











目次
Target Reader
本記事は Amazon QuickSight Enterprise Edition のアーキテクチャおよび 機能のご紹介を中心に執筆を致しました。Amazon QuickSight の導入をご検討中の方、Amazon QuickSight 設計者向けの記事となります。
OverView The Amazon QuickSight
Amazon QuickSight は Amazon Web Services(以下 AWS) における BIサービスです。
多様なデータストレージへアクセスし、データの組み合わせを自由に表現します。公開されたダッシュボードは閲覧者へ鮮彩なビジュアルと共に適切な分析結果を提供する事が出来ます。
Architecture
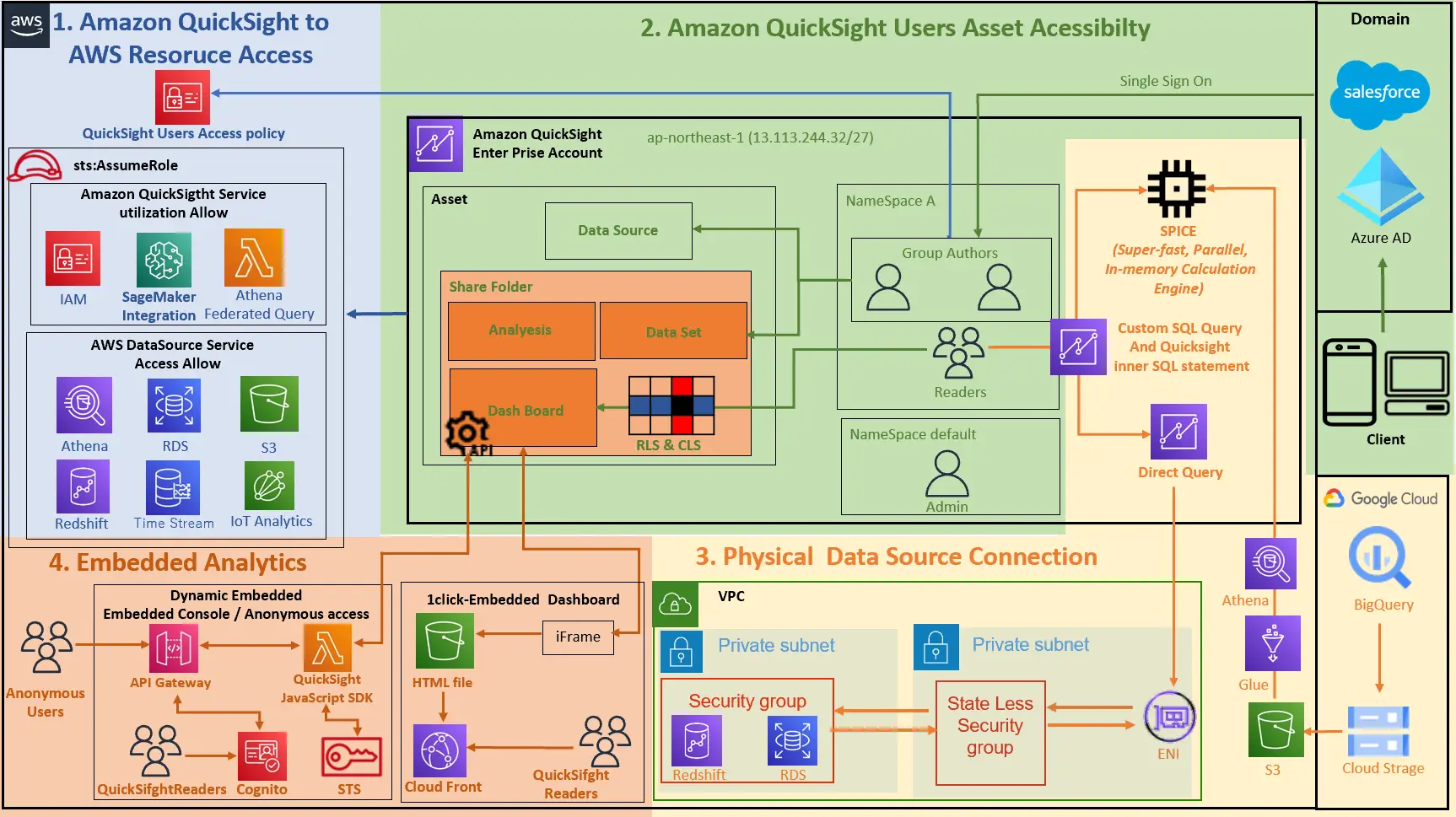
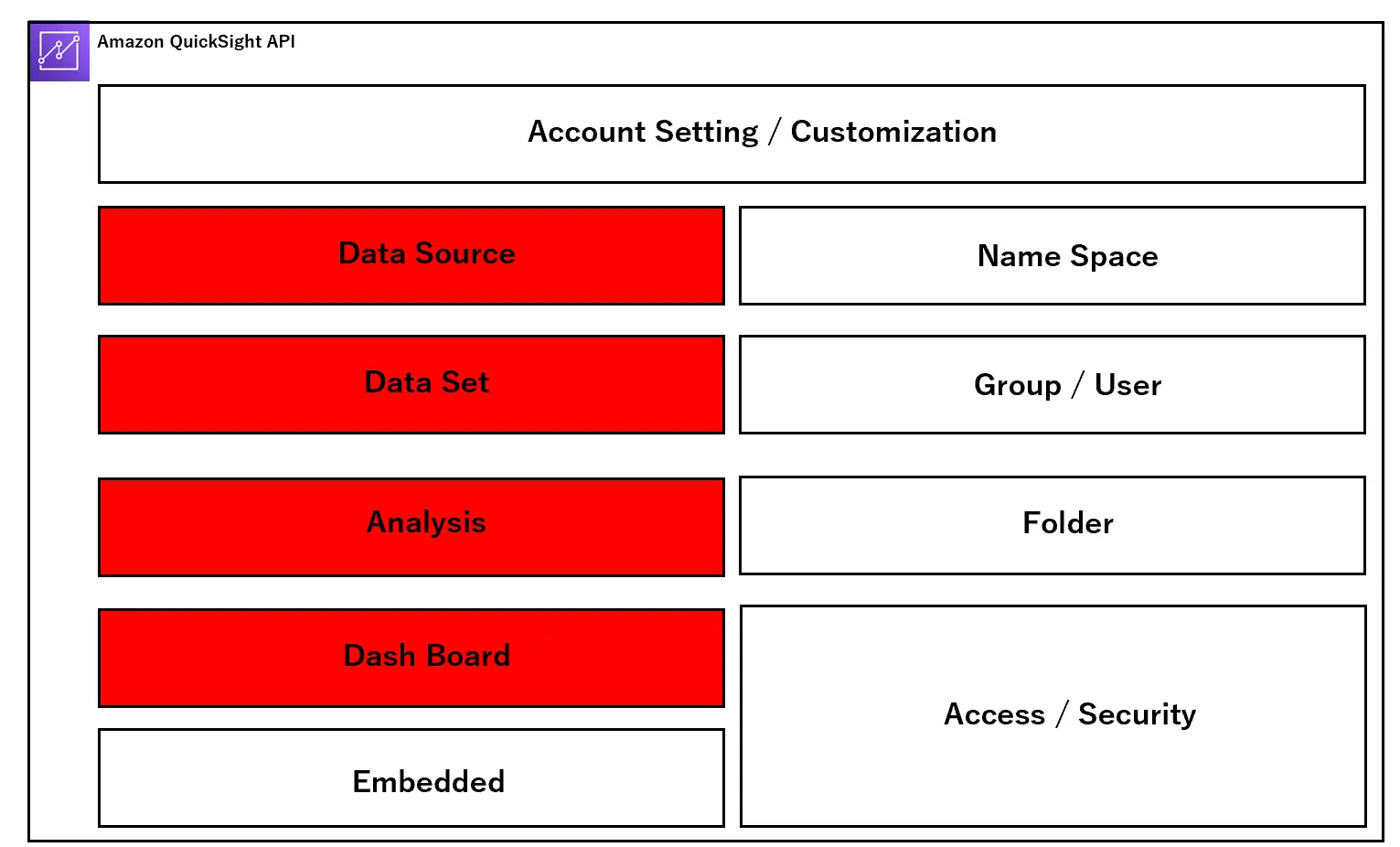
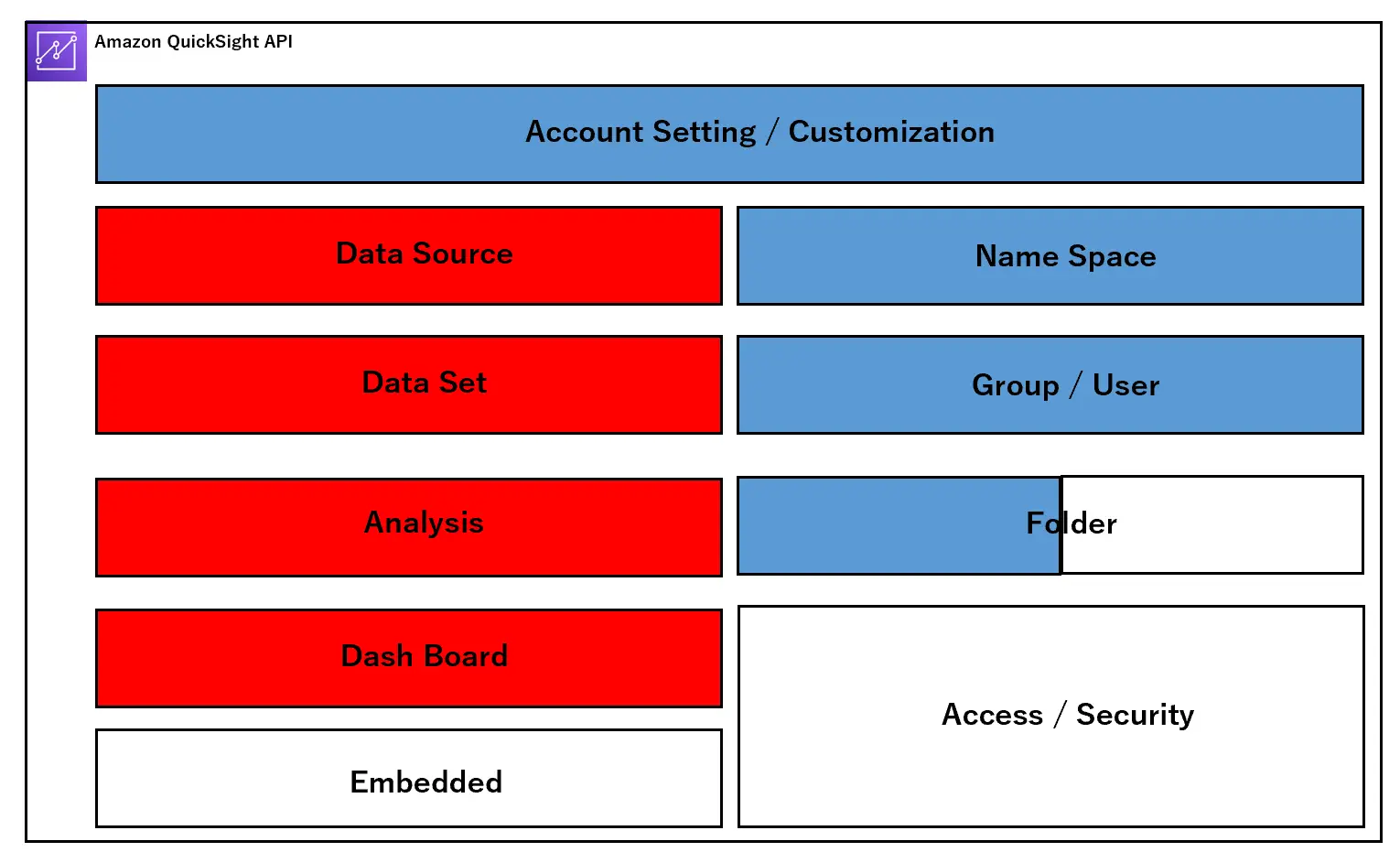
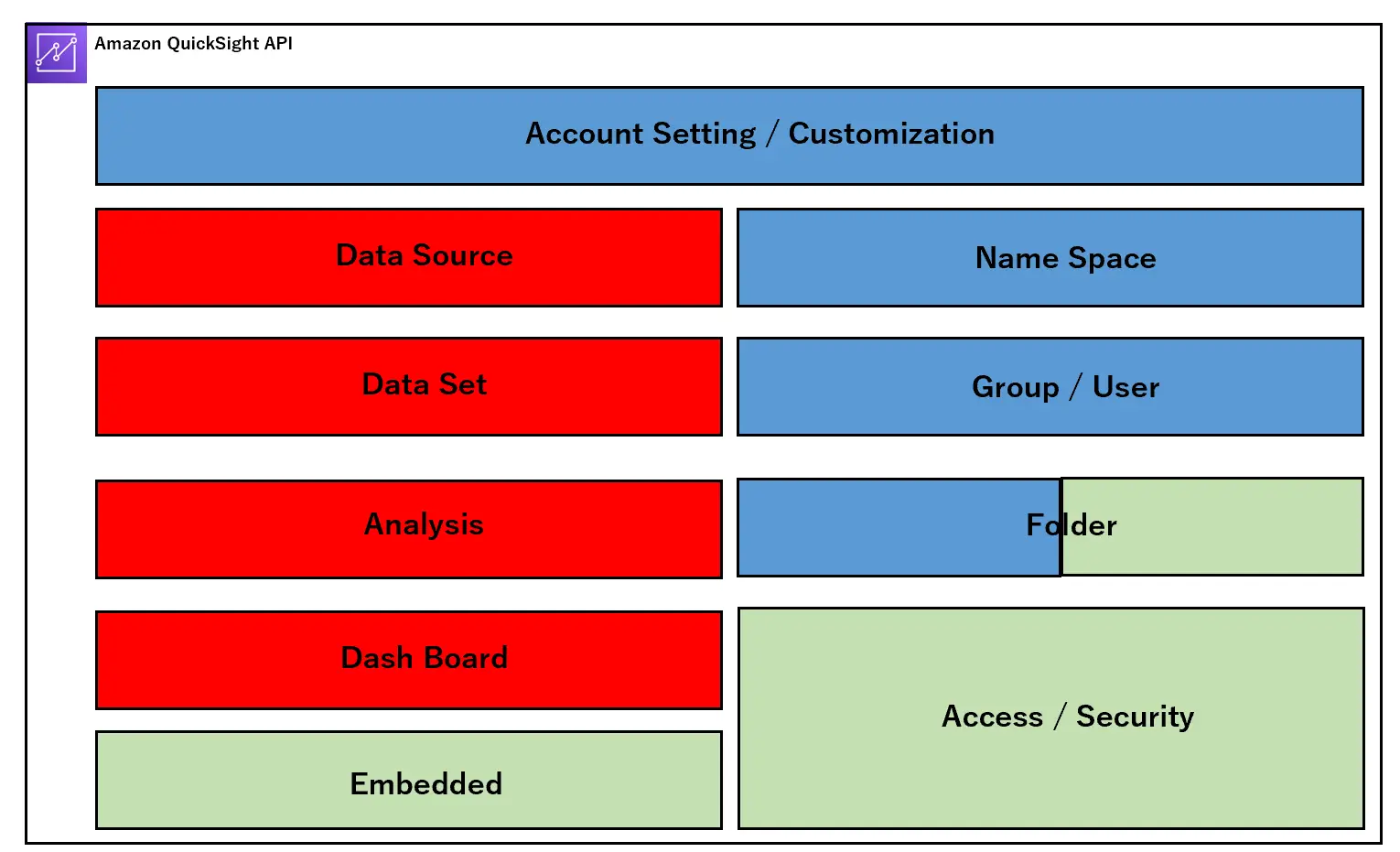
まずはアーキテクチャを見ていきます。以下は、Amazon QuickSight 内部の構造体をAPI ベースに区別して表現しています。
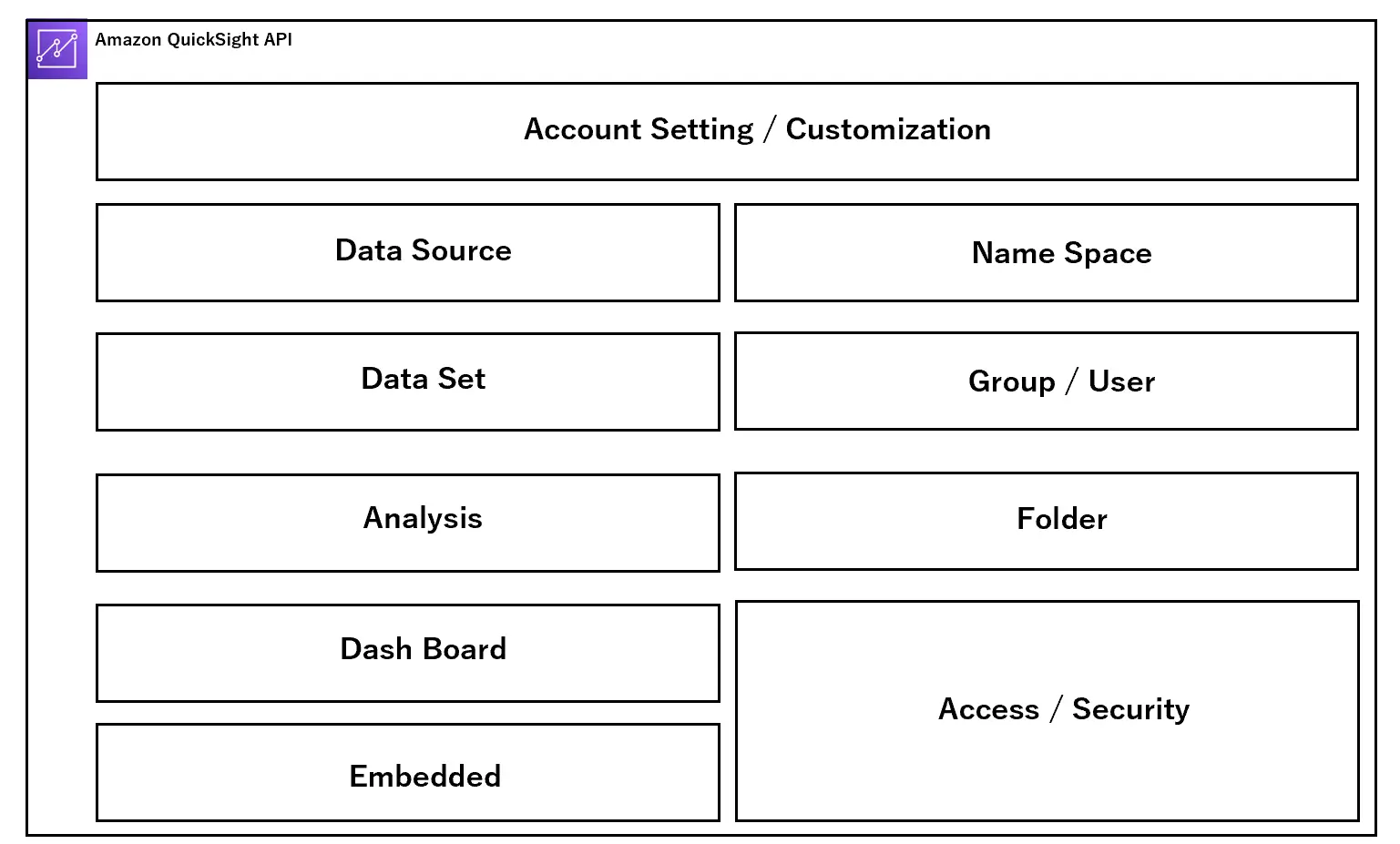
設計段階において、主に開発プロセス、ユーザー設計、アクセス設計という3つの側面からサービス全体のフレームワークの理解をしていく必要があると考えます。これらを一つずつ見ていきましょう。
DashBoard Development Process (開発プロセス)
開発工程では、主に赤い部分のオブジェクトを対象にご説明します。
ここで説明するものは、一括りにアセットと呼ばれます。これらの工程ごとに必要な設定を行っていき、最終的にユーザーへダッシュボードを提供します。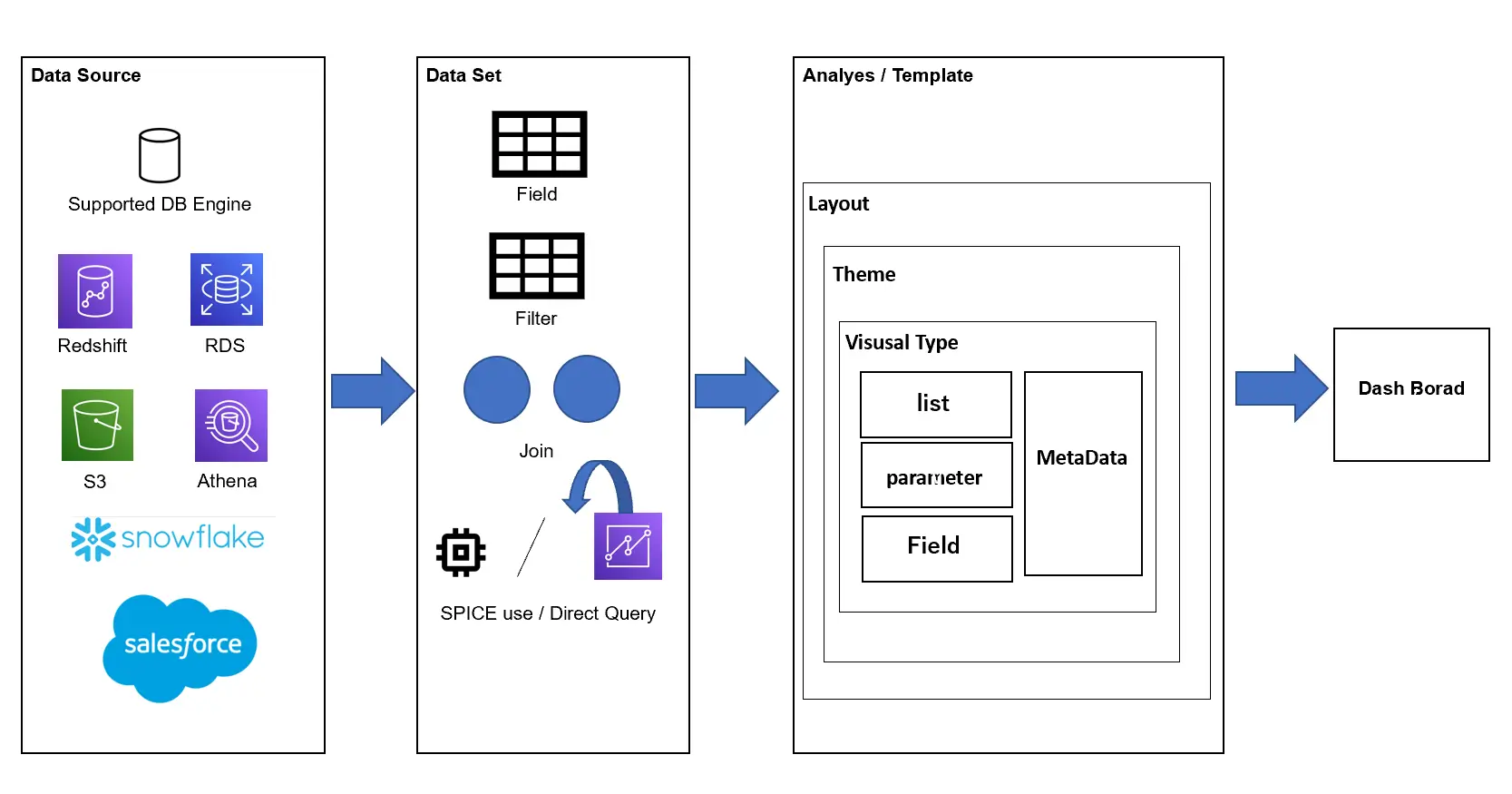
Data Source
データソースは Amazon QuickSight 上から使用するデータを選択し、それらの情報を保持します。既に登録されたデータソースは、後述する別のデータセットとして利用する事が出来ます。
以下は、データソースを新規で定義する際に、選択が可能なデータソースタイプです。いずれかの項目を選択し、データソースタイプに沿った設定項目を入力し、データソースを定義していきます。
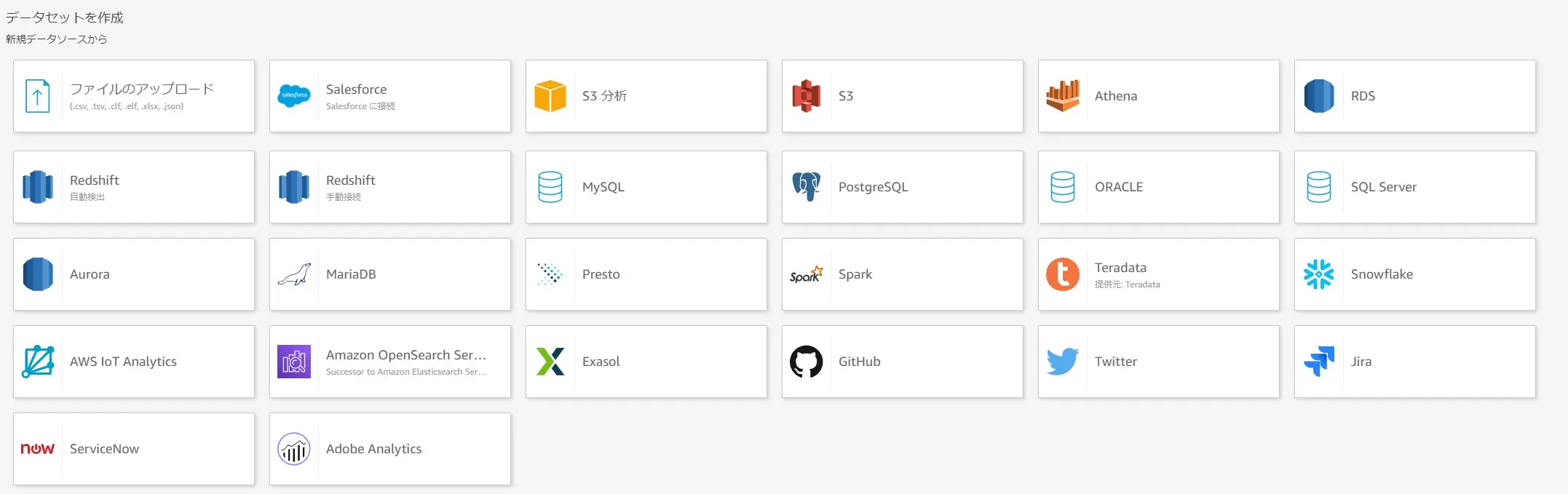
参考情報 サポートされているデータソース
Data Set
データセットは、定義済みのデータソースからデータを認識し、Amazon QuickSight がサポートする形へデータを定義していきます。この際、Amazon QuickSight は 元データの列毎にフィールドという形式を設けていきます。データセットの作成工程では、特定のフィールドへフィルタリングを設けたり、複数のデータセットを使用して、 結合を行うなどの作業を行います。また、データセットに対する変更作業は、作成した後においても可能となります。
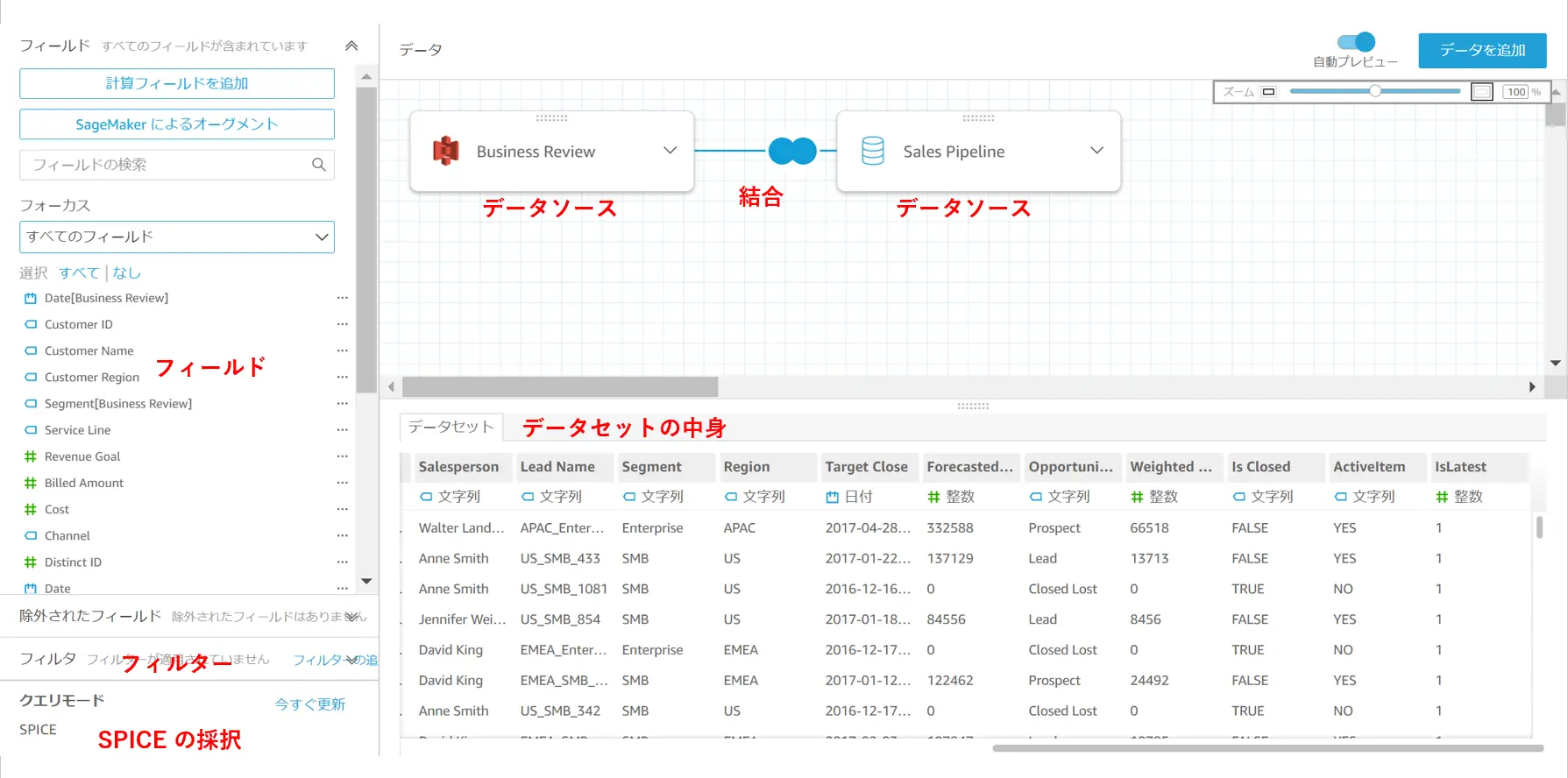
また、 カスタムSQLクエリと呼ばれる Amazon QuickSight からクエリを発行する事で、データセットに含むデータを整形する事が出来ます。クエリモードと呼ばれる SPICE を使用するか、クエリを直接発行するかを選択する事も可能です。これらは後述のアクセス方式にて、ご説明します。
Analysis
作成したデータセットを元に、Analysis (分析) を作成していきます。後述のダッシュボードとなる UI を開発していくパートとなります。
分析のレイヤは、以下のイメージ図のように複数の項目から成り立っています。これら設定内容を元にダッシュボードを公開していきます。
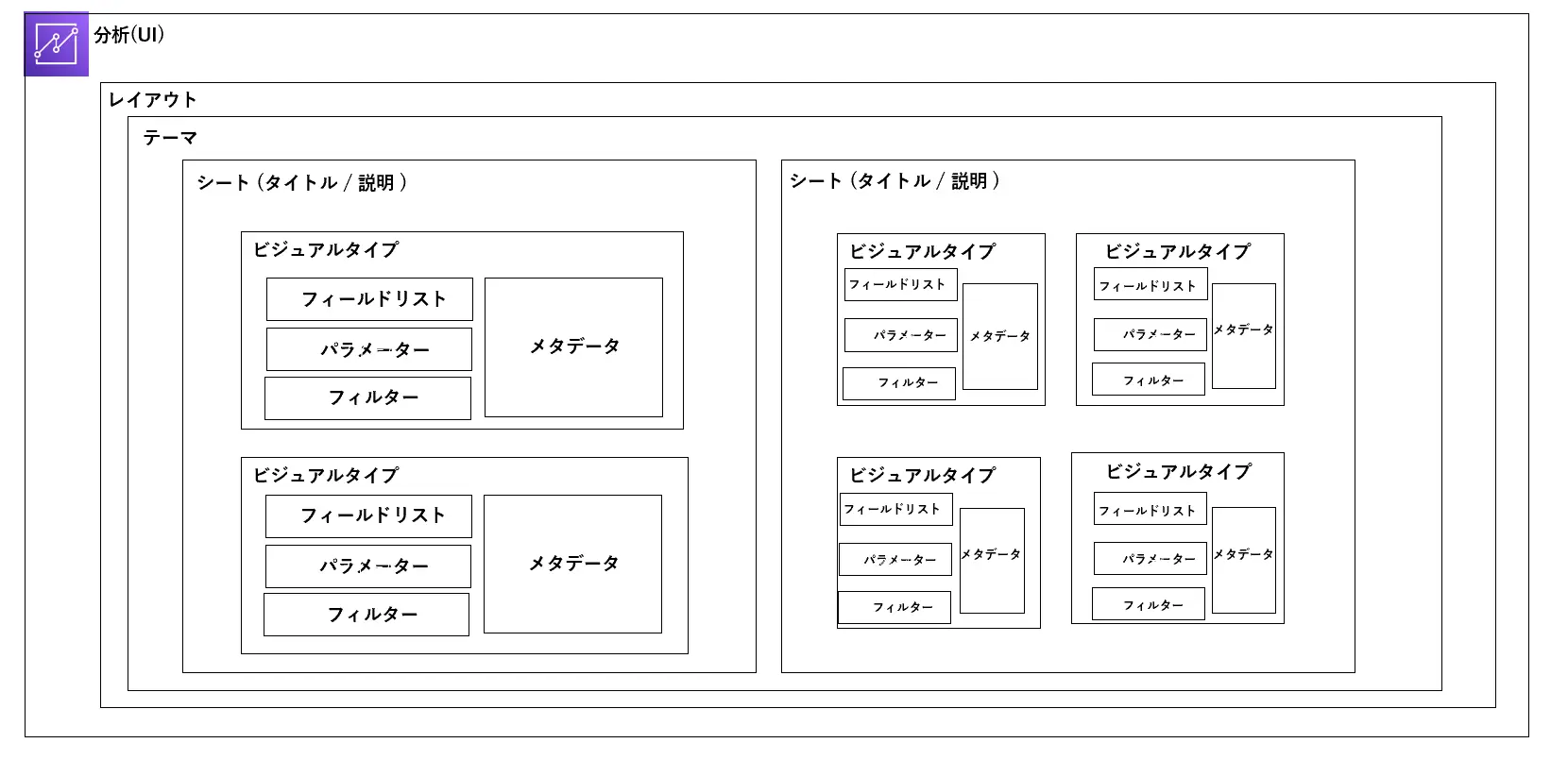
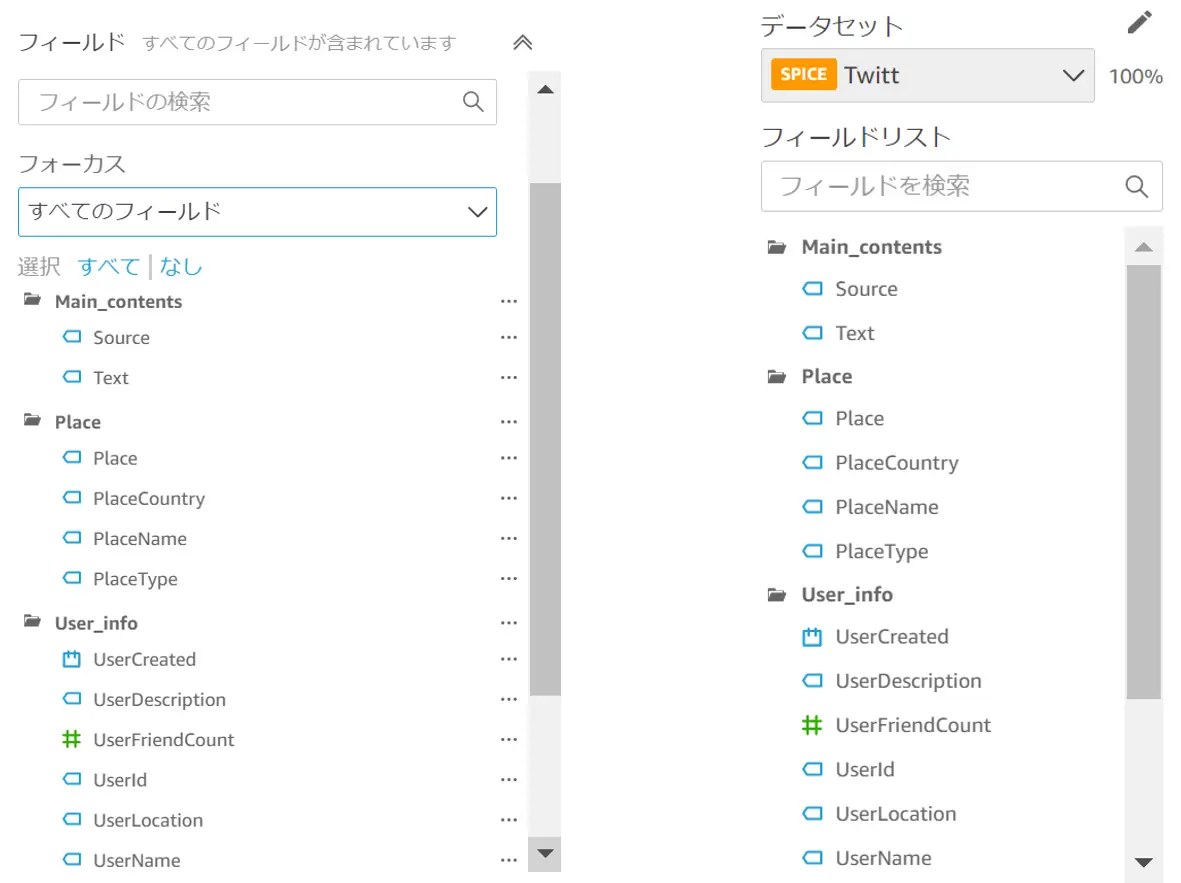
以下は分析の実際の画面です。フィールドは、データセットで定義したものがフィールドリストという形で一覧化されます。
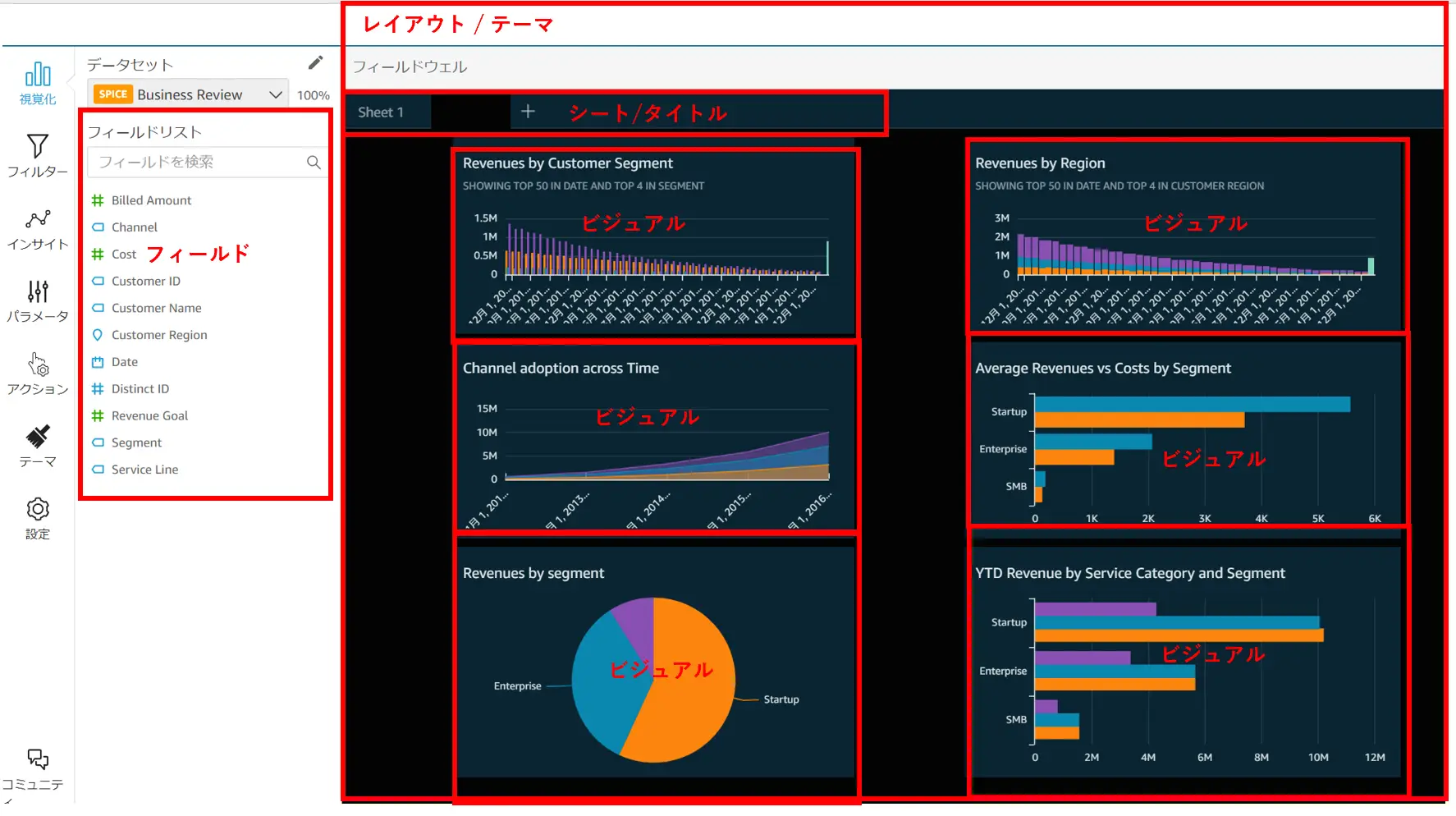
ここで分析に使用されるオブジェクトを見ていきます。
Layout / Theme
レイアウトは後述するビジュアルのフォームを決定します。テーマはUI の台紙となる部分です。ダッシュボードの背景色、分析のグリッド線の表示などがこれに該当します。
Sheet
ページの単位です。1つの分析上から複数のシートを作成できます。公開されたダッシュボードは、これら複数のシートを1つのダッシュボードから確認する事が出来ます。
Visual
表やグラフ、画像やインサイトなどを表現する一意のオブジェクトの単位です。ビジュアルタイプとは、ビジュアルを作成する際に選択するフォーマットであり、Amazon QuickSight は多様なビジュアルタイプをサポートします。
参考情報 Amazon QuickSight が使用出来るビジュアルタイプ
選択されたビジュアルタイプ毎に、適用するフィールド(フィールドウェル)やフィルター、パラメーターなどを指定していきます。これらを元に、表現したいUIを開発していきます。詳細な設定項目については、後述に記載致します。
Dash Board
公開された分析は、ダッシュボードから閲覧する事が出来ます。
ダッシュボードの閲覧者には、分析で使用されたパラメーターやオプションを元にインタラクティブな機能が提供されます。例えばフィルタリング機能や、ファイル形式のダウンロードなどです。
なお、Amazon QuickSight Enterprise Edition では、ダッシュボードにML Insights が適用されたデータを確認する事も可能です。こちらも後述します。
User Design (ユーザー設計)
ユーザー設計では、青色の部分を対象にご説明します。
Amazon QuickSight が使用するユーザーは、それぞれが独立した関係を持ちますが、以下のように包含関係として示す事が出来るかと思います。それぞれの項目について触れていきます。
