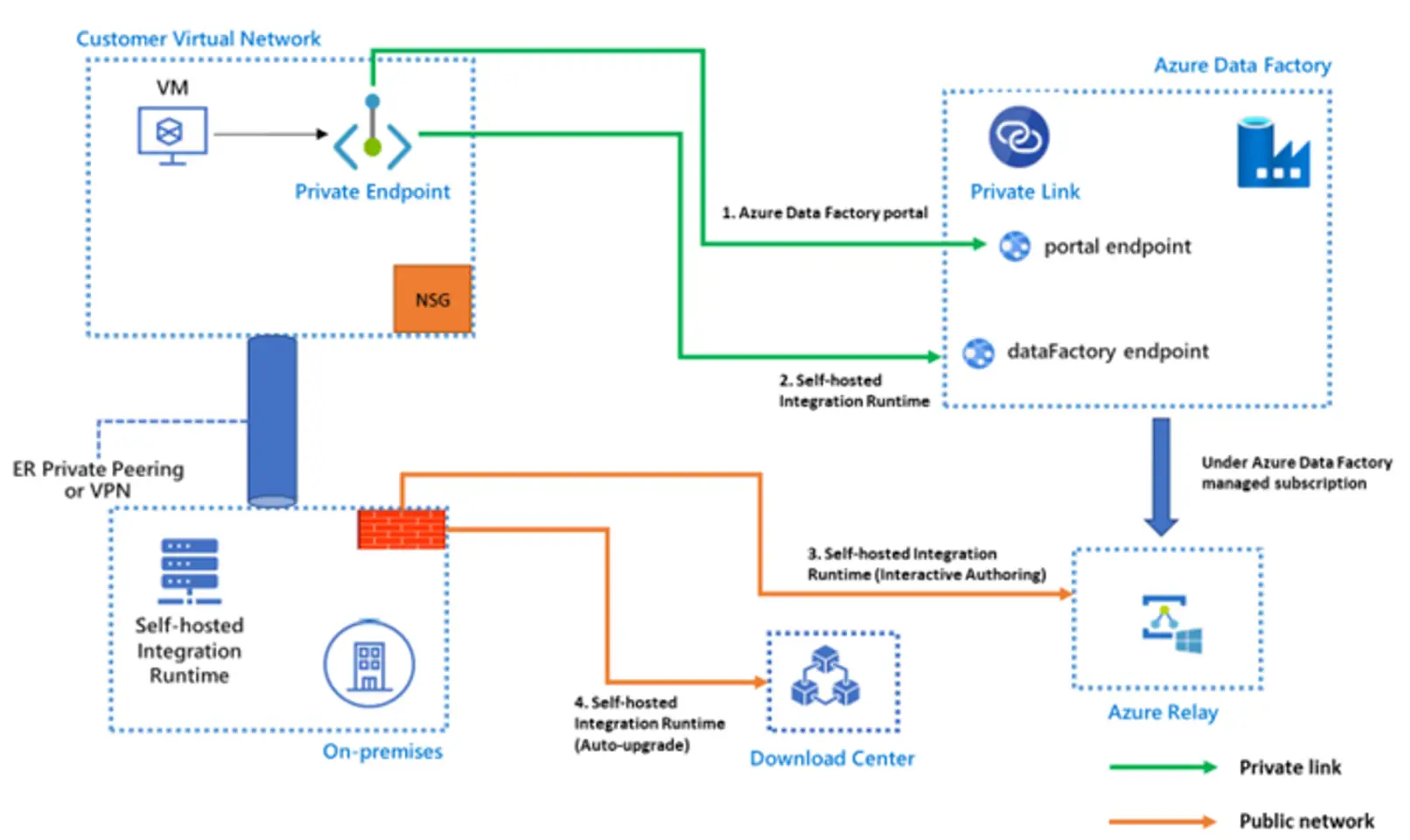
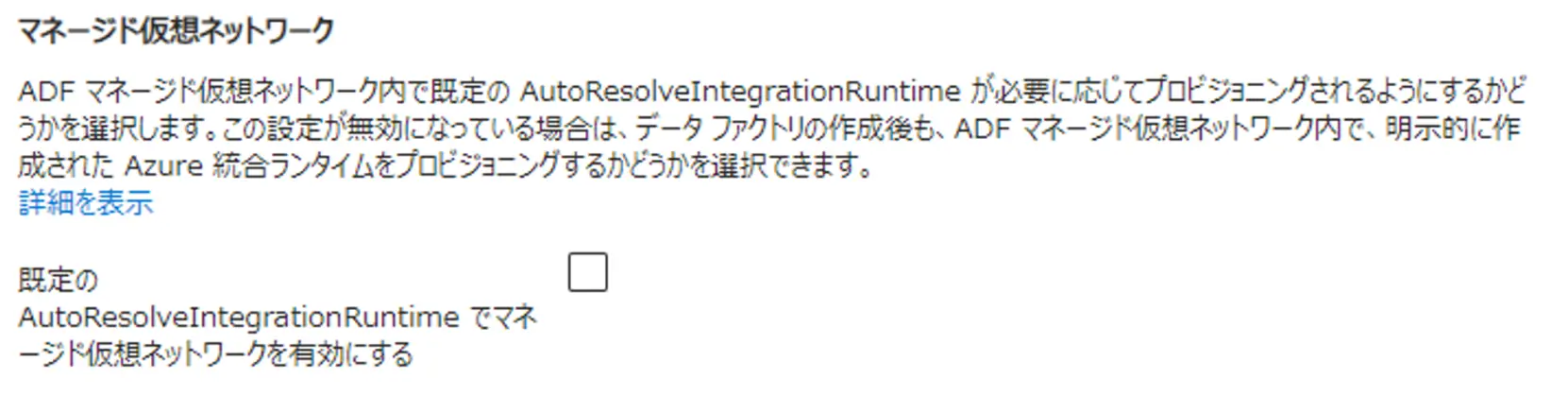
続いて、マネージド仮想ネットワーク内に Azure 統合ランタイム(Azure IR)を作成すると、サポートされるデータストアへのアクセスを可能にします。マネージド仮想ネットワークは、Data Factory リージョンと同じリージョン内でのみサポートされます。
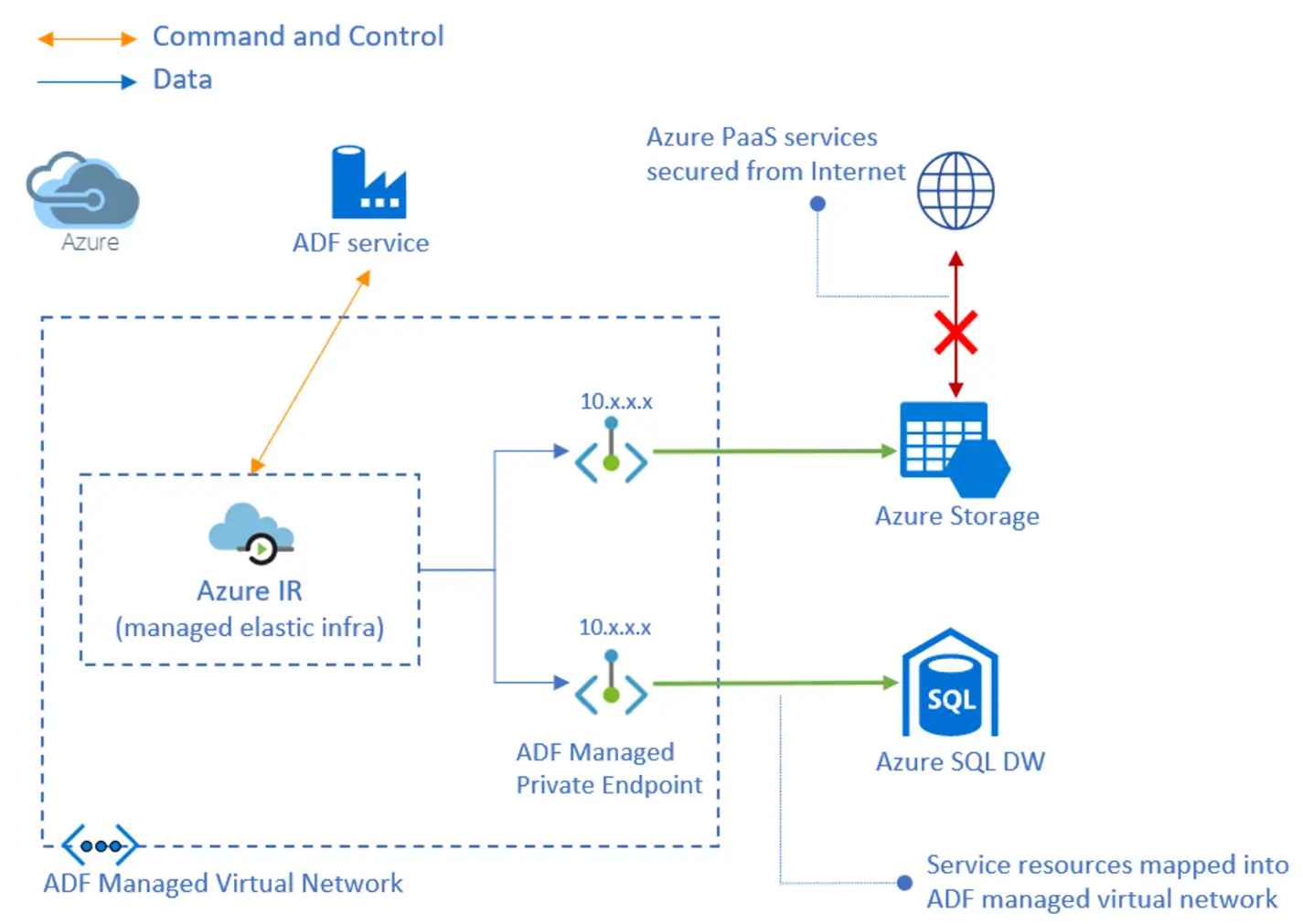
これらはデータアクセスが全面的に Microsoft のバックボーンネットワークを介して転送され、セキュリティに保護された利用が可能です。
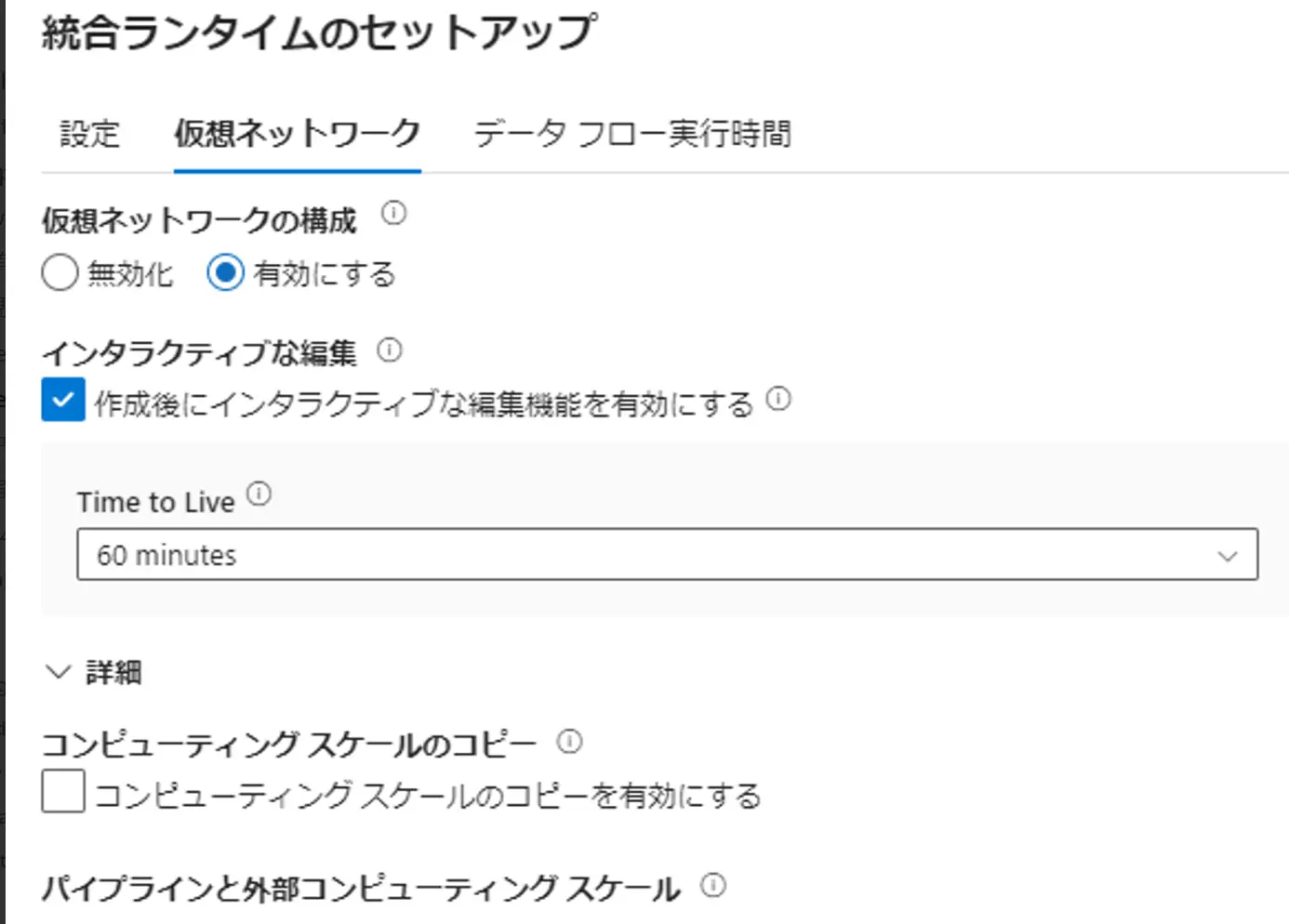
マネージド プライベート エンドポイントは、Data Factory によって自動的に管理されます。マネージドプライベートエンドポイントを作成し、Azure の PaaS サービスに上図のイメージのようにアクセス出来ます。対象のサービスからエンドポイント接続の承認を実施し、Data Factory のマネージドプライベートエンドポイントのステータスを Approve する事で利用が可能です。
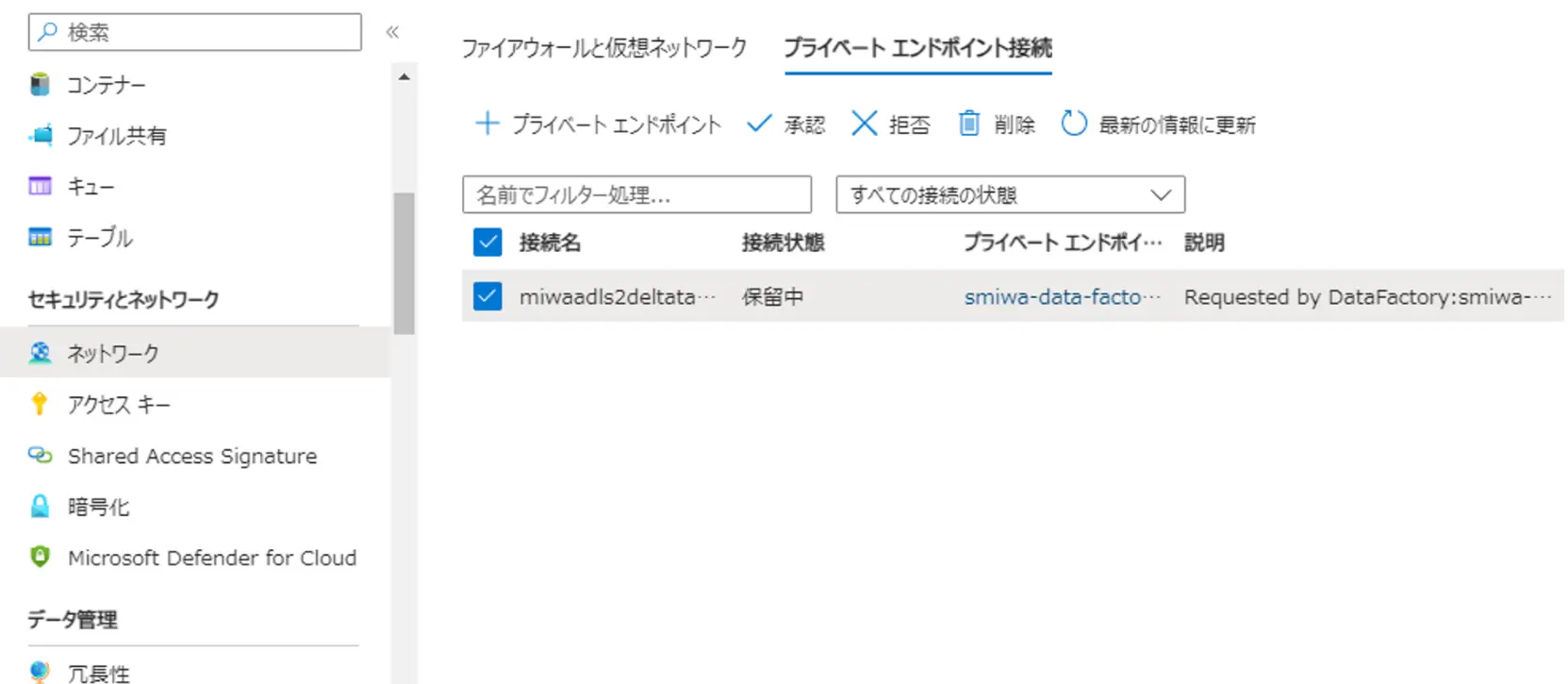
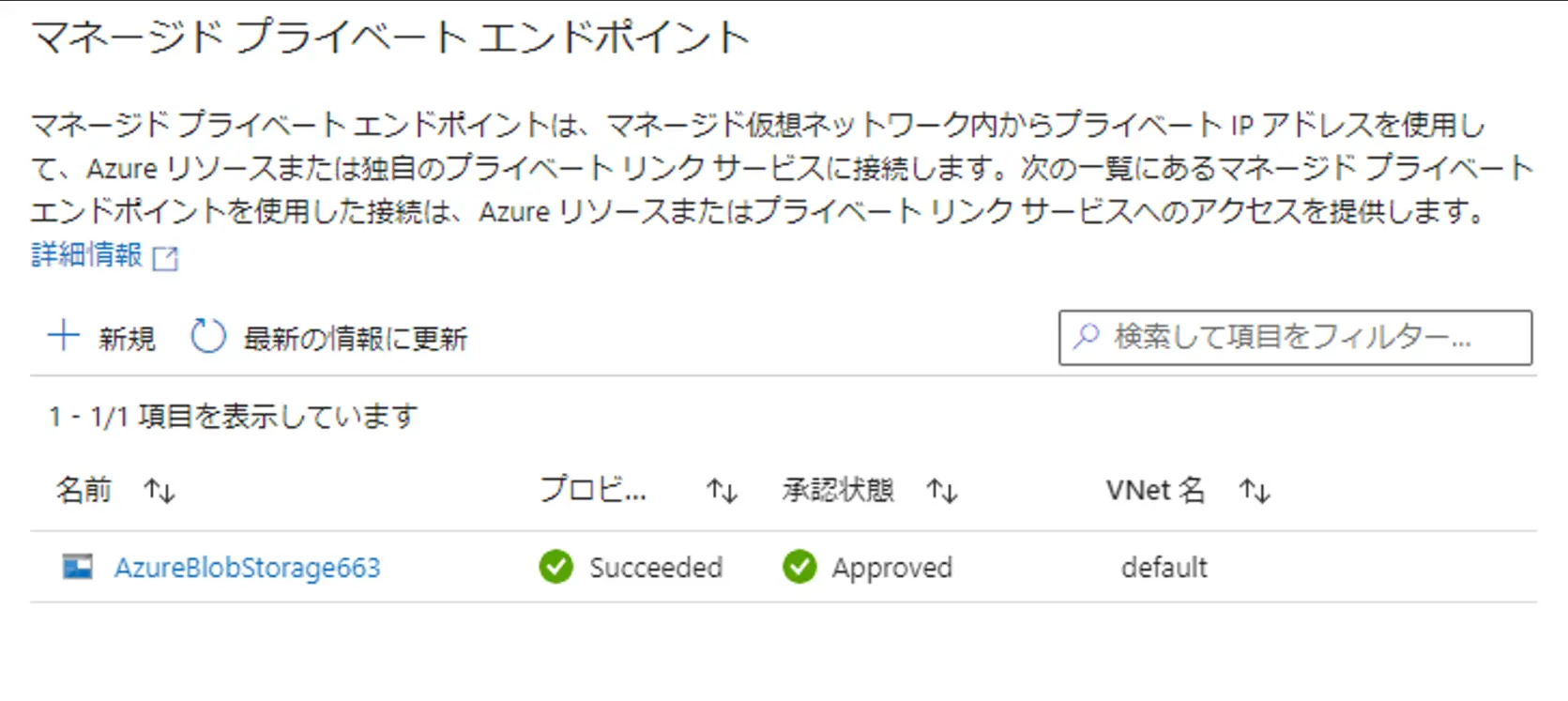 Data Factory 用のプライベートエンドポイントリンクをセットアップする方法について、マネージド仮想ネットワークおよびマネージドプライべートエンドポイントの作成手順については記載の通りです。
Data Factory 用のプライベートエンドポイントリンクをセットアップする方法について、マネージド仮想ネットワークおよびマネージドプライべートエンドポイントの作成手順については記載の通りです。
最後に、こちらリンクでは、シナリオにあったランタイムを構成するとともに各ランタイムの特性が比較された内容がされています。
Azure IRにおいては、パブリックネットワーク経由でのアクセスである点、ターゲットとなるデータストアのFWの制御によって構成される通信方式です。

マネージド仮想ネットワークを使用した Azure IR においては、マネージドプライベートエンドポイントを使用したセキュアなアクセスとなります。Private Link サービスの追加により、一部インプレミスのデータソースへのアクセスも可能とします。
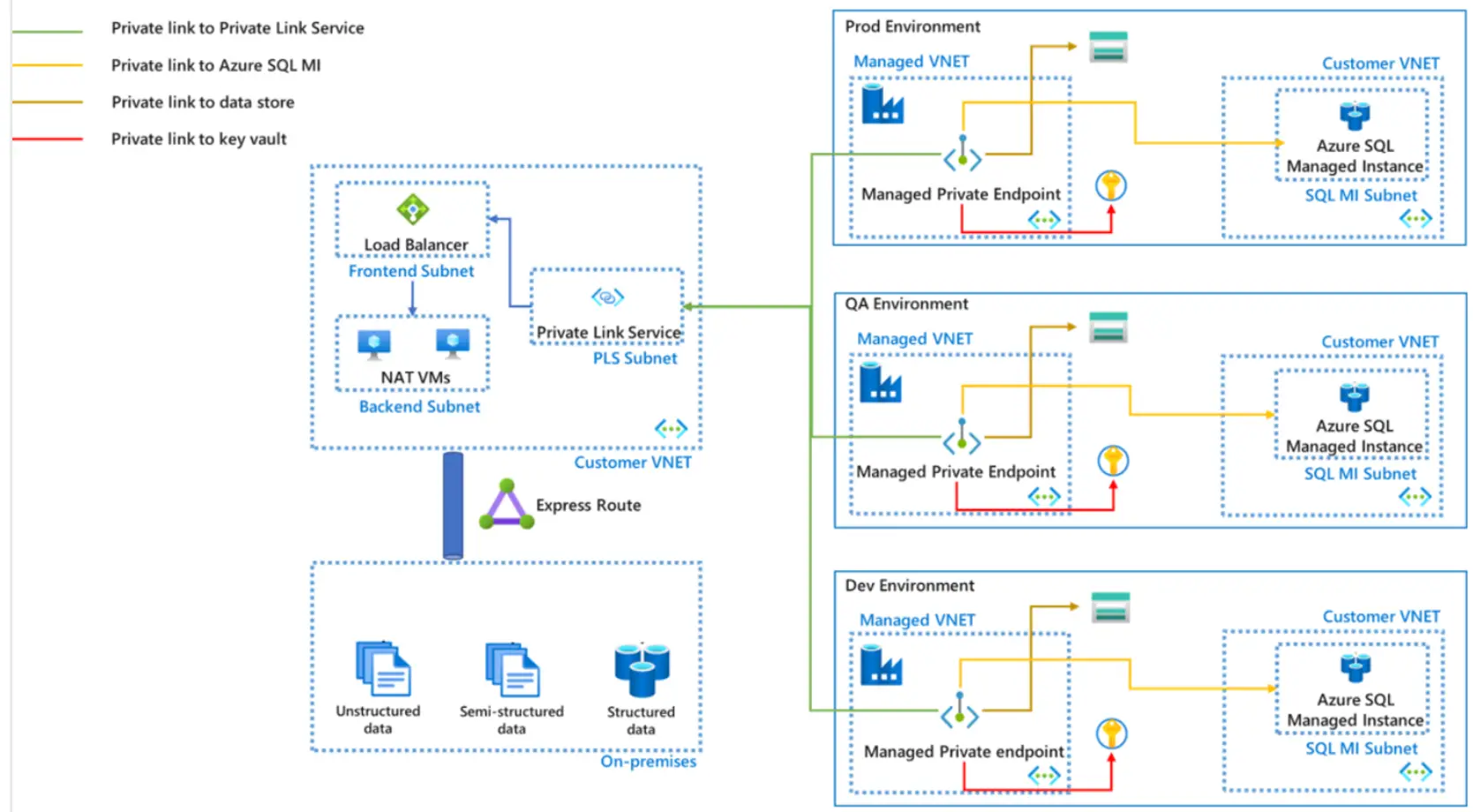
セルフホステッド統合ランタイム(SHIR) においては、自己管理のコンピューター上で動作し、パブリック ネットワーク経由でデータストアにアクセスします。Azure ネットワーク外のデータストアへのアクセスする場合に利用ケースが多く、PrivateLink を経由したプライベート接続も可能です。
また、共有機能による、複数のData Factory インスタンス上で機能する1台のランタイム運用を行う事も可能です。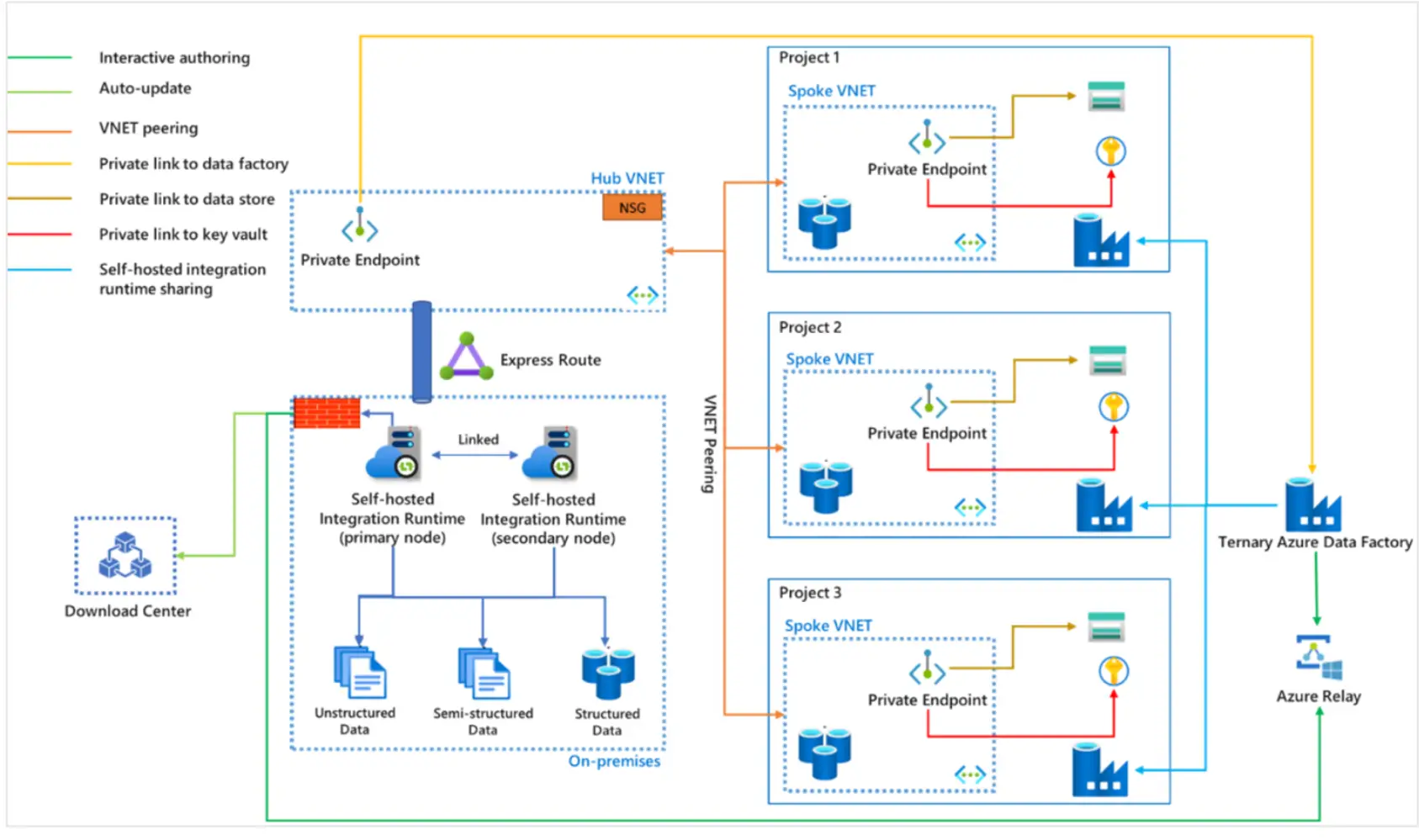
Programmatically Create Data Factory
冒頭にあったデータファクトリーの作成画面は、Azure Portal から Data Factory を作成する際の画面です。このように Azure Portal 上から Azure Data Factory のインスタンスを作成する事が可能です。他の方法を見ていきましょう。
Azure Data Factory の REST API では、データファクトリを作成するための API が提供されます。REST API を使用した作成手順では、PowerShell を使用した手順が記載されています。必要な情報を記載し、作成を実施します。
Connect-AzAccount
Get-AzSubscription
$tenantID = "<your tenant ID>"
$appId = "<your application ID>"
$clientSecrets = "<your clientSecrets for the application>"
$subscriptionId = "<your subscription ID to create the factory>"
$resourceGroupName = "<your resource group to create the factory>"
$factoryName = "<specify the name of data factory to create. It must be globally unique.>"
$apiVersion = "2018-06-01"
$credentials = Get-Credential -UserName $appId
Connect-AzAccount -ServicePrincipal -Credential $credentials -Tenant $tenantID
GetToken
$body = @"
{
"location": "East US",
"properties": {},
"identity": {
"type": "SystemAssigned"
}
}
"@
$response = Invoke-AzRestMethod -SubscriptionId ${subscriptionId} -ResourceGroupName ${resourceGroupName} -ResourceProviderName Microsoft.DataFactory -ResourceType "factories" -Name ${factoryName} -ApiVersion ${apiVersion} -Method PUT -Payload ${body}