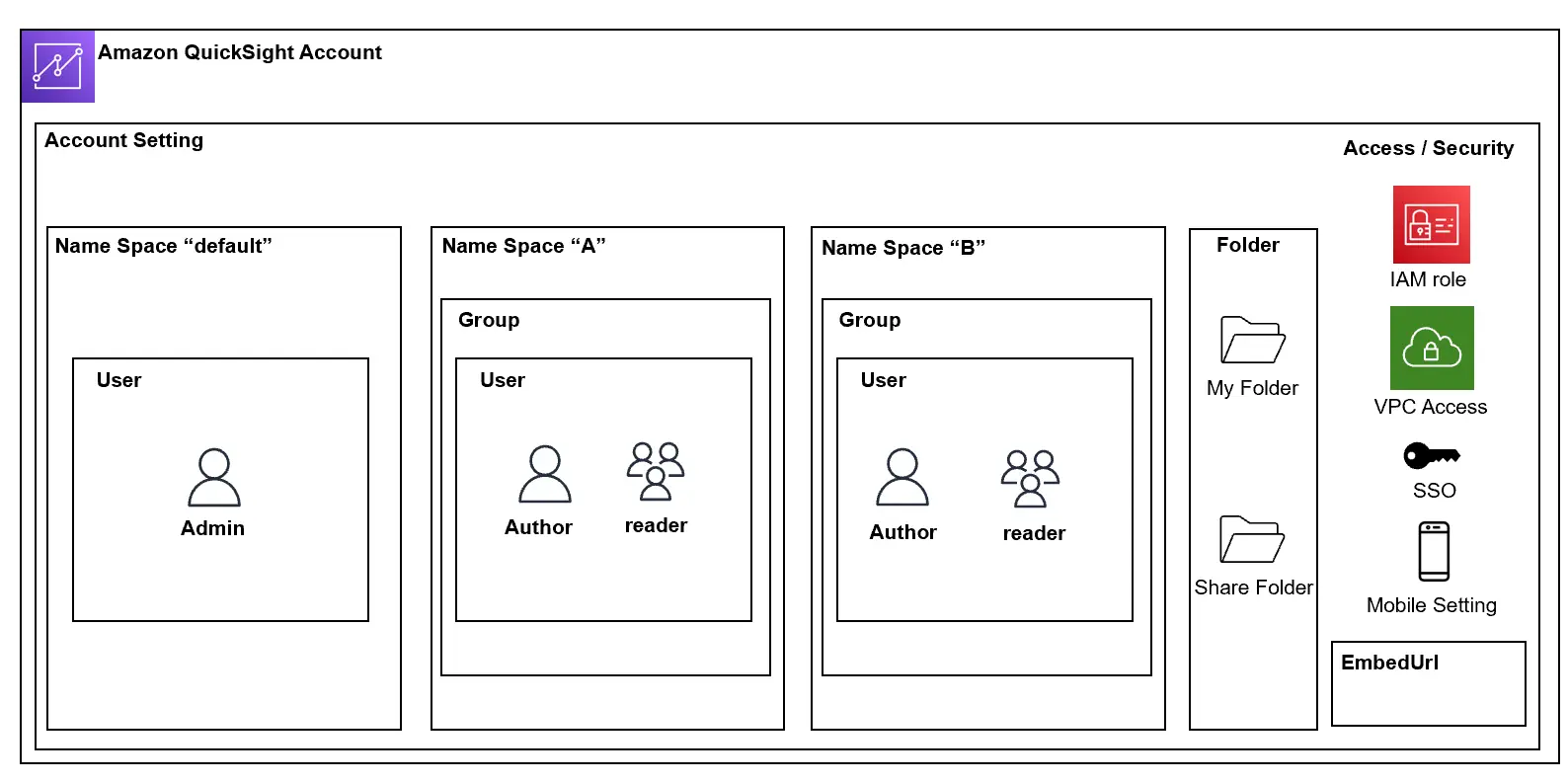
Name Space
Amazon QuickSight は AWSサービスの一つですが、AWS アカウントの特定リージョンに Amazon QuickSight アカウントを作成して使用します。
Name Space(名前空間) は、一つのAmazon QuickSight アカウント上で使用されるテナントを独立して使用出来るようにする空間です。
Enterprise Edition では、複数の名前空間を用いたマルチテナントをサポートします。
アセット(データセット、データソース、ダッシュボード、分析)は、名前空間と分離した関係となりますが、後述するユーザーは対象の名前空間内で動作する事となるため、ユーザー設計において非常に重要な概念です。
Group
対象の名前空間にグループを作成し、後述するユーザーを追加する事が出来ます。グループ単位の権限付与、共有が可能なため、大規模なユーザー数を管理するためには非常に便利な概念です。
User
先述の通り、Amazon QuickSight は、AWS 内でアカウントを作成していきます。このため、QuickSight ユーザーは、IAM ユーザー以外も使用する事が出来る仕組みとなっています。
Enterprise Edition では、大きく3つのユーザー管理がサポートされます。
1. IAMユーザーおよびフェデレーテッドログイン
2. Eメールアドレスによるユーザー管理
3. AWS Managed Microsoft AD による認証・管理
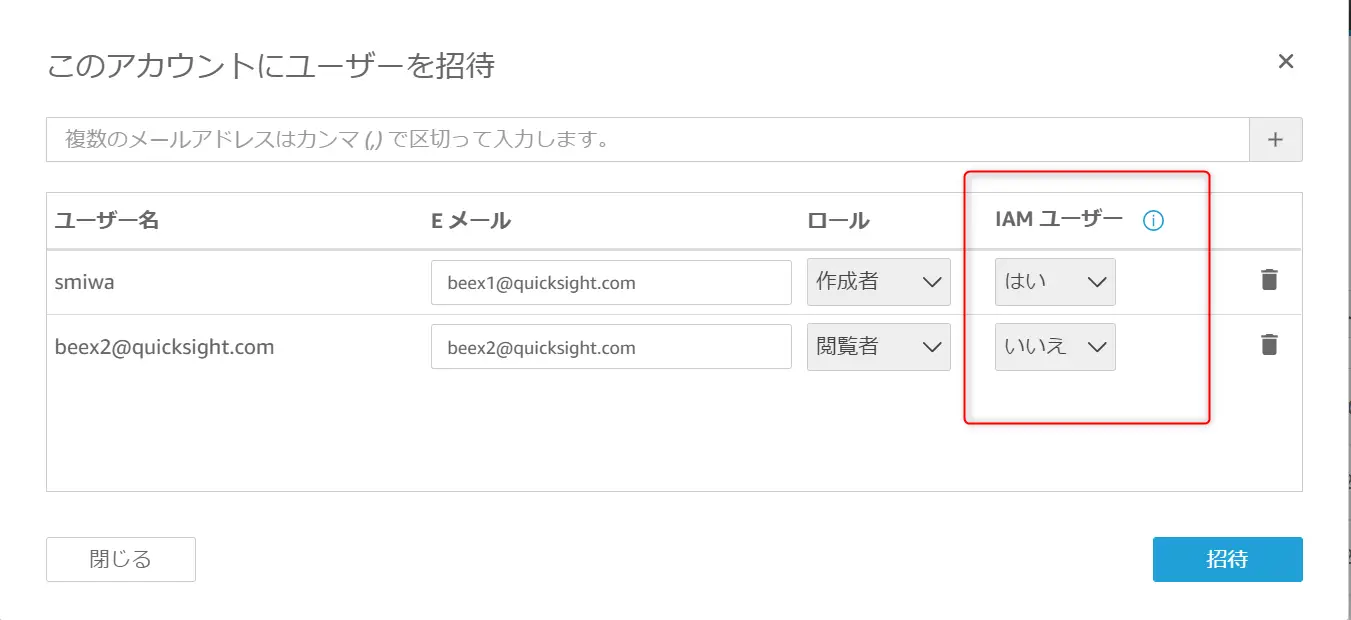
例えば、特定のEメールアドレスに招待メールを送り、Eメールアドレスを一意として IAMユーザーが存在しない状態で QuickSight ユーザーを作成する事ができます。
Folder
フォルダには、個人用フォルダと共有フォルダ、また、データセットフォルダの3種類が存在し、アセット(データセット・分析・ダッシュボード)あるいは各データセットのフィールドをフォルダに追加する事ができます。
Personal Folder (個人フォルダ)
各ユーザーがアセットに対する作業を行う際に使用するワークスペースのようなもので、効率化の用途で使用されます。
Share Folder (共有フォルダ)
AWS アカウントの他のユーザー・グループに対して対象のアセットの共有を行うためのフォルダとなります。フォルダにはアクセス許可を設ける事が可能で、これを行う事で特定のユーザーやグループへアセットを共有出来ます。
Fields Folder (フィールドのフォルダ)
各アセット単位ではなく、各データセットおよび分析のフィールドに対してフォルダを作成する事が可能です。多数のフィールドを使用する場合に、カテゴリ別にフォルダを区分けする事で、作成者が分かりやすくフィールドの操作を行う事ができます。
Access Design (アクセス設計)
最後にアクセス設計についてです。以下の図では緑色の部分のオブジェクトに関するご説明となりますが、Amazon QuickSight のアクセス性はカバー範囲が広いです。
そのため、以下4つの観点からご説明します。
2. Amazon QuickSight Users Accessibilty (Amazon QuickSight ユーザーのアクセス)
3. Physical Data Source Connection (物理データソースへのアクセス)
4. Embedded Analytics (埋め込み分析)
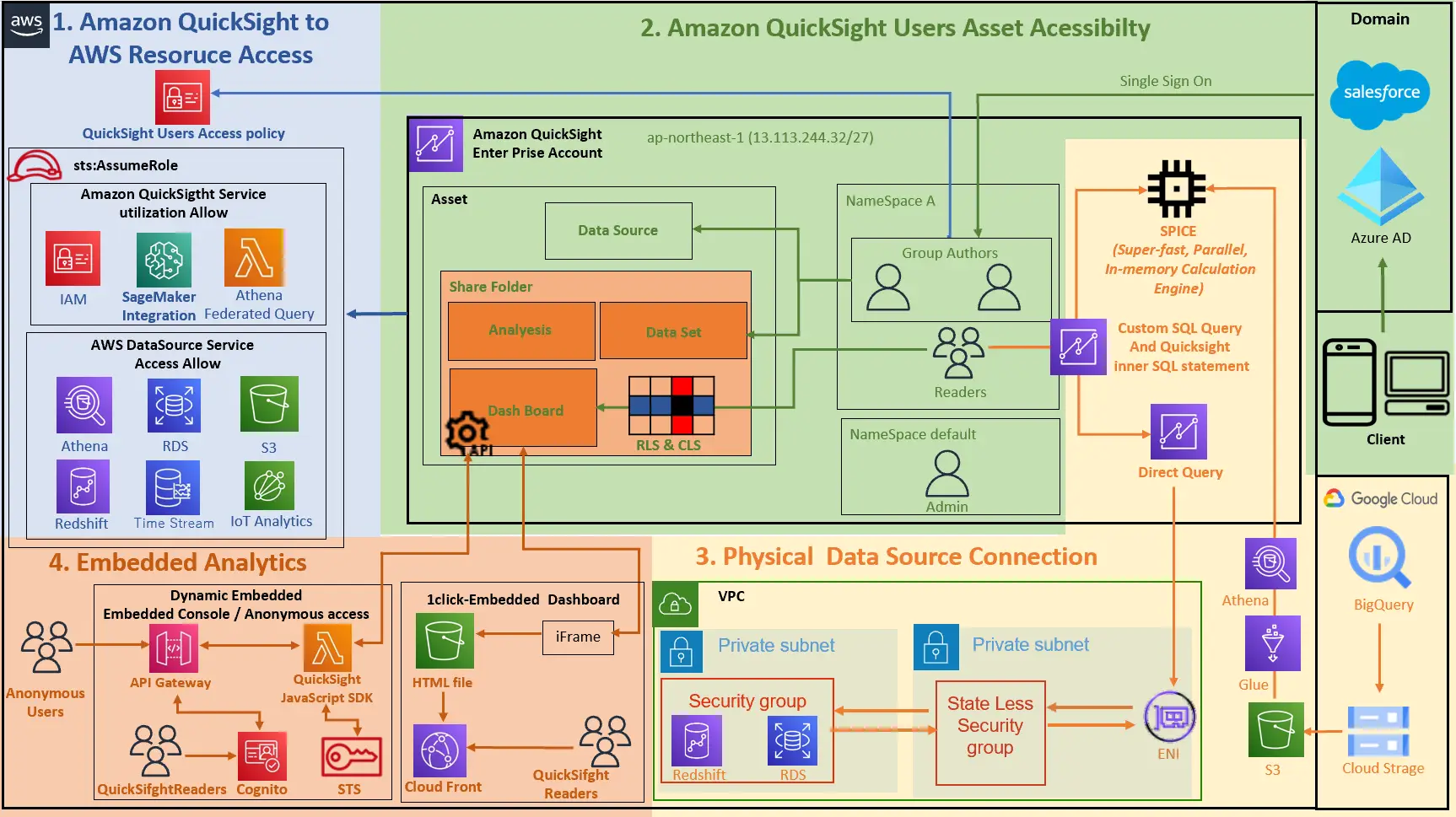
1. Amazon QuickSight to AWS Resoruce Access (AWS リソースへのアクセス)
Amazon QuickSight は AWS 上に特定リージョンの QuickSight アカウントを作成する事で利用が可能となります。Amazon QuickSight から特定のAWS リソースへアクセスが必要な場合、ロールを引き受けることを許可する信頼ポリシーを IAM ロールに対してアタッチします。デフォルトでは aws-quicksight-service-role-v0 というIAMロールを使用しますが、既存のロールへ変更する事も可能です。
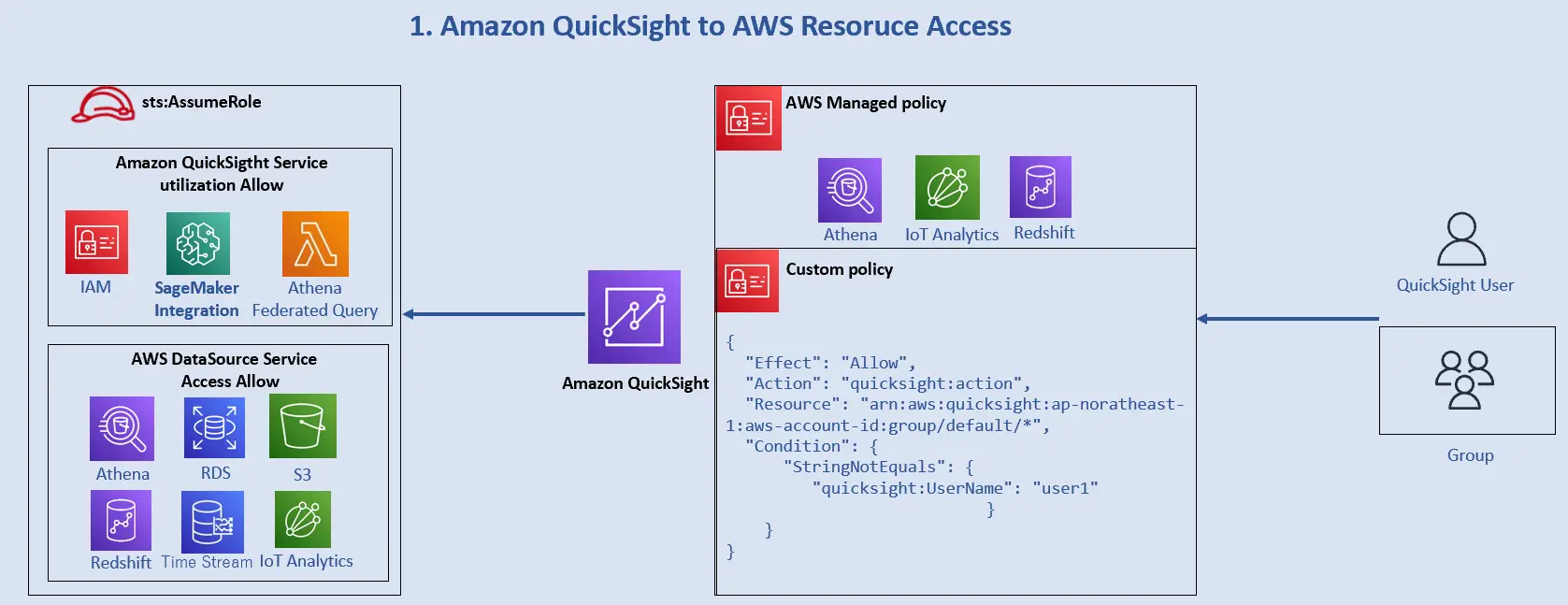
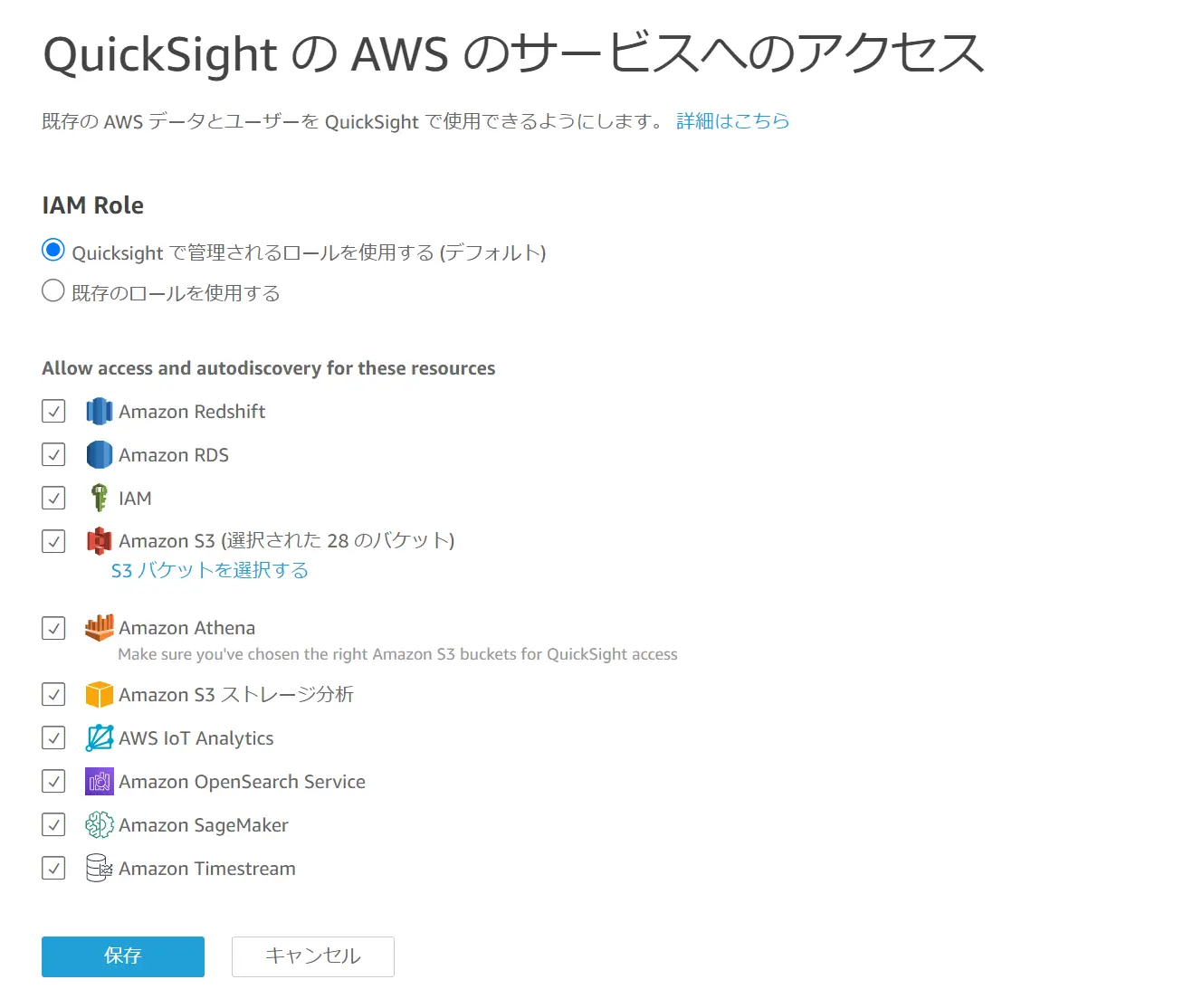
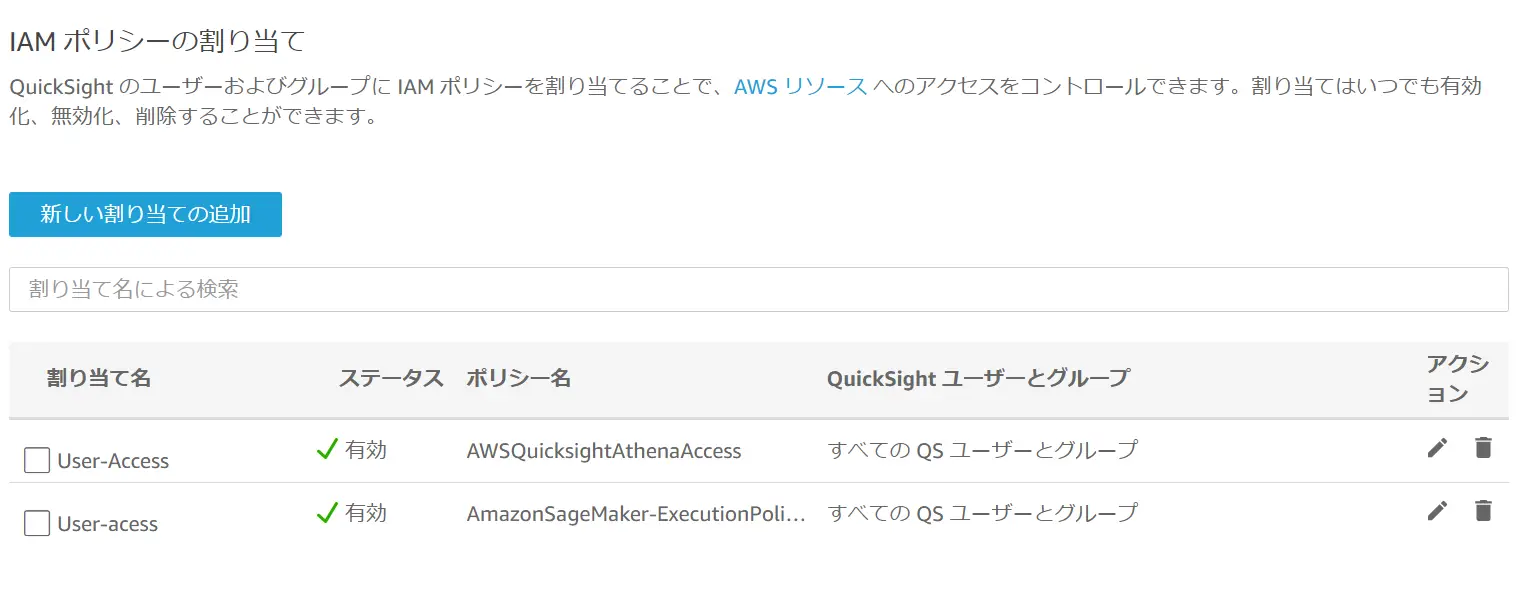
一方、IAM ポリシーを使用してグループやユーザーに対して割り当てを行う事でAWS リソースへのアクセス制御を行う事も可能です。これは、規定のIAMポリシーをアタッチする事でAWSリソースに対して制御を行います。
2. Amazon QuickSight Users Asset Acessibilty (Amazon QuickSight ユーザーのアクセス)
ここでは、QuickSight ユーザーの操作権限、共有方法について触れていきます。
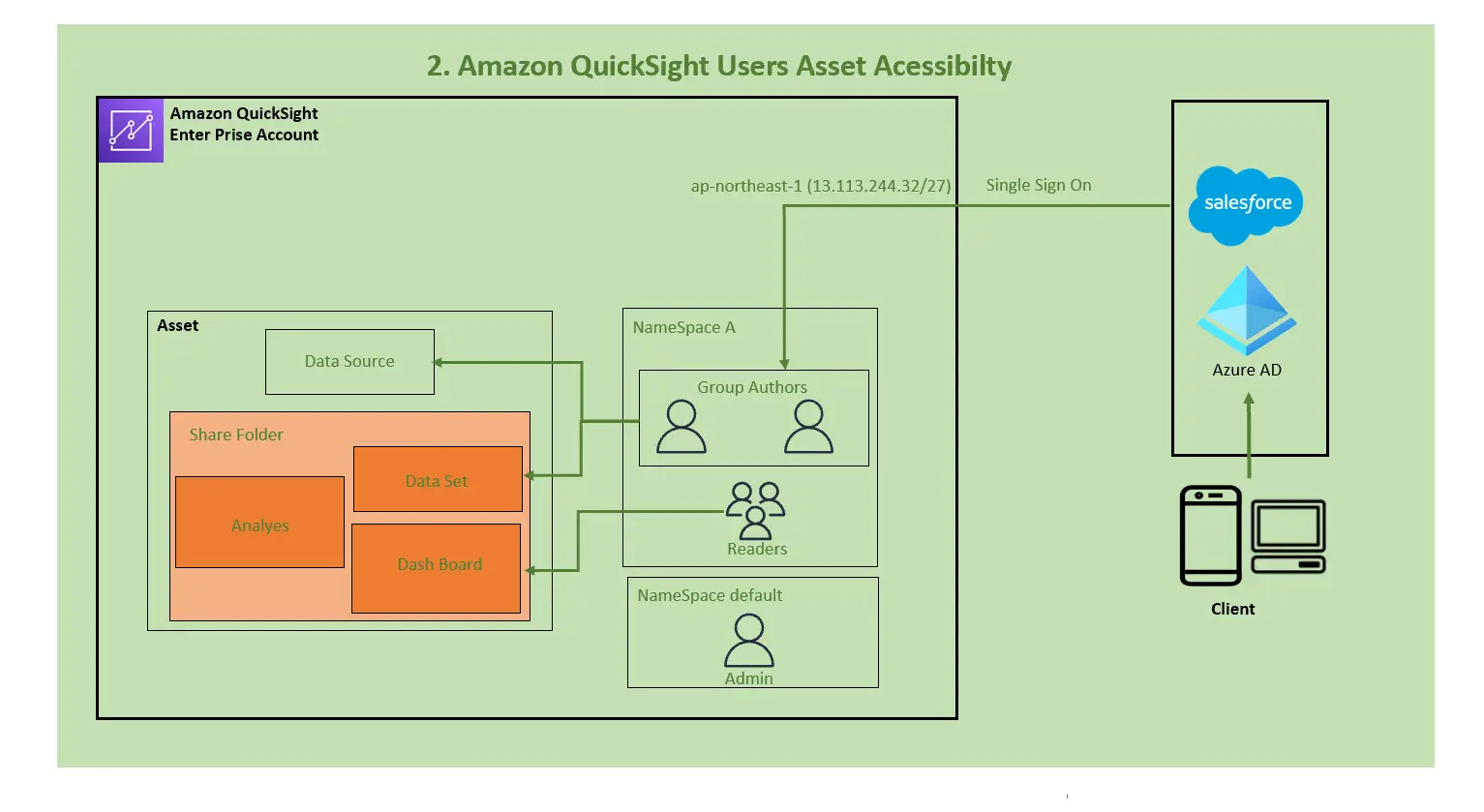
Role and Security Cohort
アセットを共有、閲覧するために、ユーザーの権限について理解する必要があるかと思います。QuickSight ユーザーは、以下3つのロールいずれかに所属する必要があり、ロールに沿って操作可能な権限が付与されます、なお、このロールはエディション毎に異なります。
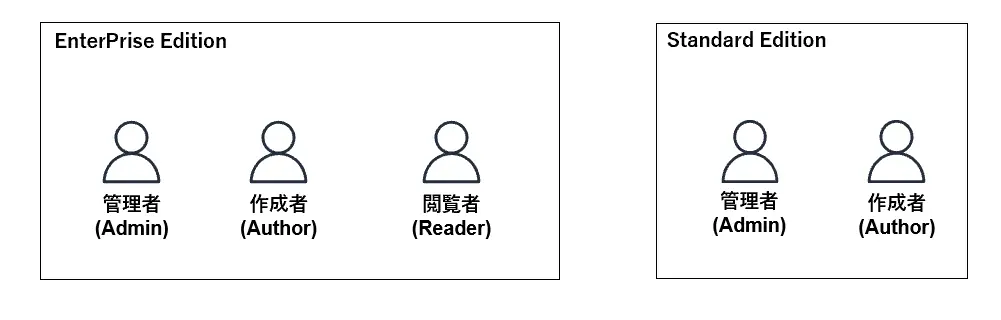
管理者(Admin)
ユーザー管理やSPICE 容量の購入などの管理タスクの実行権限を持ちます。また、ロールとしての管理者と、IAM 管理者ユーザーが存在し、これもまた、権限が異なります。
IAM 管理者ユーザーは、上記の管理者権限および、アクセス許可の管理、Editionのアップグレード、サブスクリプション解除も行うことができます。
作成者(Author)