$response.ContentBicep とは、ファイル内で、Azure にデプロイするインフラストラクチャを定義し、そのファイルを開発ライフサイクル全体にわたって使用して、インフラストラクチャを繰り返しデプロイします。Azure Data Factory はBicepによる管理をサポートします。
ここでは、Bicep を使用して Azure Data Factoryを作成する手順が記載されています。ストレージアカウントとBlobコンテナを作成、ADFはADFインスタンスを構成し、リンクドサービスとこれに紐づくデータセット、最後にCopy アクティビティ用のパイプラインを生成する定義です。
@description('Data Factory Name')
param dataFactoryName string = 'datafactory${uniqueString(resourceGroup().id)}'
@description('Location of the data factory.')
param location string = resourceGroup().location
@description('Name of the Azure storage account that contains the input/output data.')
param storageAccountName string = 'storage${uniqueString(resourceGroup().id)}'
@description('Name of the blob container in the Azure Storage account.')
param blobContainerName string = 'blob${uniqueString(resourceGroup().id)}'
var dataFactoryLinkedServiceName = 'ArmtemplateStorageLinkedService'
var dataFactoryDataSetInName = 'ArmtemplateTestDatasetIn'
var dataFactoryDataSetOutName = 'ArmtemplateTestDatasetOut'
var pipelineName = 'ArmtemplateSampleCopyPipeline'
resource storageAccount 'Microsoft.Storage/storageAccounts@2021-08-01' = {
name: storageAccountName
location: location
sku: {
name: 'Standard_LRS'
}
kind: 'StorageV2'
}
resource blobContainer 'Microsoft.Storage/storageAccounts/blobServices/containers@2021-08-01' = {
name: '${storageAccount.name}/default/${blobContainerName}'
}
resource dataFactory 'Microsoft.DataFactory/factories@2018-06-01' = {
name: dataFactoryName
location: location
identity: {
type: 'SystemAssigned'
}
}
resource dataFactoryLinkedService 'Microsoft.DataFactory/factories/linkedservices@2018-06-01' = {
parent: dataFactory
name: dataFactoryLinkedServiceName
properties: {
type: 'AzureBlobStorage'
typeProperties: {
connectionString: 'DefaultEndpointsProtocol=https;AccountName=${storageAccount.name};AccountKey=${storageAccount.listKeys().keys[0].value}'
}
}
}
resource dataFactoryDataSetIn 'Microsoft.DataFactory/factories/datasets@2018-06-01' = {
parent: dataFactory
name: dataFactoryDataSetInName
properties: {
linkedServiceName: {
referenceName: dataFactoryLinkedService.name
type: 'LinkedServiceReference'
}
type: 'Binary'
typeProperties: {
location: {
type: 'AzureBlobStorageLocation'
container: blobContainerName
folderPath: 'input'
fileName: 'emp.txt'
}
}
}
}
resource dataFactoryDataSetOut 'Microsoft.DataFactory/factories/datasets@2018-06-01' = {
parent: dataFactory
name: dataFactoryDataSetOutName
properties: {
linkedServiceName: {