データセットの作成、分析とダッシュボードの作成などを行う権限を持ち、閲覧者としての権限範囲も含みます。
作成者の権限範囲は広いため、Authorの権限を制限する事も可能です。
閲覧者(Reader)
Enterprise Edition のみ、共有されたダッシュボードを操作できる権限を持ちます。
Custom Permission
Enterprise Edition では、一意のロールを上書きする形で Custom Permission を使用する事が出来ます。これは、ユーザーへ割り当てる事で、上記のロールより細かい操作権限を設定する事が出来ます。但し、ユーザーのデフォルトのSecurity Cohort を超える許可を付与することはできません。たとえば、閲覧者アクセス権限を持つユーザーに、ダッシュボードの編集許可を付与することはできません。
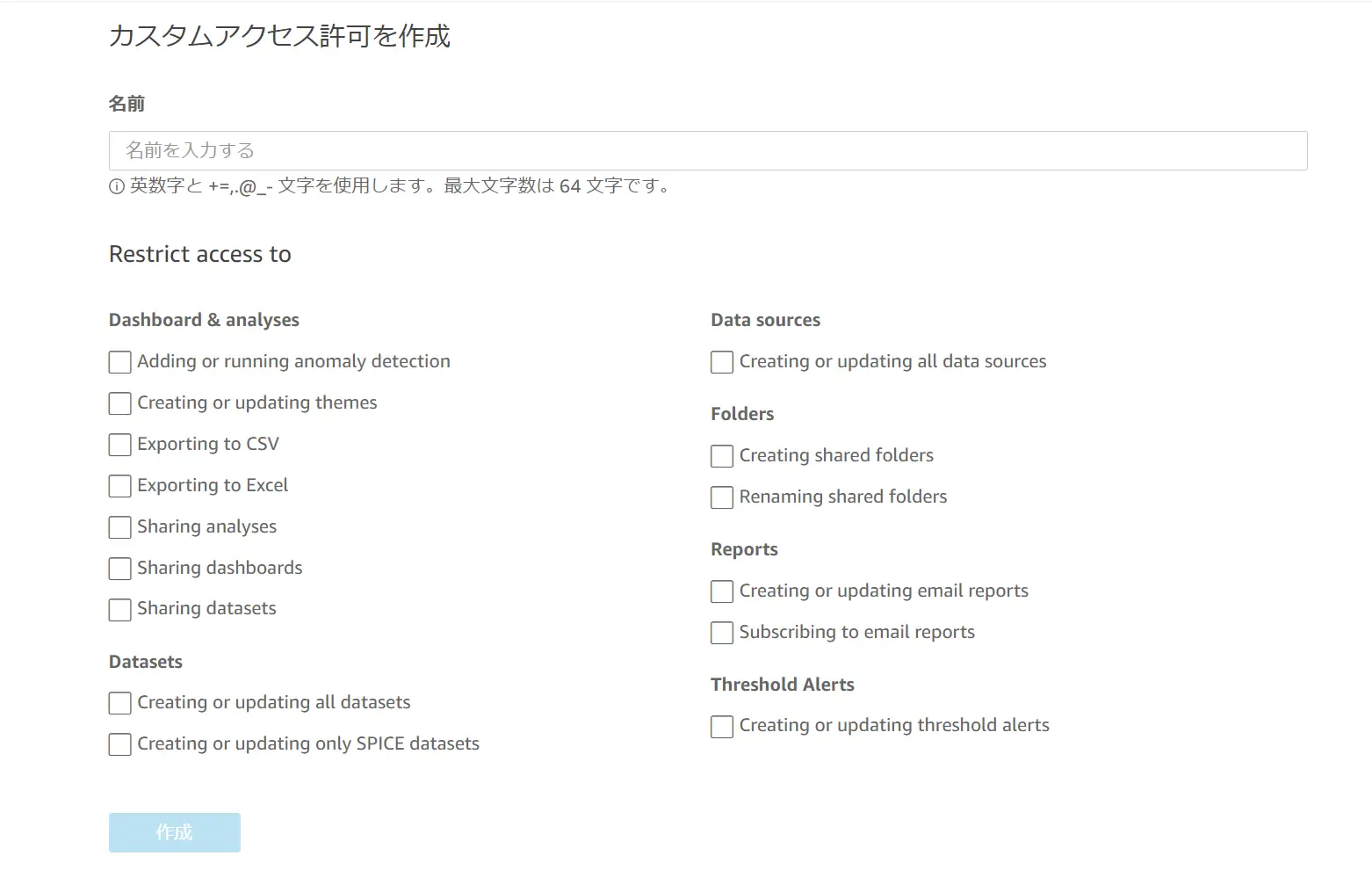
なお、Fine Grained Access Control による IAM ポリシーは、 Amazon QuickSight 内でユーザーが実行できる操作を制御しません。 これらは Custom Permmsion と機能が分離するため、上記のような Amazon QuickSight 固有の機能へのアクセスは IAM 外で、リソースレベルに処理されます。
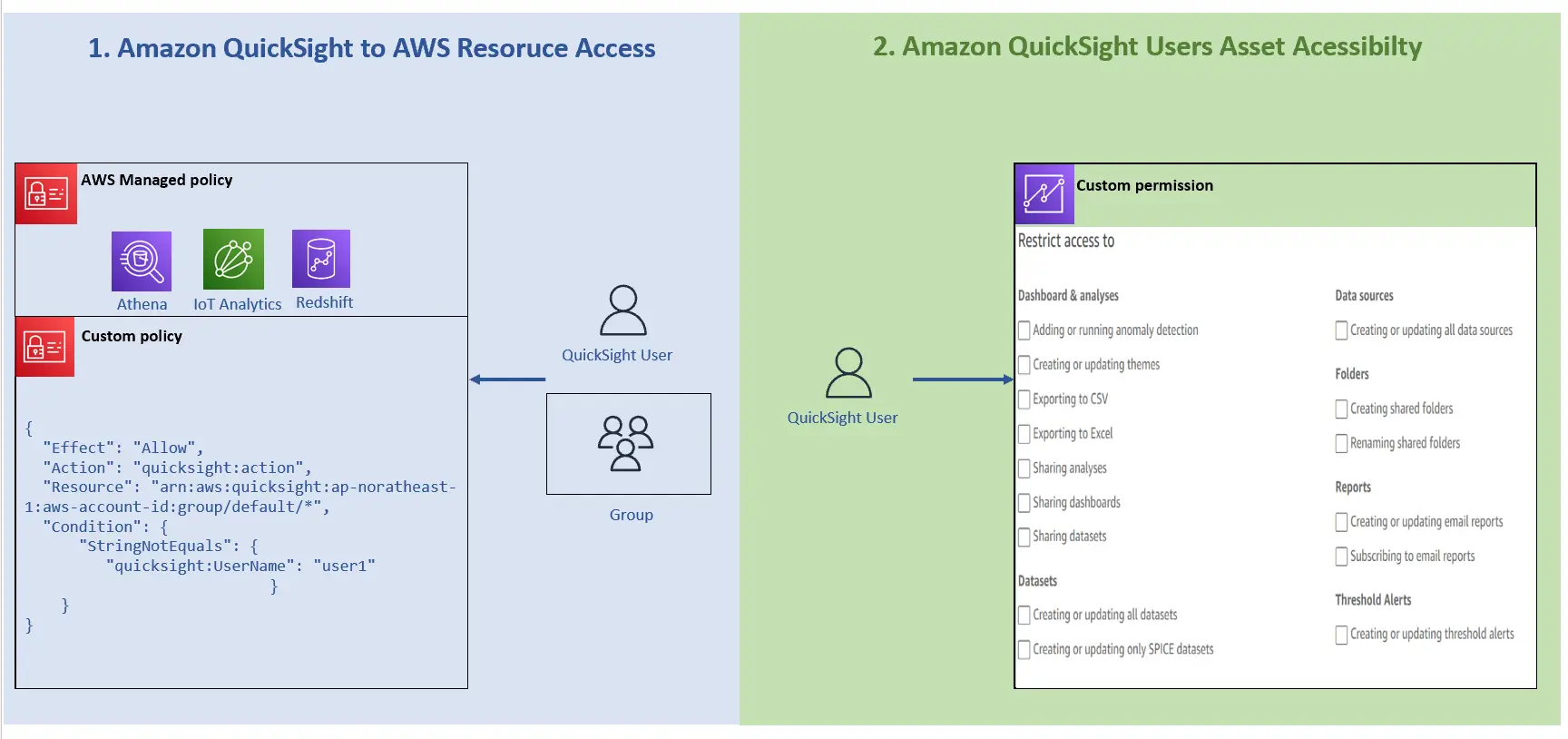
なお、作成した Custom Permission をユーザーに割り当てる場合、API (AWS CLI) を使用する必要があります。
aws quicksight update-user
--user-name <user-name>
--role AUTHOR
--custom-permissions-name <custom-permissions-profile-name>
--email <user-name@example.com>
--aws-account-id 111122223333
--namespace default
参考情報 Amazon QuickSight コンソールへのアクセスのカスタマイズShare Folder
QuickSight ユーザーは、デフォルトで他のユーザーが作成したアセットへのアクセス権がありません。そのため、他のユーザーへAPIから共有操作を行う事も可能ですが、共有フォルダを使用した閲覧・共有管理が便利です。
共有フォルダはフォルダ内にサブフォルダを作成する事で可能で、作成したデータセット・分析・ダッシュボードを指定のフォルダに配置する事が可能です。
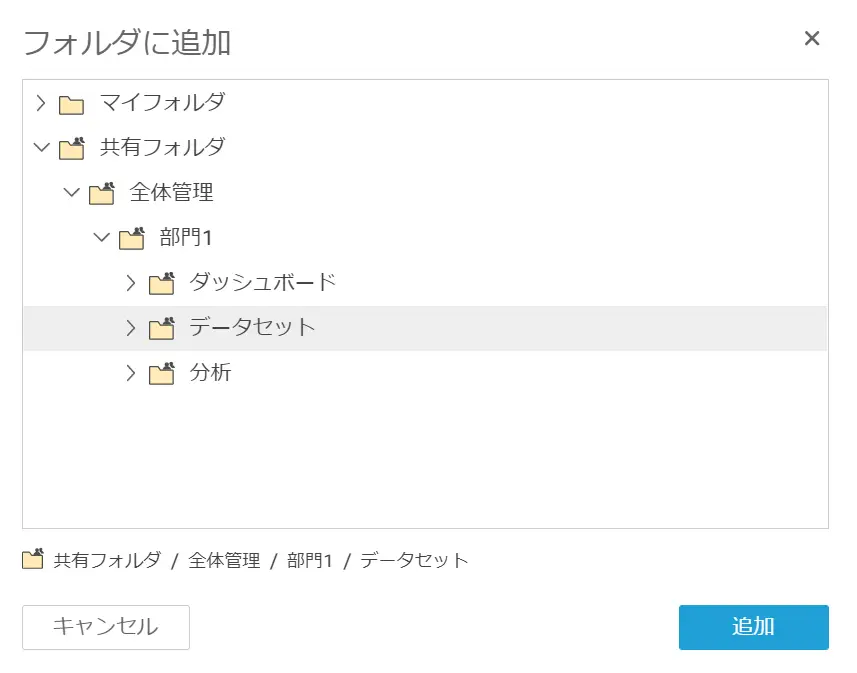
フォルダへはユーザー・グループに対して、以下2種類のアクセス権限を付与する事が可能です。
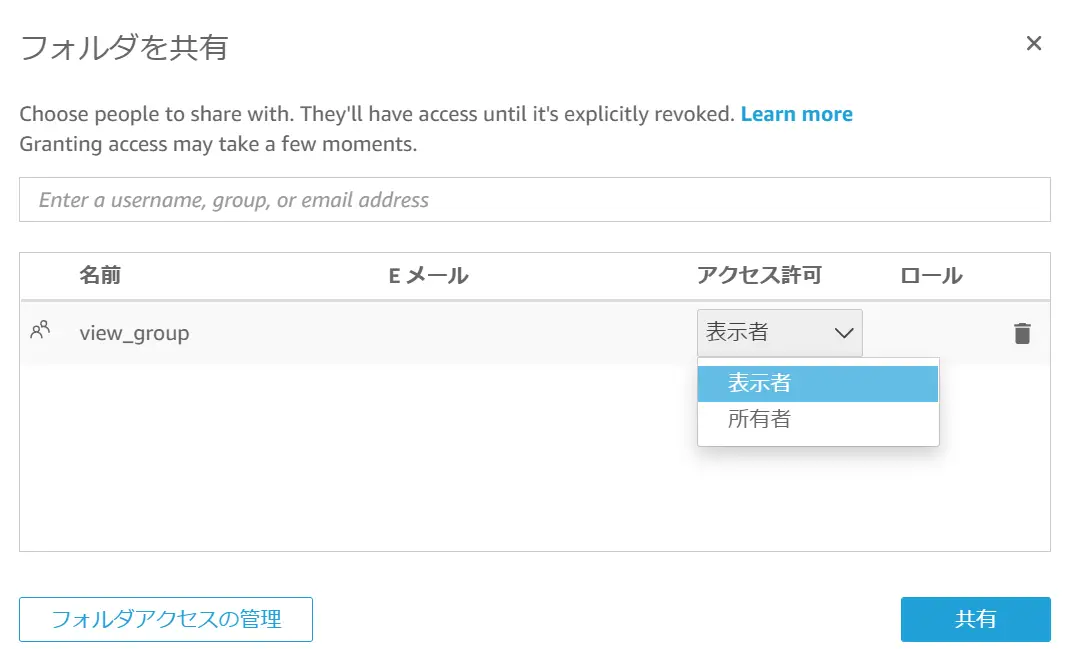
これら権限を駆使する事で、他のユーザーへの Asset の共有を簡素化し、標準化されたアクセス制御を実現します。
Single Sign On Amazon QuickSight
ユーザー設計に記載した通り、Amazon QuickSight Enterprise Edition では3つのユーザー管理がサポートされます。これらは、必ずIAMユーザーである必要はありません。またこれらユーザーは SSO によるログイン方式をサポートしております。
AWS 上で ID プロバイダーを追加し、認証リクエストを IdP へ送信することを許可する事でシームレスにログインを可能にします。
例えば SAML 2.0 を使用して SSO の管理を可能にします。SalesForce をIdPとした場合、SAMLプロバイダを AWS 上へ登録し、適切なIAMロールとリレーステート(https://quicksight.aws.amazon.com ) を設定する事でシームレスなアクセスを実現します。
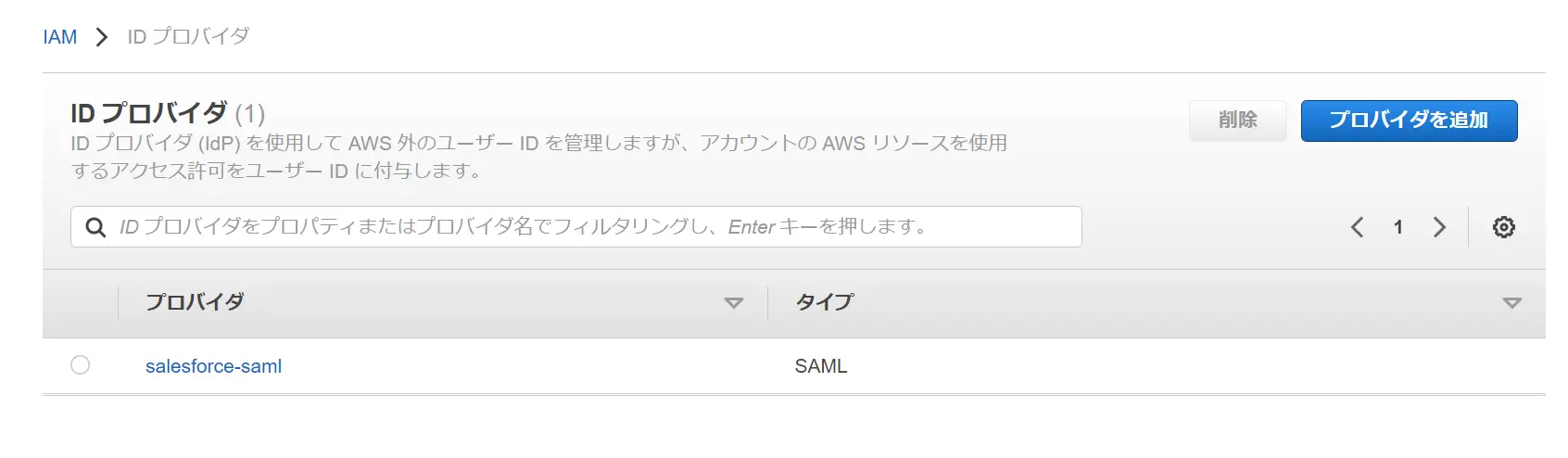
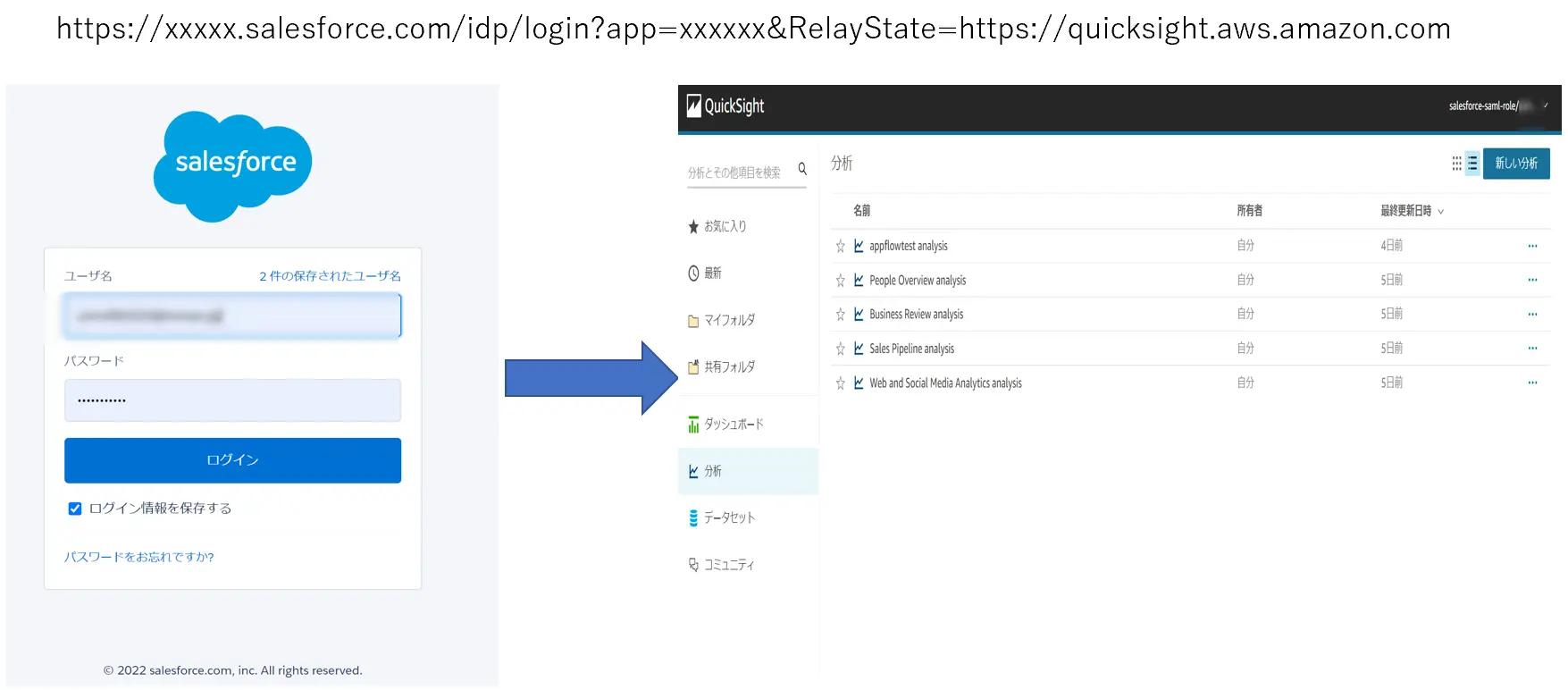
なお、IDプロバイダーによって SSO に必要な対応が少し異なるようなので、事前に手順の確認をしておくことをお勧め致します。
参考情報 Amazon QuickSight Enterprise Edition でのプロバイダー開始のフェデレーションのセットアップ
RLS & CLS (行レベルのセキュリティ /列レベルのセキュリティ)
RLS
Enterprise Edition では、RLS(行レベルのセキュリティ) のデータセットルールに沿って制限されたデータのみの表示が可能となります。行レベルのセキュリティを追加することで、ユーザ単位でアクセスを繊細なレベルまで制御できます。
RLS は、後述の匿名型の埋め込み(Anonymous Embedded) を除いて、ユーザーベースのルールを用いて RLS を実装します。データセットルールと呼ばれる RLS を適用するユーザー、グループ名、あるいは Arn と、制御を行うフィールド名と値を含む CSV ファイルを用意します。
例えば、以下です。UserArn 列には別々のユーザーの Arn が含まれます。

これをデータセットとして登録し、RLS の設定画面からユーザーベースのルールとしてアクティベートします。
![]()
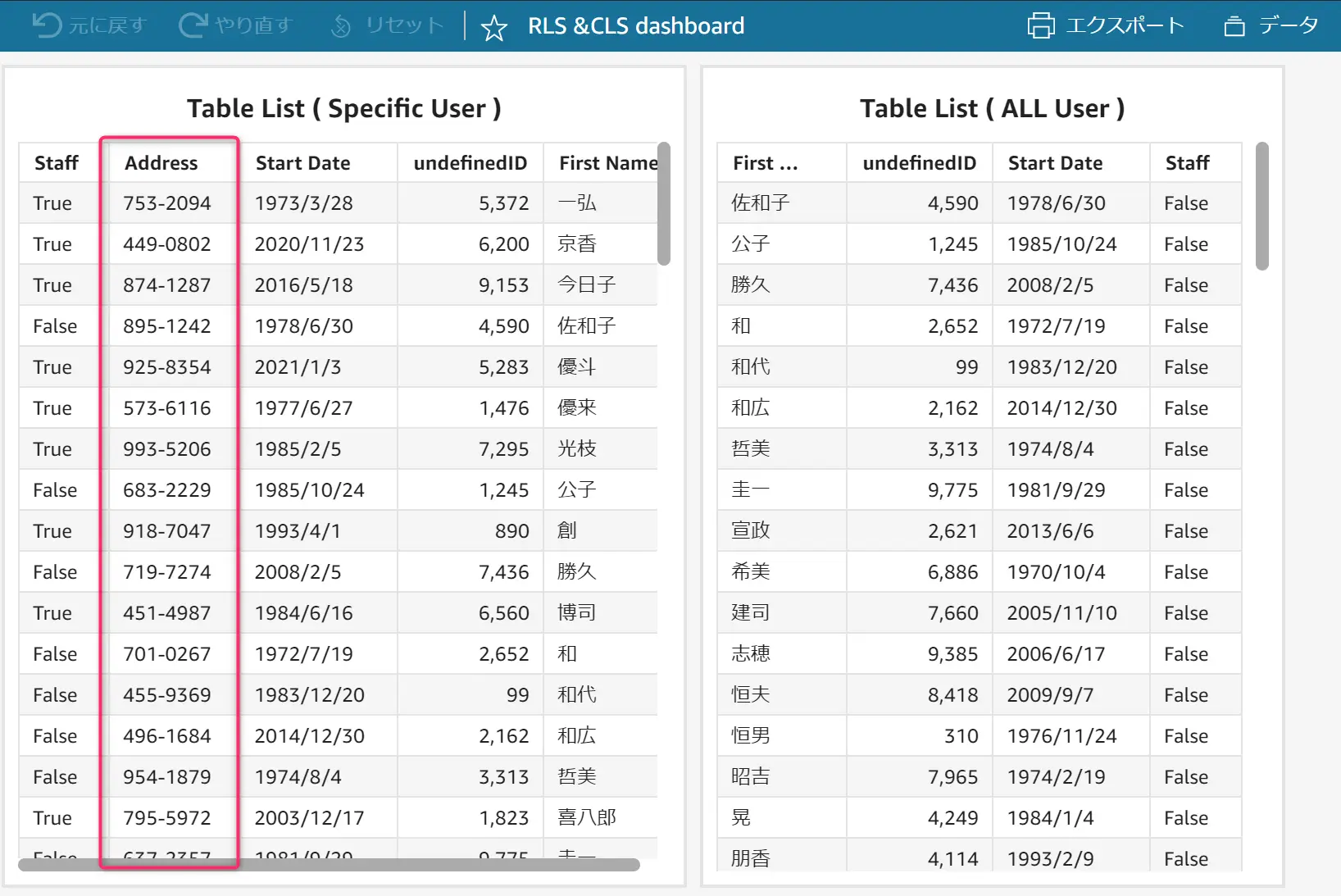
上記のデータセットルールには Region のフィールドが含まれていました。以下2つの画面は、ルールが適用されたそれぞれのユーザーから見た同じダッシュボードのビジュアルです。以下のように User Arn に紐づいた Region のみが表示される仕組みであることが確認できます。
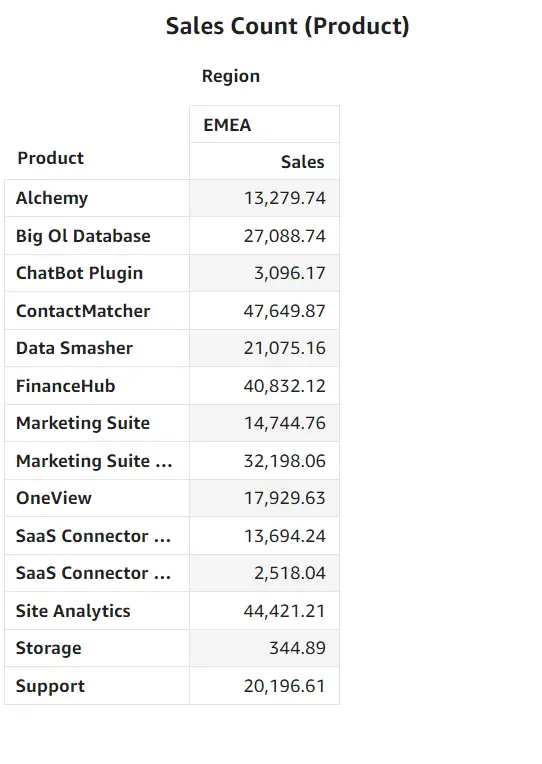
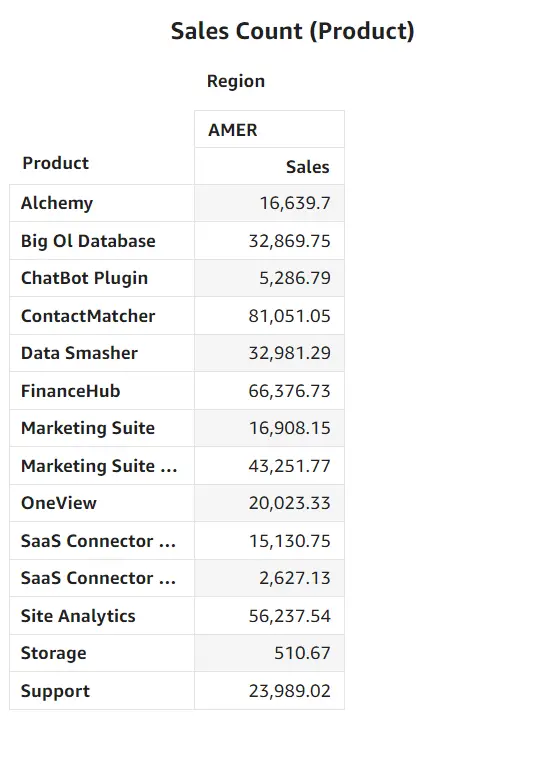
CLS
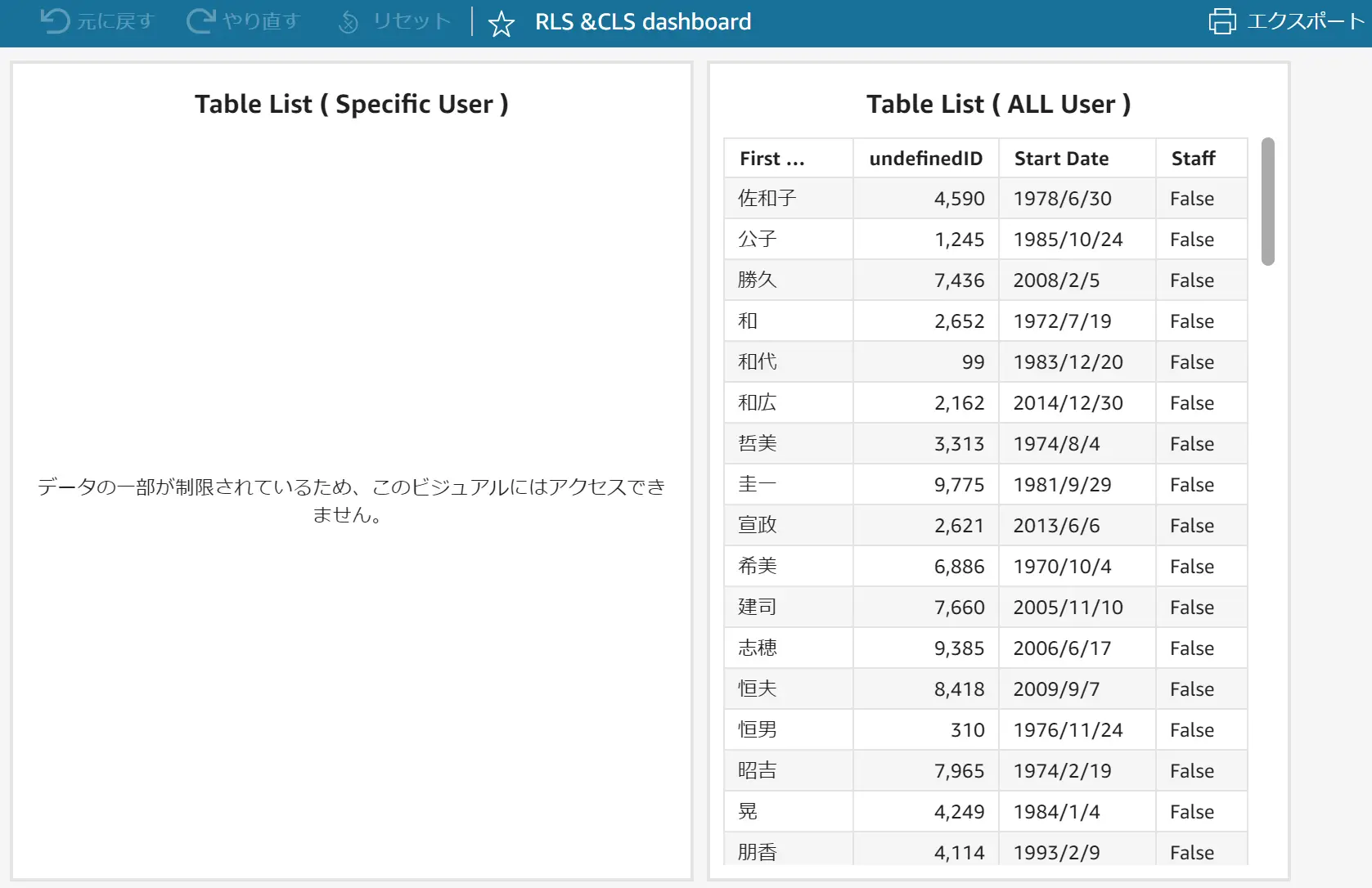
CLS(列レベルのセキュリティ)では、対象列に対して、アクセス制御を設ける事が可能です。データセットが認識した列単位に特定のユーザーやグループに対してアクセスを設ける機能です。