referenceName: dataFactoryLinkedService.name
type: 'LinkedServiceReference'
}
type: 'Binary'
typeProperties: {
location: {
type: 'AzureBlobStorageLocation'
container: blobContainerName
folderPath: 'output'
}
}
}
}
resource dataFactoryPipeline 'Microsoft.DataFactory/factories/pipelines@2018-06-01' = {
parent: dataFactory
name: pipelineName
properties: {
activities: [
{
name: 'MyCopyActivity'
type: 'Copy'
typeProperties: {
source: {
type: 'BinarySource'
storeSettings: {
type: 'AzureBlobStorageReadSettings'
recursive: true
}
}
sink: {
type: 'BinarySink'
storeSettings: {
type: 'AzureBlobStorageWriteSettings'
}
}
enableStaging: false
}
inputs: [
{
referenceName: dataFactoryDataSetIn.name
type: 'DatasetReference'
}
]
outputs: [
{
referenceName: dataFactoryDataSetOut.name
type: 'DatasetReference'
}
]
}
]
}
}Redundacy
Azure Data Facotry の作成はリージョン毎にあるという事が冒頭の画面上から確認できました。
Azure Data Factory におけるデータは、パイプラインやデータセット等のオブジェクトにあたるメタデータと監視データが含まれています。そして、ほとんどのリージョンにおいて、ペアリージョンへ、これらのデータが格納され、レプリケートされます。
なお、セルフホステッド統合ランタイムは、フェールオーバーの管轄外となるため注意が必要です。
Git Management
Azure Data Factory は Git 連携を標準でサポートしており、Git 連携を有効化すると、Github、Azure DevOps のリポジトリ上での管理を可能にします。
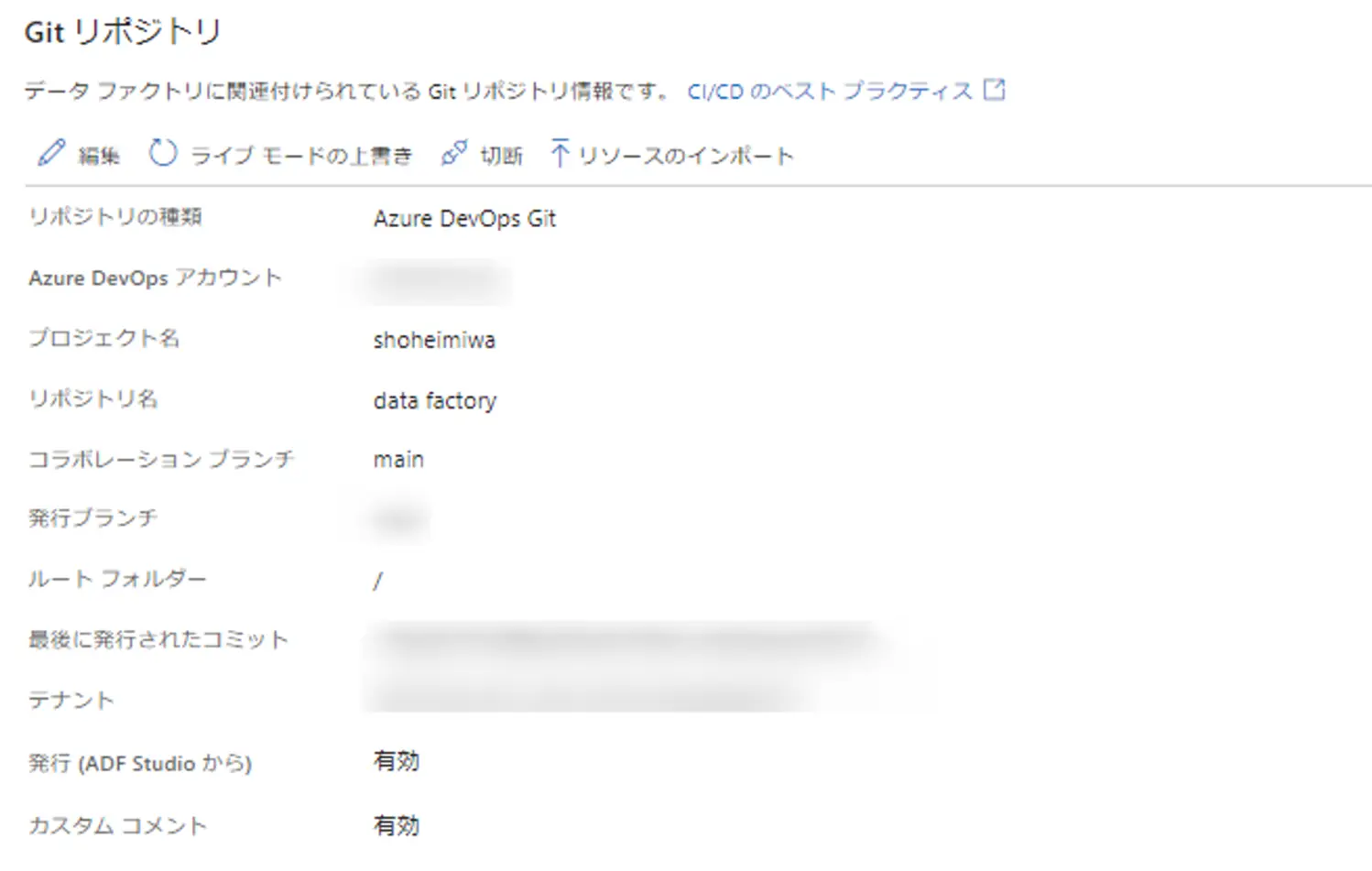
Azure DevOps との連携をメインに行う手順については、以前執筆したものを参考に頂けると幸いです。
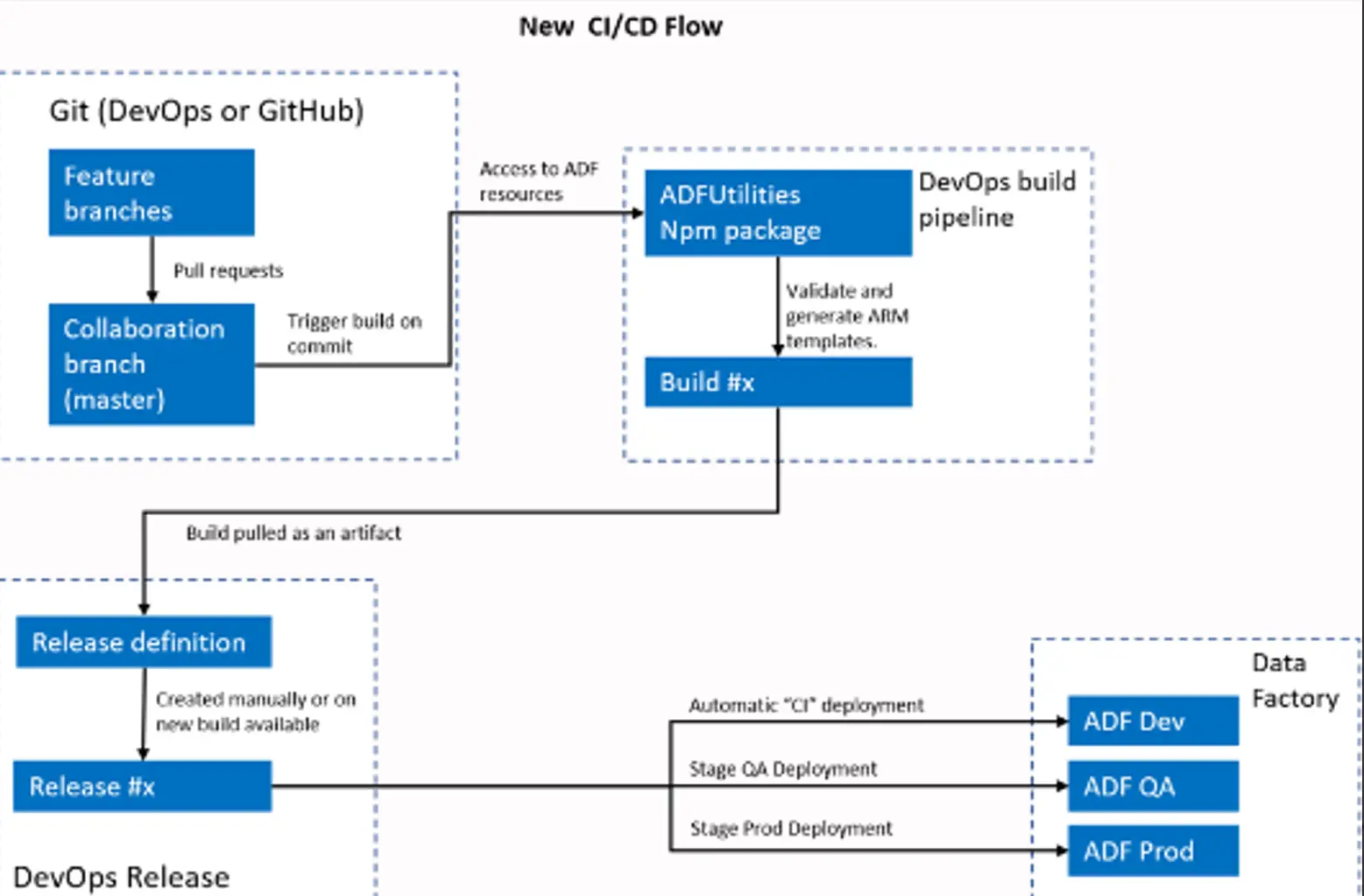
CI/CD パターンでは、単一の Data Factory 上でブランチ毎に管理が行える事が分かりました。
For Connectors
Azure Data Factory におけるコネクタとは、Azure Data Factory に標準で組み込まれた接続設定が可能なリソースにあたるかと思います。
Azure Data Factory のコネクタは、非常に豊富なサポートを行っています。後述の Copy Activity / Mapping Data Flow / Lookup Activity / Get Metadata Activity / Val Acticity の利用に関しては、コネクタ毎にサポートの有無が存在するため事前の確認が必要です。
また、Fabric のデータファクトリにおけるコネクタとの違いについては、比較があります。
Fabric における Data Flow Gen2 フローについては、次回ご説明をします。
LinkedService / Connector / Dataset / Integration Runtime
ここでは、リンクドサービス、コネクタ、データセット、統合ランタイムの関係性について見ていきます。
リンクドサービスとは、接続文字列のように位置付けされ、その後に作成するデータセット、統合ランタイムとの紐付けが必要なADFのオブジェクトとなります。
下記は、Azure SQL Database 用のリンクドサービスの JSON プロパティです。
{
"name": "AzureSqlDatabase1",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "integrated security=False;encrypt=True;connection timeout=30;data source=xxxxxx.database.windows.net
"encryptedCredential": "xxxxxxx"
},
"connectVia": {
"referenceName": "selfHostedIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
}
一方、データセットは、後述のアクティビティにおける参照先となるデータの名前付きビューにあたります。
以下は Azure SQL Database を指定した JSON の例となります。
{
"name": "miwa_sql_database_dataset",
"properties": {
"linkedServiceName": {
"referenceName": "miwa_sql_database_linkedservice",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "AzureSqlTable",
"schema": [
{
"name": "ID",
"type": "nchar"
},
{
"name": "Timestamp",
"type": "datetime",
"precision": 23,
"scale": 3
},
{
"name": "Name",
"type": "nchar"
},
{
"name": "Value",
"type": "nchar"
},
{
"name": "Inventory",
"type": "nchar"
}
],
"typeProperties": {
"schema": "dbo",
"table": "Sample_table1"
}
},
"type": "Microsoft.DataFactory/factories/datasets"
}先述のコネクタの位置付けは、リンクドサービスとデータセットオブジェクトから認識されるかと思います。Azure Data Factory Studio の画面から確認出来るように、いずれも指定のデータストアやコンピューターを選択するものになります。

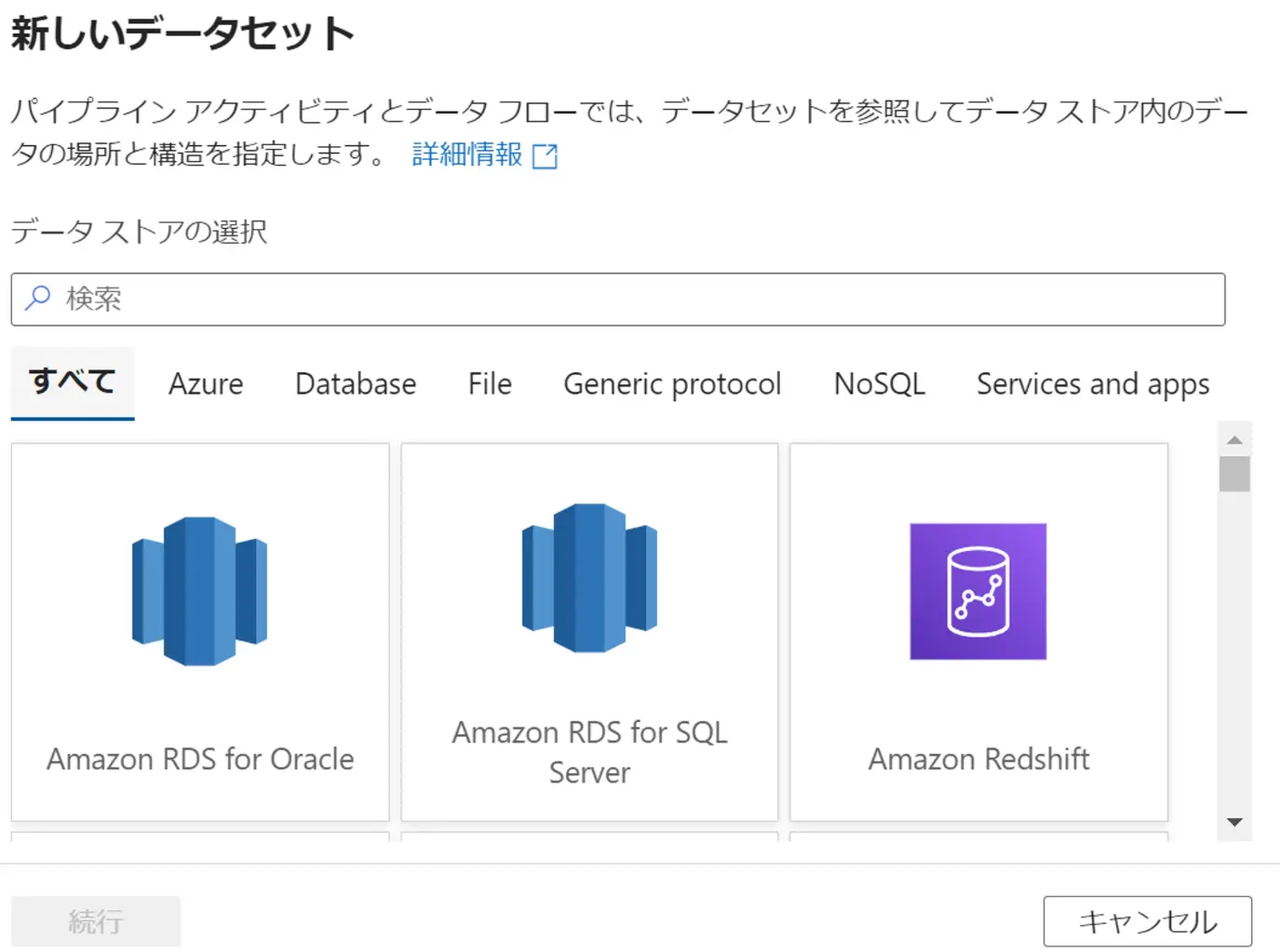
では、コネクタの接続設定について、検証を含めてみていきましょう。スタンダードな Azure BLOB Storageコネクタが持つ設定です。
まずは、リンクドサービスです。BLOB の認証方式は以下をサポートします。
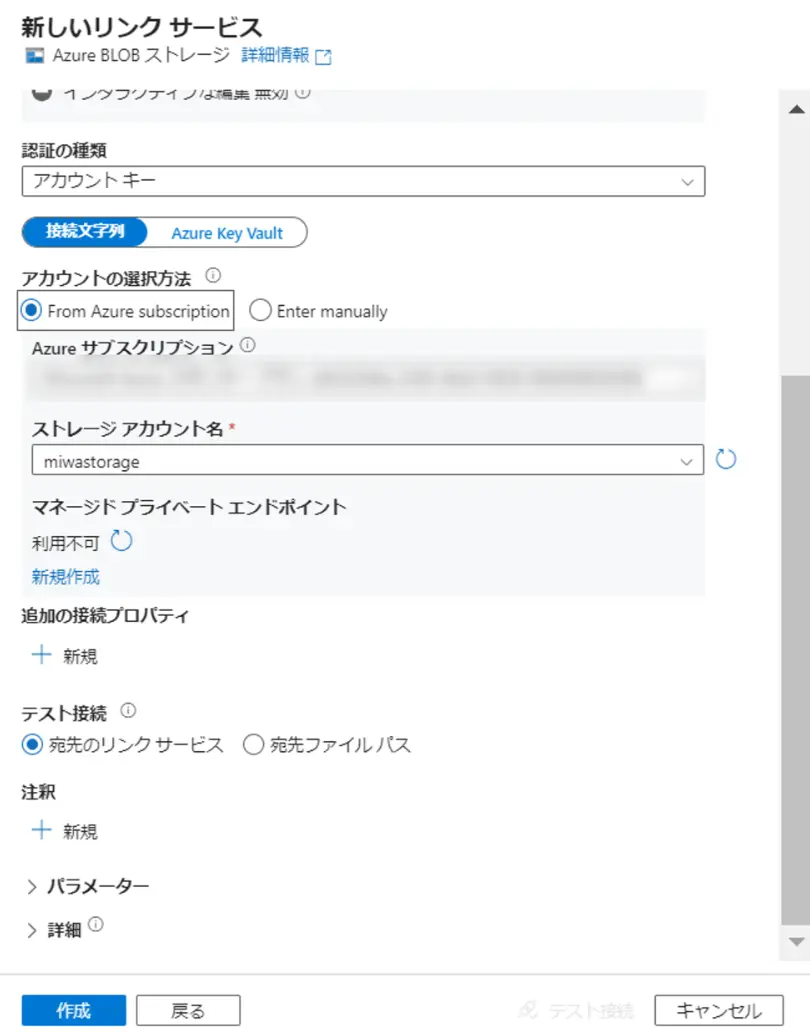
下記、作成画面からわかる通り、ストトレージアカウント名までがリンクドサービスとしての接続文字列にあたります。Enter manually を選択する事で上記、認証方式をいずれも使用出来ます。
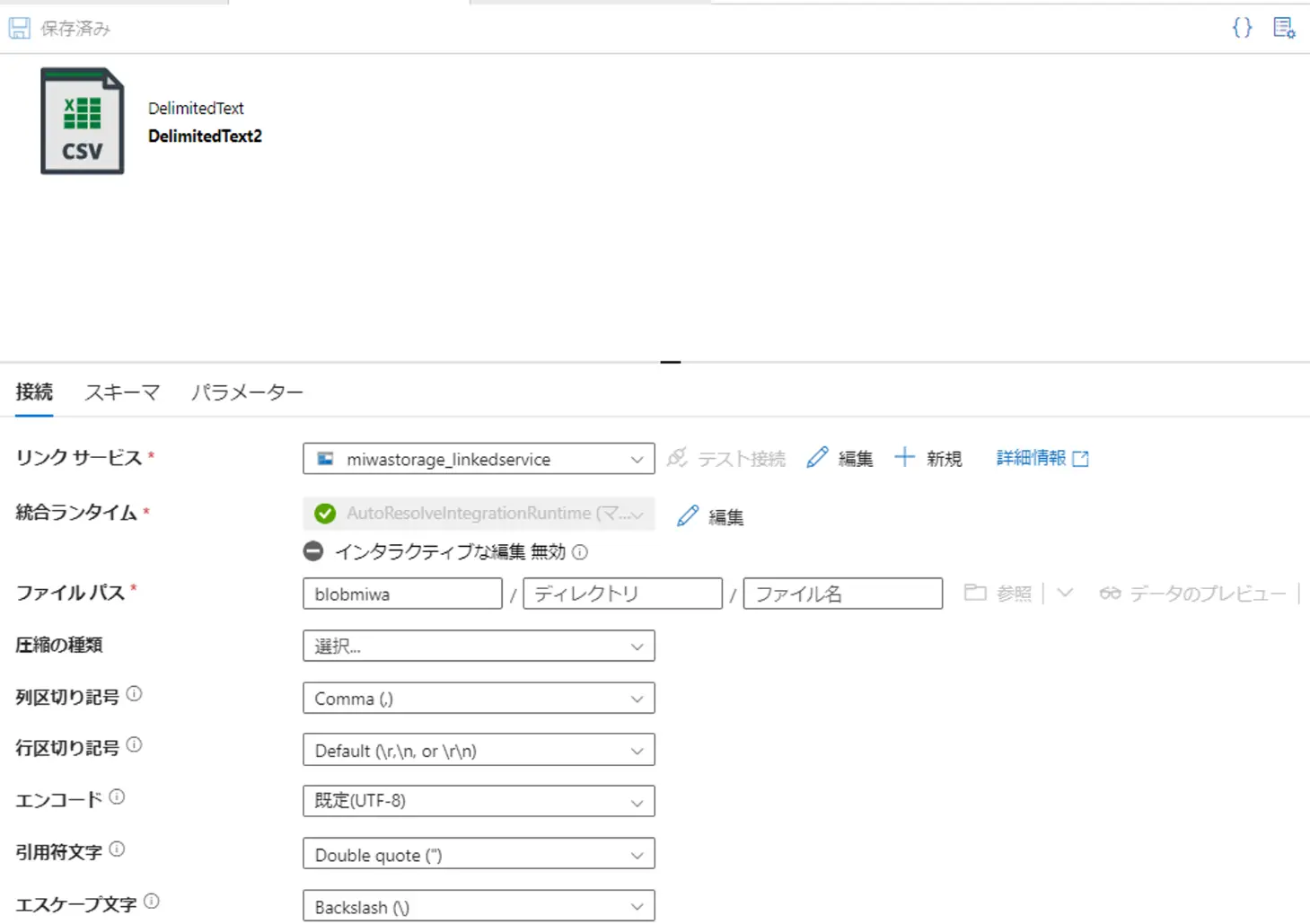
続いて、リンクドサービスに紐づくBLOB データセットは、以下のように定義づけされます。まず、ファイルフォーマットを選択します。

CSVを例として、データセットを構成した場合、その後は以下のようにファイルフォーマット以下の具体的な定義をデータセット上で行います。
これらが定義されたデータセットの JSON プロパティの例は以下となります。
"name": "DelimitedText2",
"properties": {
"linkedServiceName": {
"referenceName": "miwastorage_linkedservice",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "blobmiwa"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [
{
"name": "ID",
"type": "String"
},
{
"name": "Timestamp",
"type": "String"
},
{
"name": "Name",
"type": "String"
},
{
"name": "Value",
"type": "String"
},
{
"name": "Inventory",
"type": "String"
}
]
}
}ここまでの仕様からオブジェクトの作成プロセスは、統合ランタイム⇒リンクドサービス⇒データセットの順番になる事が分かります。
Dataflow / Pipeline / Activity
では、Azure DataFactory がデータへアクセスし、処理を行う場合についてです。
後述の各Activityがリンクドサービスを実行し、リンクドサービスに紐づく統合ランタイムを経由してAzureDataFactoryから要求する形式になります。
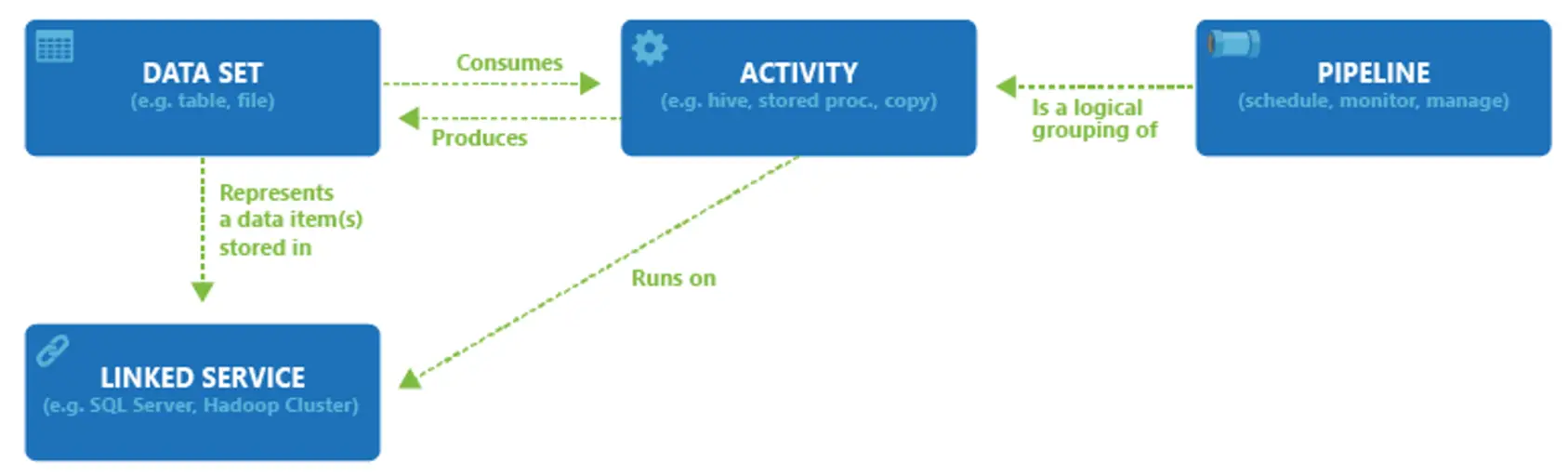
アクティビティとデータセットは Producer / Consumer の関係性になります。

パイプラインはご想像の通り、1つのタスクとして1つ以上の処理を実行するグループです。
アクティビティは、パイプライン上で制御される一つの命令のようなものです。この命令にはいくつか種類が存在し、コピーアクティビティ、データ変換アクティビティ、コントロールフローアクティビティとなります。
データフローとは、1つの処理をまとめたData Factory リソース(オブジェクト)にあたりますが、パイプライン上では一種のアクティビティとなるデータ変換アクティビティにあたります。
For DataFlow
では、データフローから見ていきましょう。
データフローは先述した通り、コードを要さずに視覚化された設計を実施出来る一つのオブジェクトにあたりますが、パイプラインにおいては1つのアクティビティになります。
例えば、以下のような画面から開発されたデータフロー dataflow2 は、パイプライン Pipeline2上から見ると、データ変換アクティビティとしてセットする一つの設定になり得るものです。
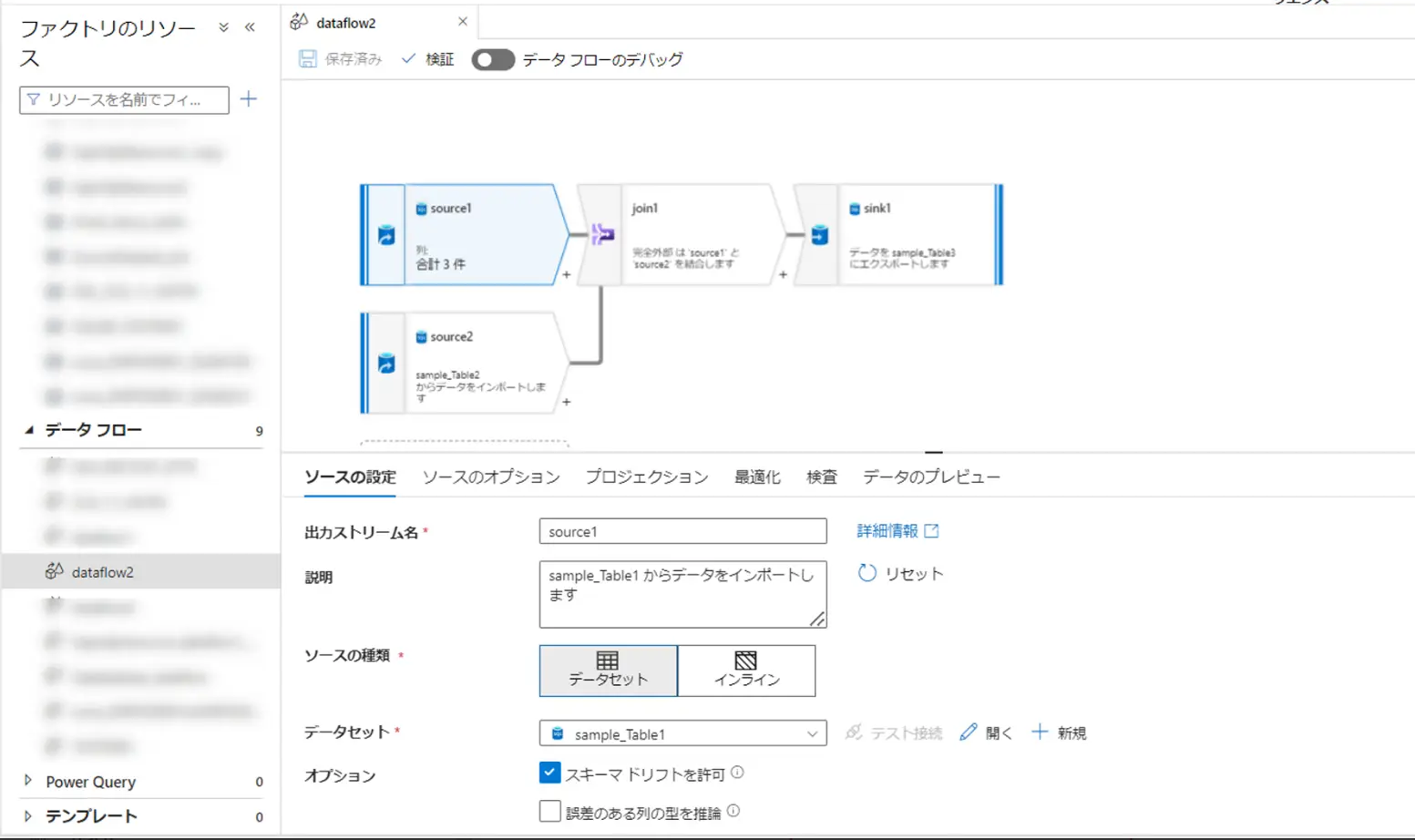
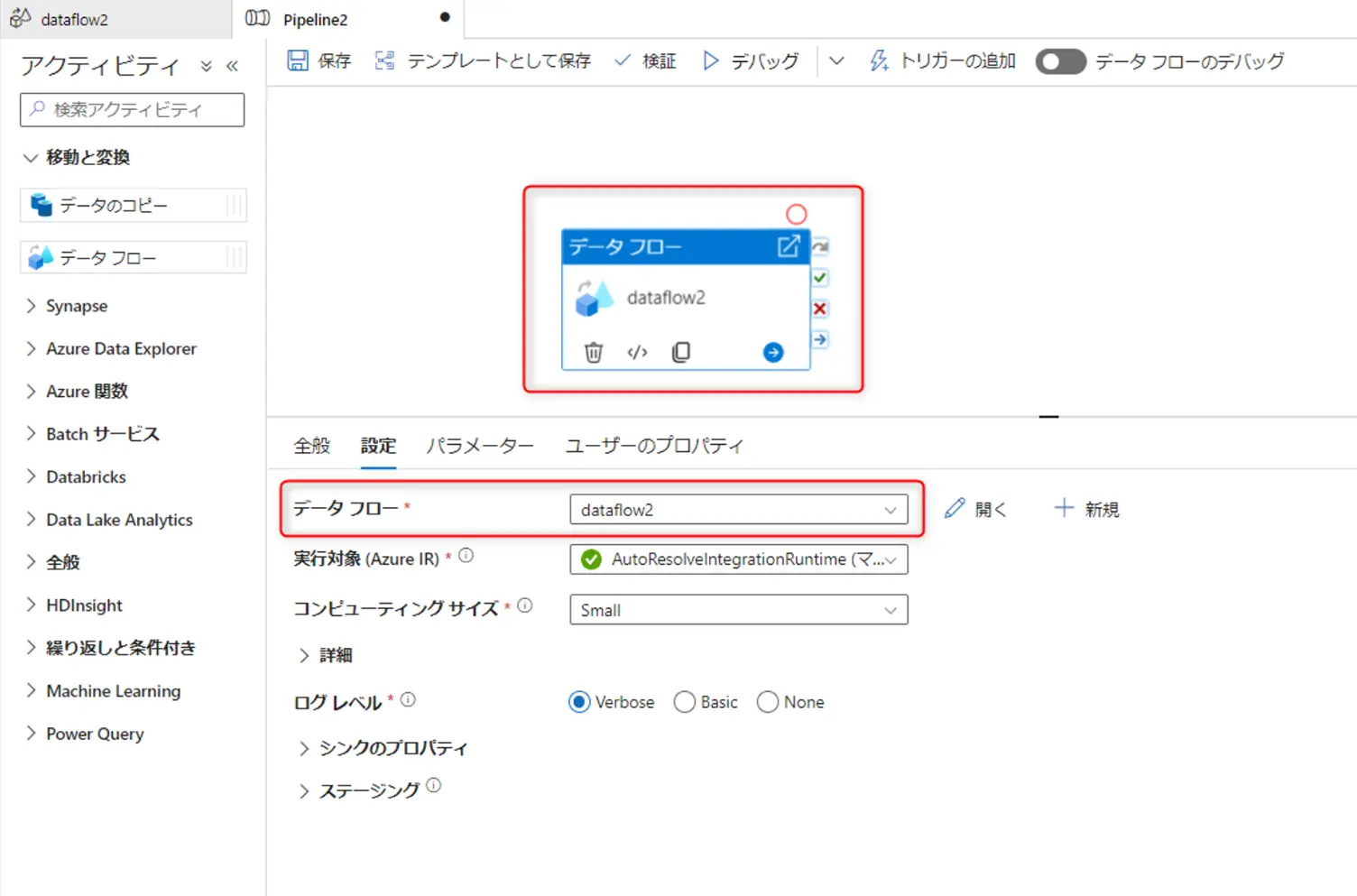
データフローは基本的に、マッピングデータフローと変更データキャプチャの二つで機能するものかと思います。
マッピングデータフローは、先ほど記載した dataflow2 のようなセットです。データフローにおける出力元を Source と呼び、出力先を Sink と言います。
マッピングデータフローと変更データキャプチャの明確な違いは、Data Factory のリソースとして違いが存在するケースもありますが、動作挙動としてマッピングデータフロー内で変更データキャプチャが実装可能であるため、実際にはマッピングデータフローと混在するものと思います。マッピングデータフローにおける変更データキャプチャは、ネイティブ変更データキャプチャと呼ばれているようです。