以下のように Address 列に対して、作成者のみアクセス権を付与します。
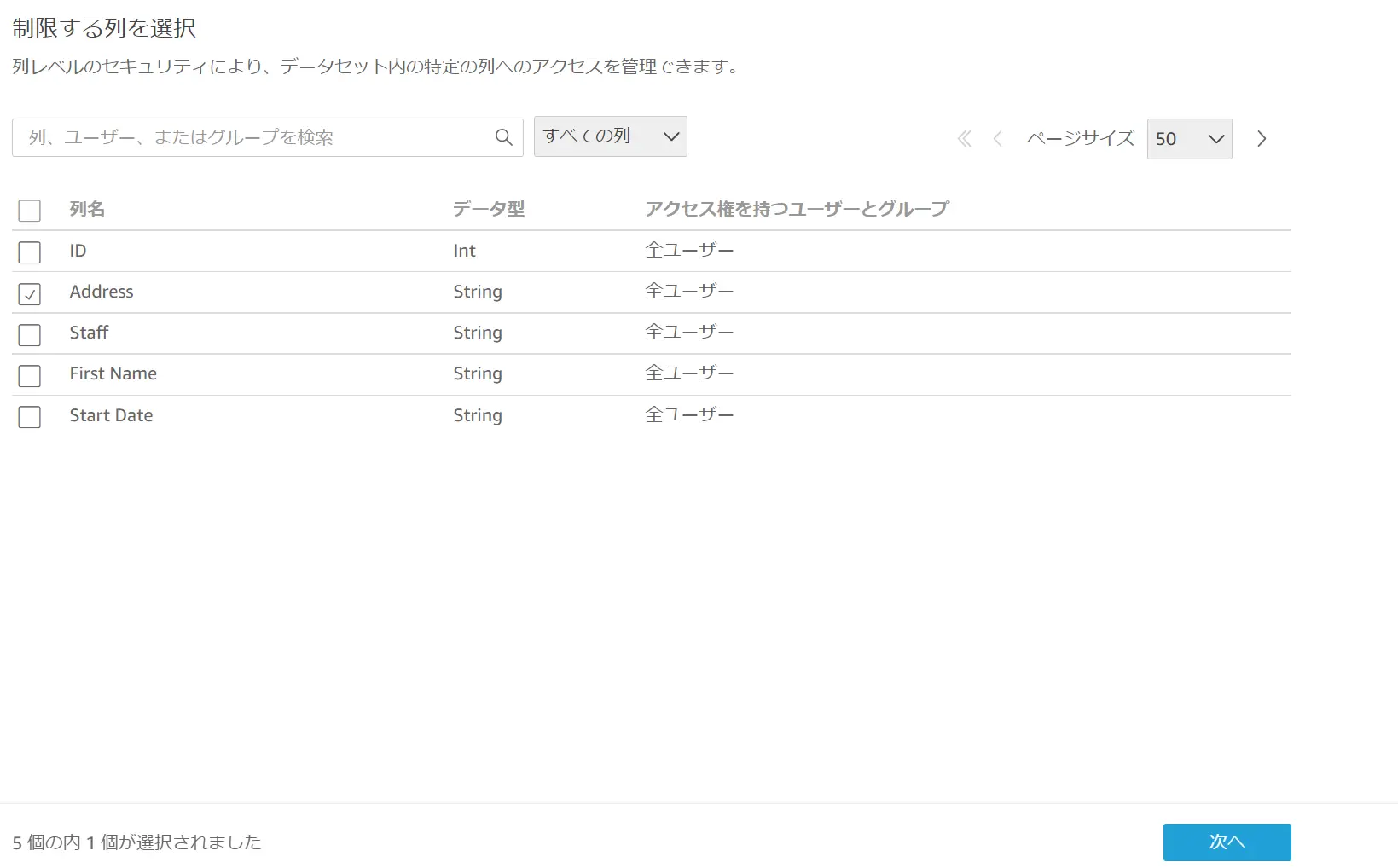
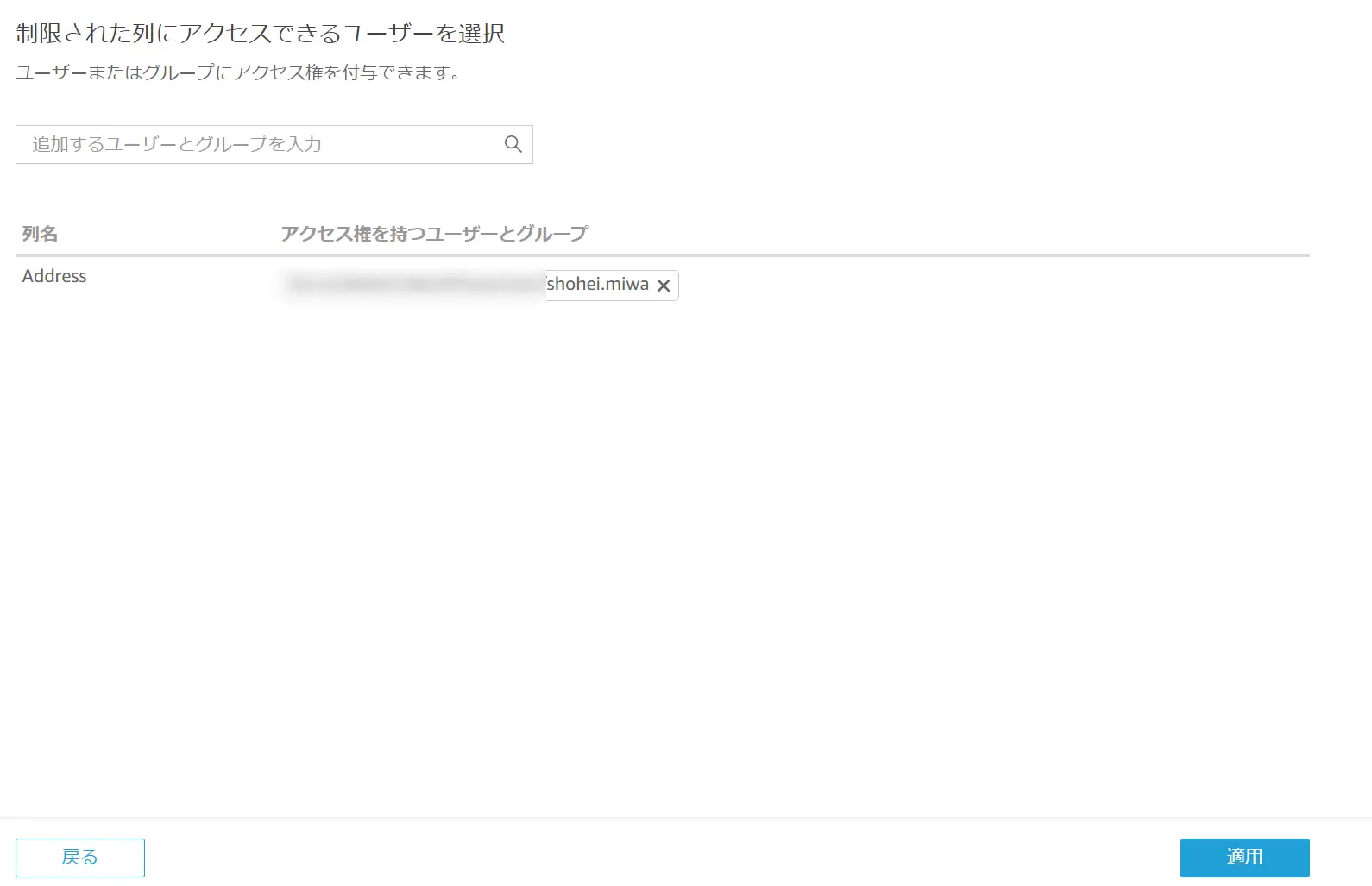
CLS が設定された列を含めたダッシュボードを公開すると、アクセス権が付与されたユーザーからは全てのデータを確認出来ますが、権限が付与されていないユーザーからは、 CLS が設定されたフィールドを含むビジュアルの参照に制御を掛かります。
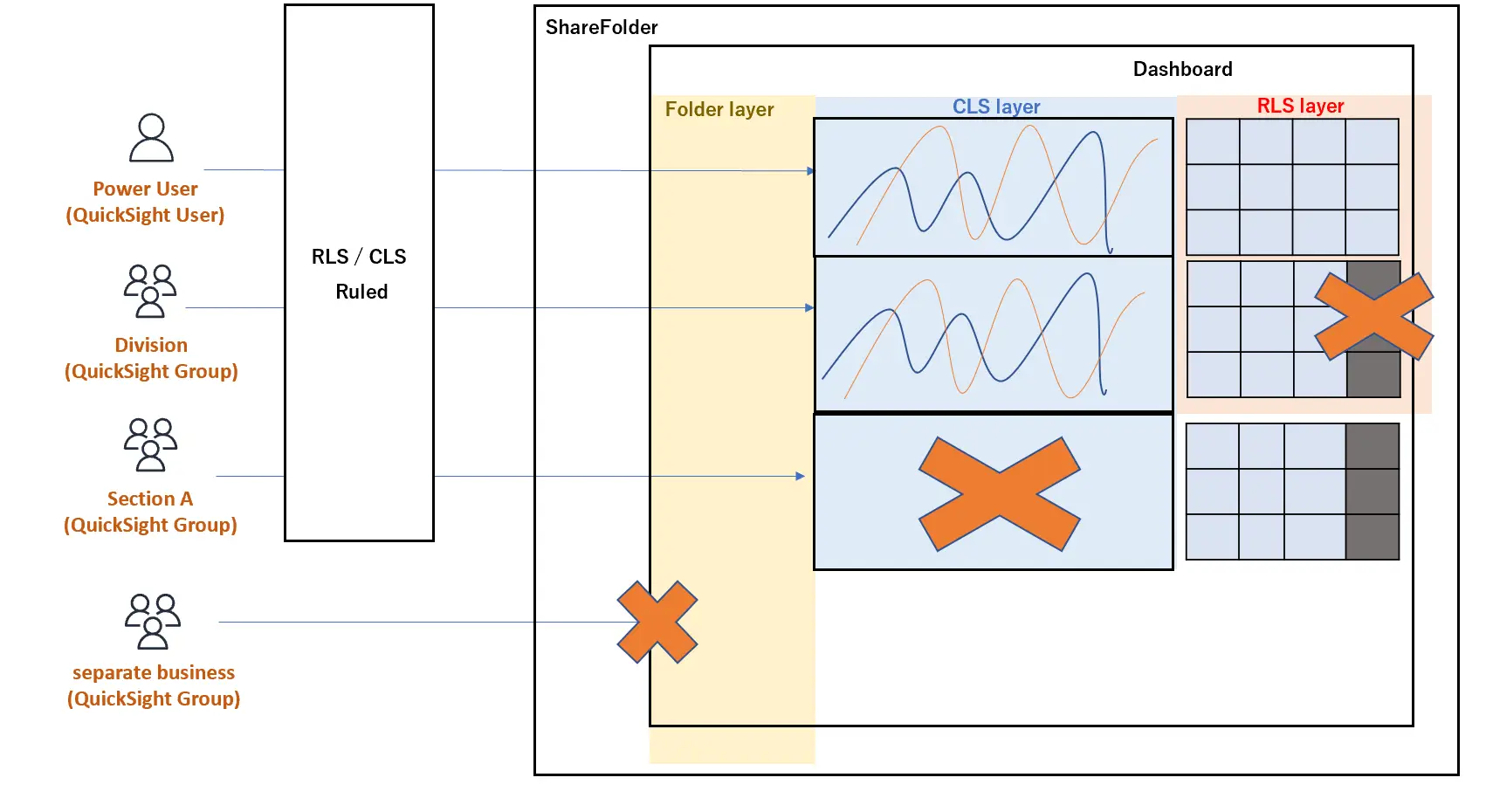
このように、データセットに紐づくルールを適切に設計する事で、アクセス制御
の用途だけではなく、ロールや部門単位毎に表示したいデータのみを表示する事が出来る、といった可視化の1つの手法であるとも言えるかと思います。
Enterprise Edition におけるユーザーは、共有フォルダによるアセットレベル、CLS によるビジュアルレベル、RLS によるフィールドレベルな制御を可能にします。
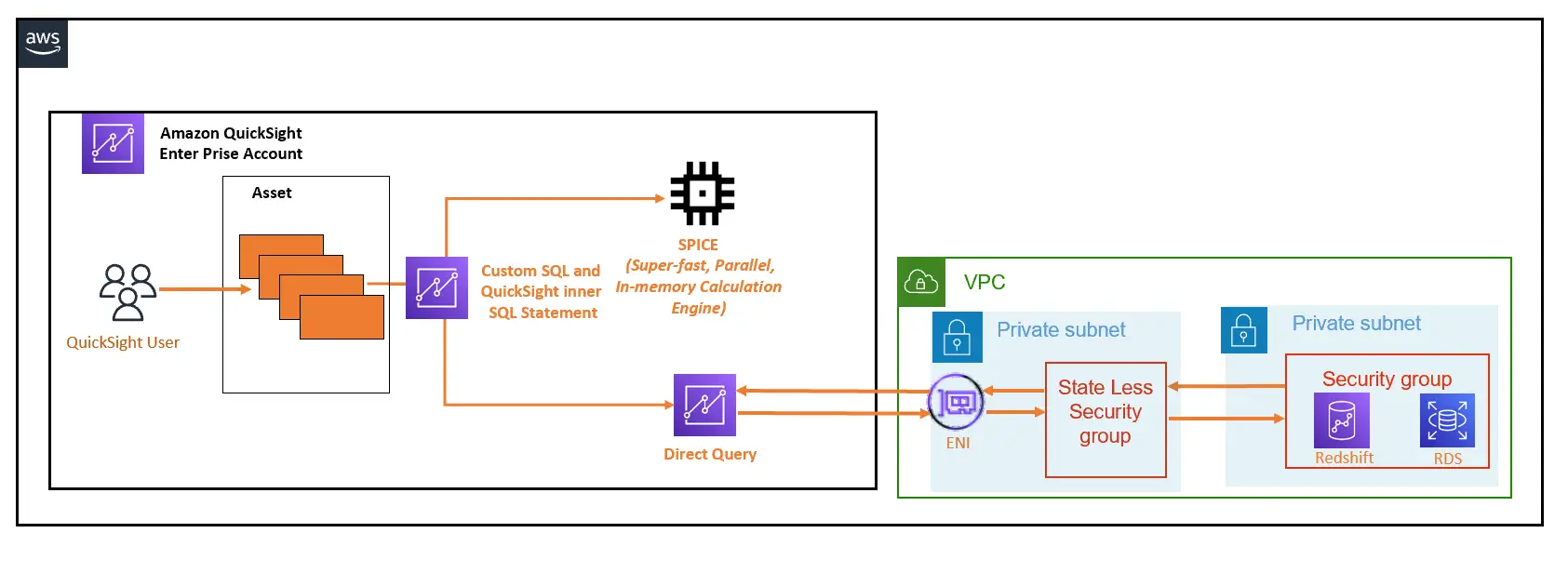
3. Physical Data Source Connction (物理データソースへのアクセス)
以下の例では、RDS や RedShift など、Private Subnet 上に払い出される AWS リソースをデータソースとしたパターン、Google Cloud の BigQuery を大元のデータソースとして S3 へデータを移行し、Glue crawler によりデータカタログを作成、Athena を SPICE へインポートするデータソースとしたパターンを表現しています。
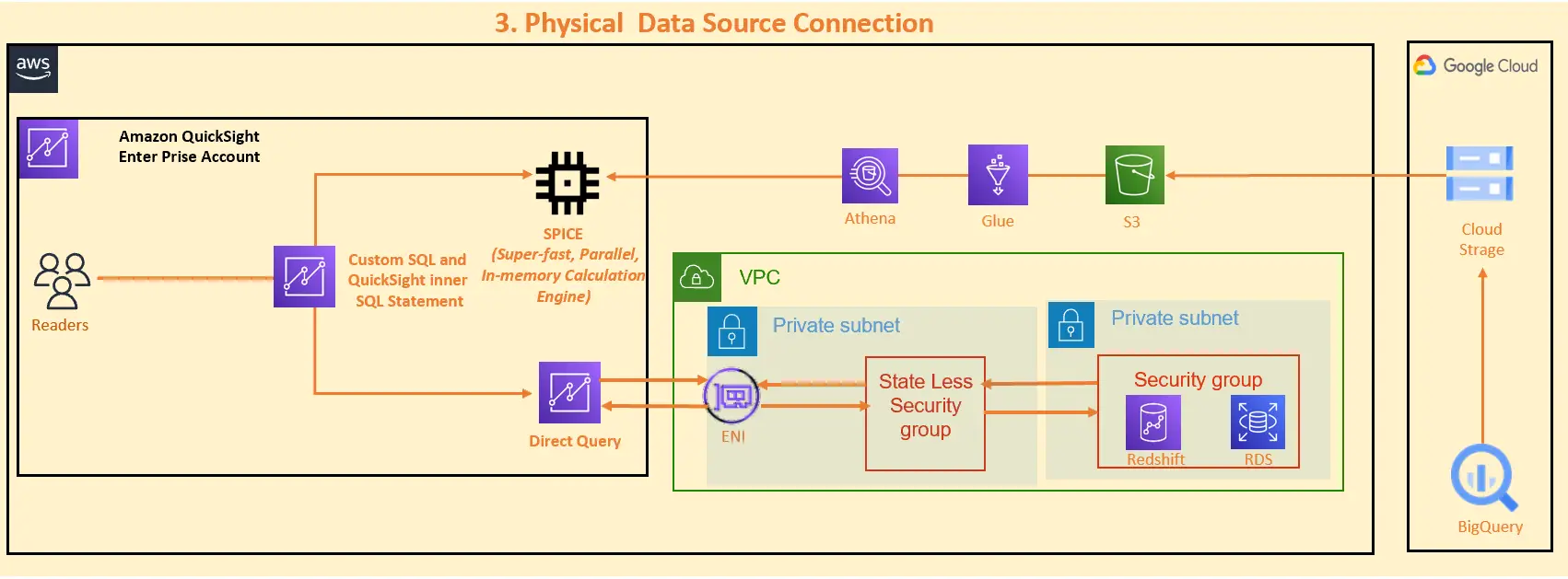
Enterprise Edition では、特定のVPCに対してプライベートな接続をサポートします。Amazon QuickSight 用のセキュリティグループを払い出し、データソースとのアクセスを行います。
注意点として、AWS QuickSight のネットワークインターフェイスにアタッチされているセキュリティグループは通常利用のステートフルとして機能せず、ステートレスな通信を行います。また、特定のアウトバウンドトラフィックのみを許可するアウトバウンドルールを設ける事が推奨されています。
参考情報 セキュリティグループ: インバウンドルールとアウトバウンドルール
なお、QuickSight は、Route 53 Resolver のインバウンドエンドポイントをセットアップして、クエリを間接的に実行することが可能です。QuickSight でインバウンドエンドポイントを使用する際、 エンドポイントの IP アドレスを入力します。
Query Mode (SPICE or Direct Query)
Amazon QuickSight では、作成されたダッシュボードを閲覧する際に Direct Query によりデータソースへ直接アクセスするか、SPICE へのアクセスを都度行うか、いずれかを選択します。
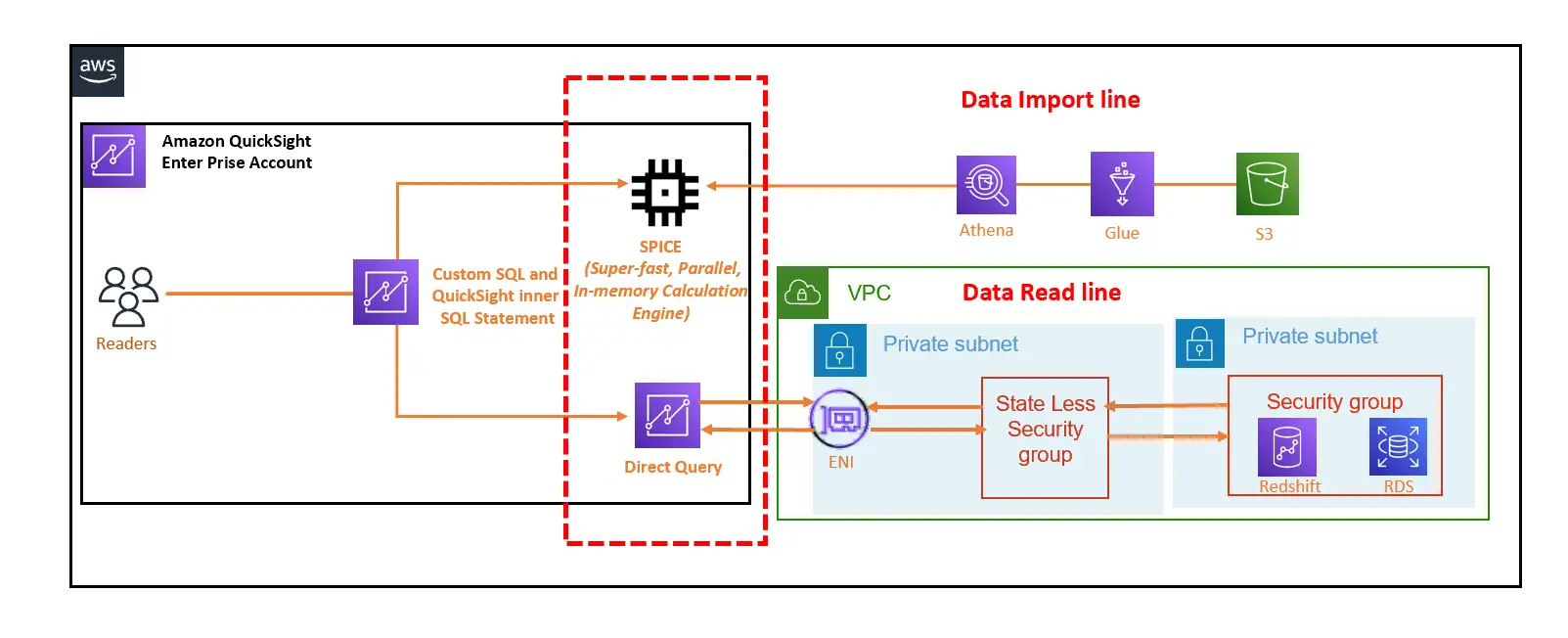 これは、データセットを作成する際に DirectQuery による接続、あるいはSPICE(Super-fast, Parallel, In-memory Calculation Engine ) にデータをインポートしてアクセスするか、いずれかを選択します。これをQuery Mode といいます。
これは、データセットを作成する際に DirectQuery による接続、あるいはSPICE(Super-fast, Parallel, In-memory Calculation Engine ) にデータをインポートしてアクセスするか、いずれかを選択します。これをQuery Mode といいます。
SPICE に保存されたデータは、追加のコストを発生させることなく複数回再利用できますが、クエリごとに課金されるデータソースを使用する場合、最初にデータセットを作成するときと、後でデータセットを更新するときにデータのクエリに対して課金されます。
また、EnterpriseEditionでは、特定のデータソースに対してスケジュールに基づいたSPICEデータセットの完全更新(Full Refresh)および増分更新(Incremental Refresh)をサポートします。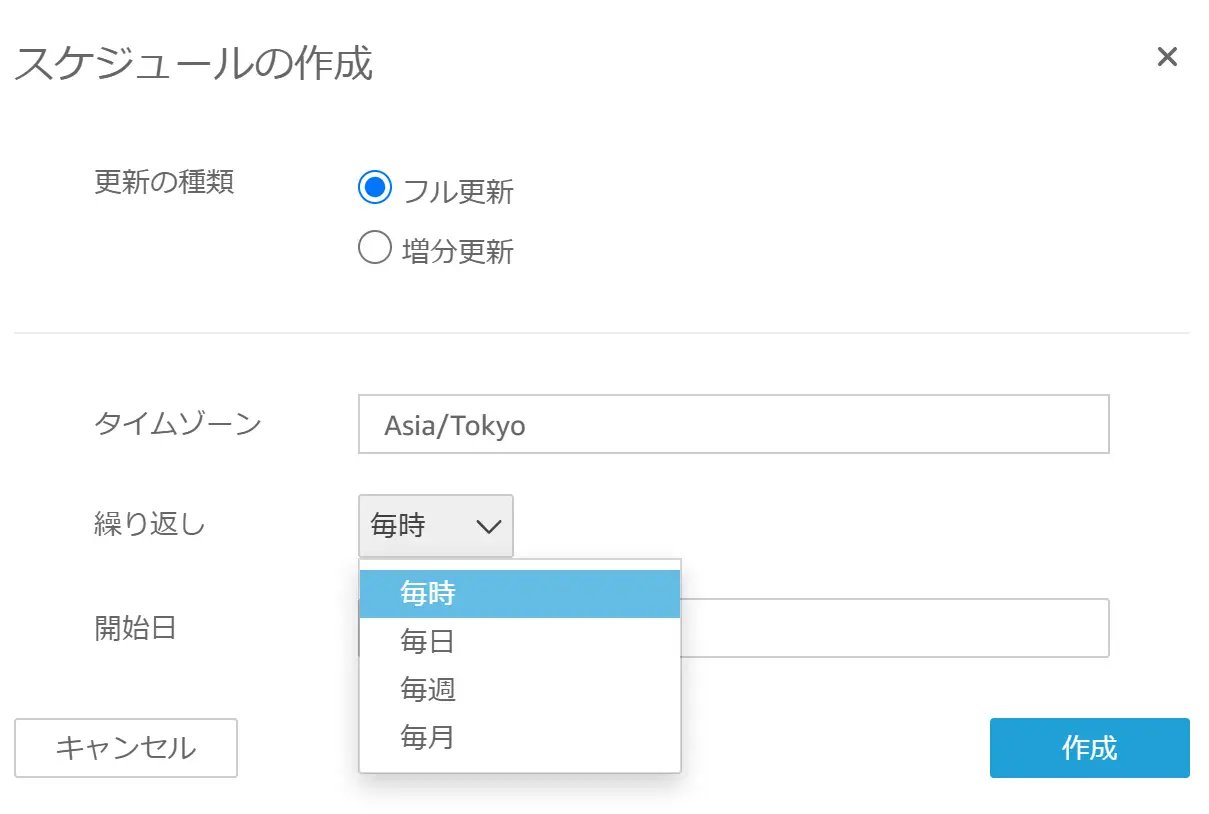
Full Refresh
日次、毎週、毎月の間隔から選択可能で、EnterpriseEdition のみ毎時をサポートします。
Incremental Refresh
Enterprise Edition のみサポートしており、15 分ごと、30 分ごと、毎時、日次、毎週、毎月の間隔から更新頻度の選択が可能です。更新するデータセットの日付フィールドをトリガーに、look back の期間を設けて対象期間のレコードを増分更新をします。
SPICE ingestion history / skipped row errors
SPICE への取り込み履歴や取り込み行数、取り込みがスキップされた行をデータセット画面から確認が可能です。
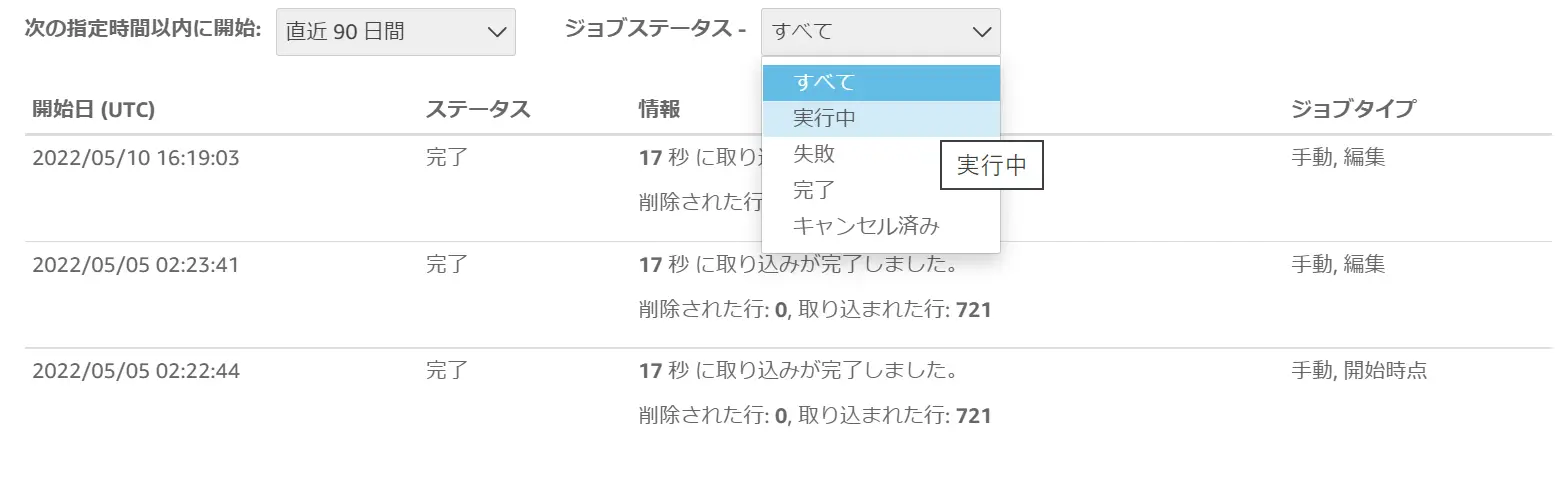
取り込み行数を確認し、任意のインポートが完了しているかどうか、また、取り込みに失敗した更新処理や、スキップされた行のトラブルシュートも可能となります。なお、取り込みがスキップされる要因はある程度パターンが決まっているようです。これらを事前に認識しておくことでトラブルを未然に防げると考えます。
For exsample to BigQuery
Amazon QuickSight では Athena Fedrated Query をデータソースとしてサポートしています。先日、Athena Fedrated Query は新たに BigQuery のデータソースコネクタをサポートしました。
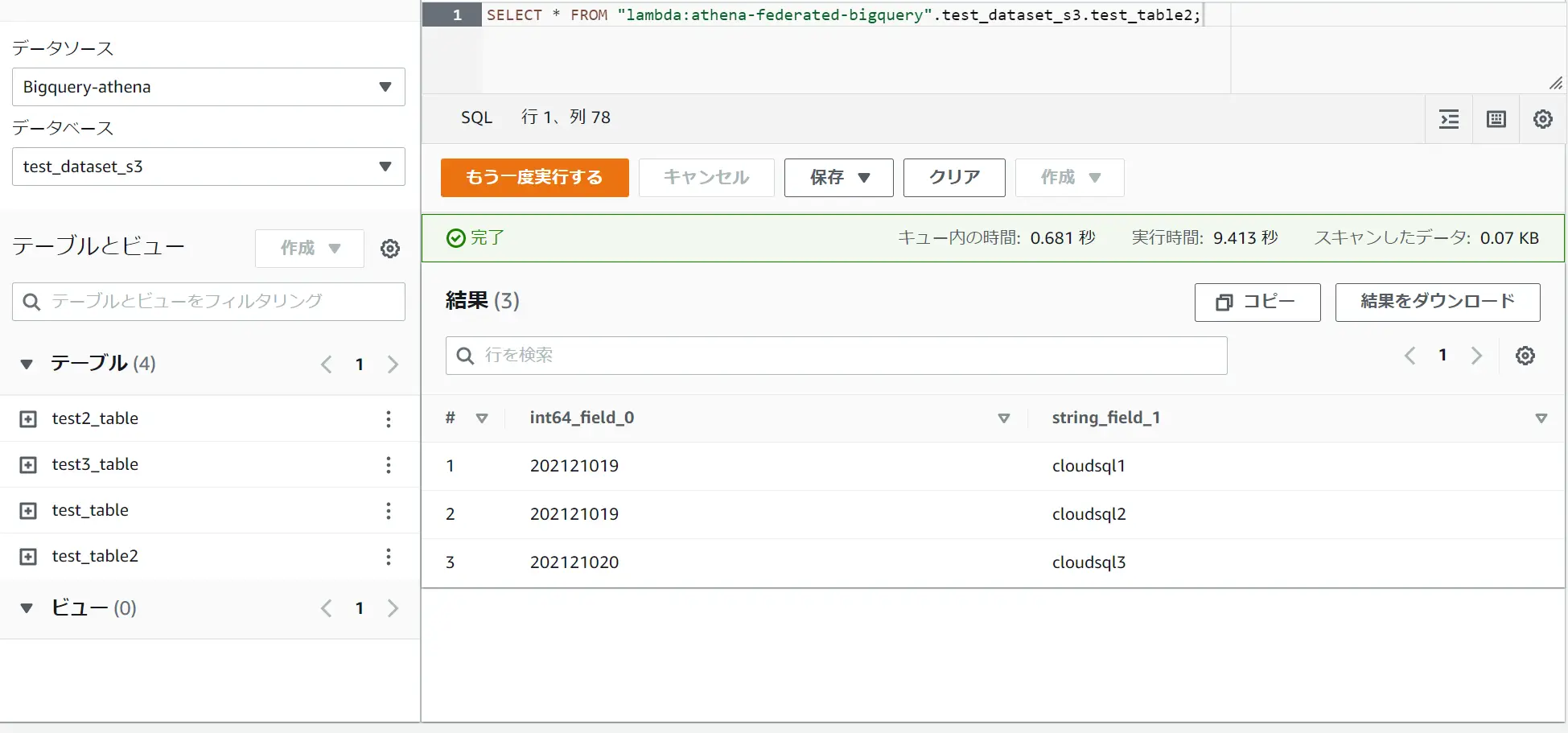