ADFにおける 変更データキャプチャ(CDC)は、パイプラインが最後に実行されてから、変更されたソース データのみを読み取るプロセスを指しており、これを実現するケースはいくつかパターンが存在するものと思います。
変更データキャプチャのファクトリ―リソースから選択可能なUIがプレビューとして公開されており、以下のようにソース種別を選択し、対象テーブルとターゲットを選択し、開始をするが可能なようです。
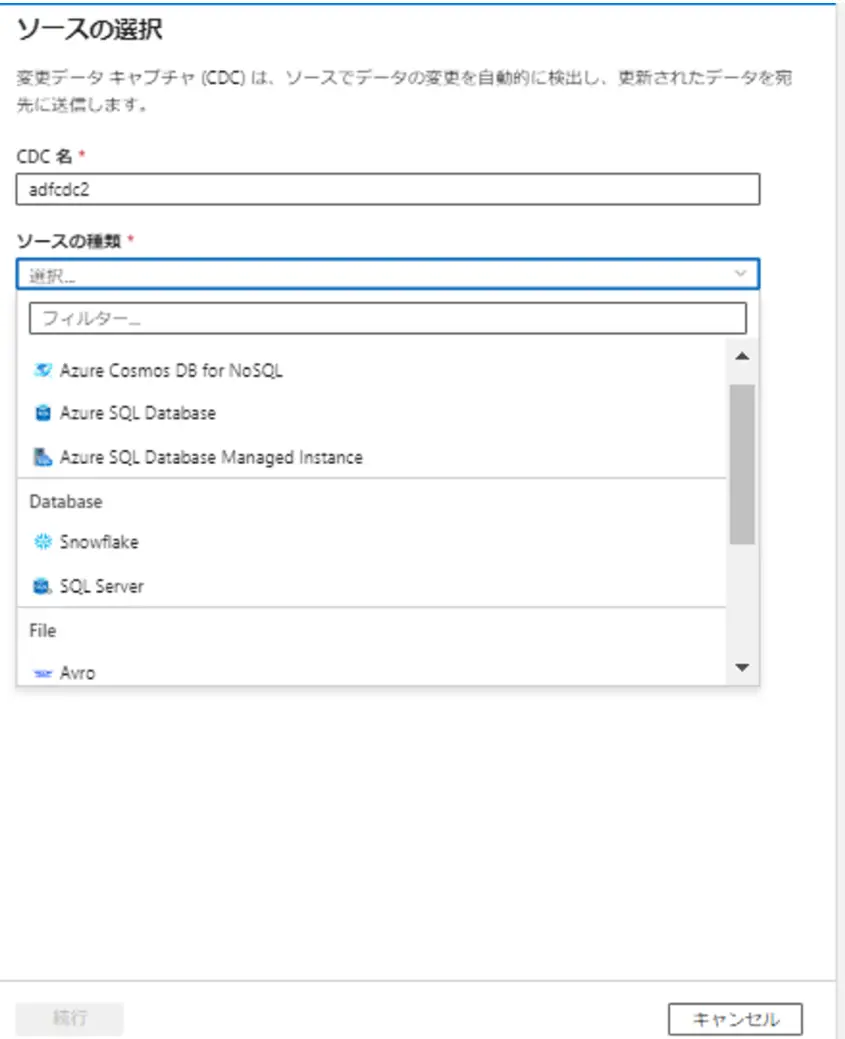
一方、マッピングデータフローでのネイティブ変更データキャプチャは、以下、サポートされたコネクタを使用している場合に有用な実装方式です。データベースからの変更データキャプチャにおいては、ネイティブ変更データキャプチャが推奨されています。
- SAP CDC
- Azure SQL Database
- SQL Server
- Azure SQL Managed Instance
- Azure Cosmos DB (SQL API)
- Azure Cosmos DB 分析ストア
- Snowflake
これらネイティブ変更データキャプチャの観点を含めて、マッピングデータフローを見ていきます。
データフローにおける設定項目はコネクタ(データセット)に依存します。例えば、データストアとしてCDCがサポートしているコネクタを使用すれば、指定した設定値から実現が可能ですし、その分 Data Factory Studio上の設定値もCDCをサポートしていないコネクタとプロパティが異なります。
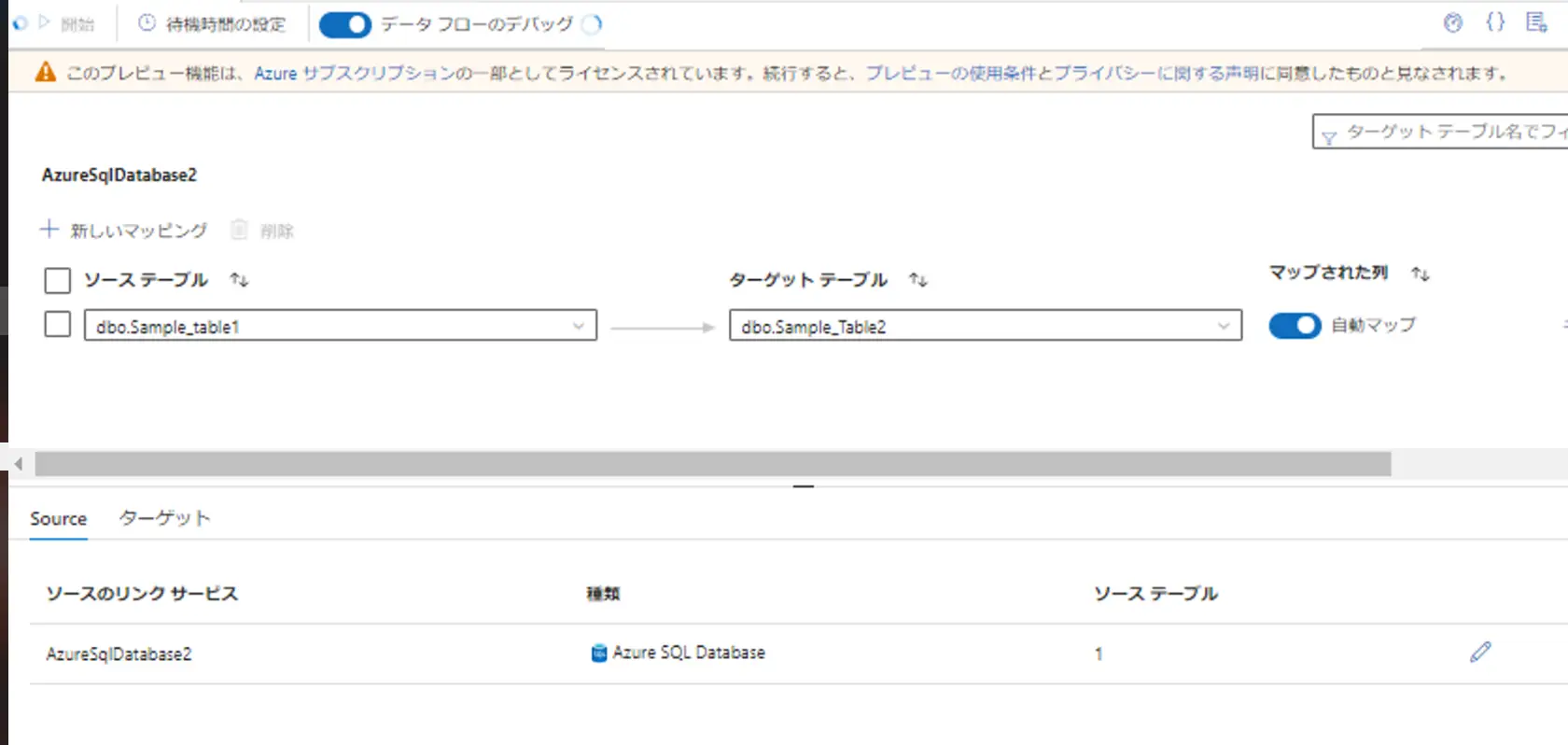
ここから、Azure SQL Database コネクタから構成される sample_Table1 データセットをセットした場合の一例をご紹介します。
Source
ソースの設定に位置付けされる共通的な項目の中で、ポイントとなるものは、処理列の変更を明示的に許容するスキーマ誤差・検証、ファイルベースのヘッダーの有無設定の際に汎用的な設定として利用ケースのあるスキップ行数、デバッグモードから実行する際のサンプリングです。
また、データセット or インラインデータセットにおける採択可否は、コネクタの仕様に依存するため、各コネクタのドキュメントを確認するものが良いかと思います。但し、両方サポートするケースは、データフロー作成時、最初に決定する項目です。基本的に、再利用可能なものはデータセット、パラメーター化されたソースに推奨されるのがインラインデータセットという理解で問題無いかと考えます。但し、後述のようにインラインデータセットを利用してインタラクティブな操作を要求するケースにおいても非常に有用かと思います。
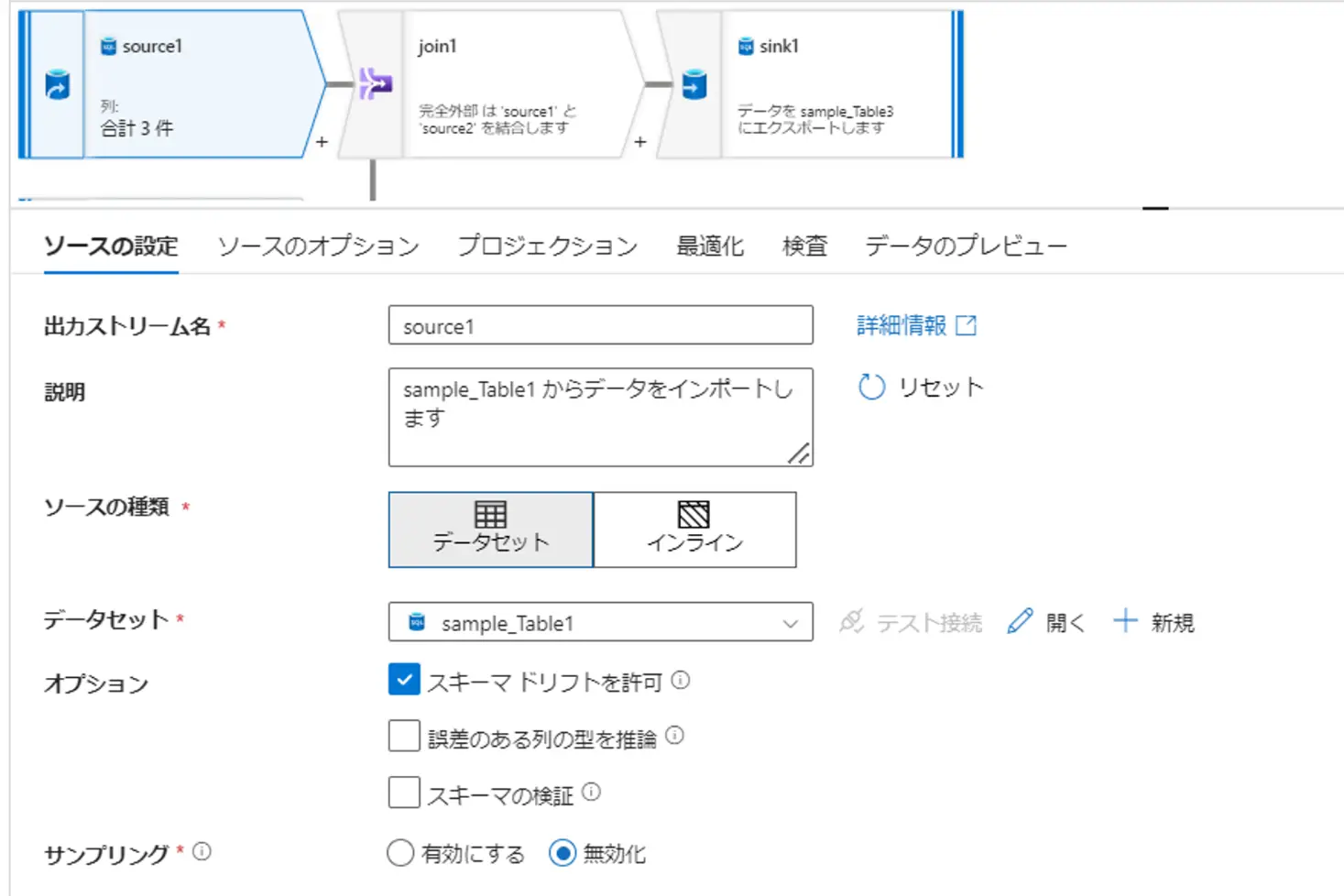
ソースのオプションも、コネクタの仕様により設定が変わります。Azure SQL Database の場合、入力として、テーブル、クエリ(SQL)、指定のストアドプロシージャを選択する事が可能です。クエリのケースにおいては、読み取りのデータ量を削減する際のパフォーマンス向上に有用です。
バッチサイズとは、列のキャッシュのバッチのサイズを制御します。バッチ サイズを大きくすると、メモリ使用率と圧縮が向上しますが、データをキャッシュするときに OOM をリスクにさらします。分離レベルは、読み取りのパフォーマンスに依存します。デフォルトは、Read Uncommit であり、パフォーマンスは一番高いですが、状況次第使用するようなオプションが用意されています。
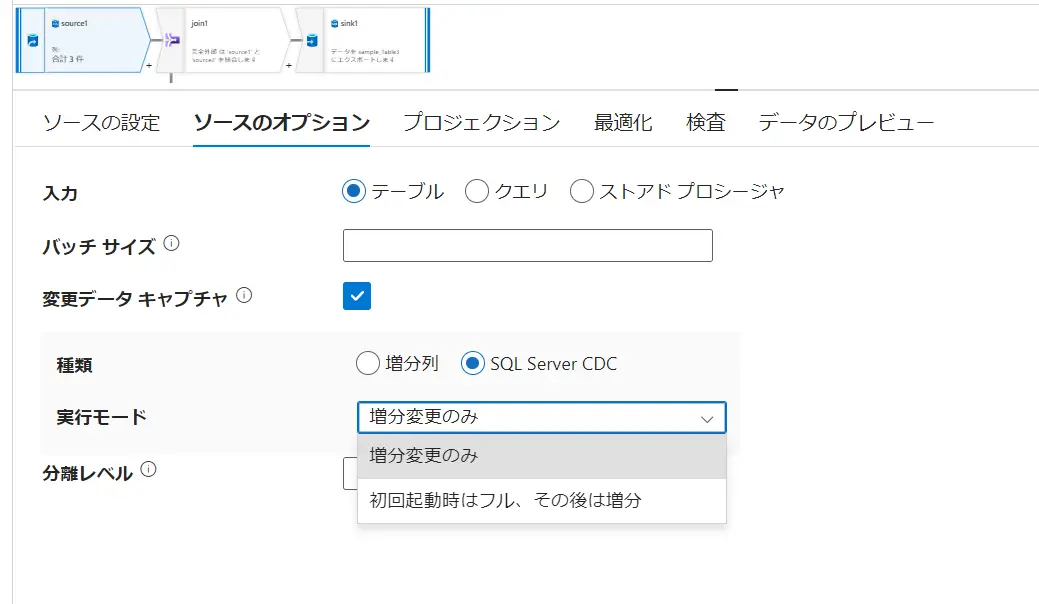
SQL Database はネイティブ変更データキャプチャをサポートしており、以下添付した画面の変更データキャプチャにチェックをすると、ネイティブ変更データキャプチャが有効となります。
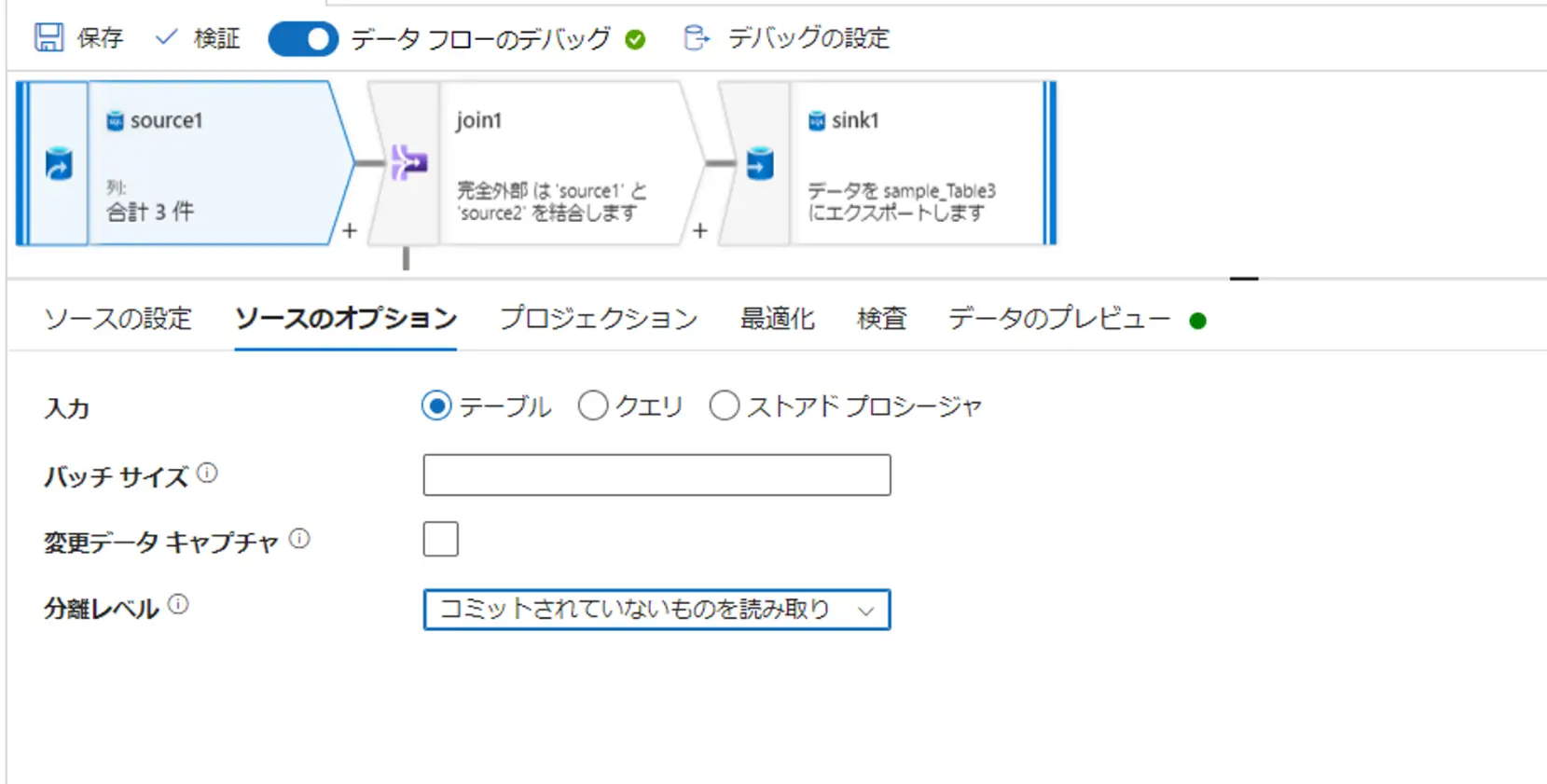
変更データキャプチャの設定は、コネクタ側で事前の準備が必要です。例えば、SQL Database における CDC の利用は、増分列か、SQL Server CDC です。SQL Server CDCは、SQL Server 上から変更データキャプチャの有効化を行う必要があります。
--データベースへの CDCの有効化
USE <Database-name>
GO
EXEC sys.sp_cdc_enable_db
GO
--有効化の確認
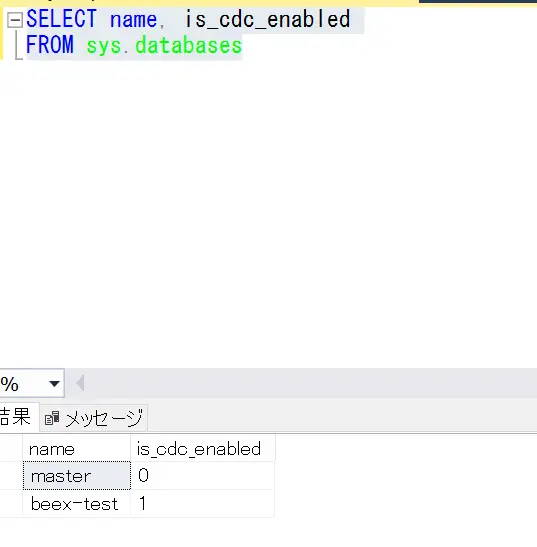
SELECT name, is_cdc_enabled
FROM sys.databasesまず、データベース上で有効化されたデータベースは 1 を返します。
テーブルレベルにおける CDC の有効化には、ストアド プロシージャ sys.sp_cdc_enable_table を使用します。有効化したいテーブル名を入れて CDC を有効化します。
sp_helptext 'sys.sp_cdc_enable_table';
--テーブルレベルでの有効化
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'table-name',
@role_name = N'role-name',
@filegroup_name = NULL ,
@supports_net_changes = 1
GOこれらを行う事でシステムテーブル上にいくつかCDCにテーブルが生成されます。
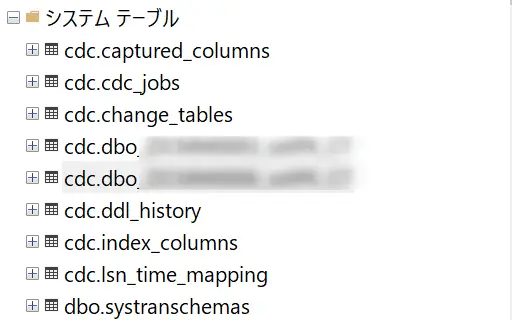
なお、下記の記載の通り、対象テーブルには、主キーか一意のインデックスが必要となります。