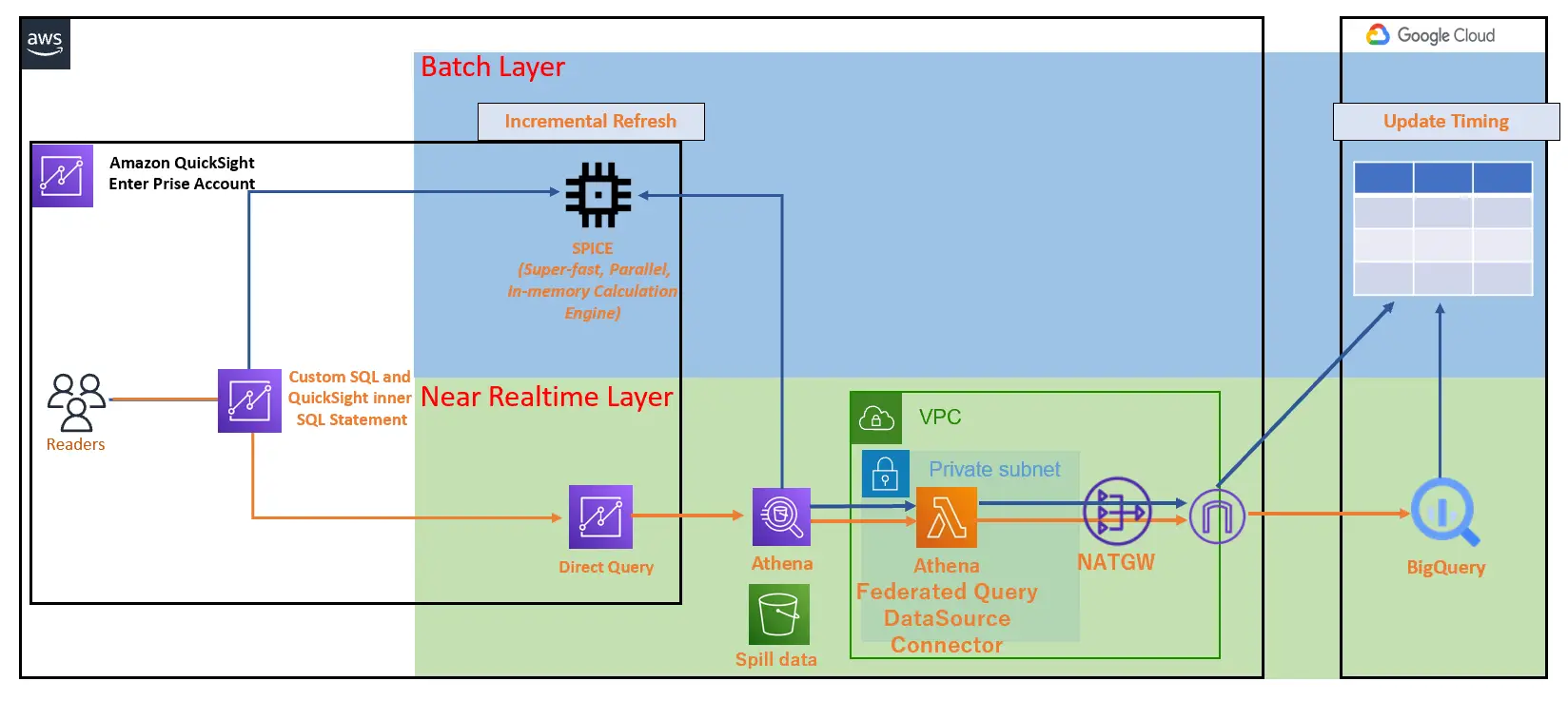
先述の Incremental Refresh をベースにした更新タイミングに応じたSPICEデータセットの反映(Batch Layer)、Athena Federated Query を使用してDirectQuery からダイレクトにアクセスを行う(Near Realtime Layer) といった実装パターンが考えられるかと思います。
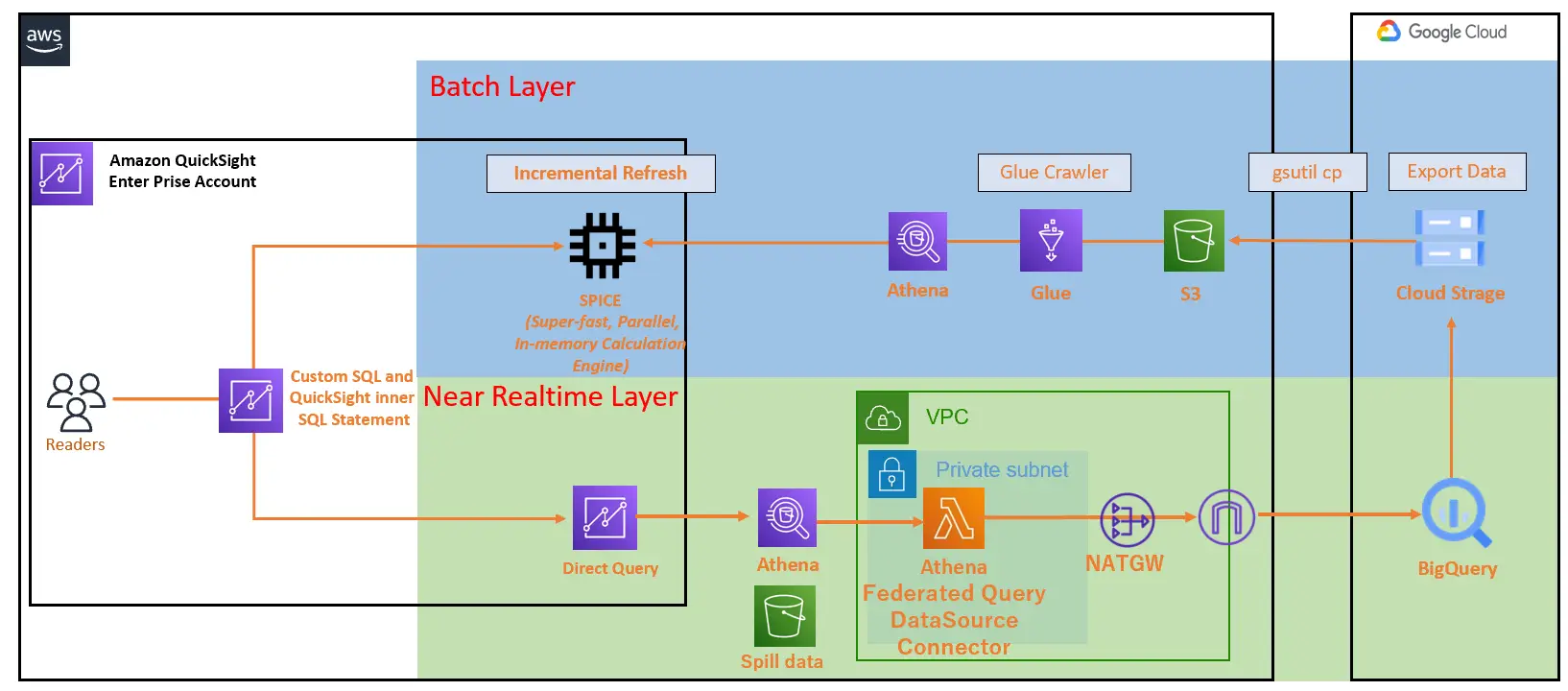
BigQuery と Athena の接続間には データソースコネクタ が必要となります。これは Serverless Application が Lambda Function としてソースを公開しています。QuickSight のデータソースから Athena Fedrated Query を使用するデータソースを選択し、更に DirectQuery を選択した場合、これらを元に公開されたダッシュボードは、アクセスするのに都度 Lambda を実行してBigQuery へと接続を行う挙動になります。
つまり、ダッシュボードが表示されるスピードは Lambda を介する事を考慮する必要があります。このため、SPICE にデータを保存して任意のタイミングでRefresh 処理を行う事が望ましいと考えられます。
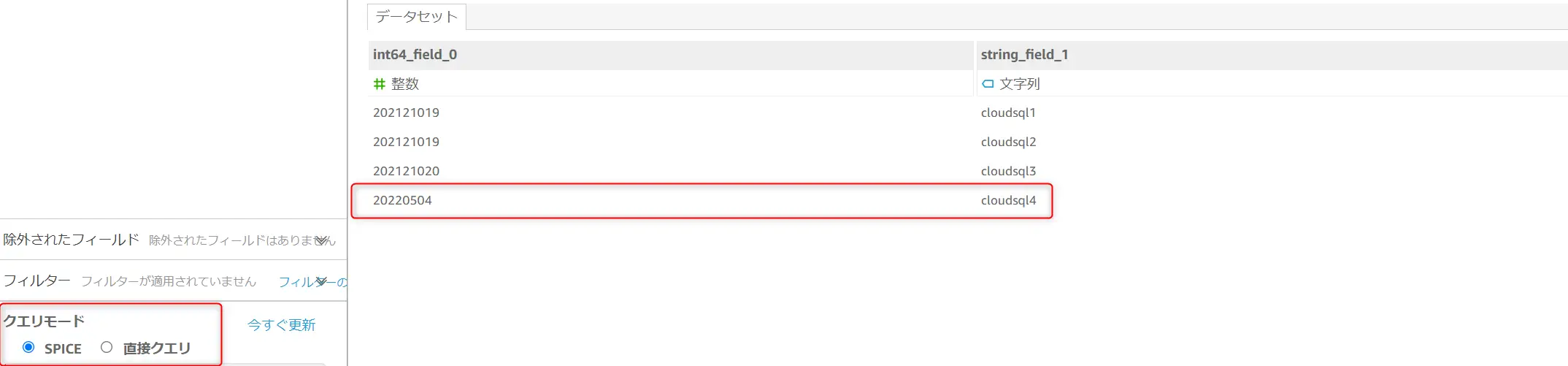
Custom SQL Query
データセット作成時に カスタムSQLクエリを使用する事が可能です。

カスタムSQLクエリとは、Amazon QuickSight 上で実行される SQL Statement です。データソースから抽出したデータの整形するよう、カスタムSQLクエリ を使用します。
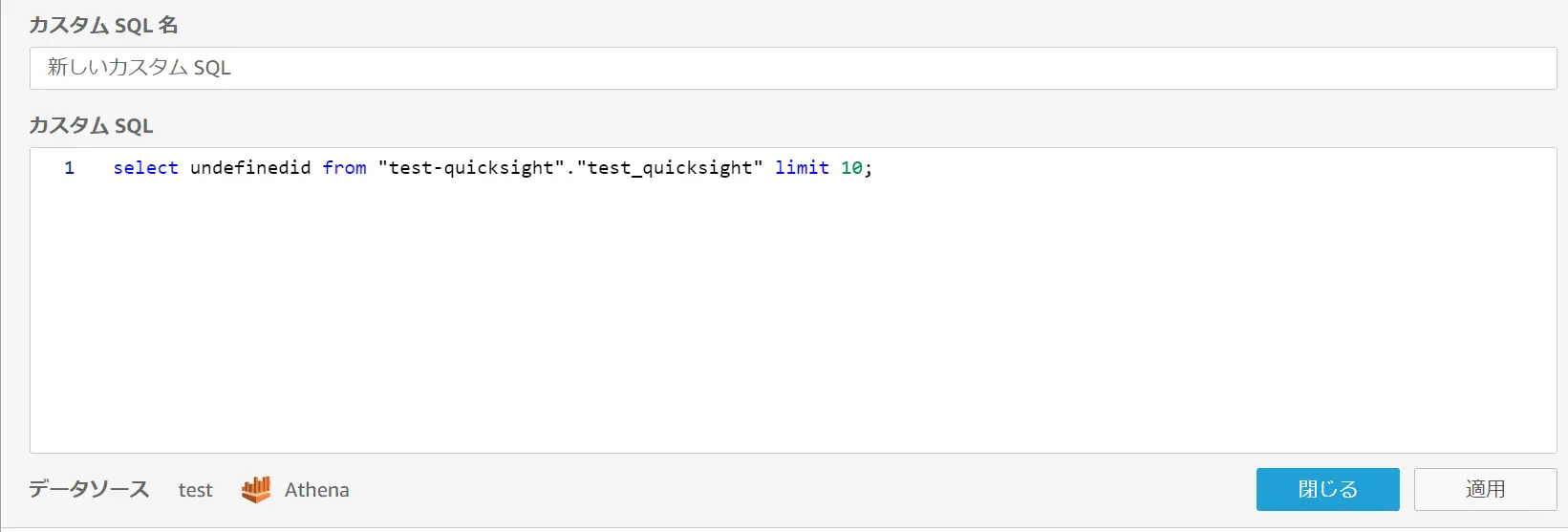
データソース側でのデータ形式の調整が出来ない場合や、テーブルの特定のカラムを Amazon QuickSight で表示させたい場合、カスタムSQL クエリを使用します。なお、作成済のカスタムSQL(データセット)に対して定義したクエリを変更する事も可能です。
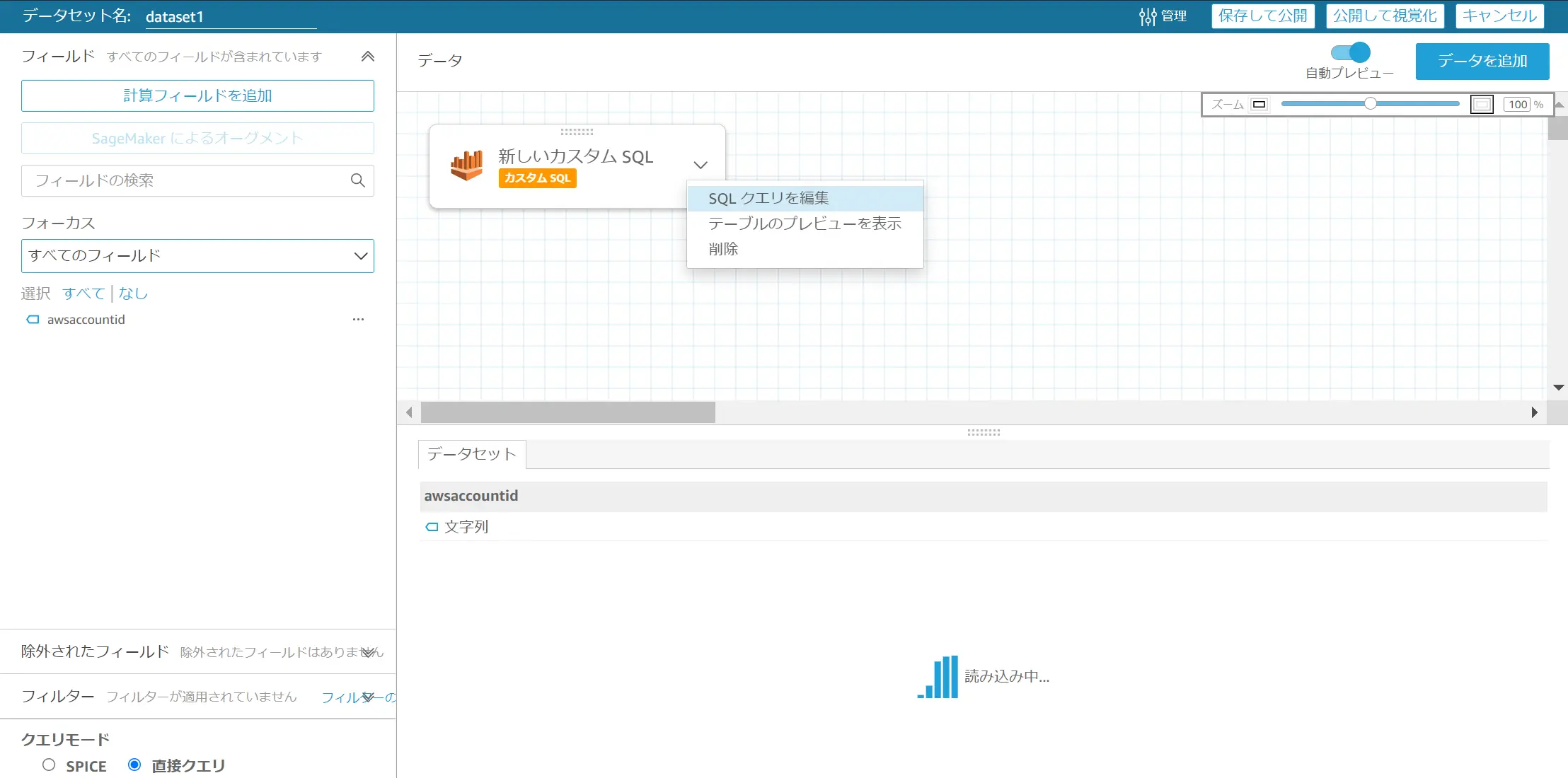
Amazon QuickSight は、データソースの列にサポートしていないデータタイプが存在する場合、データの準備中に SQL クエリを使用して CAST あるいは CONVERT コマンド等によりフィールドのデータタイプの変更しています。
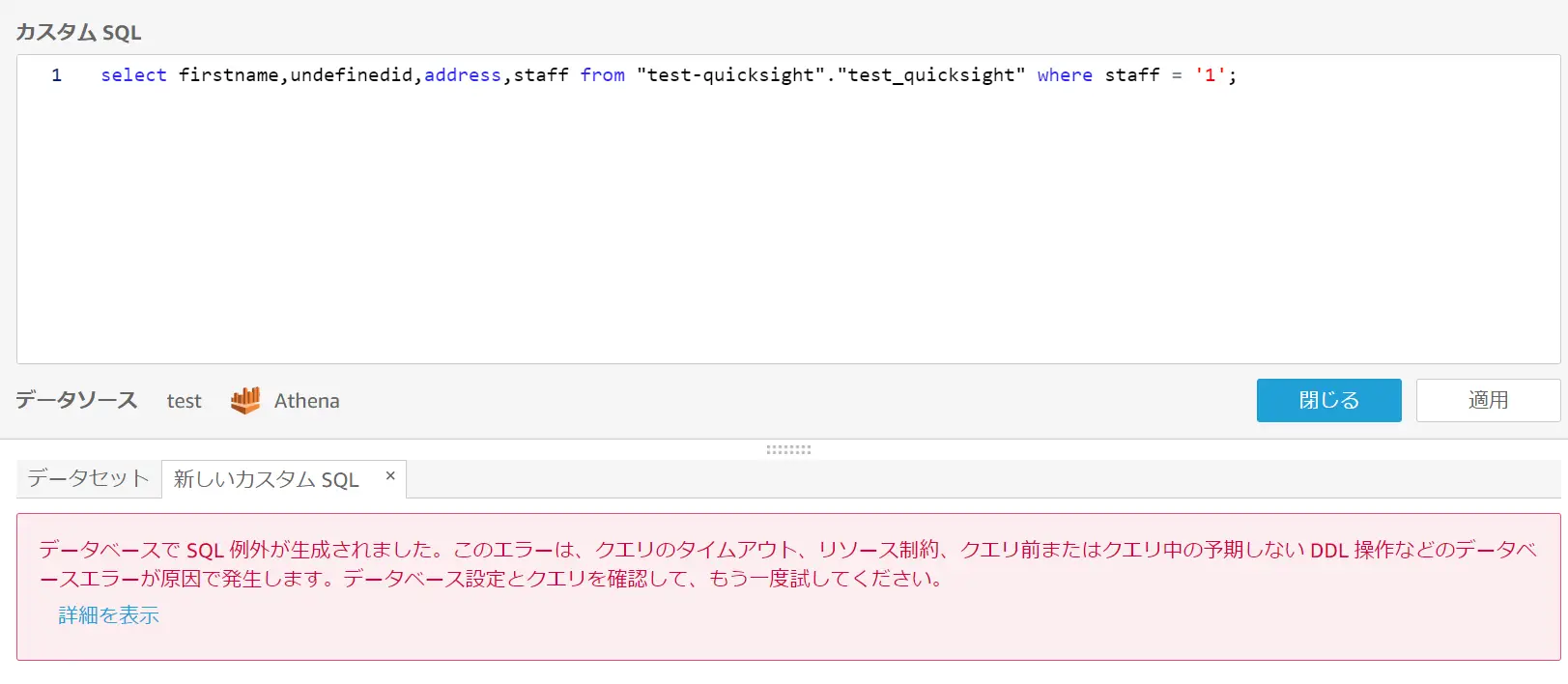
Custom SQLクエリは、データソースの要件に準拠する必要があるようで、例えば、以下図の staff フィールドは Athena 上 BOOLEAN 型で登録されていますが、QuickSight では整数型へと CONVERT が行われています。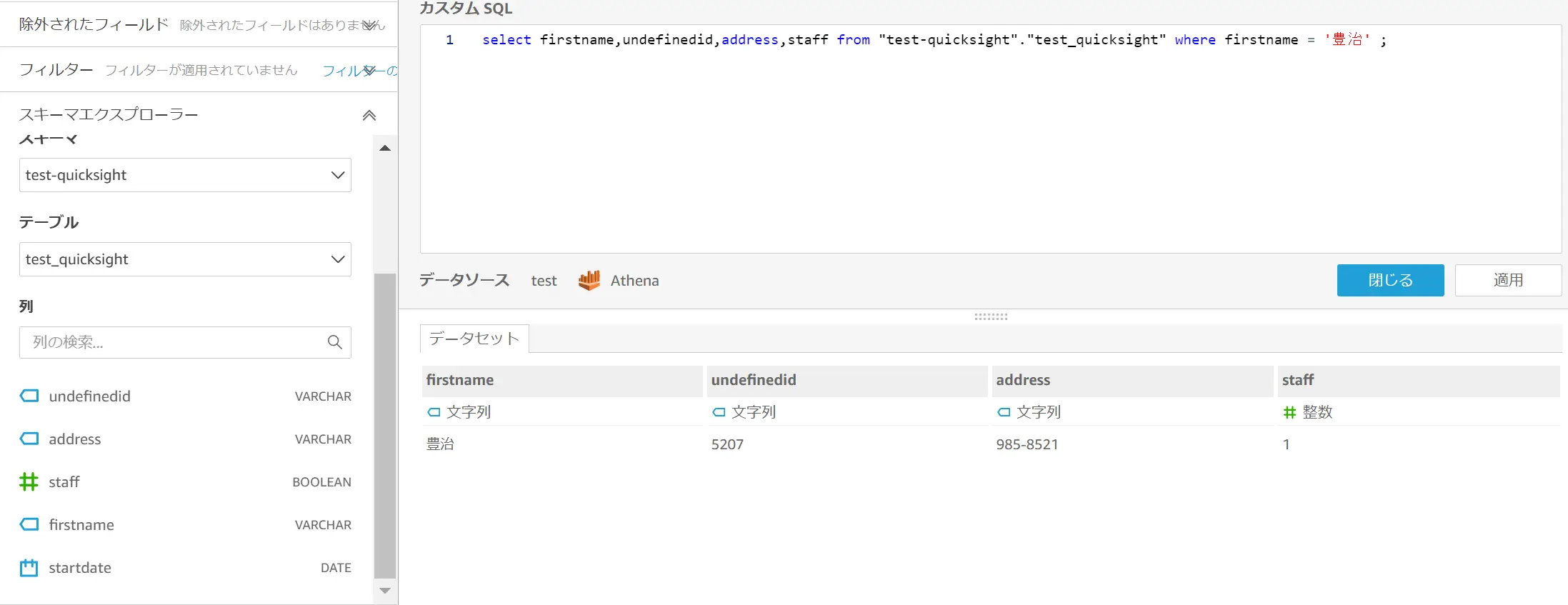
このような場合、staff フィールドの値が有効でない為、whereやgroup byなど特定の値を指定するとクエリを発行するとエラーを返します。事前に実行するクエリが有効であるかどうかは確認頂く事をお勧め致します。
Fields as a dimensions or measures and Calculated field
Amazon QuickSight は各列のデータを1つのフィールドとして認識します。フィールドは、データソースから取得したデータを、ディメンションフィールド、メジャーフィールドとして分類します。これらを元に、計算フィールドと呼ばれる新たに追加するフィールドを作成出来ます。
Measure Field (メジャーフィールド)
数値データを主に表現するフィールドであり、商品数などの任意のデータ型のフィールド、また、比較や集計などの数値項目がメジャーフィールドに該当します。
Dimension Field (ディメンションフィールド)
メジャーに関連する商品名などの属性(STRING)を示すものであり、集計をする際の分類別がディメンションにあたります。また、特定の属性を示す ID番号などの数値データや日付フィールドもディメンションに該当します。
Calculated field (計算フィールド)
データソースから認識した特定のフィールドに対して、演算子あるいは関数を用いて独自のフィールドを作成します。
フィールドとデータタイプの具体的な違いは、分析画面から顕著に出ます。フィールドは、分析で使用されるフィールドウェルに属する1つのオブジェクトとなるものに対して、データタイプは実際の数値や項目などのデータの内容を区別するものとして分別する事が出来ます。
例えば、下記のようにビジュアルのテーブルを使用した場合、メジャーフィールドとディメンションフィールドをオブジェクトとして挿入する事で、ビジュアル内のテーブルグラフのレイヤがデータタイプに沿ったデータとして表現されます。
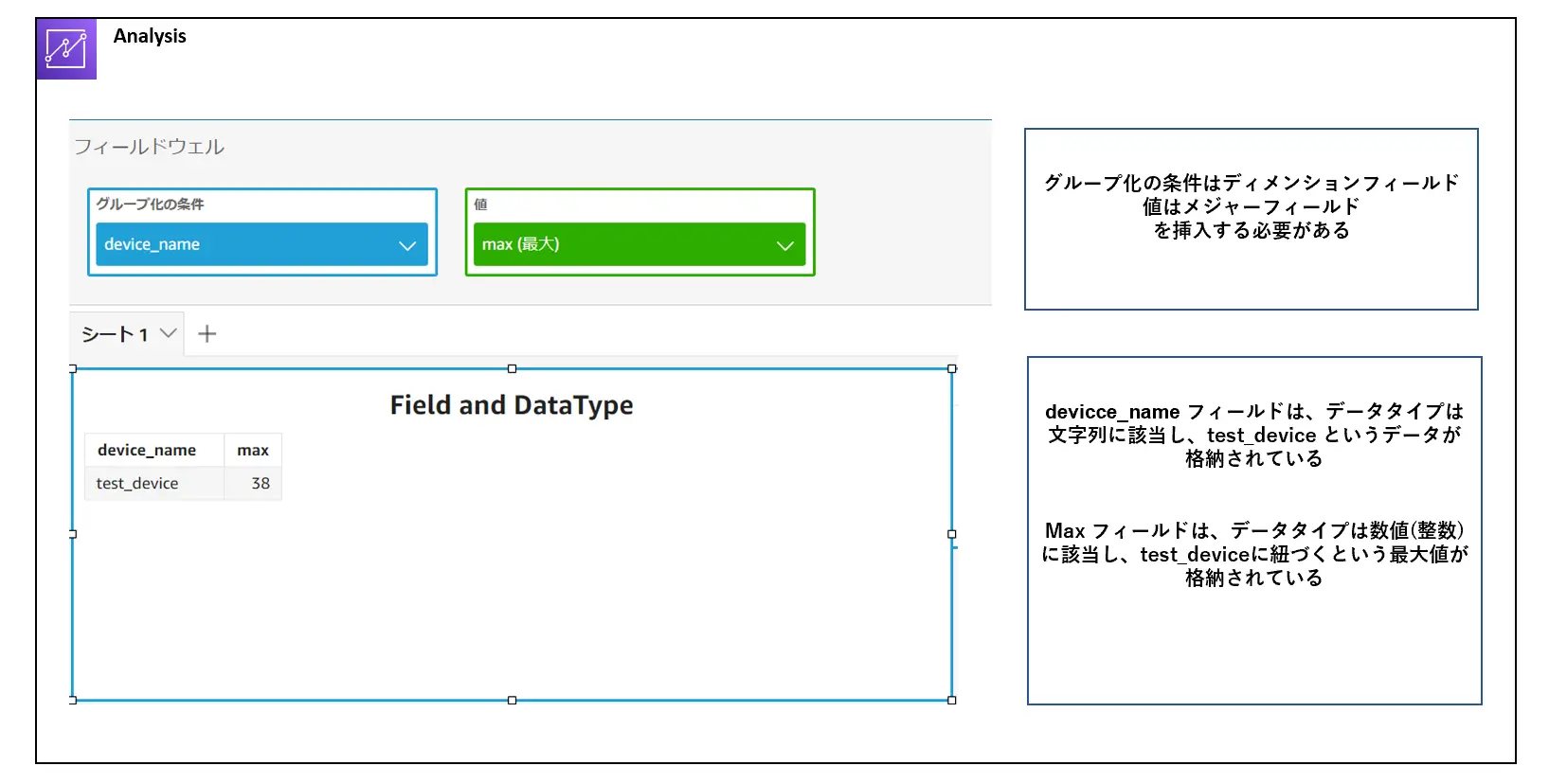
なお、メジャーフィールドとディメンションフィールドの変更は可能であり、更にはフィールドのデータタイプ自体も変更が可能となっています。
以下 Level-Aware-Aggregations では、計算フィールドを使用していきます。
LAA(Level-Aware Aggregations)
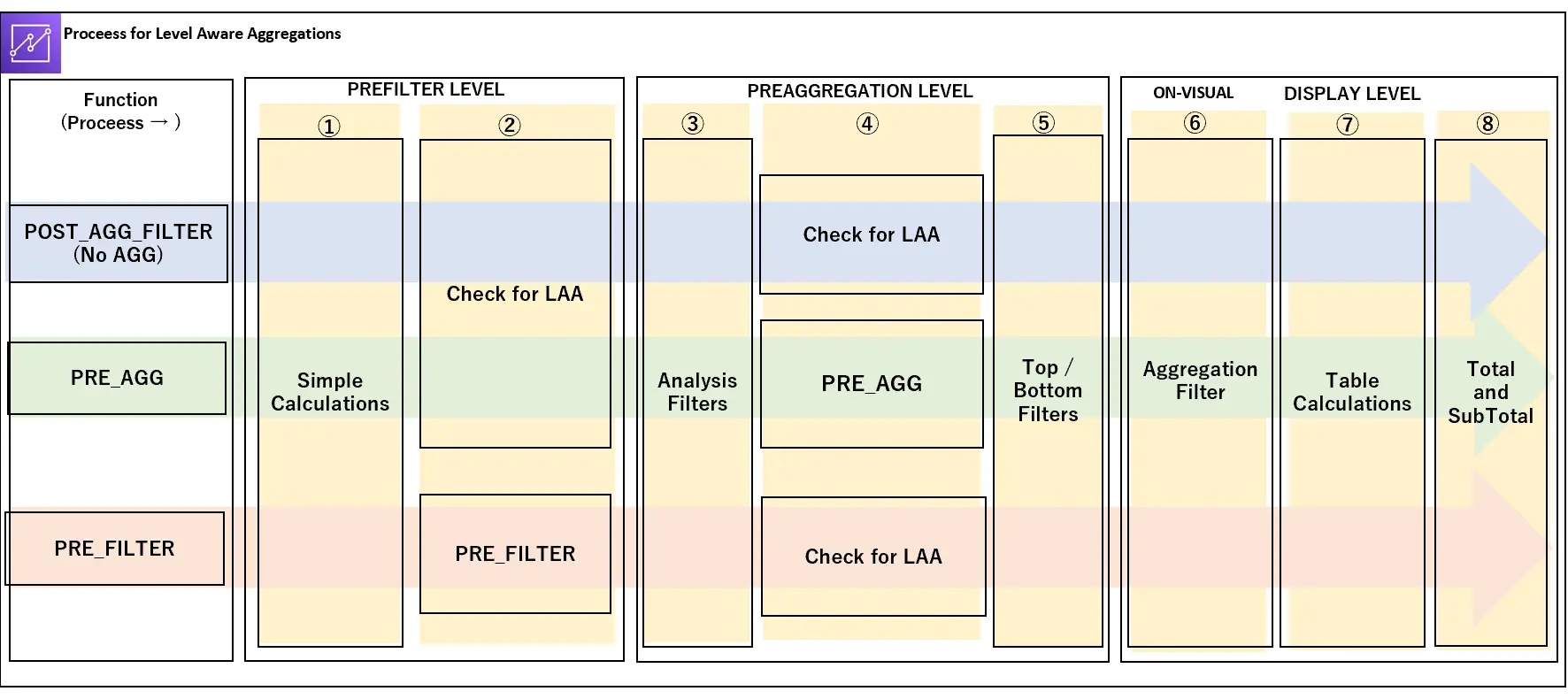
上述した計算フィールドやフィルター機能、集計を使用する際、Amazon QuickSIght は 全体的なクエリの評価順序と計算方式を決定していきます。これらの評価順序を調整する事を Level-Aware-Aggregations と呼び、以下3つの関数を用いて実装を行います。
POST_AGG_FILTER
PRE_AGG
PRE_FILTER
以下は、Analysis(分析)の内部で行われる順序であり、上記3つの関数がどのように評価を行っていくかを示しています。
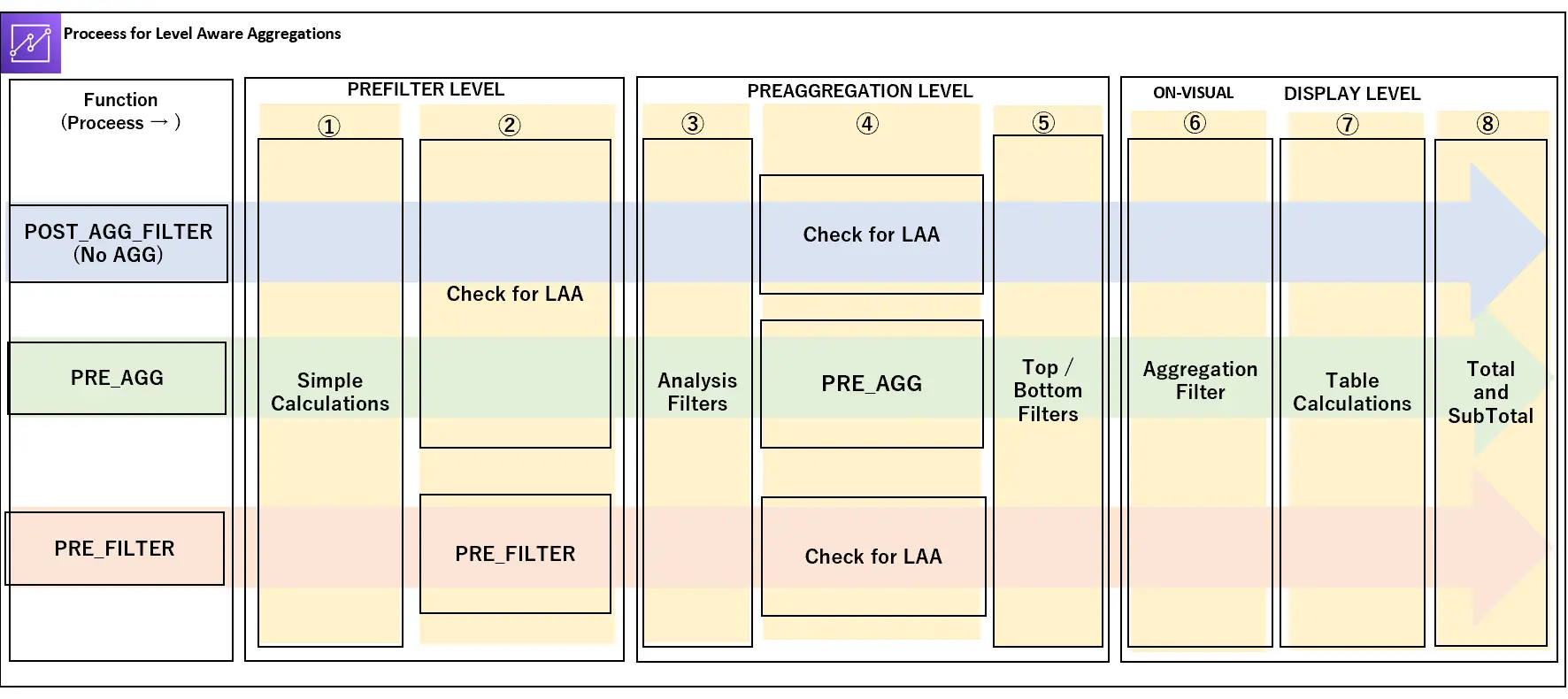
PREFILTER LEVEL - はじめに分析フィルタの前にデータの評価を行います
①Simple Calculations - 集計のない計算を行います。
② PRE_FILTER - PRE_FILTER を使用した場合、最初にPRE_FILTERの計算を評価します 。次に、これらの計算で設定されたフィルタを適用します 。
PREAGGREGATION LEVEL - 次に集計の前にデータセットを評価します
③ Analysis Filters - 分析フィルタは、ビジュアルで集計されていないフィールドのデータセットに適用されます。
④PRE_AGG - この時点で集計が適用される前に事前集計 PRE_AGG の計算を実行します。次に、これらの計算で設定されたフィルタを適用します。
⑤ Top /Bottom Filters - 上部と下部 N フィルタ - 上部と下部の N 個の項目を表示するためのディメンションに設定されるフィルタです。
DISPLAY LEVEL - 最後にビジュアルに適用された集計、テーブル計算、および残りの設定を評価します
⑥ Aggregation Filter - この時点でフィールドウェルにあるフィールドに基づいて集計を実行します。次にHAVING句と同様に、これらのフィールドに設定されているフィルタを適用します。
⑦ Table Caluculation - この時点で Amazon QuickSight は、表示レベルの集計に基づいてまずウィンドウ計算を実行します。次に、テーブル計算にフィルタを適用します。
⑧ Total and Sub Total - 表形式のビジュアルでリクエストされた測定の合計を計算します。
参考情報 Amazon QuickSight での評価の順序
countOver 関数を用いて実際に PRE_AGGの 仕様を確認します。
countOver 関数は、ディメンションのリストからパーティション分割されたディメンションあるいはメジャーの数を表現します。
countOver ( measure or dimension field ,[partition_field,・・] ,calculation level )参考情報: countOver
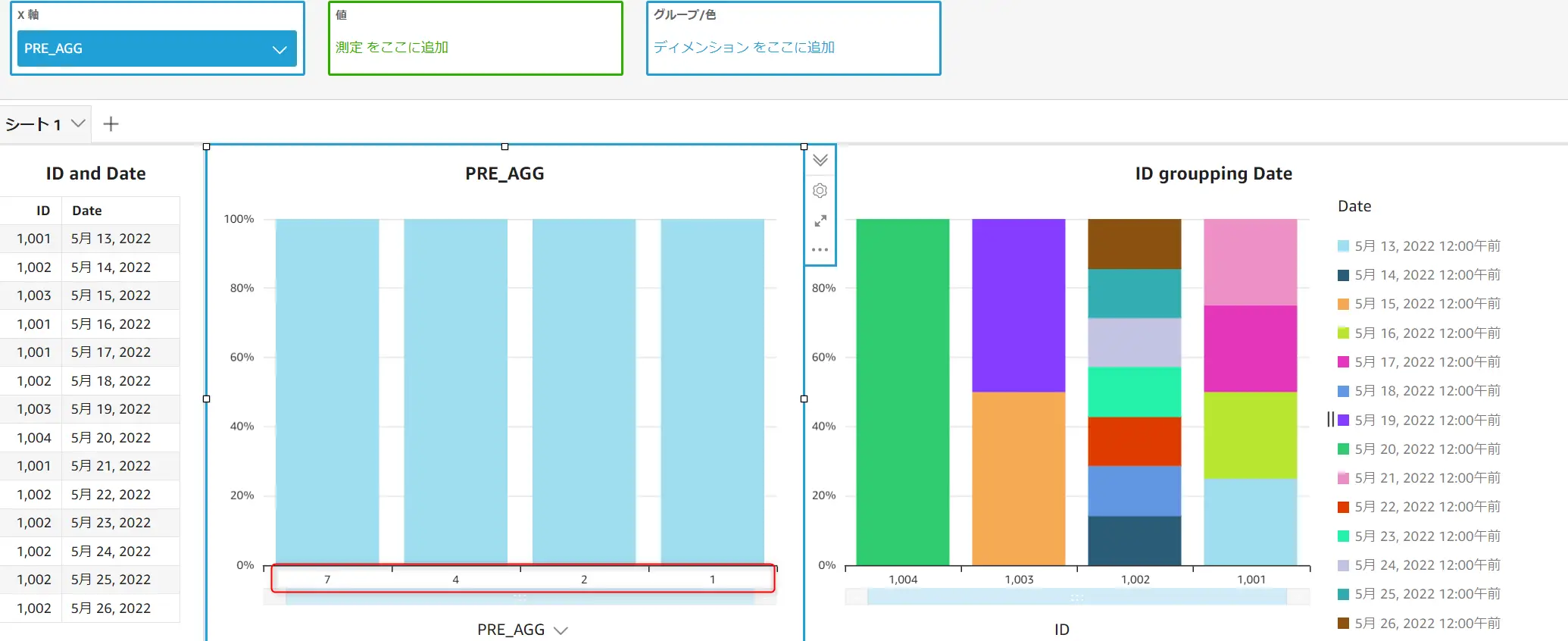
以下の例では、ID フィールドと Date フィールドにデータが入っています。Dateフィールドを計算を実行する第1引数とし、IDを第2引数に設定します。最後に計算レベル PRE_AGG を使用して計算フィールドを作成します。これを行う事で、ID毎にDateのカウント数をビジュアルに適用する前に計算します。
countOver((Date),[ID],PRE_AGG)実際にビジュアルに反映すると以下のようになります。上記で作成した PRE_AGG 計算フィールドを棒グラフの X軸で表現すると、ID (1001/1002/1003/1004) 毎の Date のカウント数が表示されます。これに対して、通常のIDフィールドは右図にあるように ID 1001/1002/1003/1004 を表現します。 これにより 特定フィールドがビジュアルで表現される前(PREAGGREGATION LEVEL)に集計処理を行った情報を保持している事が判ります。
Level-Aware-Aggregations では、Amazon QuickSight のデータの評価順序を適切に調整するものであり、PRE_FILTER によるデータセットをフィルタする前に計算されるもの、PRE_AGGによる集計をビジュアルに適用する前に計算されるもの、POST_AGG_FILTER (デフォルト)によるビジュアルが表示されるタイミングで計算するもの、これらを最適に利用する事で正しくデータを表示するためのソリューションとなるかと思います。
このように、物理的なデータソース、または SPICE へアクセスを行い、カスタムSQLクエリによる抽出データの整形を行います。必要に応じてLevel-Aware Aggregations によるデータの評価順序を調整します。
これらを経て、Amazon QuickSight が内部的に実行されるSQL Statement が各アセットのデータ群を表現していきます。
4. Embedded Analytics (埋め込み分析)
Amazon QuickSight Enterprise Edition はダッシュボード、コンソール画面の埋め込みをサポートします。埋め込みではユースケースに合わせた実装が必要となります。
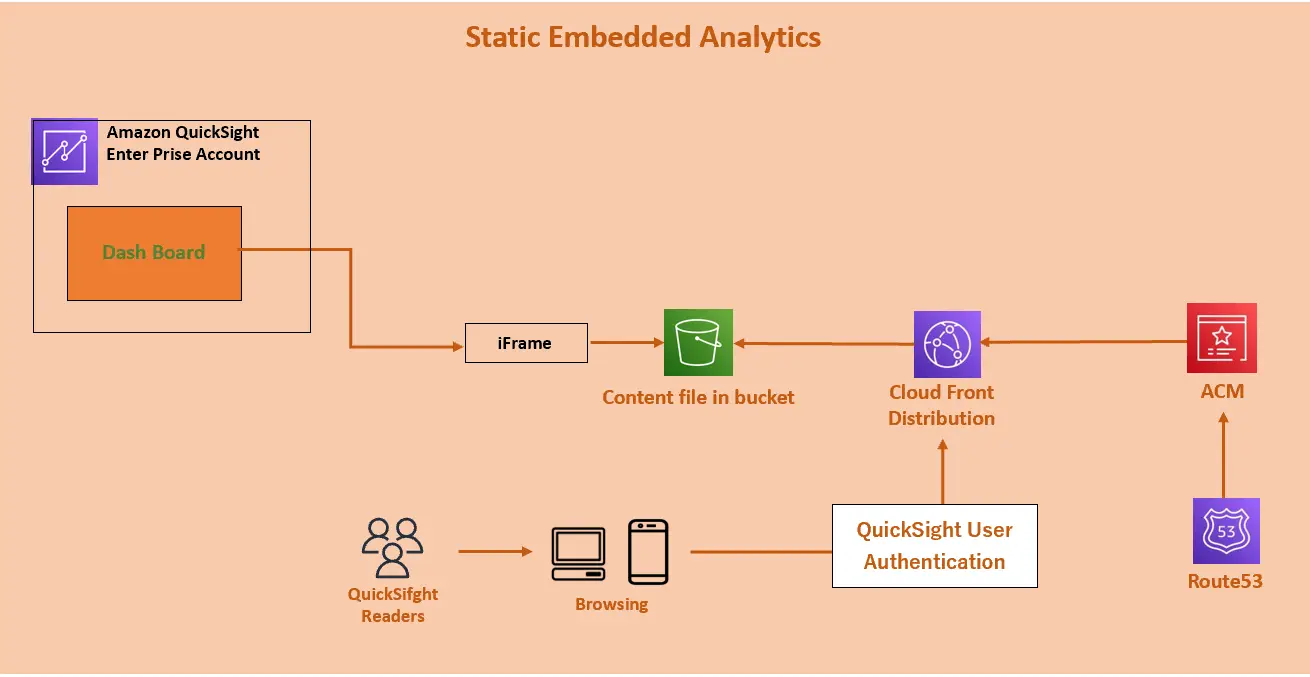
Amazon 1-click Embedded (Static Embedded URL)
Enterprise Edition では、1-click Embedded の実装をサポートします。1-click Embedded とはAmazon QuikSightによる認証 URL にリダイレクトする事でユーザー認証を実装するものであり 、 公開されたダッシュボードの HTMLコード をコピーする形でダッシュボード部の UI を生成します。
公開されたダッシュボードの埋め込みコードをコピーすると、iframe が発行されるため、これを HTML に挿入します。
HTML の一例
<!DOCTYPE html><html lang="ja" >
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width">
<title>QuickSight</title>
</head>
<body>
<h1>QuickSight</h1>
<iframe width="960" height="720"
src="https://ap-northeast-1.quicksight.aws.amazon.com/sn/embed/share/accounts/xxxxxxx/dashboards/xxxxxxx">
</iframe>
</body>
</html>
実装パターンは複数あると考えられますが、今回の例では S3 に配置したコンテンツファイルを CloudFront 経由でアクセスします。これまで 1-click Embedded はQuickSight ユーザーの認証が必須でしたが、先日、Public な埋め込みがGAされたようです。