差分変更のクエリをサポートするには、行を一意に識別するための主キーまたは一意のインデックスがソース テーブルに必要です。 一意のインデックスを使用する場合は、 @index_name パラメーターを使用してインデックスの名前を指定する必要があります。 主キーまたは一意のインデックスで定義した列は、キャプチャするソース列の一覧に含まれている必要があります。
ここまでが、SQL Server 側での準備です。これらの設定を行う事で ADF からネイティブ変更データキャプチャ設定を行う事が出来ます。これを行わないと、変更データキャプチャをセットしたデータフローのプレビュー画面でエラーが出力されるようです。
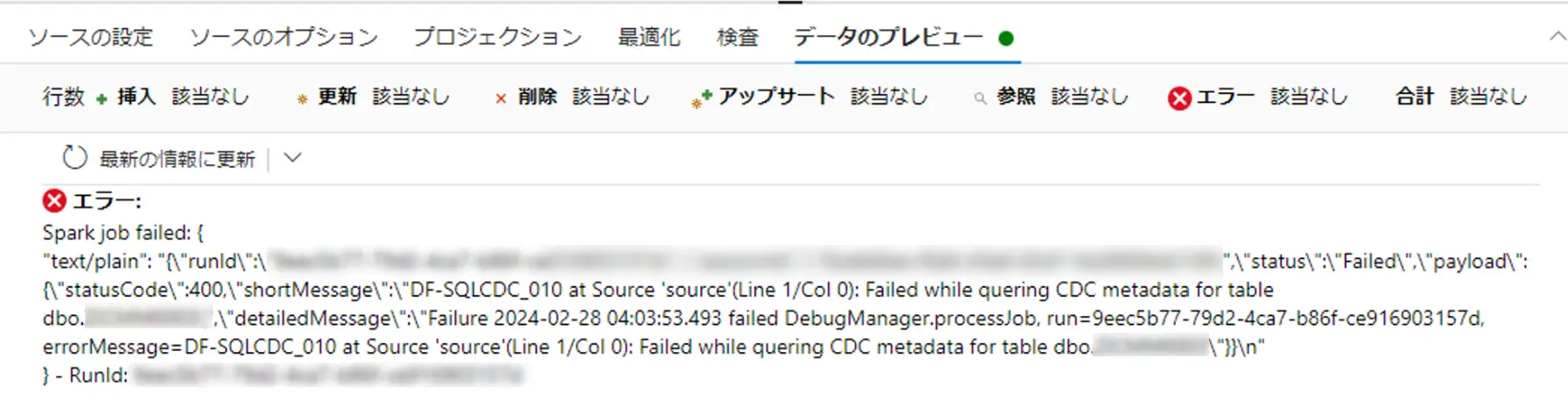
SQL Server CDC における 実行モードは、増分変更か 初回起動時はフル、その後は増分を選択し、ETL 処理を行います。ADF における CDC の動作挙動は、シナリオを多く構成出来る分、複雑であるため事前に挙動確認を行う事を推奨します。
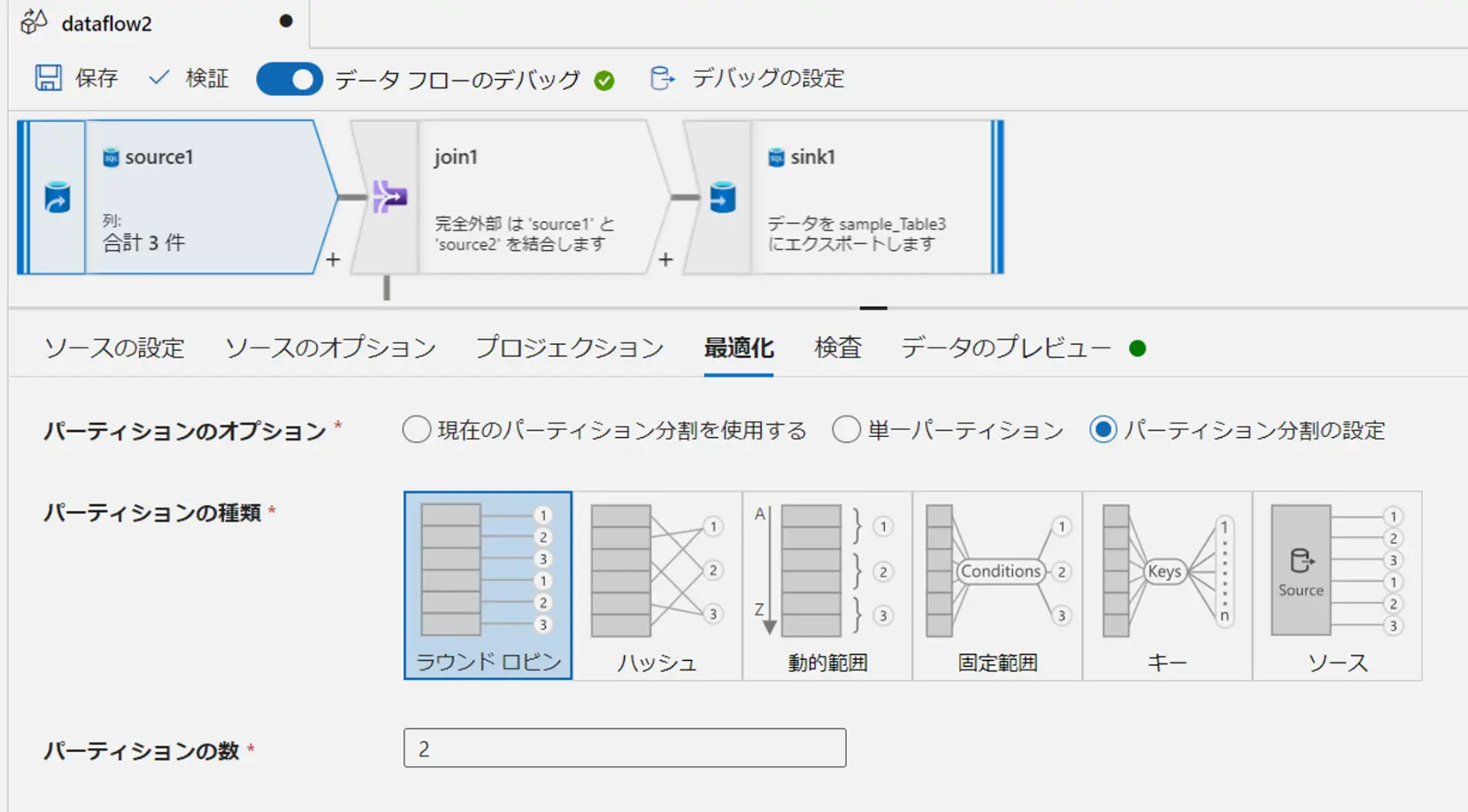
Source の設定項目に戻ります。最適化設定では、パーティションをセット出来ます。ここに寄与する要素は実行のパフォーマンスです。
- Apache Spark クラスターのスピンアップ(起動時間)
- Source の読み取り
- 変換処理時間
- Sink への書き込み
最適化設定は、変換処理のいずれにも存在し、変換後にデータのパーティションの再分割を行うかどうかを指定するものです。
既定は、現在のパーティション分割を使用するが選択されており、ほとんどのケースにおいては、この設定が推奨されているようです。理由はパーティション再分割自体に、時間を要するためです。なお、有用なケースとして、以下のケースとなるものと言及されていますが、実際に最適な方法を選定する場合は、変換処理後のデータ配置の理解と、分散システムにおけるパーティショニングに関する十分な理解を要するケースになると思います。
データを再パーティション分割するシナリオとしては、集計と結合の後にデータが大幅に歪む場合や、SQL データベースでソース パーティション分割を使用する場合などがあります。
Transformation
続いて、Source と Sink の間に入る変換処理です。抽出、集計、変換、条件分岐、あるいは検出を担う多様な処理が可能であり、Azure Data Factory では、これら処理を視覚化して定義する事が可能です。
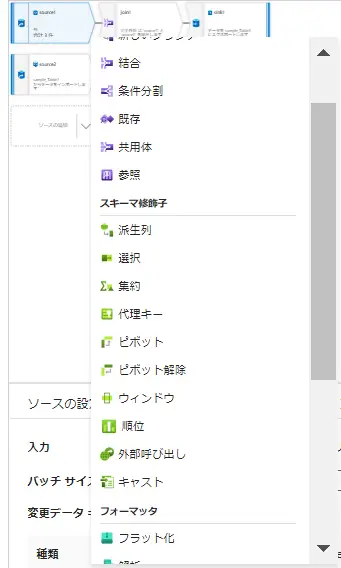
変換処理においては、式ビルダ―を活用するケースが多く存在します。
式ビルダ―とは、ADFの実行時に Spark のデータ型として評価される列の値とパラメーター、指定が可能な関数(あるいはUDF)、演算子と値で構成されます。
また、処理を言語化してコメントアウトする事が可能です。
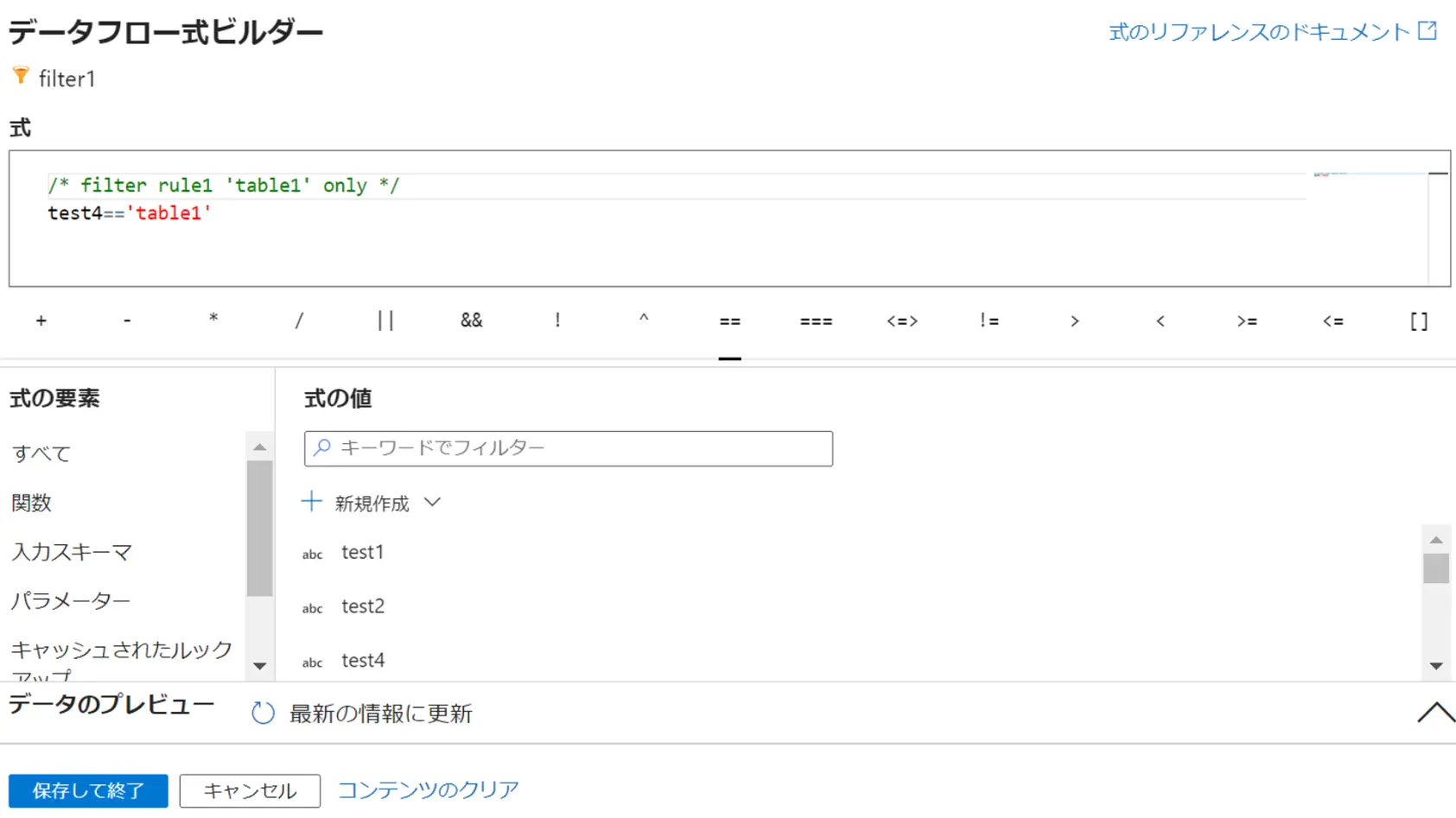
Transfomation の一例として、Assert / Change Row Policy / Split を見ていきます。
Assert 変換は、予想された入力に対して、一定の基準を満たしているかどうかをチェックする品質と検証を目的とした処理です。
Expect True / Expect unique / Expect exists というアサートの種類から適切なルールを定義していきます。
Expect True では、true を予期する範囲を検証します。下記例では、toDate 関数として文字列の日付へ変換して、Isnull関数 により 結果が NULL かどうかをチェックするエクスプレッションを定義しています。Expect True における結果出力は Bool 型である必要があるため、結果は ture or false です。
isNull(toDate(Date,'yyyyMMdd'))
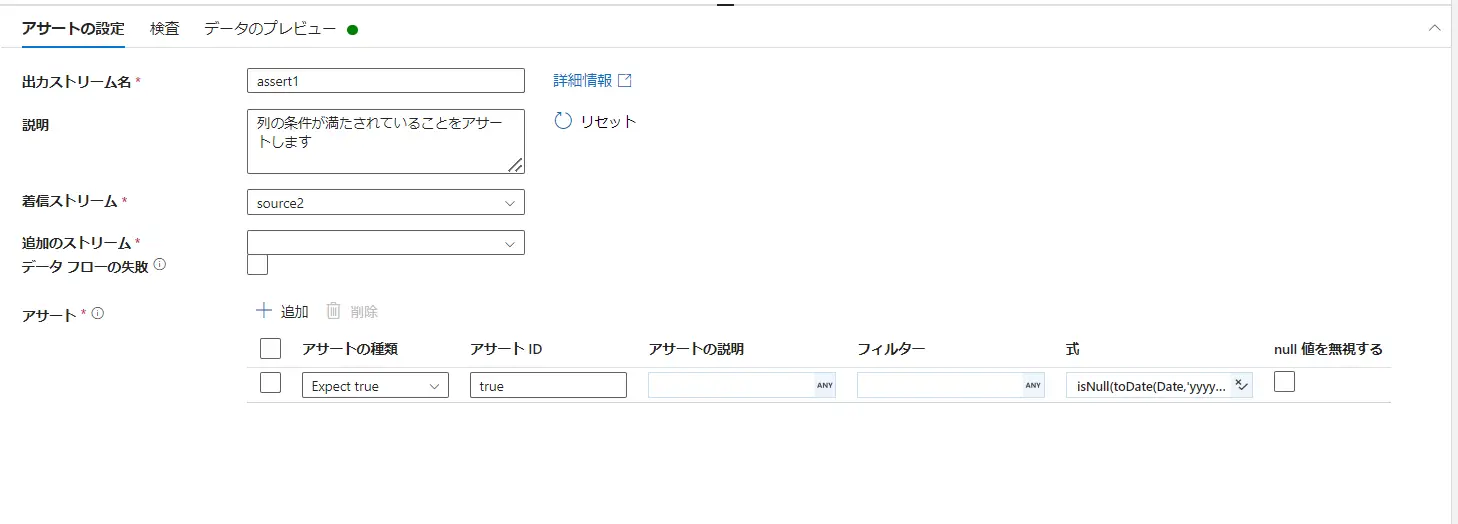
アサート構成パネル では、アサーションに失敗した行を表示します。toDateに失敗した列 ×が付いています。
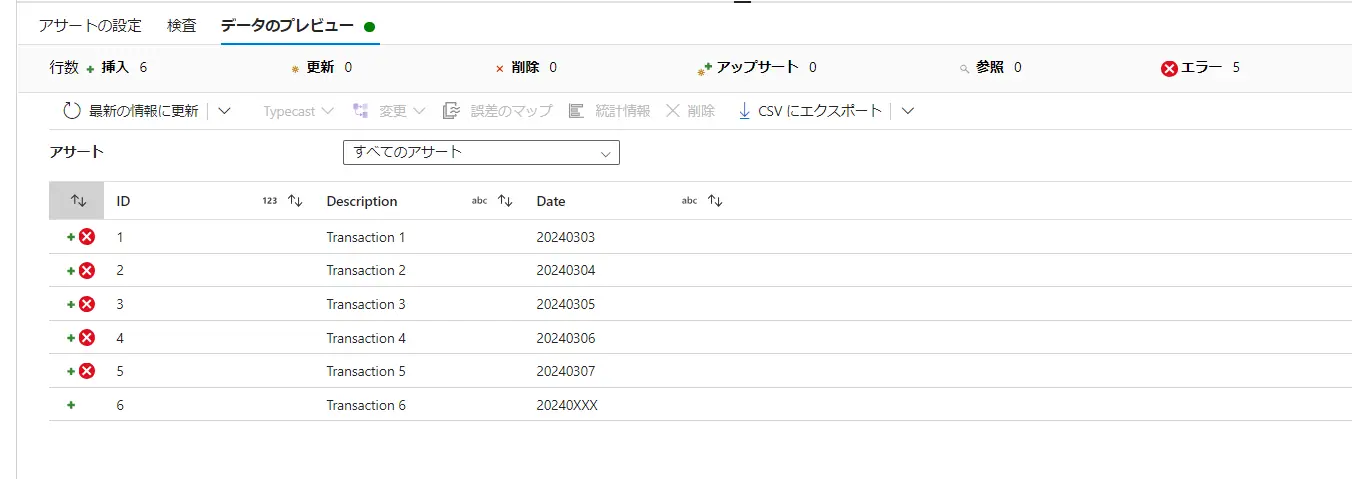
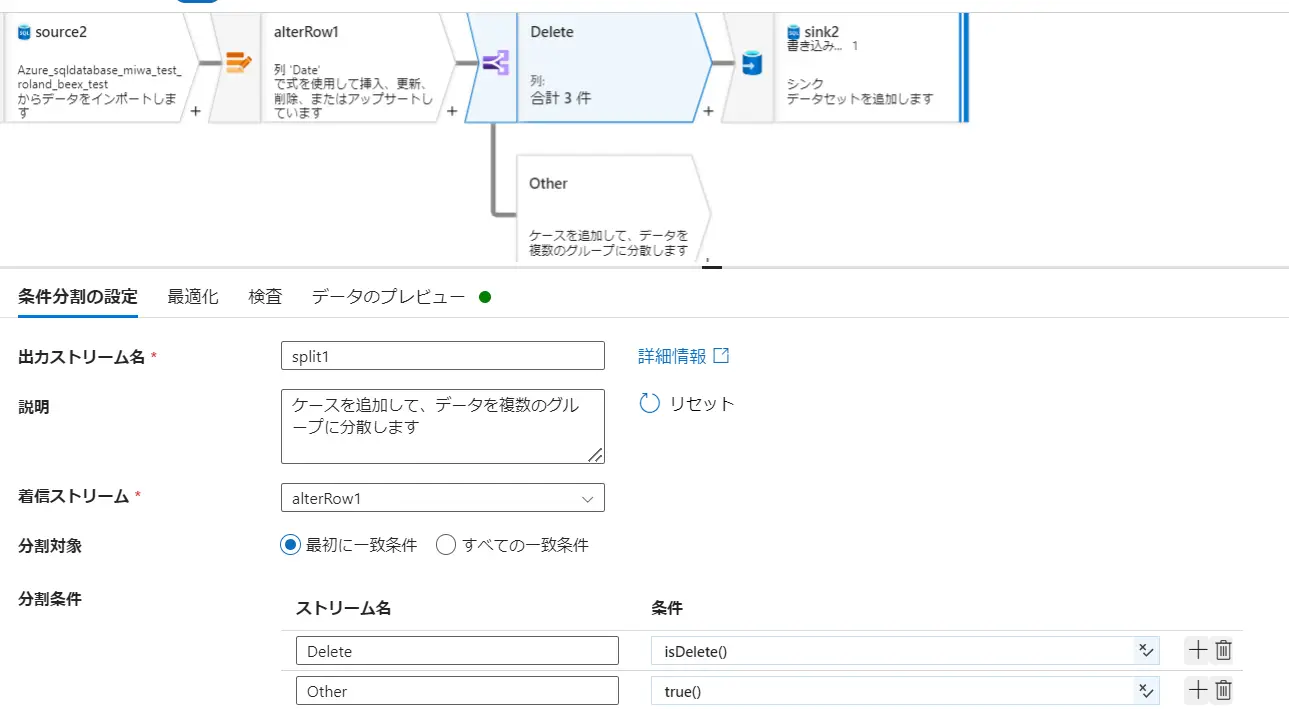
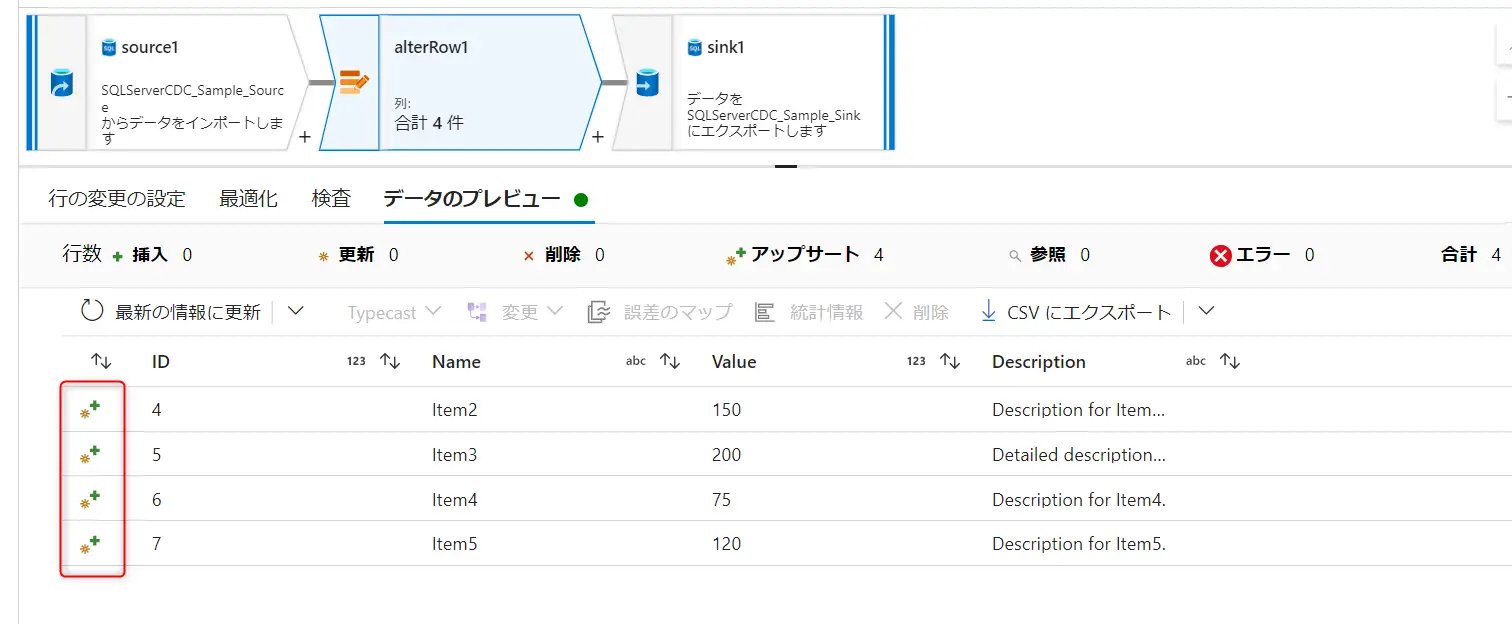
Change Row Policyでは、行の変更条件を指定して、条件に合致する場合に挿入 / 削除 / 更新 / upsert を行う事をデータフロー内で定義します。この条件は複数指定が可能であり、優先度は上から順に評価されます。
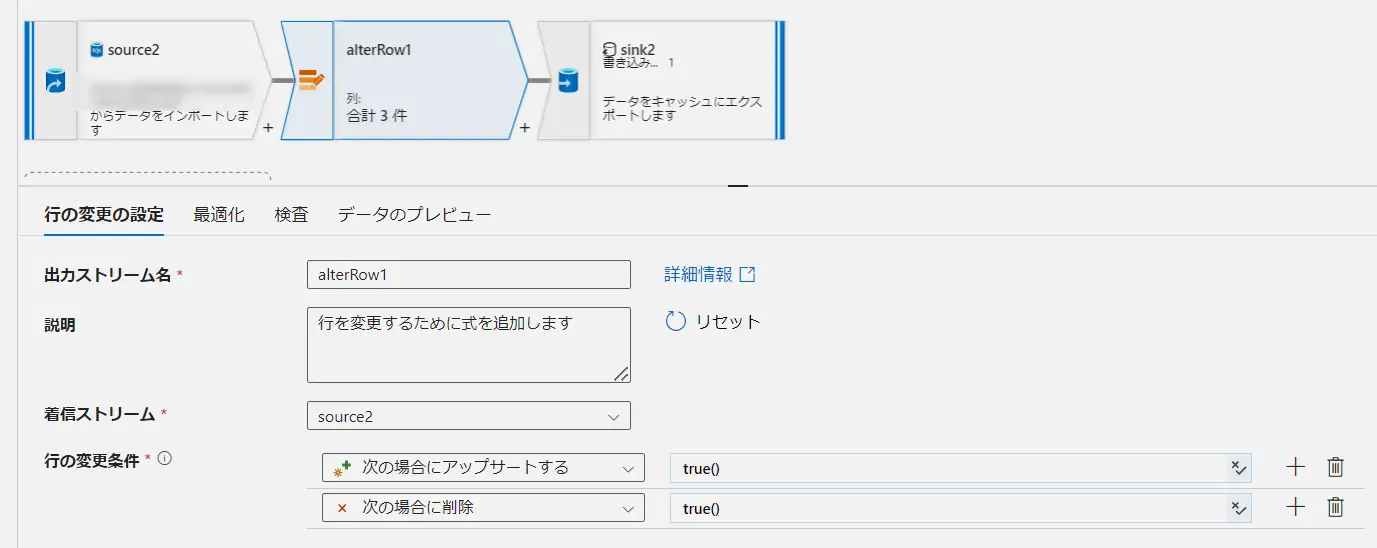
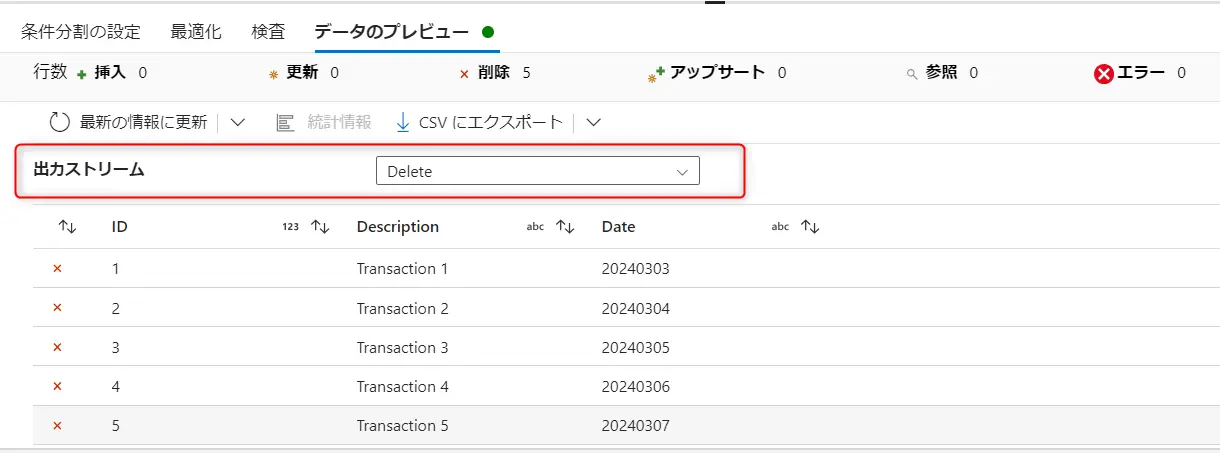
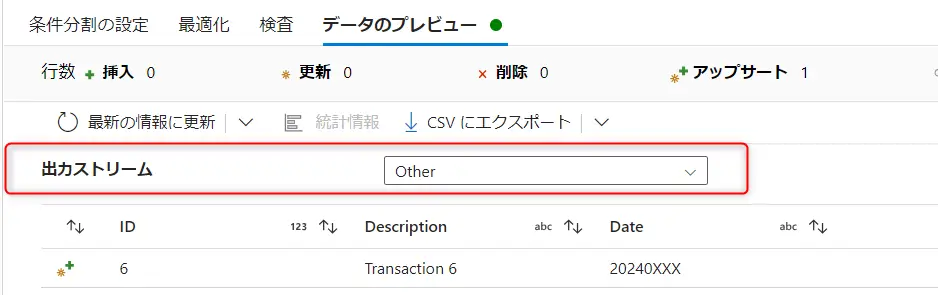
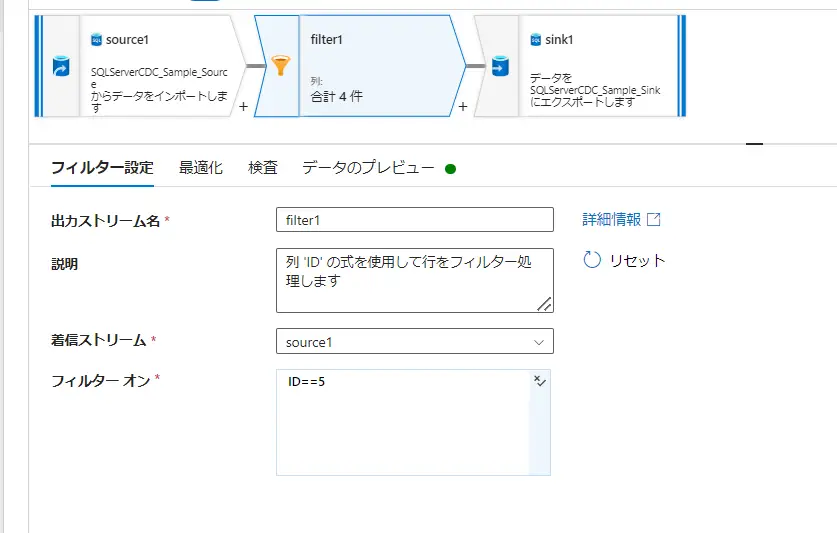
既定は、どの条件式にも一致しない行を Insert としてマークします。行の変更ポリシーにおける条件を true() とする事で、Insert 以外の処理においても全てのレコードに処理を許可します。これらのポリシーの結果については、データのプレビューからレコードレベルでの確認が出来ます。以下のケースでは、ID 1-5 までに削除を許可し、ID6へ upsert を許可します。
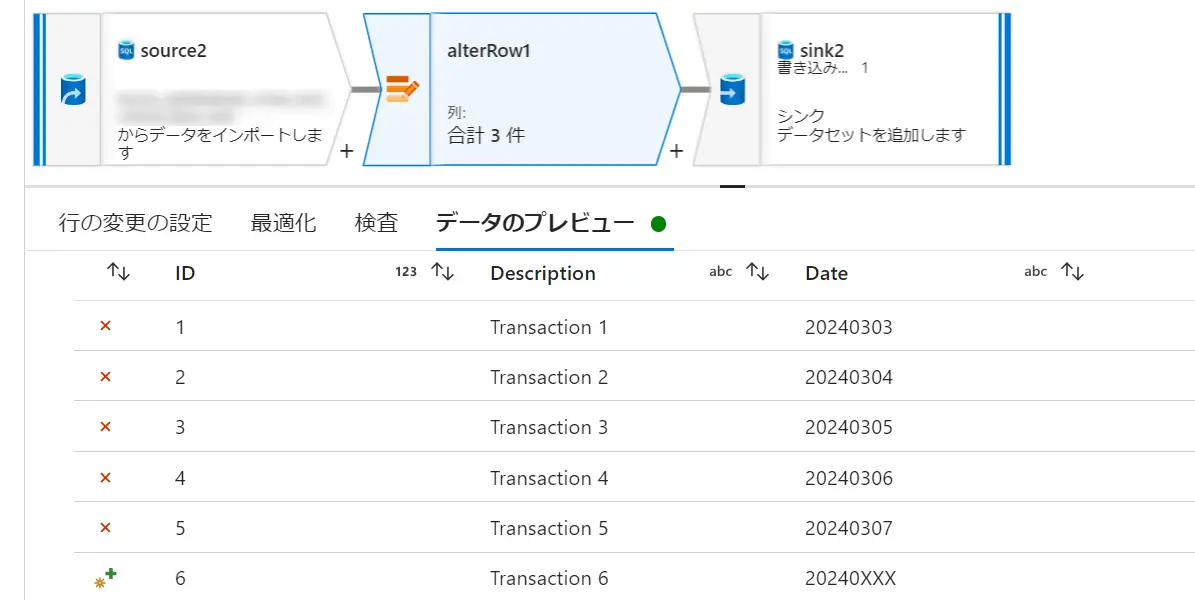
isDelete() 関数は、行が削除用にマークされているかどうかをチェックする関数です。例えば、上記の様に削除マーカーがチェックされたレコードと upsert 用のレコードを split する事が出来ます。ここにおけるストリームとは、Source2 や alterrow1 などの処理ブロックを意味しており、入力は input 、出力は output を意味します。