参考情報 Amazon QuickSight 1-click public embedding
API Embedded (Dynamic Embedded URL)
上記とは異なり、API により埋め込みを生成していく方式となります。この実装方式では、QuickSight ユーザーの認証を行わず、匿名型(Anonymous)のユーザーにダッシュボードを提供していくパターンと、ユーザーベースにAmazon QuickSight のコンソール自体(Amazon QuickSight Console Embedded)を埋め込みしていく方式があります。本記事は、 Amazon Web Services よりご提供頂いている WorkShop Studio を参考とさせていただきました。
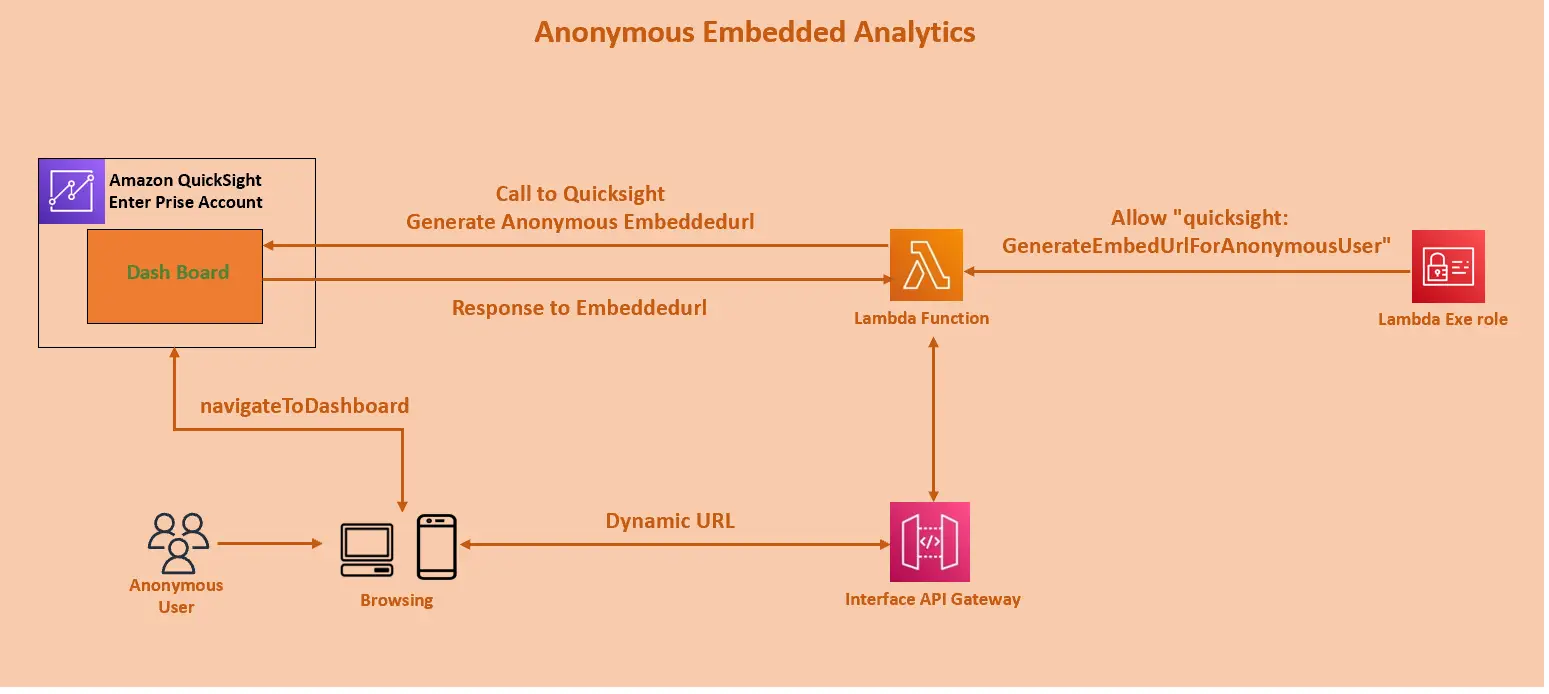
Anonymous Embedded
Amazon QuickSight における Anonymous は仮想的にNameSpaceに属し、一時的なAmazon QuickSightユーザ IDを発行したものと位置づけされています。
実装パターンとしては、Lambda Function と API Gateway を使用しています。
匿名の埋め込み分析を実装する際は GenerateEmbedUrlForAnonymousUser API が使用されます。アプリケーションが Amazon QuickSight のAPIを呼び出して、埋め込みURLを返します。Lambda は、HTMLファイルに動的なURLに含め、API Gateway 経由でブラウザに返します。
また、ユーザーが追加のダッシュボードを選択した場合、QuickSight JavaScriptライブラリー内のnavigateToDashboard関数がダッシュボードを呼び出します。
参考情報 GenerateEmbedUrlForAnonymousUser
参考情報 amazon-quicksight-embedding-sdk
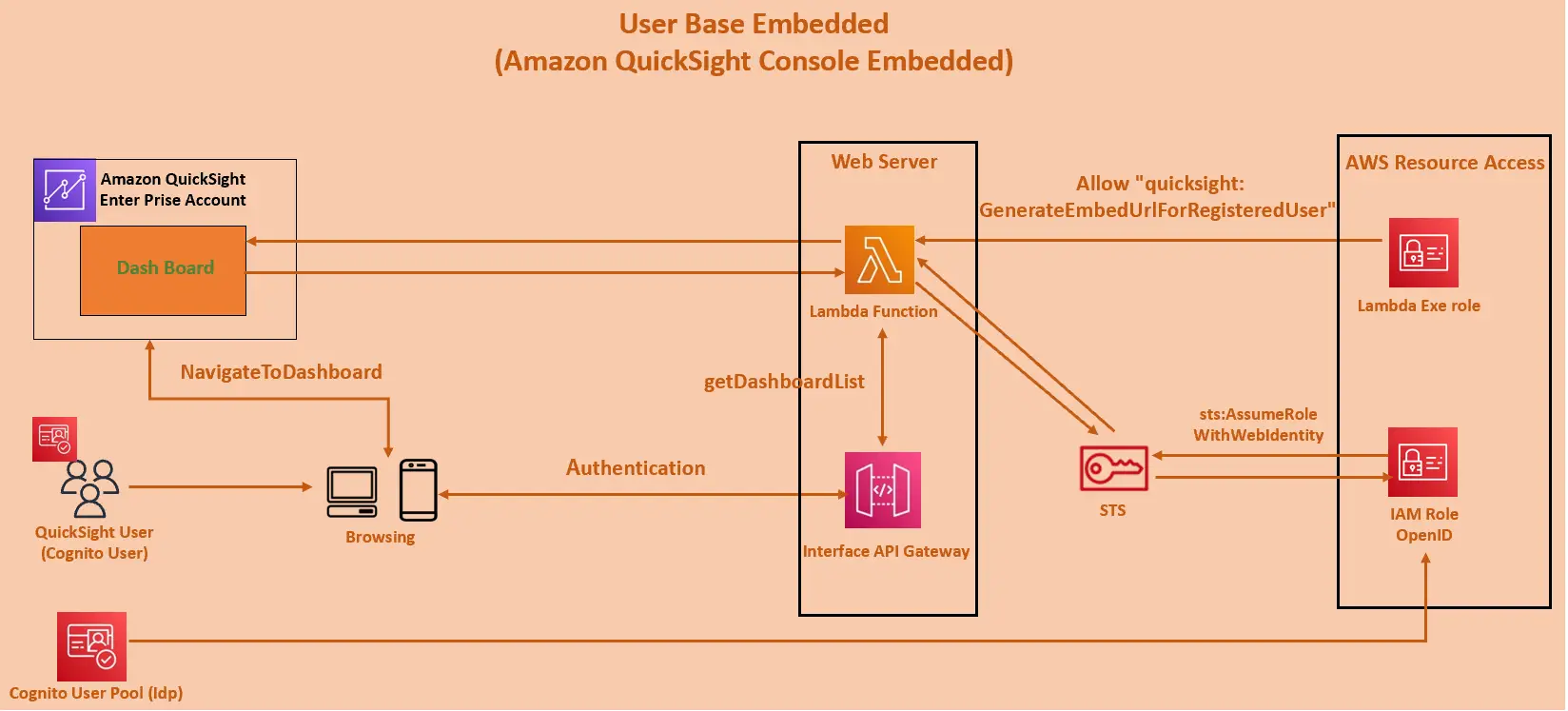
User Base Embedded (Amazon QuickSight Console Embedded)
内部的には、OpenIdトークン(OAuth)が、API Gatewayをコールし、API Gatewayがlambda関数を呼び出し、STSロールを引き受け、トークンを評価するためのみの Web Identity コールを呼び出すようです。
トークン/アサート文字列が有効の場合、lambdaはそのロールを引き受け、トークンの有効性が確認されると、ダッシュボードのリストを取得するコールと埋め込みURLを取得するコールを並列でAPI Gatewayを介して呼び出します。
なお、埋め込みURLが、特定のHTMLの DIV 内の iframe に埋め込まれており、QuickSight がセッションやダッシュボードをロードするようです。これらをNavigateToDashboard API で呼び出しする事で、同じiframeの選択されたダッシュボードをロードし、DIVを見えるようにします。
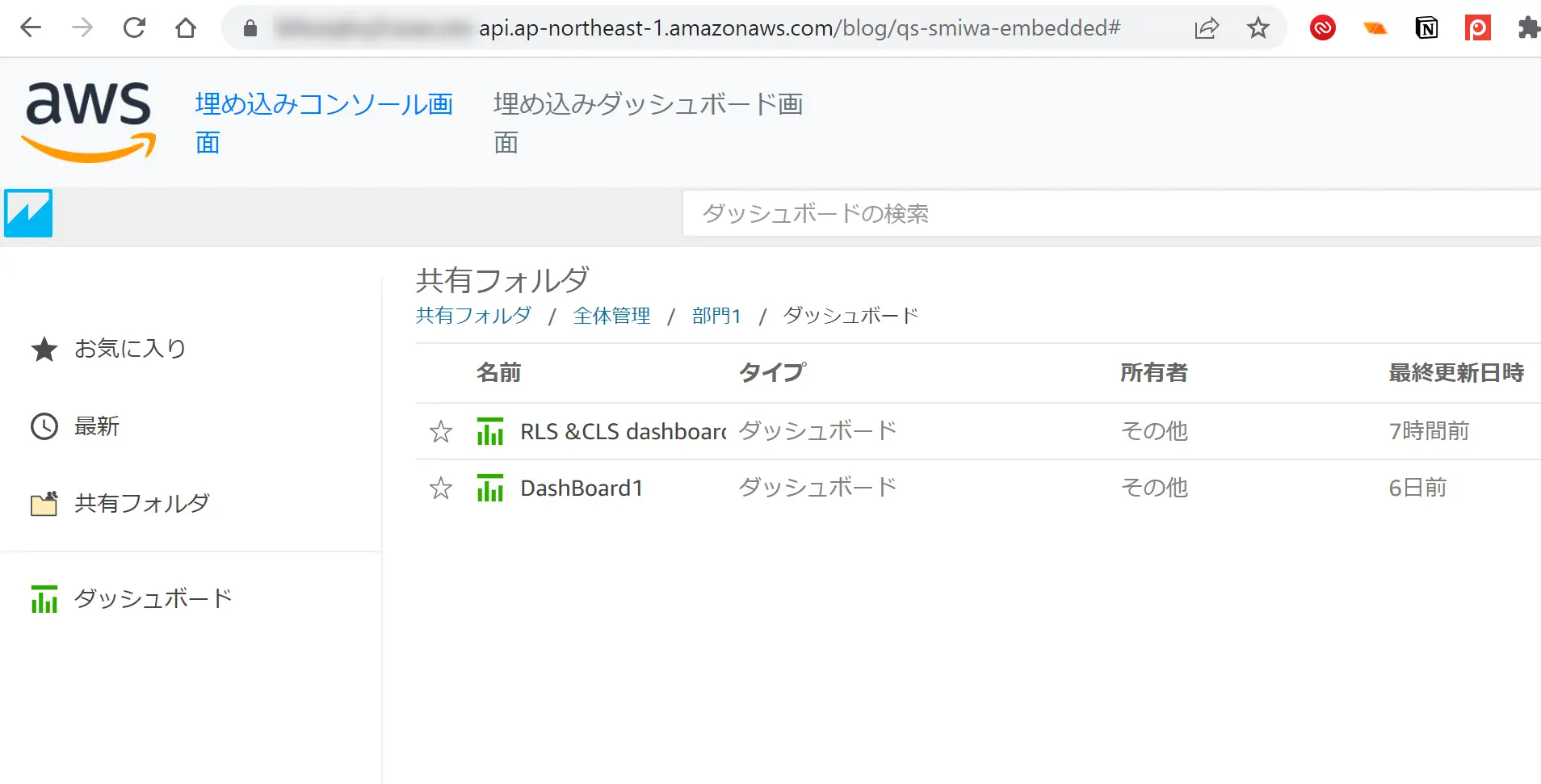
ユーザーベースの認証が完了すると、ポータルは以下のように表現され、API としての埋め込みが行われます。
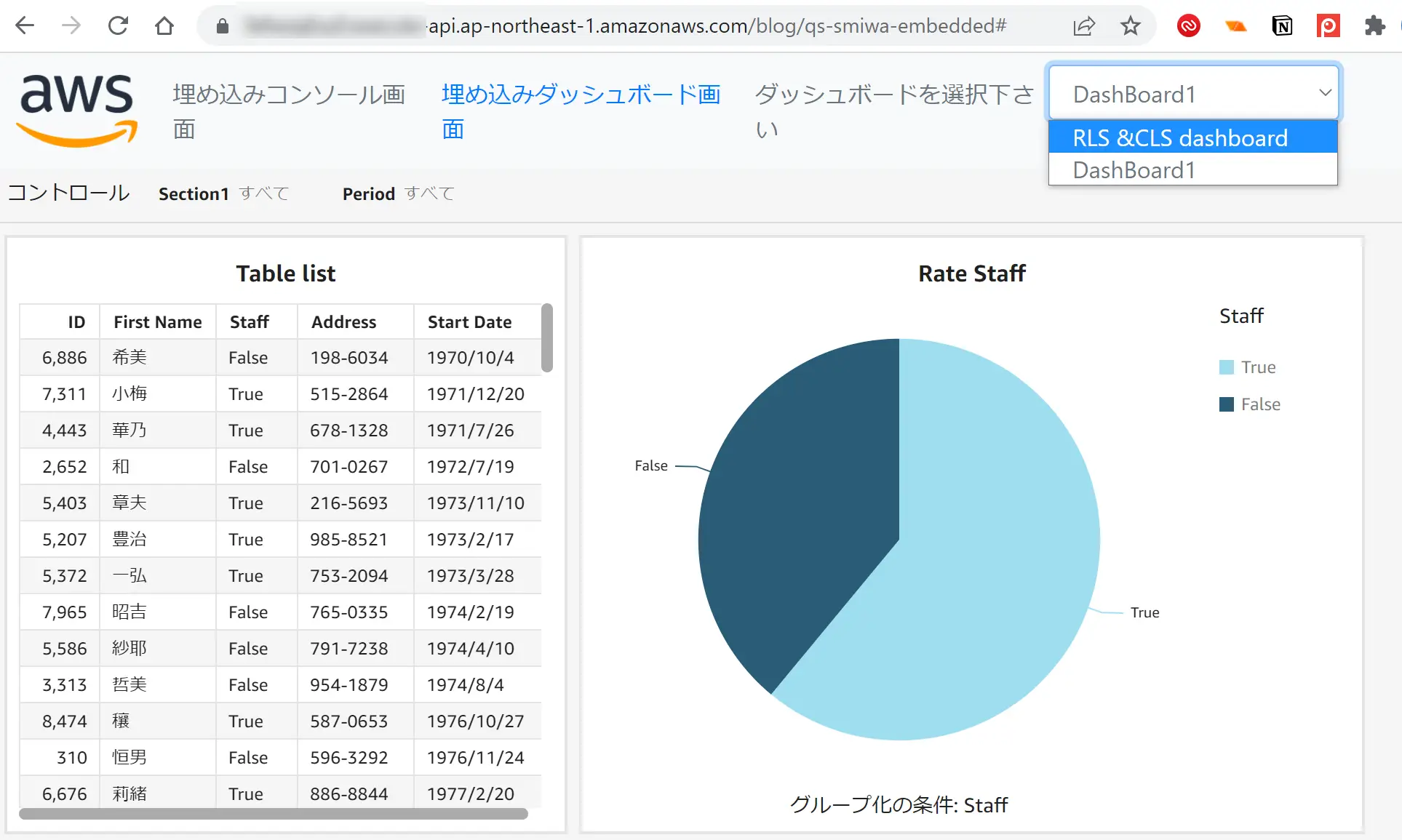
今回 AWSサービスを使用した埋め込みをご紹介しましたが、勿論SaaSへの埋め込みも可能であり、用途に沿った埋め込み方式を採用する事が良いと考えます。
Other solutions
Amazon QuickSight Enterprise Edition は用途に沿った多くのソリューションをトピック形式でご紹介できればと思います。
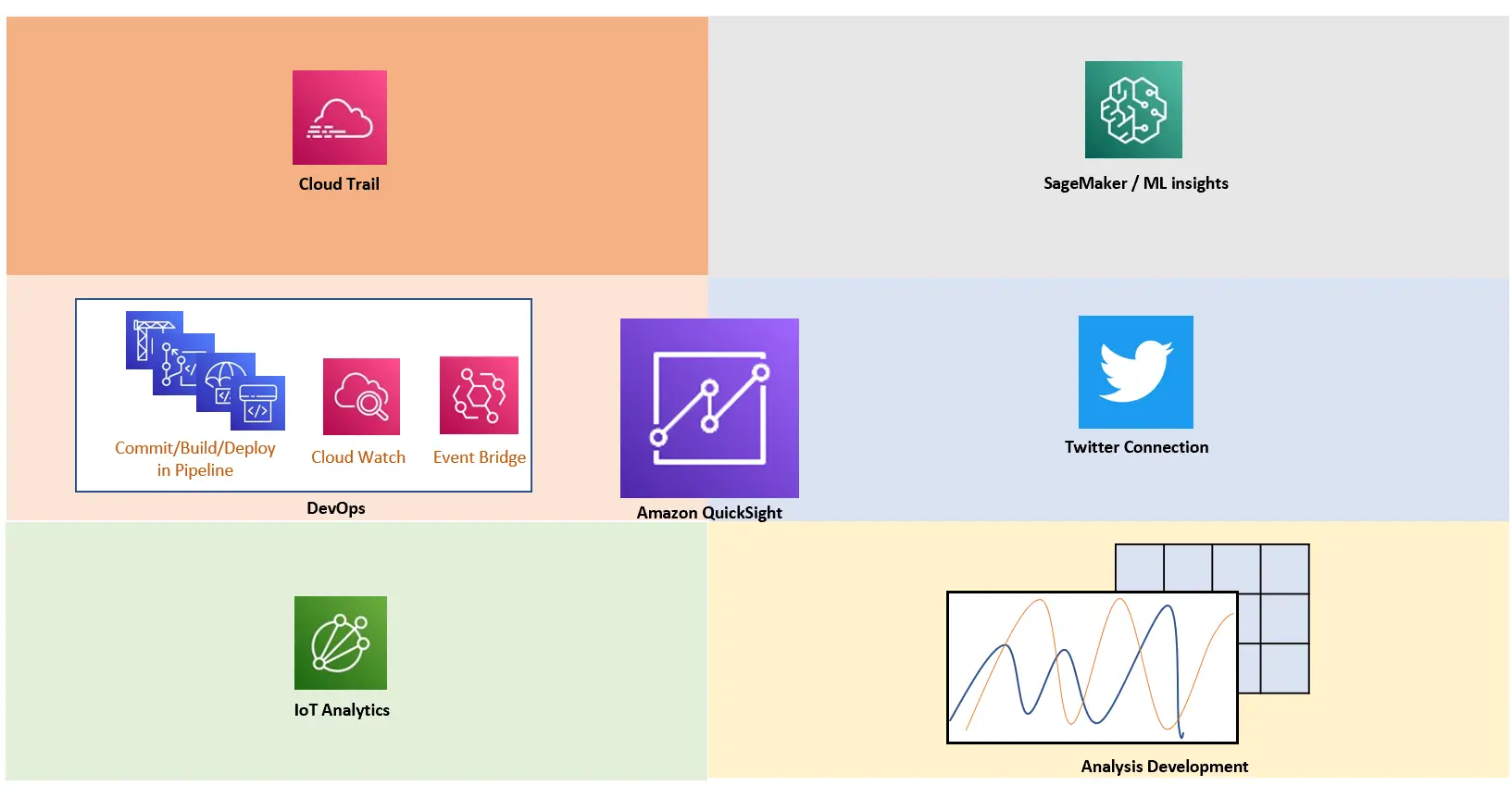
Amazon QuickSight for Incident (インシデント管理)
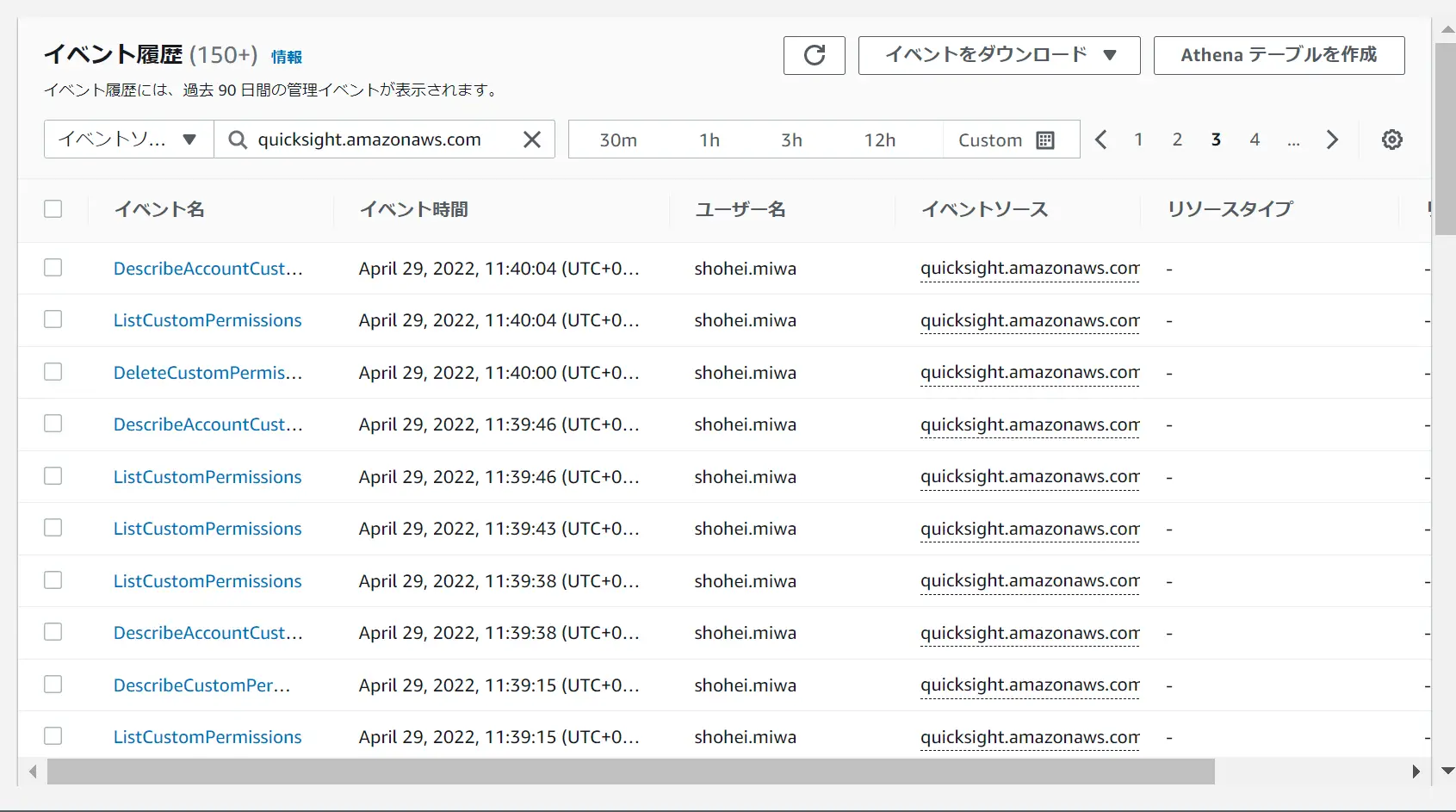
CloudTrail Integration
Amazon QuickSight はCloudTrail と統合されており、QuickSight のすべての API コールをイベントとしてキャプチャします。インシデントや証跡管理としてS3 に保存するなど、QuickSight の運用管理を柔軟にカバーします。
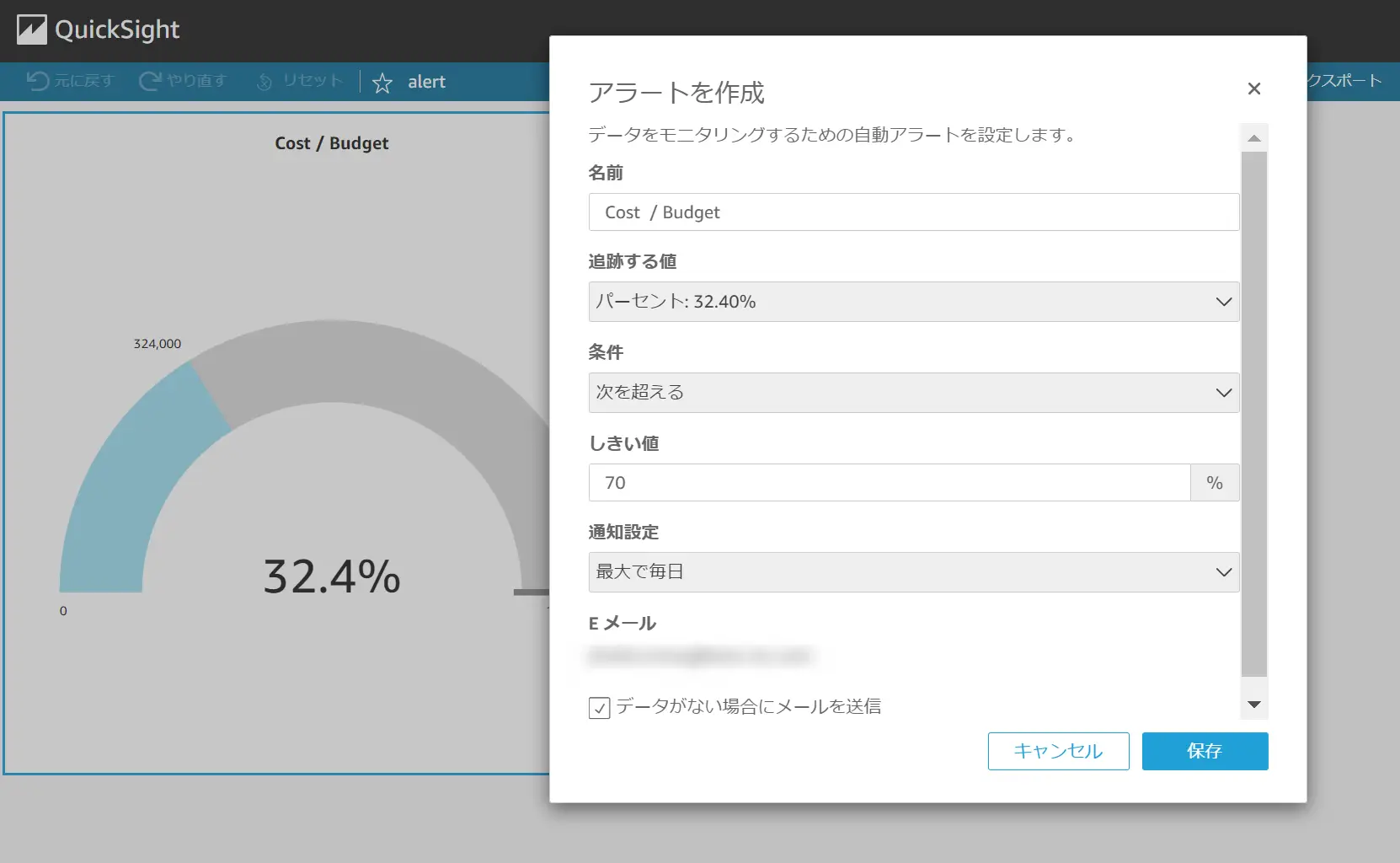
Threshold Alerts
Monitoring for DevOps (DevOps モニタリング)
DevOpsの開発に特化したモニタリングが公開されています。これは AWS 上で使用される主に CI/CD パイプラインを活かしたソリューションとなるかと思います。
参考情報 DevOps Monitoring Dashboard on AWS Architecture overview
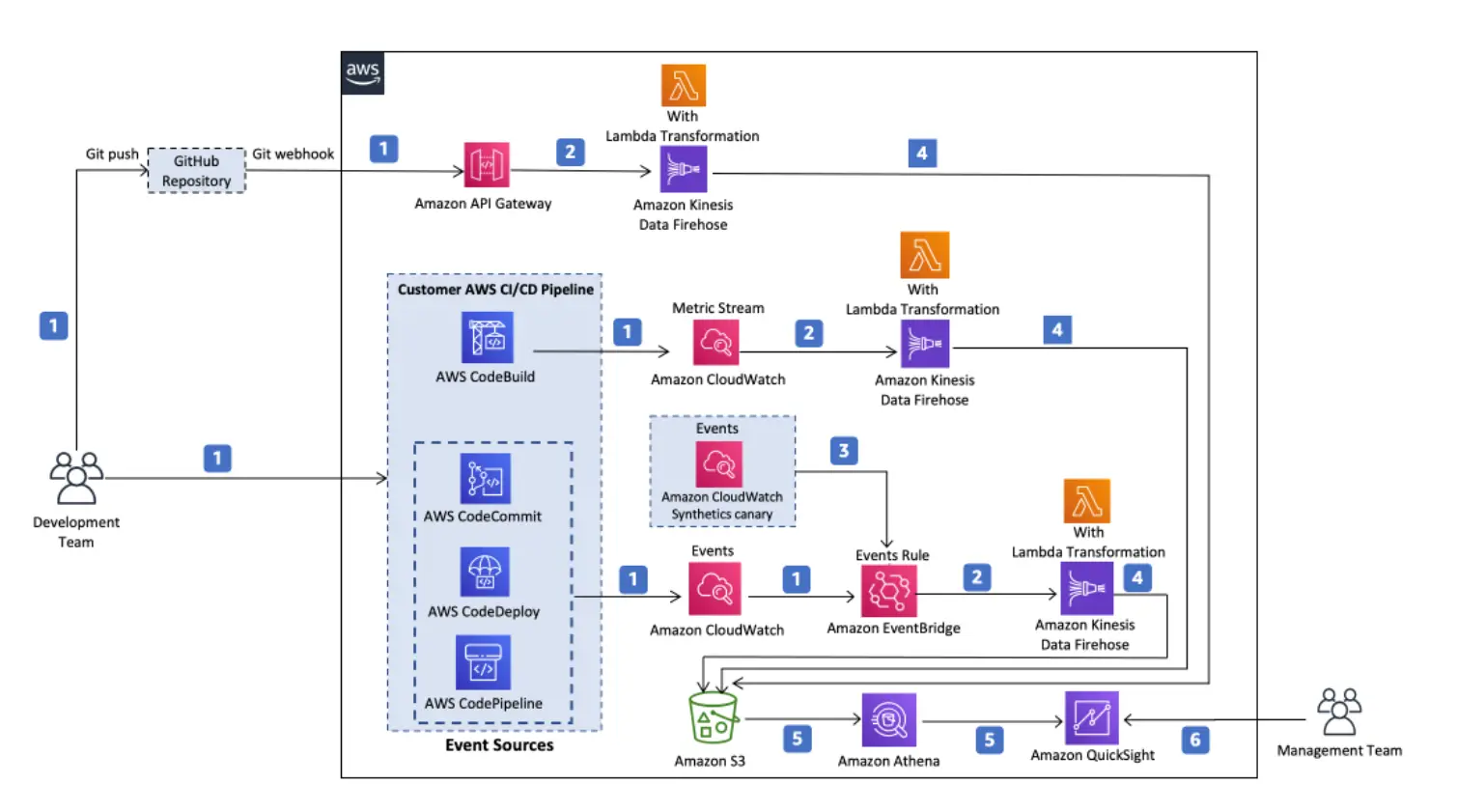
AWS Code Pipeline 上で実行される、commit や deploy 処理がCloudWatch / EventBridge を経由してAmazon QuickSight にデータを転送する仕組みのようで、これらから、CI/CD パイプラインの集計情報を可視化する事が出来ます。また、 アプリケーション向けに Amazon CloudWatch Synthetics Canary と CloudWatch Alarm を使用してサービス監視や平均回復時間の観測が可能となるようです。
なお、これらのサービスを含んだダッシュボード生成の CloudFormation テンプレートが以下に公開されているようですので、構築自体はクイックに可能なようです。
参考情報 AWS での DevOps Monitoring Dashboard