 なお、ネイティブ変更データキャプチャにおいては、行マーカーが自動検出されるため、行の変更ポリシーについては不要となります。
なお、ネイティブ変更データキャプチャにおいては、行マーカーが自動検出されるため、行の変更ポリシーについては不要となります。
行の変更変換は、SQL Server や SAP などのネイティブ CDC ソースを使う変更データ キャプチャ データ フローには必要ありません。 それらのインスタンスでは、ADF によって行マーカーが自動的に検出されるため、行の変更ポリシーは必要ありません。
データフローにおける Transformation のレイヤは様々な処理があり、処理の組み合わせによって実現できる事が多くあるかと思います。こちらは次回執筆の際もご紹介できればと思います。
Sink
最後に Sink を定義します。Sink は Source と異なり、データセット or インラインデータセット or キャッシャを選択肢として出力先に指定して動作します。
キャッシュ(シンク)とは、Spark キャッシュにデータを書き込むケースです。
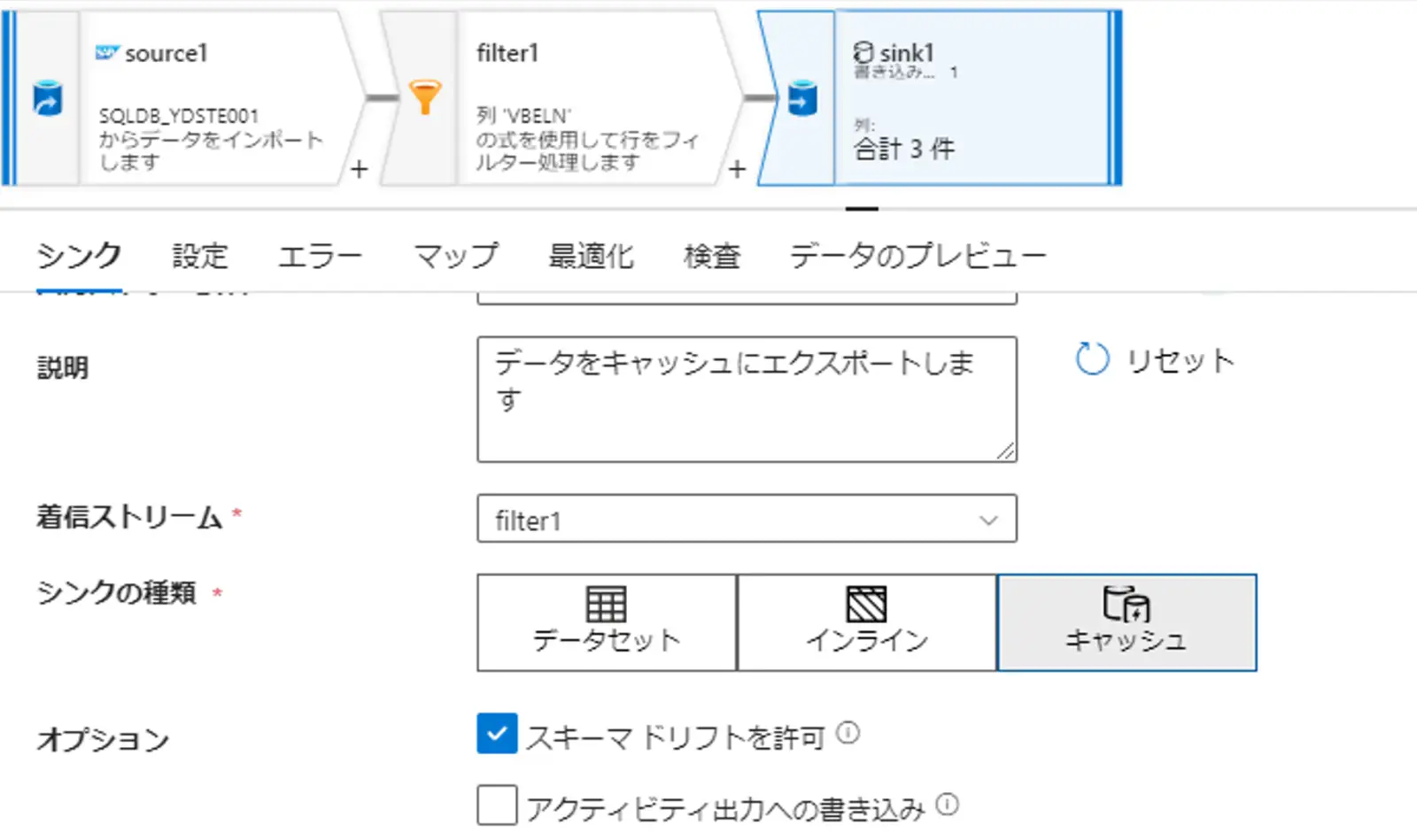
キャッシュシンクを利用して、同じデータフロー内で式ビルダ―からキャッシュの値を参照する場合の lookup() 関数から取得するキー列を指定します。あるいは、outputs()関数を指定して、複数の配列をキャッシュシンクとする場合は、キー列を使用しません。
キャッシュ シンクのユースケースは、データ ストアで特定値を検索する、エラー コードをエラー メッセージ データベースと照合することが挙げられるようです。
設定については、Source 同様 Sink 先としたコネクタによって、項目が異なります。
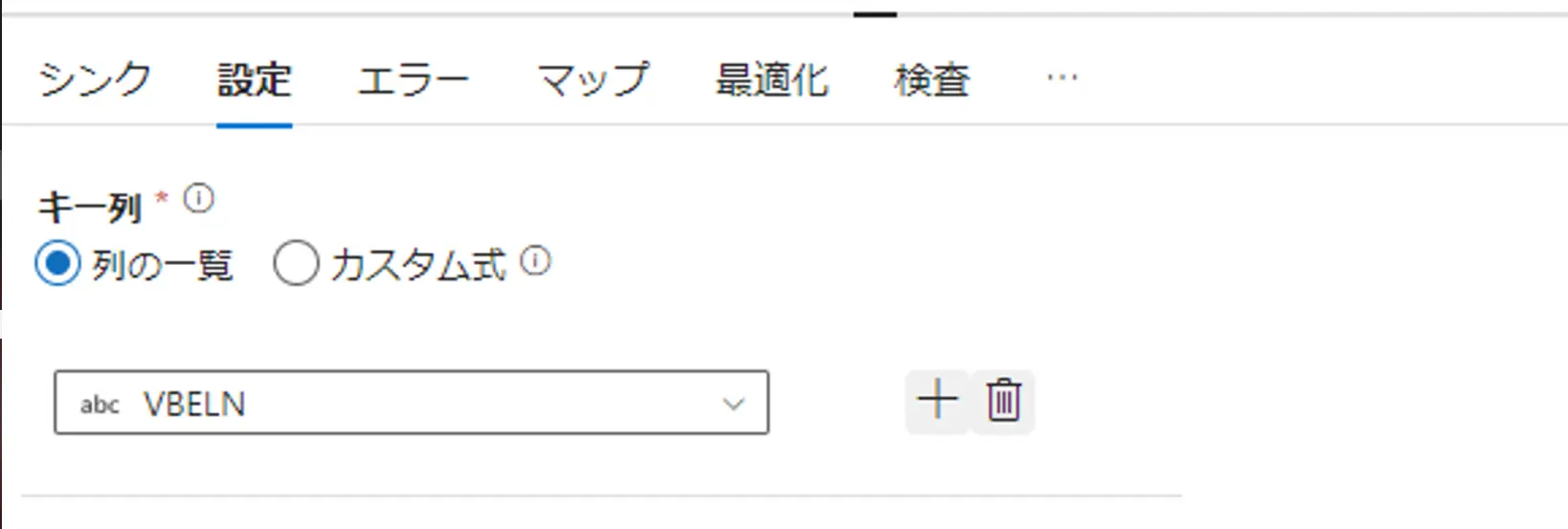
例えば、Sink が Azure SQL Database の場合、更新方法、更新をキー列、キー列の書き込みスキップが存在します。キー列は複数指定可能です。また、SQL Server のキー設定に関与せず、Azure DataFactory のみが認識するキー列をここへ定義します。例えば、複数キーによって構成される一意の値をここへ指定する事で、Source からのUpsert 取り込みを再現します。
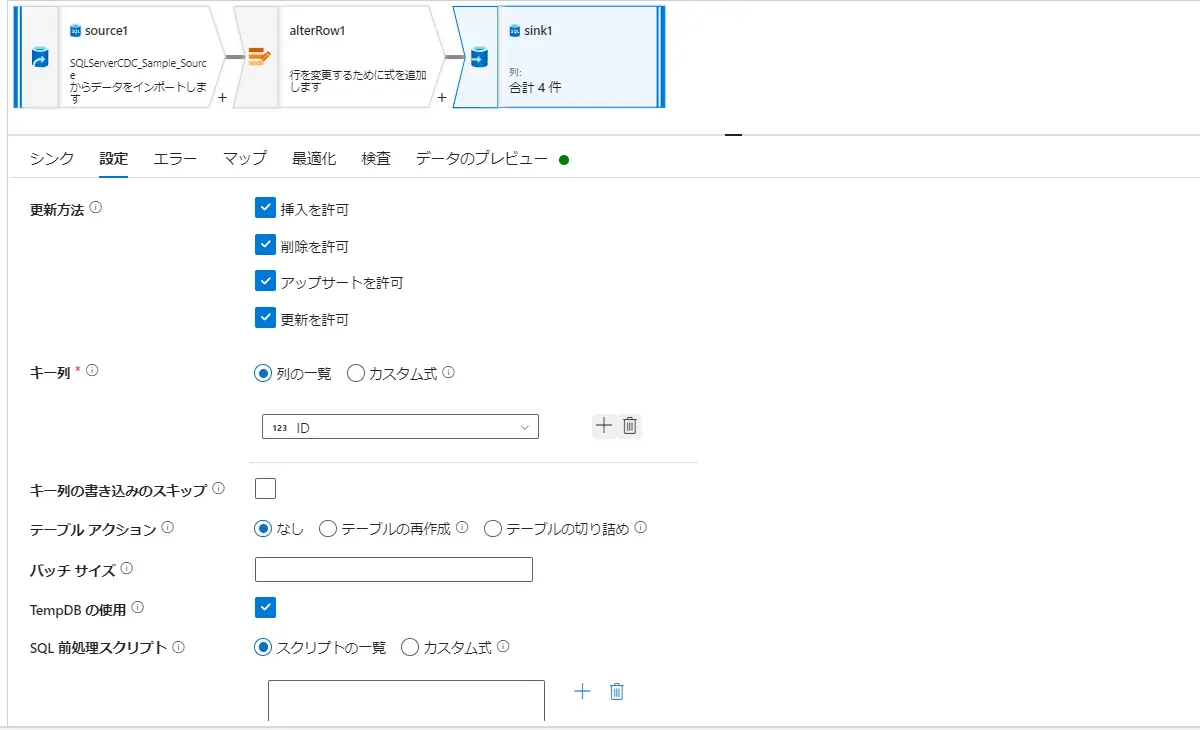
テーブルアクションでは、Sink 側で処理の取り込み前に実施されるアクションを選定するものです。テーブルの再作成はテーブルが drop され、新しいスキーマ定義をしたテーブルを Sink 先として定義でき、テーブルの切り詰めでは、Truncate を実施して、取り込みを行います。
なお、テーブルアクションを指定した場合における前段の変換・加工処理は、有効として判定されるようです。例えば、テーブルアクションで指定したテーブルの切り詰め前の Filter 処理は有効判定として適切に処理されるというものです。
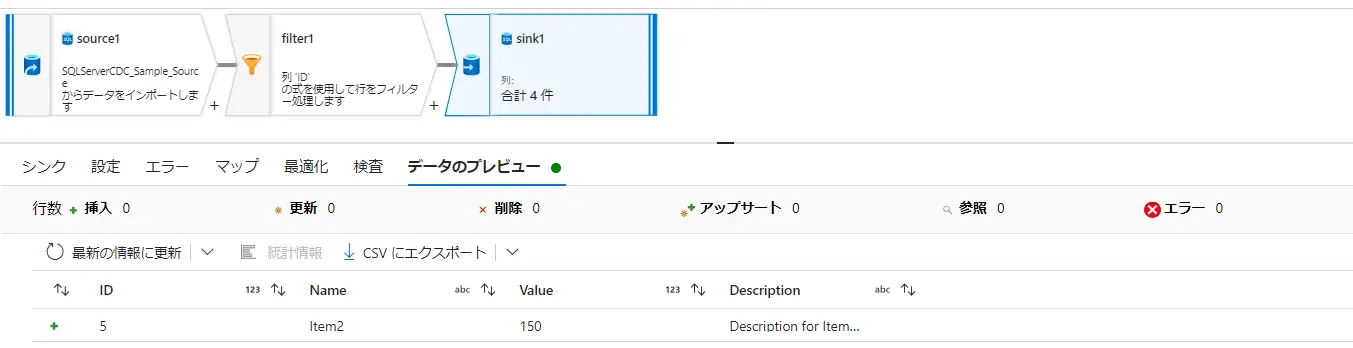
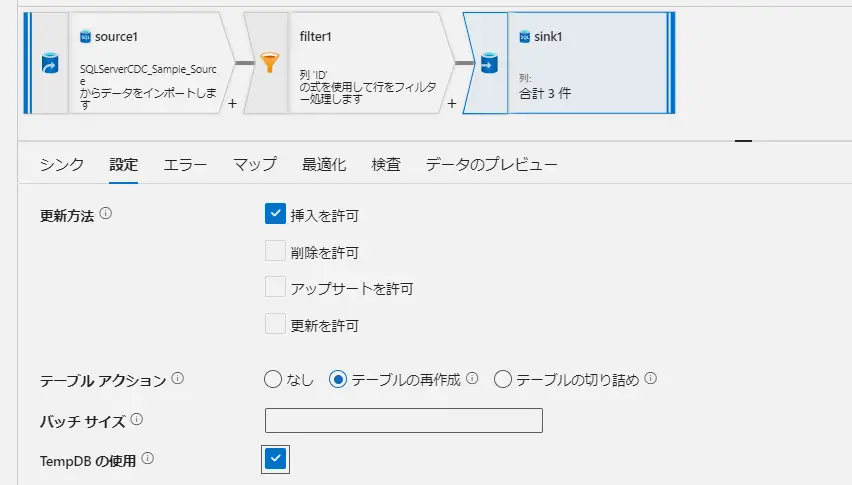
tempdb の利用の設定については、グローバル一時テーブルを使用するか、ステージングとして使用するテーブルを指定する事が出来ます。大量データの読み込み時に指定のステージングを選定する事が有効であり、デフォルトは ON します。
マップの設定は、マッピングデータフローにおいて、一番重要な設定項目かと思います。
デフォルトでは自動マッピング機能がONとなっており、スキーマドリフトの誤差範囲列を含む、入力列名と出力列名を自動比較して、マッピングが行われます。
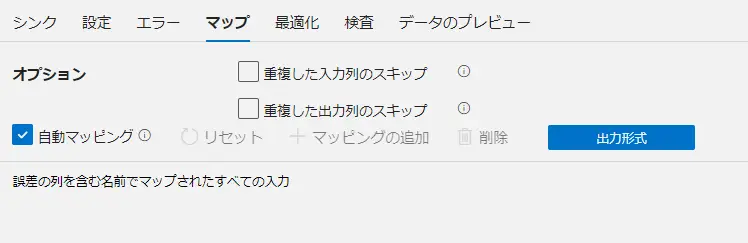
自動マッピングを行わず、手動でマッピングの定義をする事も可能です。
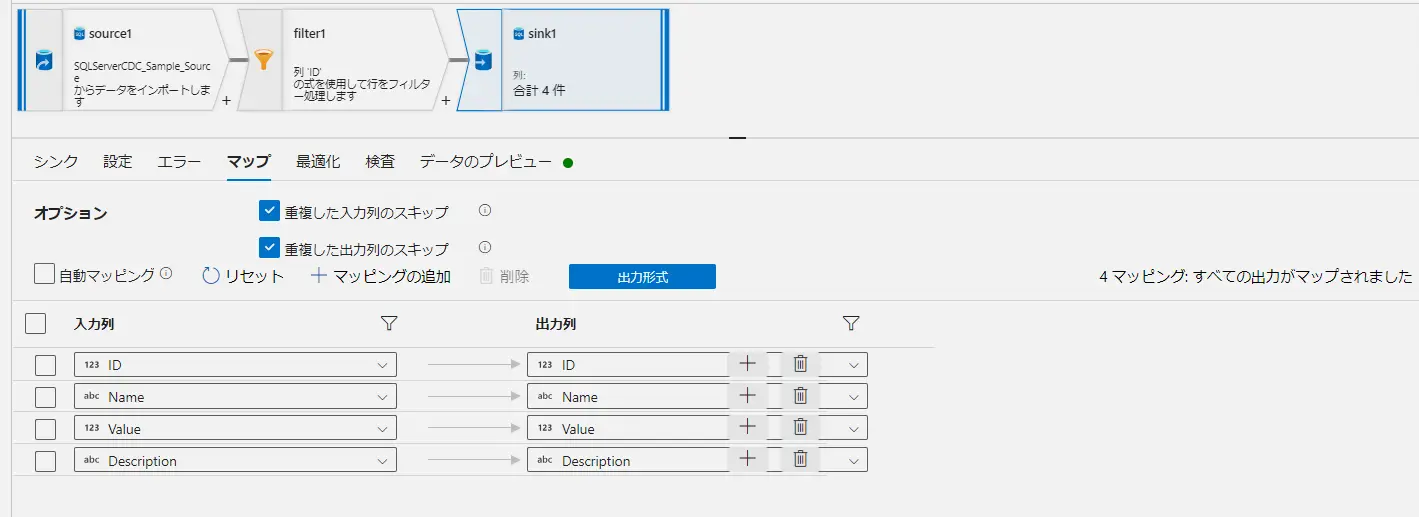
マッピングは、入力列出力列、データストアに存在する列を全て入れる必要はありません。以下は、上記のマップにある Description 列を入力出力からいずれも抜いたマップです。このケースにおけるデータフローの結果は、Description列へ NULL が入ります。つまり、定義する必要もない列を Data Factory 上で認識させる必要はなく、その場合に、対象外とした列には値は特に入らないというものです。
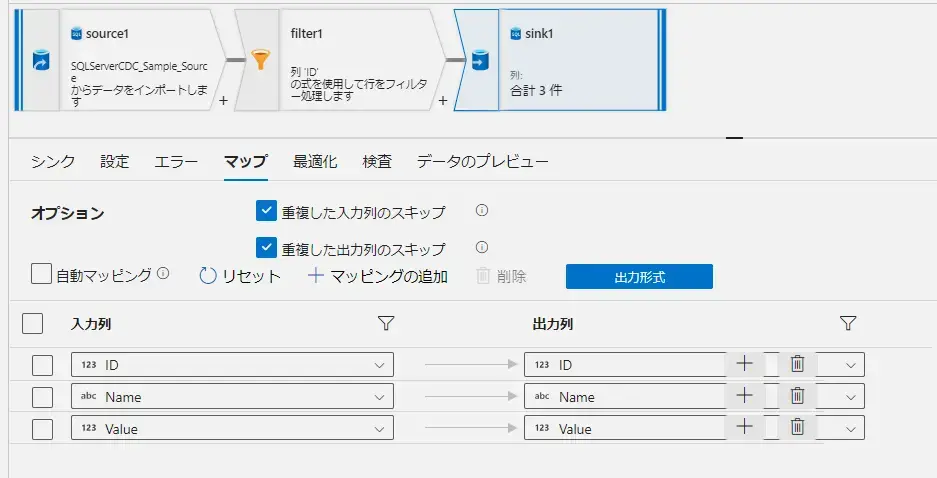
Intractive
ADF はプレビュー機能が抽象化され、Data Factory Studio から開発を実施する際の補足機能としてスピードを促進します。
データフローにおけるプレビューは、デバッグモードとして機能します。データフローにおいて結果の照合をインタラクティブに確認する場合、タスクの実行を行わずに、デバッグモードを有効化し、データのプレビューから確認するものが一般かと思います。また、即時に確認したいケースにおいて、インラインデータセットは指定リンクサービスから手動入力をしてデータストアの反映の確認が可能なため、これも有用です
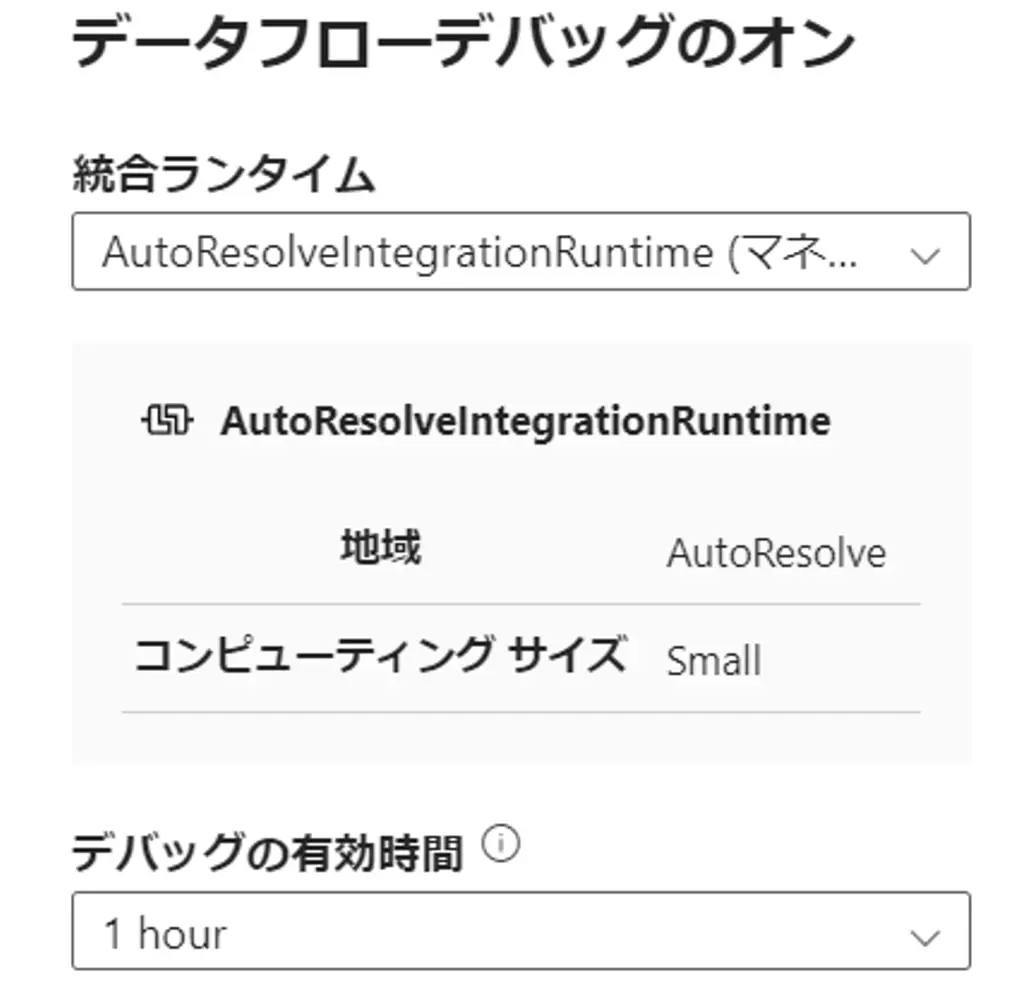
デバッグモードでは、ADF がバックグラウンドで、対話的にデータフローを構築するために Spark クラスターを一時的に使用します。これにおける有効化は指定した統合ランタイム、AutoResolveIntegrationRuntime を含む Azure IR を使用する事が可能です。但し、Azure IRではコールドスタートとなるため、Time to Live を調整するか、AutoResolveIntegrationRuntime による迅速な確認を行うものが良いと考えられます。
下記例のように、デバッグの有効時間を指定して動作するため、ここで発生する料金と指定時間を超えた場合に自動的にオフとなる事に注意が必要です。
データのプレビューは、Source のみならず全ての処理単位に視覚化をする事が出来るタブです。ここを閲覧するために上記、デバックモードを有効化しておく必要があります。
以下は、Source のデータのプレビュー画面です。ここでは3列2行で構成されたテーブルを読み取っており、この結果をプレビューを通じて表示させています。なお、この結果はいずれもCSVとして出力可能です。
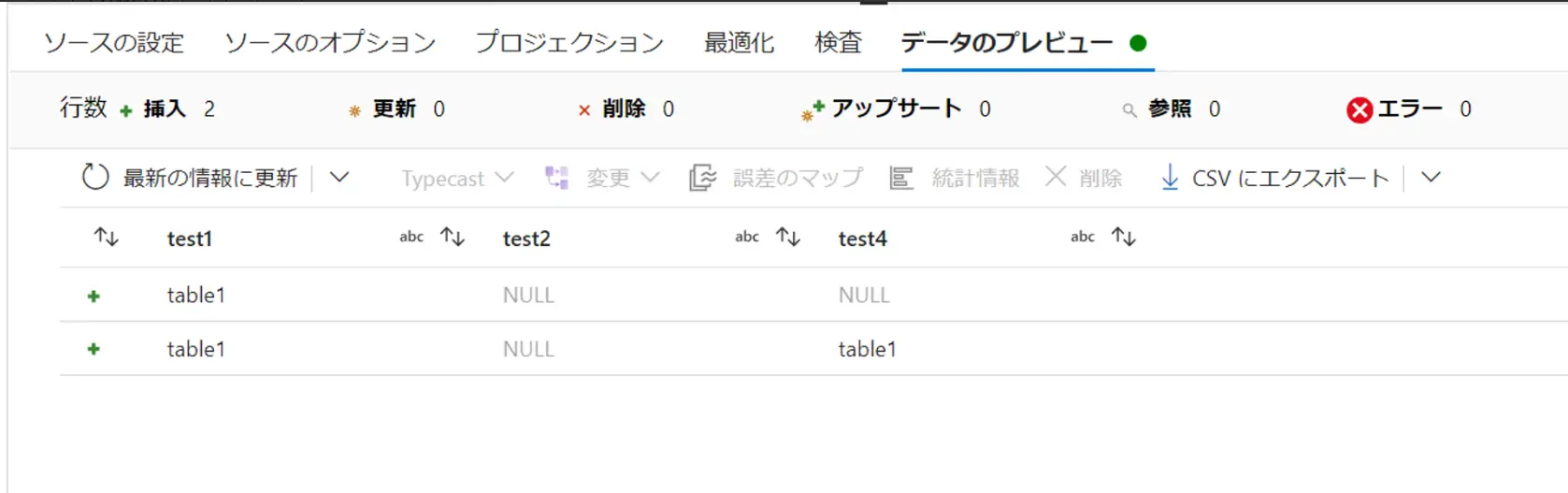
データのプレビューは、先述の通り、各処理のブロック単位に表示可能なタブです。例えば、Source におけるデータのプレビューは、接続先のデータストアの情報を、加工変換無しに取得します。データフロー全体から見ると、Before のイメージにあたるかと思います。また、結果の取得には、プロジェクションやデータセットのインポートが必要です。
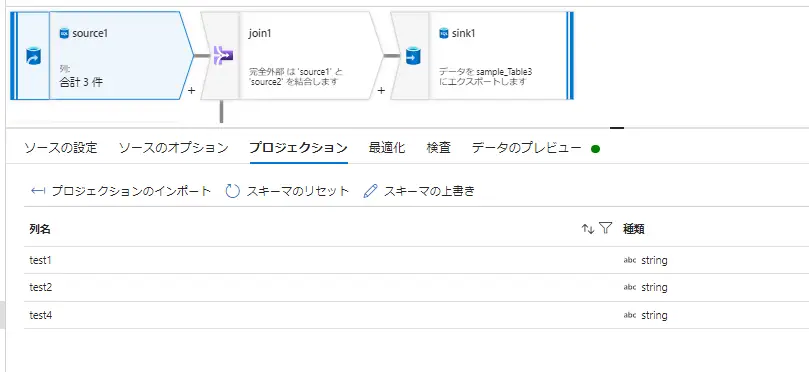
一例として、Source - Filter - join - Sink におけるデータのプレビューを見ていくと、以下の様に、処理後の結果反映を即時に取得し、表示します。
Source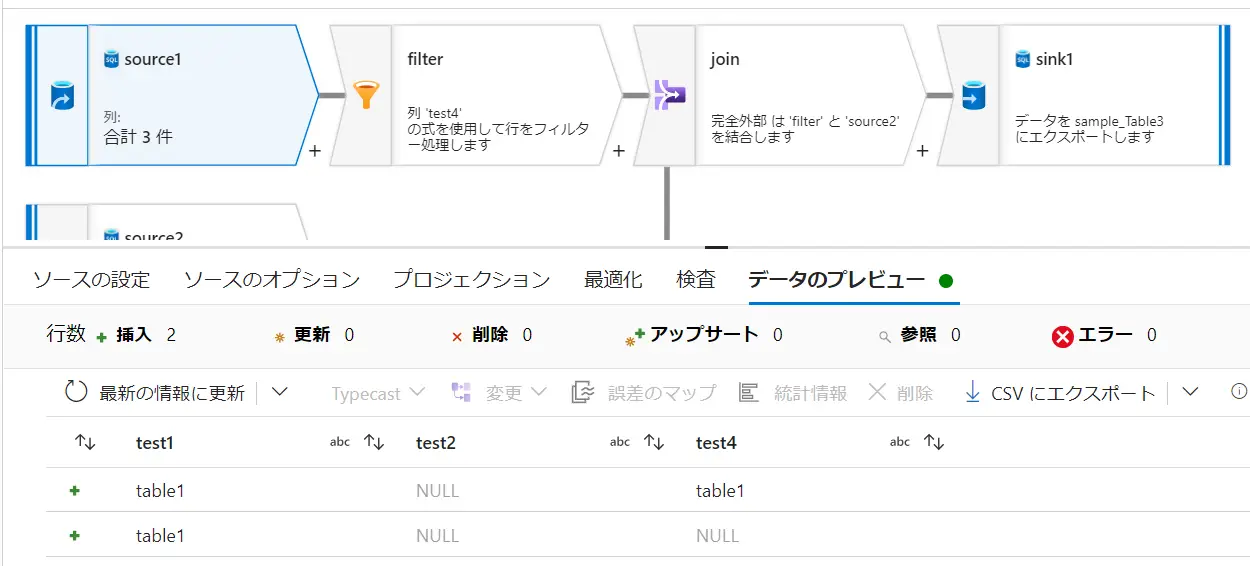
Filter ( test4=='table1')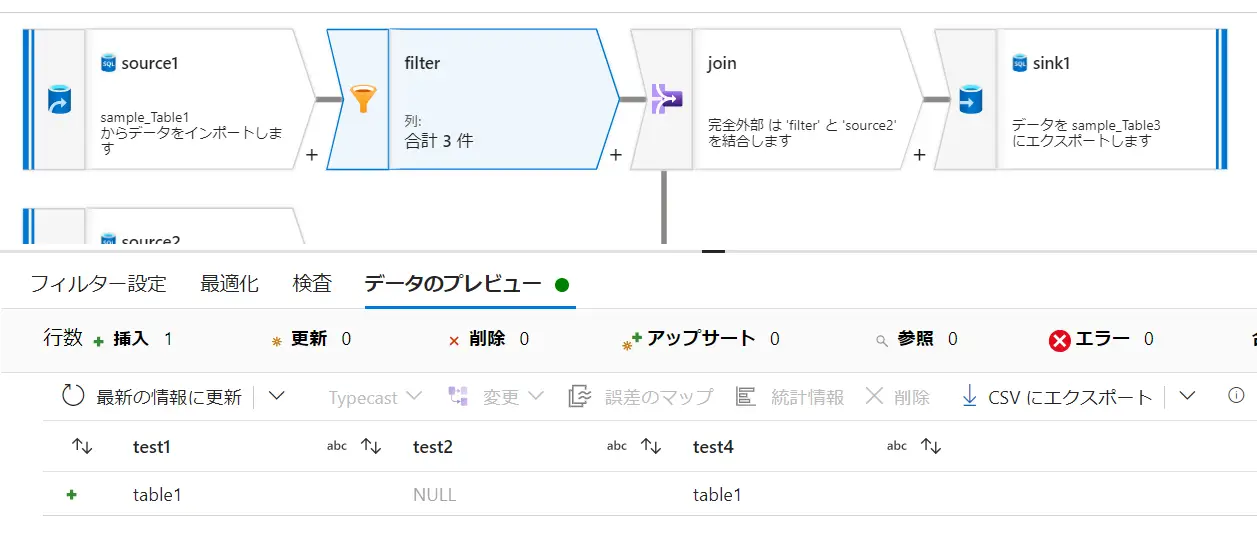
Join ( outer join on test1 == test1) 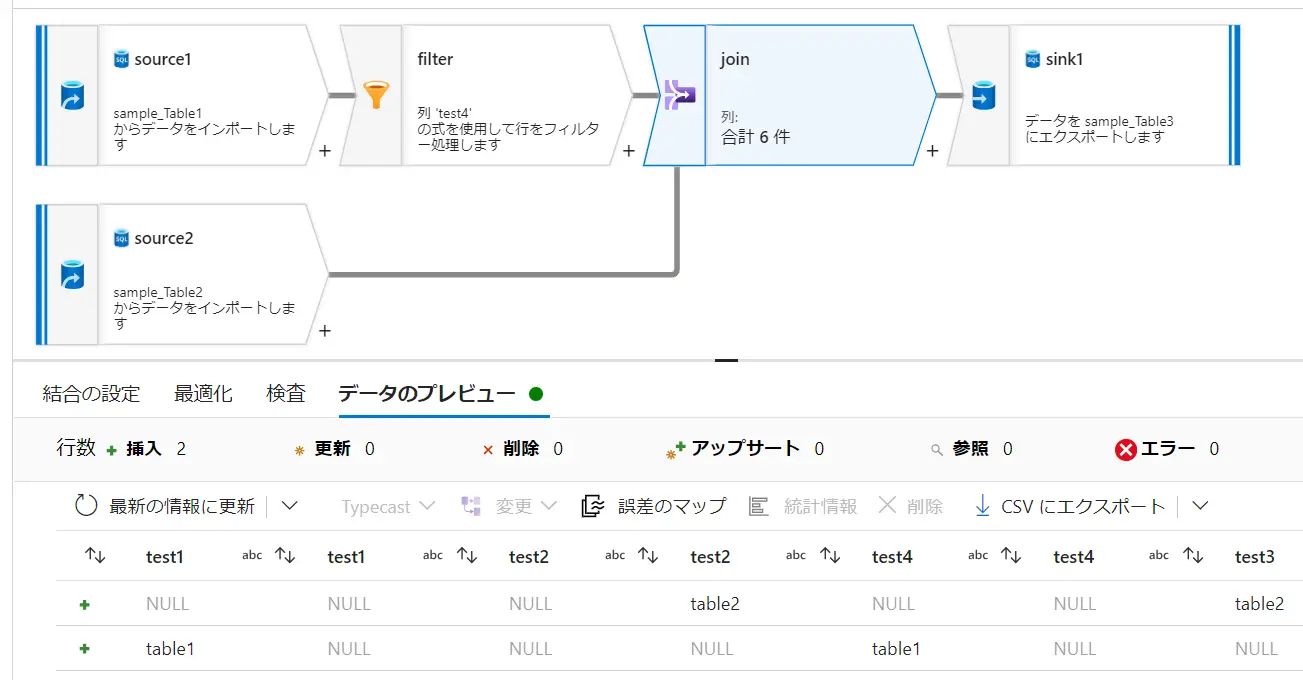
Sink (Cachesink) 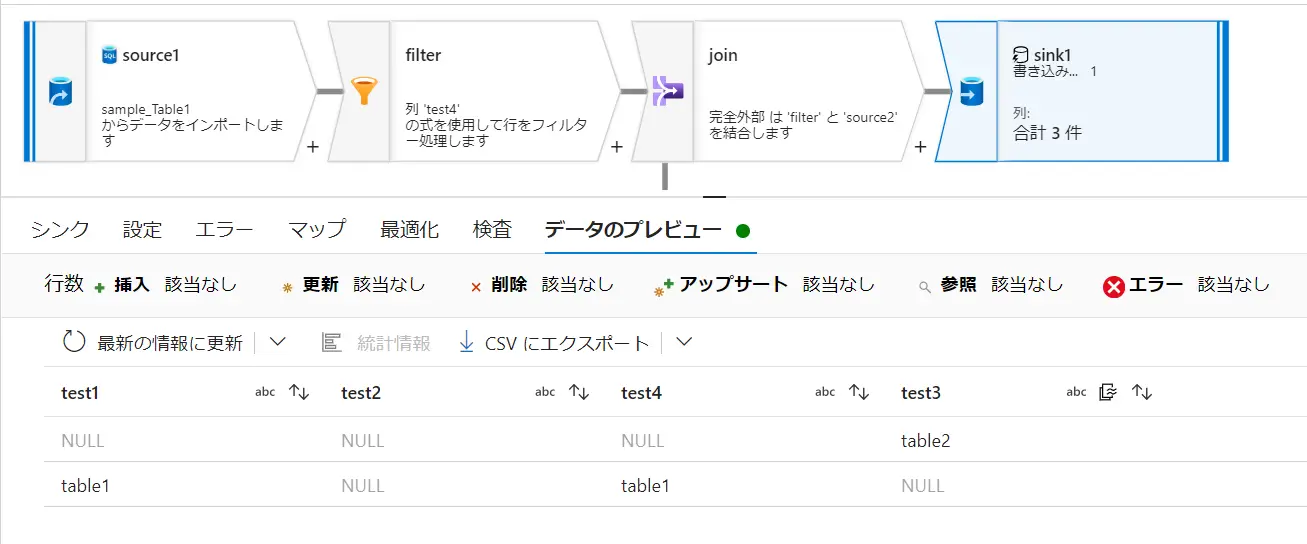
また、処理行の変換には、処理の種別をフラグとして認識する事が出来ます。例えば、行の変更ポリシーにおける、処理の条件を追加する事で、データのプレビューから upsert マーカーが認識されます。
For Pipeline
最後にパイプラインについてです。本稿では、データフローアクティビティにおけるパイプライン処理について記載を致します。
作成されたデータフローは、パイプラインにより実行されます。ここにおける設定項目について確認をしていきたいと思います。データフローを一つのアクティビティとしてみた場合に、いくつかパイプラインの設定下から制御が行えます。アクティビティの状態を非アクティブとすると、パイプライン上から対象のアクティビティを実行せず、成功、失敗、スキップの任意のマーカーとして後続処理へ渡す事が出来ます。複数アクティビティが存在するパイプラインから特定の検証を行うケースで有用となるかと思います。また、一つのアクティビティに対して、アクティビティポリシーを設定する事が出来ます。これは、タイムアウト時間を設ける事や、最大再試行回数を制御、secureOutput にあたる、監視用ログの非出力が出来ます。
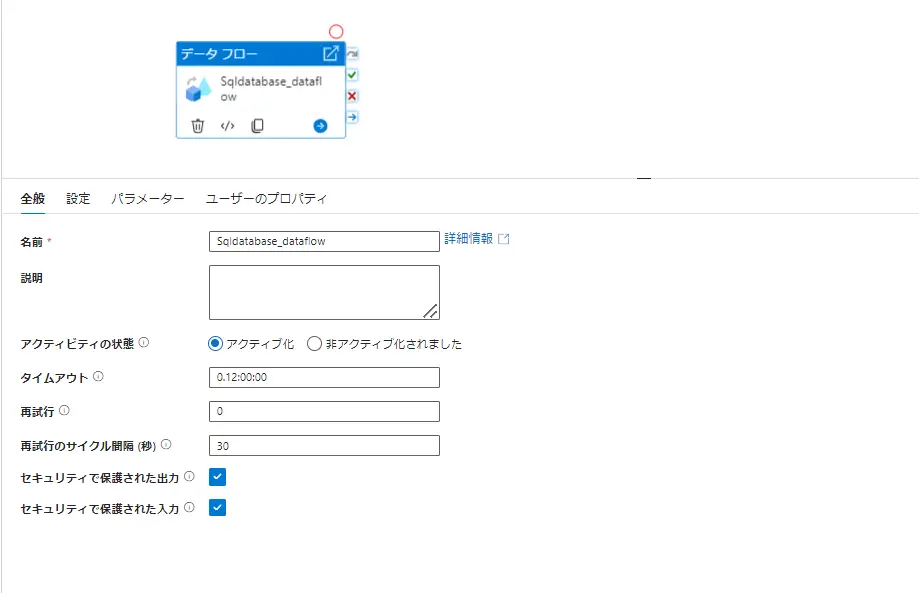 なお、これらはアクティビティ毎に設定されるものです。例えば、データフローが連動するパイプラインにおいても個別の設定が可能です。
なお、これらはアクティビティ毎に設定されるものです。例えば、データフローが連動するパイプラインにおいても個別の設定が可能です。
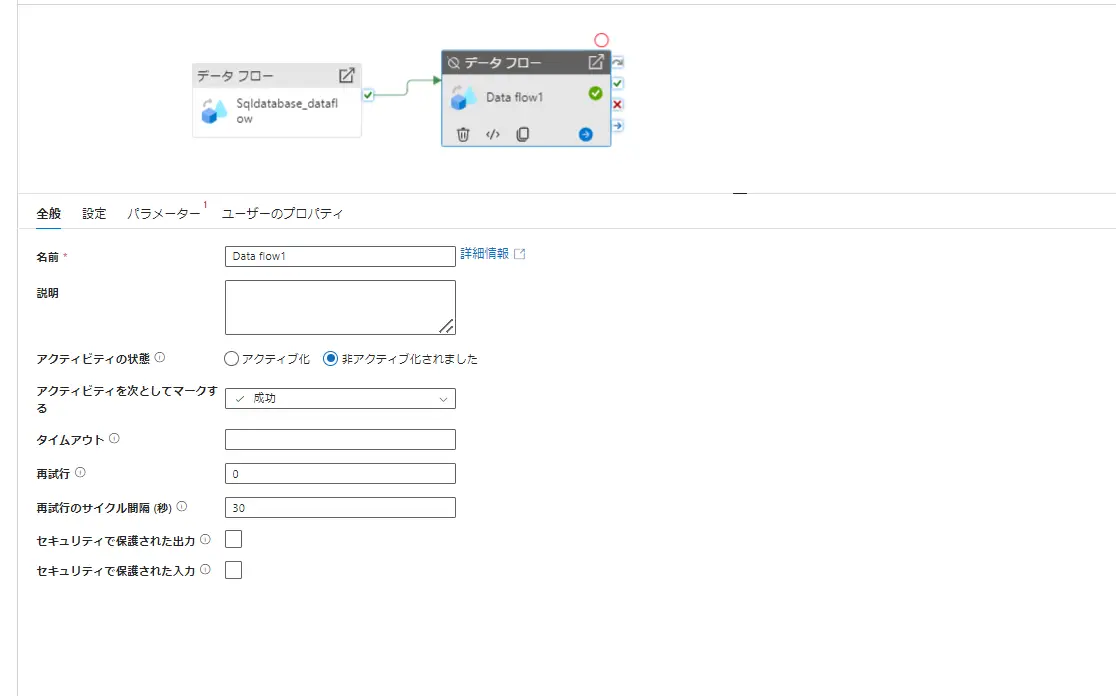
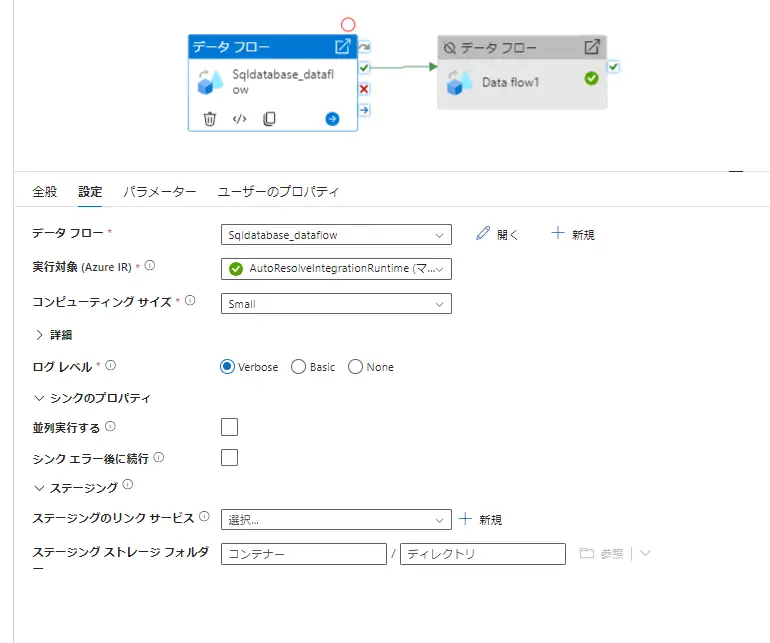
では、続いてデータフロー固有の設定となります。データフローの対象を選んだ後、実行対象を選定します。データフローにおいては既定では AzureIRを使用します。ログ記録レベルは、デフォルトでパーティションレベルの記録を行う verbose となっています。トラブルシューティングにおいては有用となるかと思いますが、Basic または None への変更はパフォーマンス向上が見込まれる可能性があるようです。
Synapse Analytics におけるステージング、または SAP ODPフレームワークを使用したSource をデータフロー内で実装している場合、ステージングのリンクサービスを指定する必要があります。下記例は、SQL Database のため割愛致します。
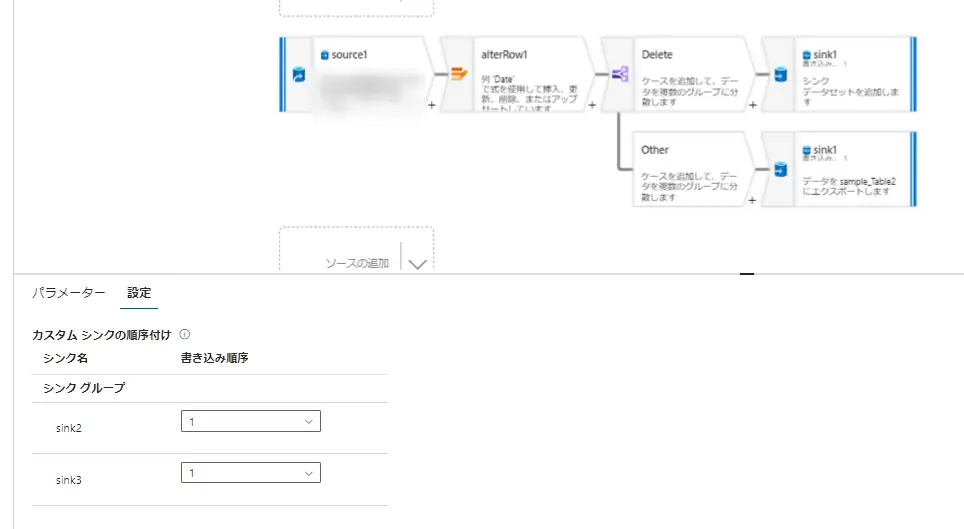
 データフローには、シンクグループという、Source が同一にあたる条件分割された複数のシンクに対して同じ順序を適用する事でグループ化される機能があります。先述のシンクのプロパティにおける並列実行は、グループ化されたデータフローを並列実行化するかどうかを選択する事が出来ます。但し、これらは同じストリームからの処理でないと不可能なため、注意が必要です。
データフローには、シンクグループという、Source が同一にあたる条件分割された複数のシンクに対して同じ順序を適用する事でグループ化される機能があります。先述のシンクのプロパティにおける並列実行は、グループ化されたデータフローを並列実行化するかどうかを選択する事が出来ます。但し、これらは同じストリームからの処理でないと不可能なため、注意が必要です。
ここまでがパイプラインにおけるデータフローアクティビティのご紹介となります。
本稿は以上となります。次回も引き続き Data Factory に関する記事を執筆します。
最後まで御覧いただきまして、ありがとうございました。
- タグ

この記事をシェアする