IoT data Solution ( IoT Data の活用)
Amazon QuickSight は、AWS IoT をデータソースとした可視化に対応しています。AWS Iot Core が収集したデータを AWS IoT Analytics に転送し、AWS IoT Analytics Dataset を Amazon QuickSight がデータソースとして SPICE へデータを取り込みます。Dataset 上で SQL クエリを発行の上、整形されたデータの取り込みを Amazon QuickSight で行う仕組みかと思います。
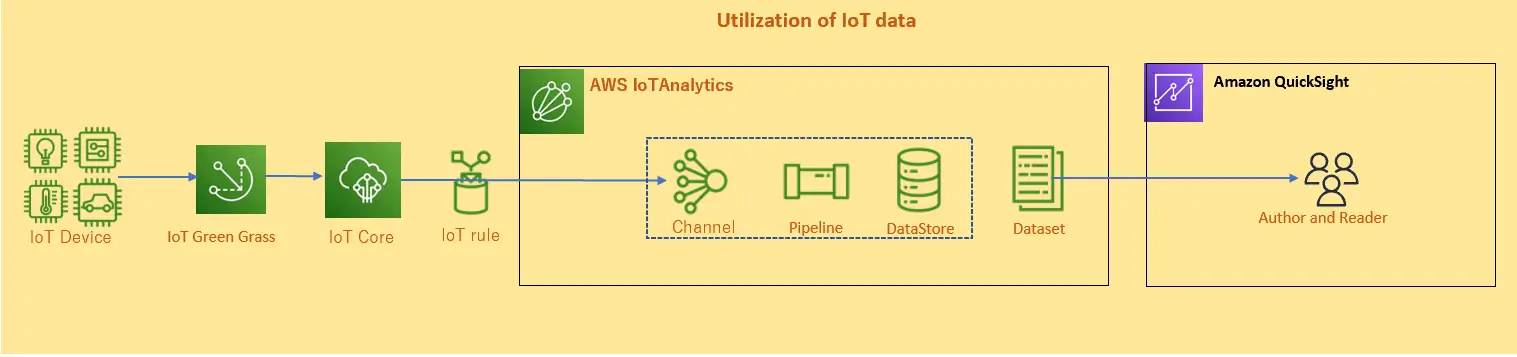
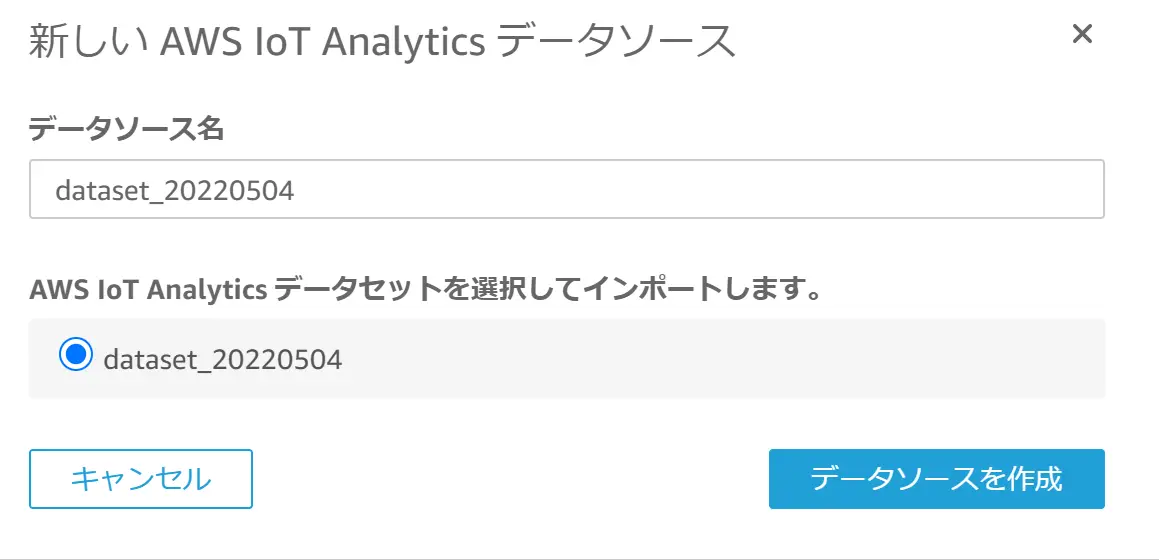
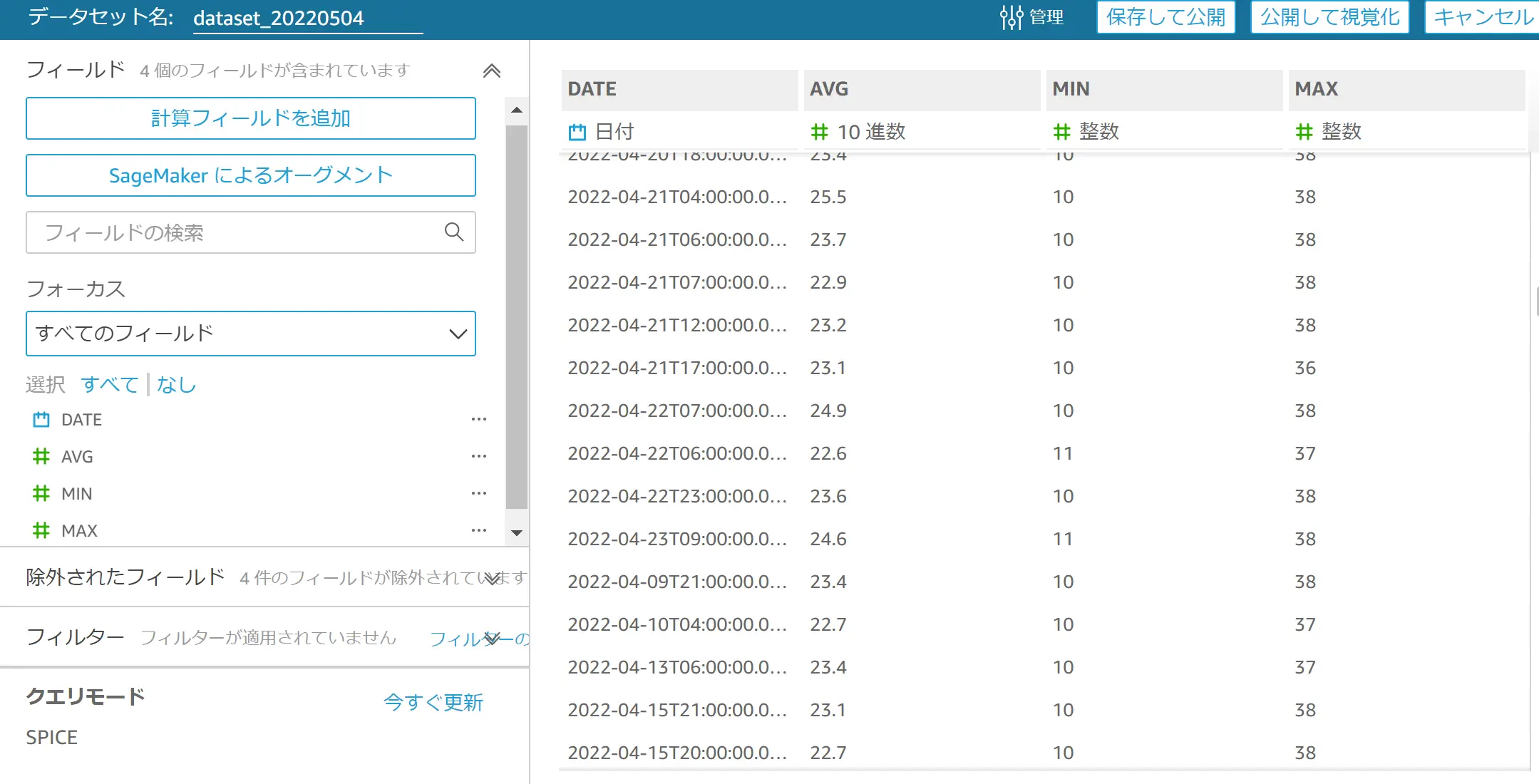
インポートされたデータは、他のデータソースタイプと同様に QuickSight の機能を使用して可視化する事が可能です。
Amazon QuickSight ML Insights (ML インサイトについて)
Amazon QuickSight Enterprise Edition は QuickSightビルトインの ML Insights をサポートします。これは Amazon QuickSight が Random Cut Forest アルゴリズムを使用して異常検知や予測が行われ、その他にも自動説明文の追加を可能となります。一つずつ動作を見ていきましょう。
Anomaly or Outlier detection
外れ値および異常検知を行う場合、一つの日付フィールドとメジャーまたはディメンションフィールドを使用して、一つのビジュアルとしてセットアップを行っていきます。

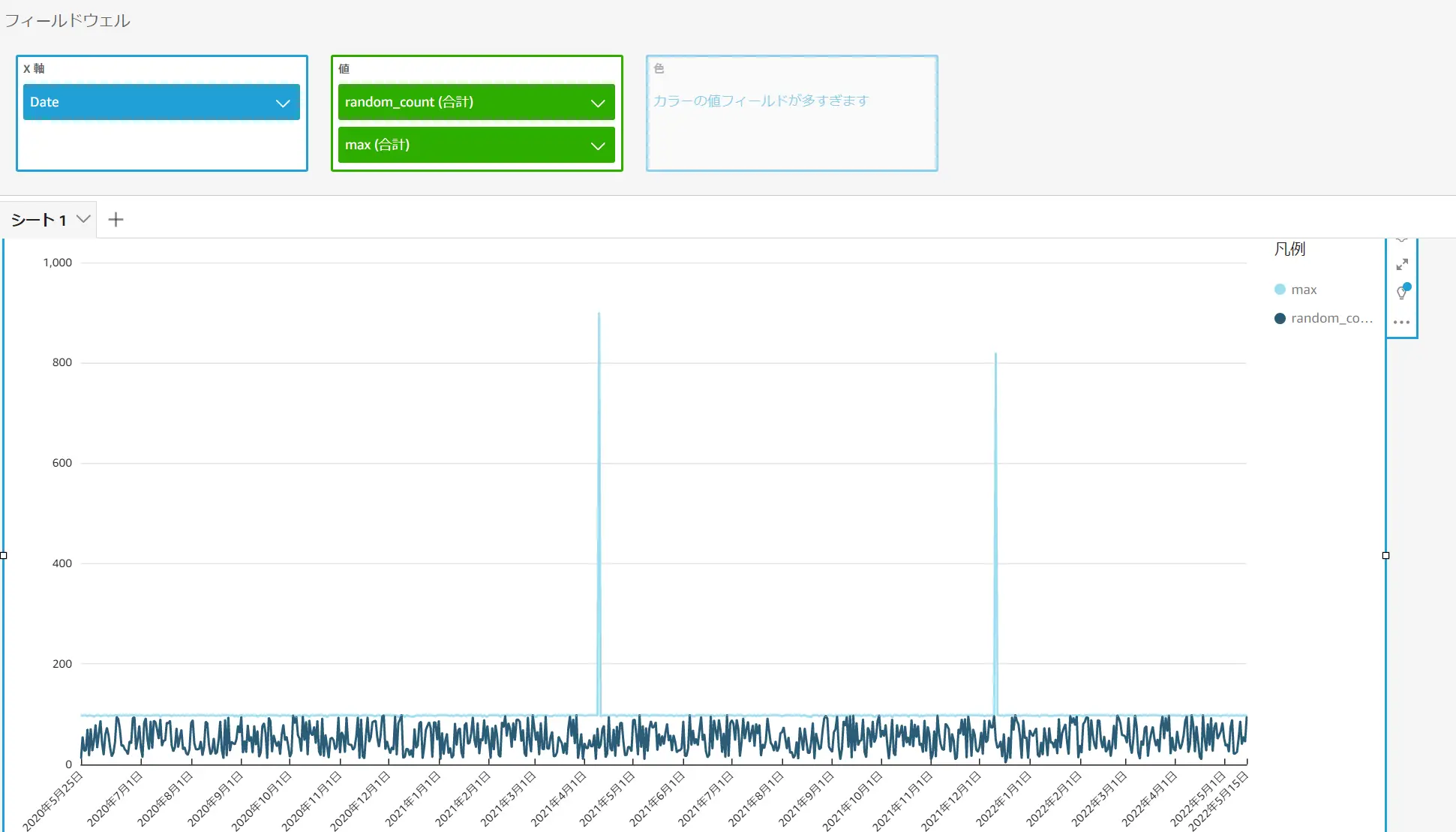
下記の例では、任意の Date / Max 値を使用して異常検知を行います。このデータの値のMax値の平均値は 94~98 ですが、一部だけ 900 と 820 のデータを含んでいます。
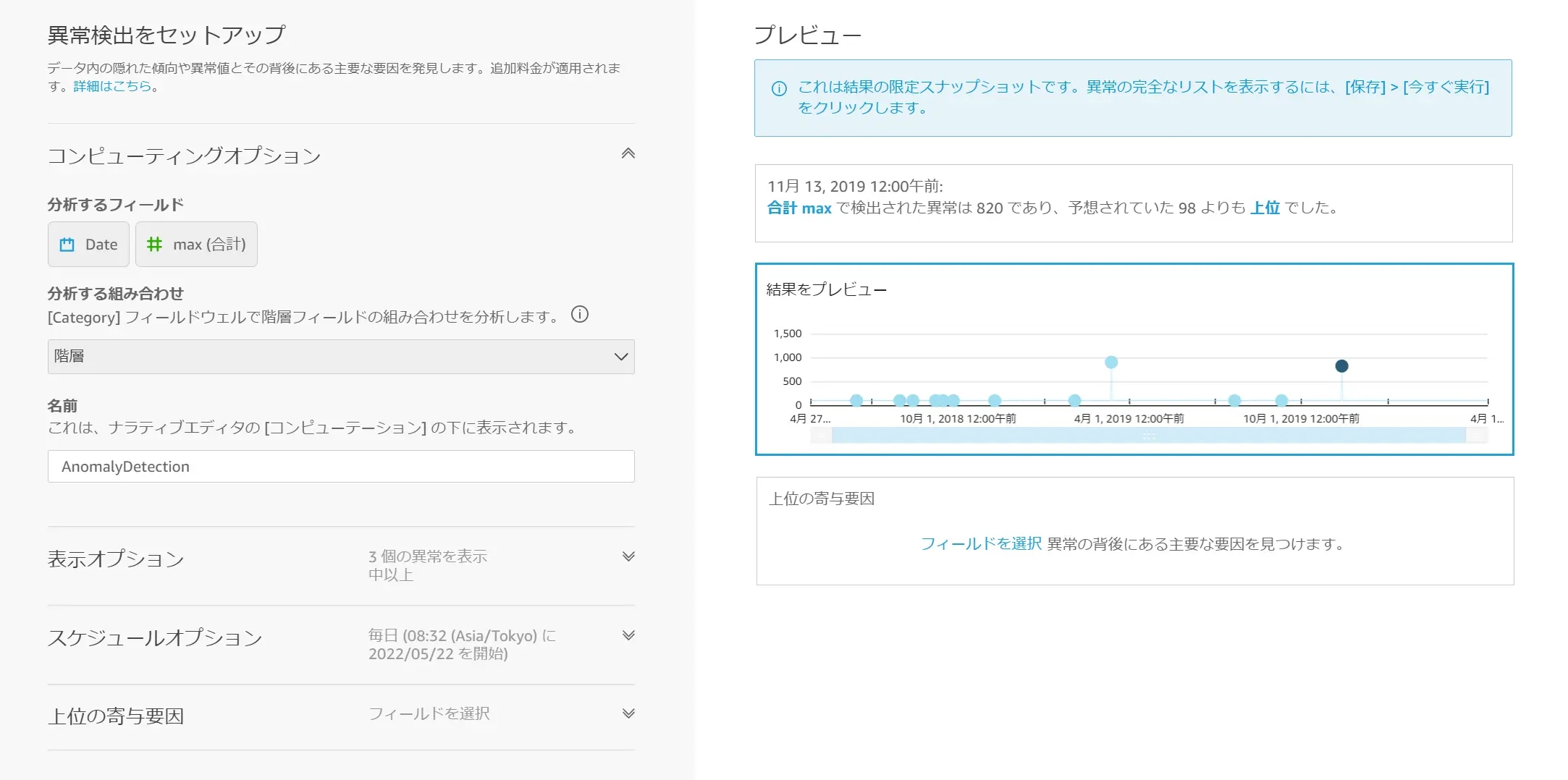
表示オプションでは、ダッシュボードに表示される内容をカスタマイズする設定です。実際の設定はダッシュボードから変更可能です。
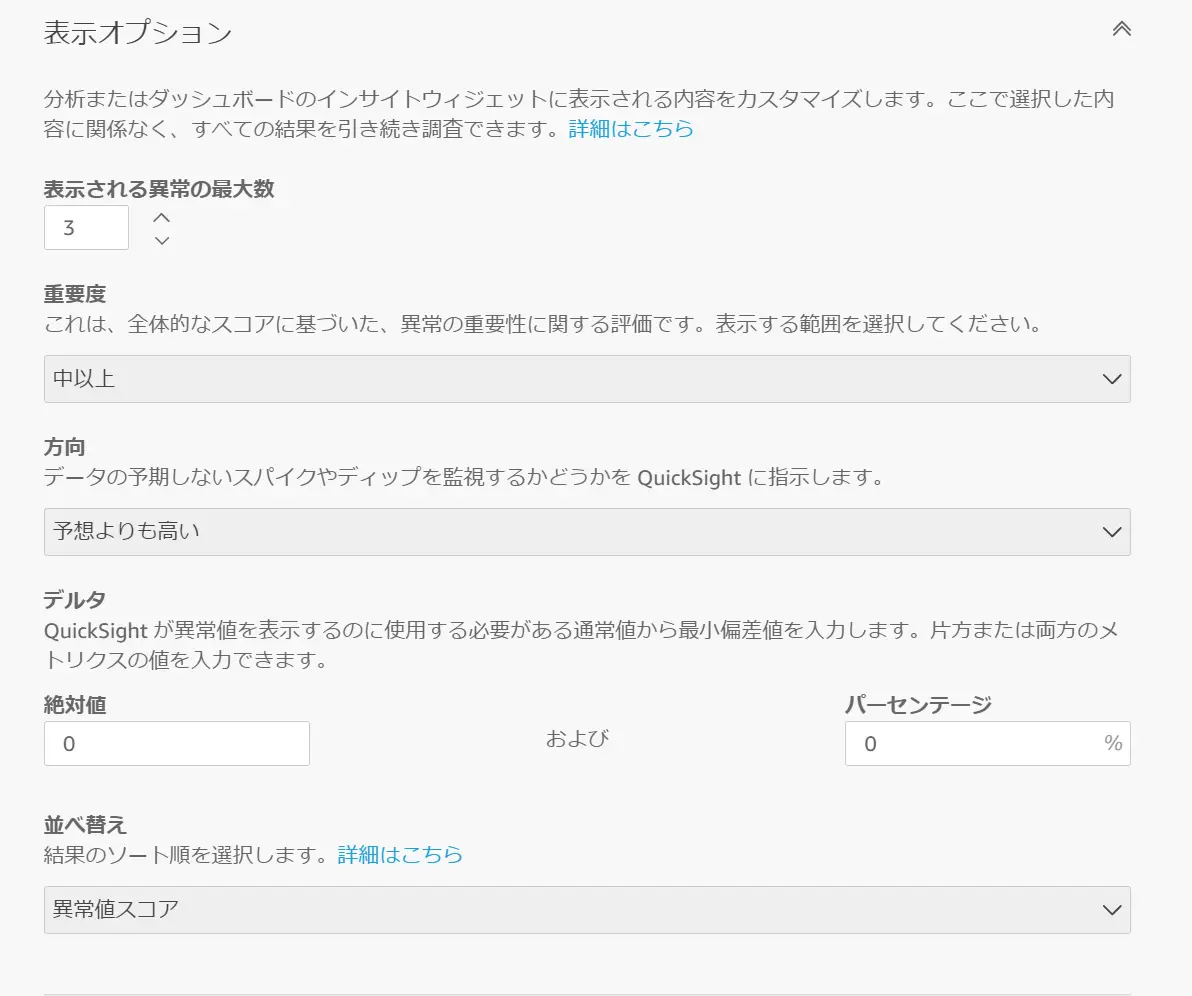
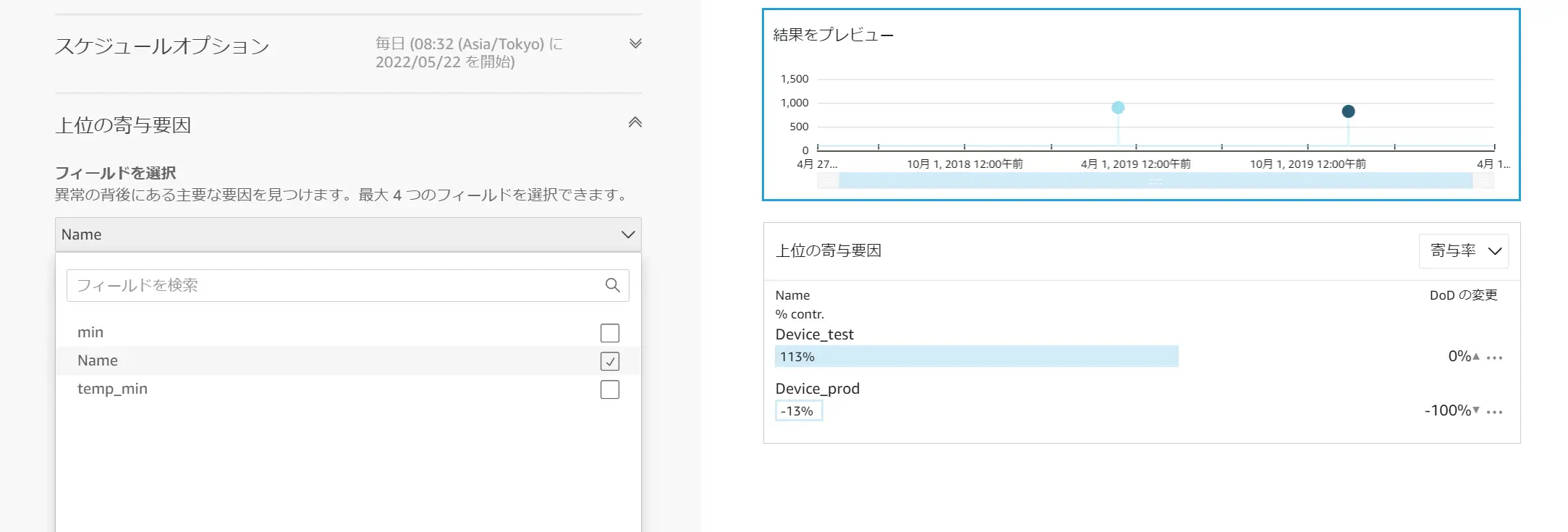
これらを設定し、異常検出を分析から実行します。ダッシュボードから見ると、以下のような自動説明文が記されました。
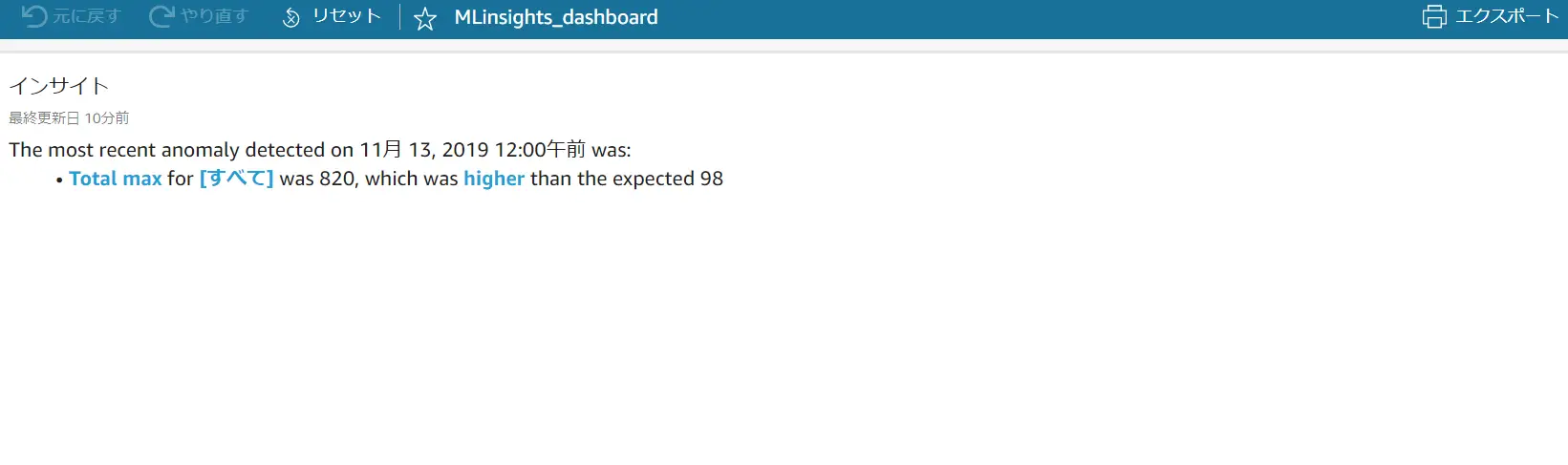
> 2019年11月13日12:00にて検出された直近の異常は、最大値が 820 であり、予想値 98より高かった。
異常の探索画面 (ダッシュボードから確認出来ます)から見てみると、以下のようにMax 値に挿入された 900 / 820 のデータポイントが異常値として検知されている事が確認出来ます。
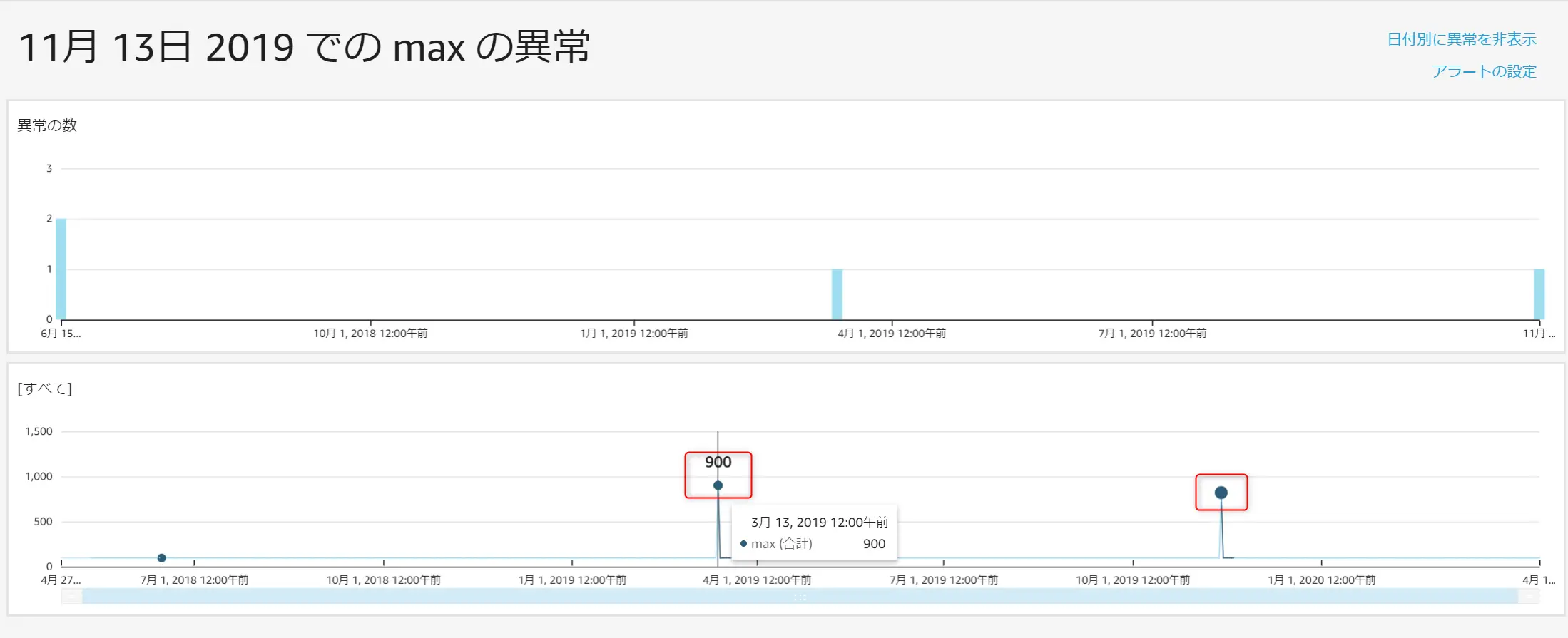
寄与要因を見ると、Name フィールドの Device_test が 113% 、Device_Prod が -13% となっています。Max 値 900 / 820 には Device_test をデータとして投入されています。寄与要因率の結果では Device_test が異常検知の要因として100% を上回るという事が判断できます。
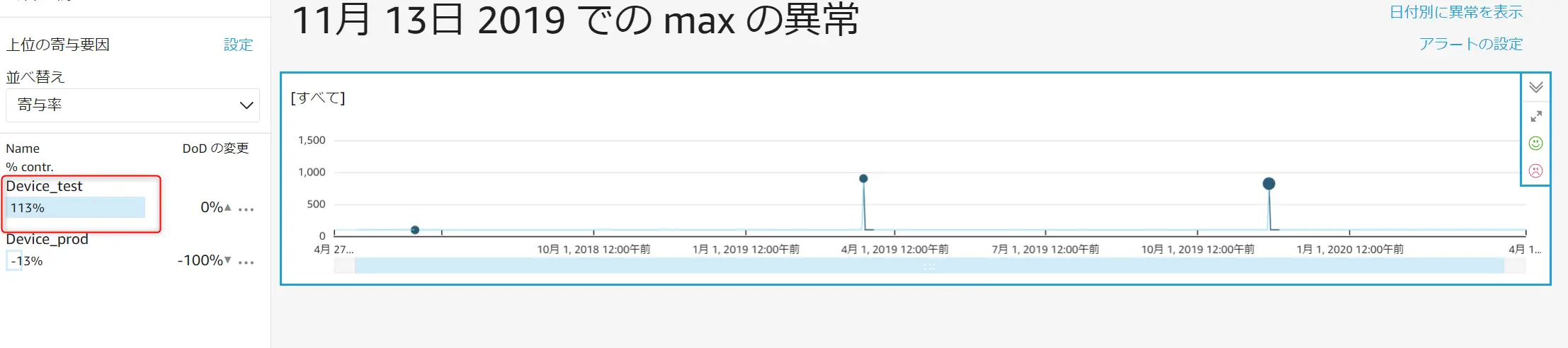
なお、これらの異常検知設定からアラートを発報する事が可能となりますので、インシデント管理としての対応も可能にすると考えられます。
 上記は単調な一例となりますが、インサイトでは、ディメンションフィールドを5つまで追加する事が可能となりますので、複雑な処理もML insight による計算が可能になると考えます。
上記は単調な一例となりますが、インサイトでは、ディメンションフィールドを5つまで追加する事が可能となりますので、複雑な処理もML insight による計算が可能になると考えます。
参考情報 外れ値と主要因を検出するための ML Insights の追加
カテゴリフィールドウェル内のすべてのフィールドの組み合わせを分析する場合は、このオプションを選択します。たとえば、日付 (T)、メジャー (N)、3 つのディメンションカテゴリ (C1、C2、C3) を選択した場合、次に示すように、QuickSight はフィールドのすべての組み合わせを分析します。 T-N, T-C1-N, T-C1-C2-N, T-C1-C2-C3-N, T-C1-C3-N, T-C2-N, T-C2-C3-N, T-C3-N
Auto-Narrative
これは機械学習とは異なり、予測や異常検知を追加する場合に ML が使用されます。上述した Anomaly or Outlier detection にてダッシュボードを確認した際に表現された文章も Auto-Narrative 機能によるものです。分析に自動説明文を追加する場合、テンプレートを使用する事が出来ます。
参考情報 自動説明文が含まれるインサイト
また、表現エディタを使用して、自動説明文の内容の変更が可能です。先ほどのAnomaly or Outliner detectionにて追加したインサイトを元に、表現エディタを開いてみます。
この例では複数のIF文とFor文から構成されています。青色で囲まれている文字が計算からデータを抽出したものとなり、結果に応じて値が代入されます。白色の背景の文字は、表示したい文字が記載されているもので、これも編集が可能です。
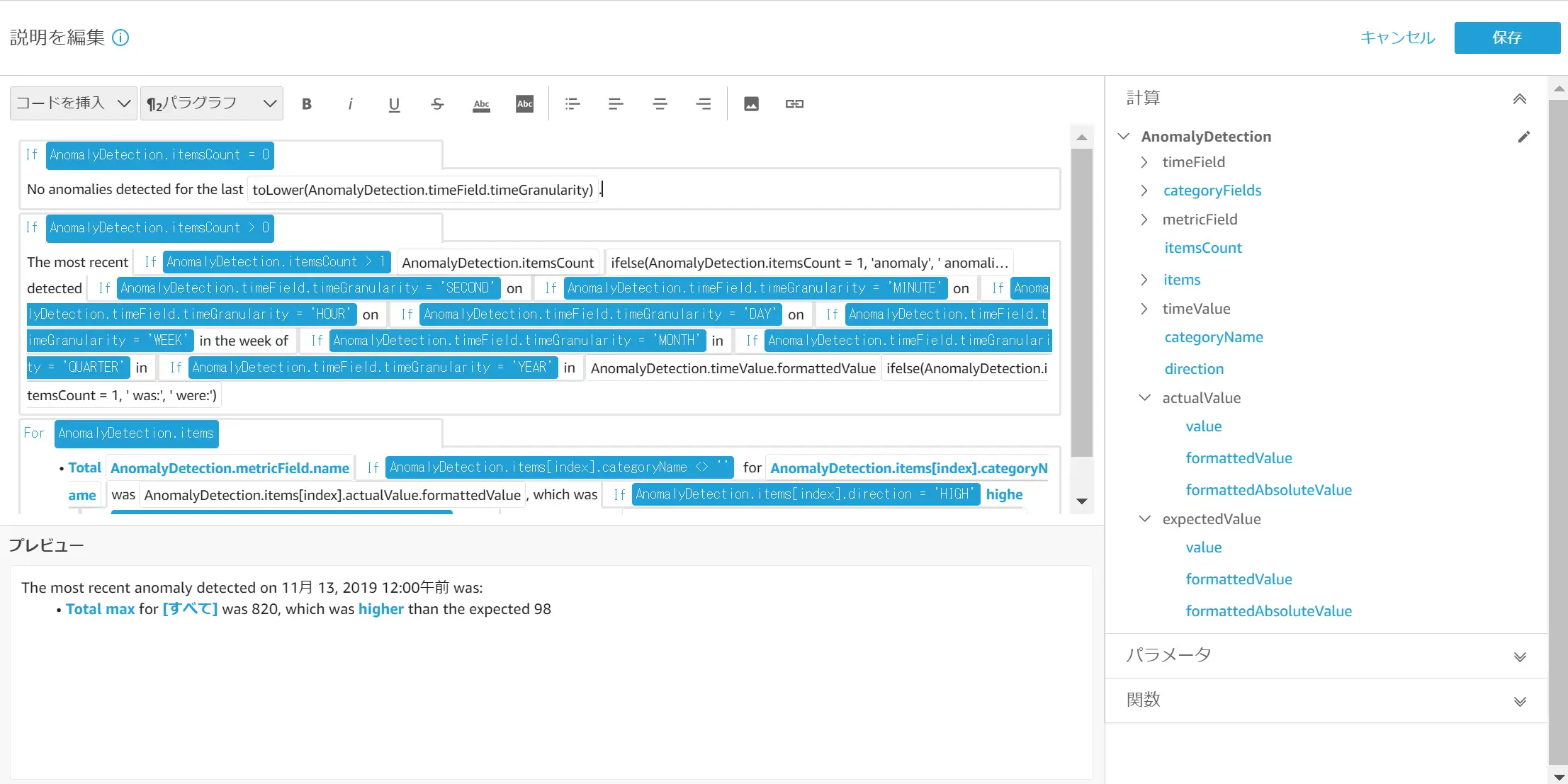
AnomalyDetection.itemCountは、計算に含まれている項目の数を返すものです。この例では特定間での値に1を返しています。AnomalyDetection.itemCount > 1へ変更すると、The most recent~ の文脈はIFに合致しない条件となり、表記が消える事が判ります。
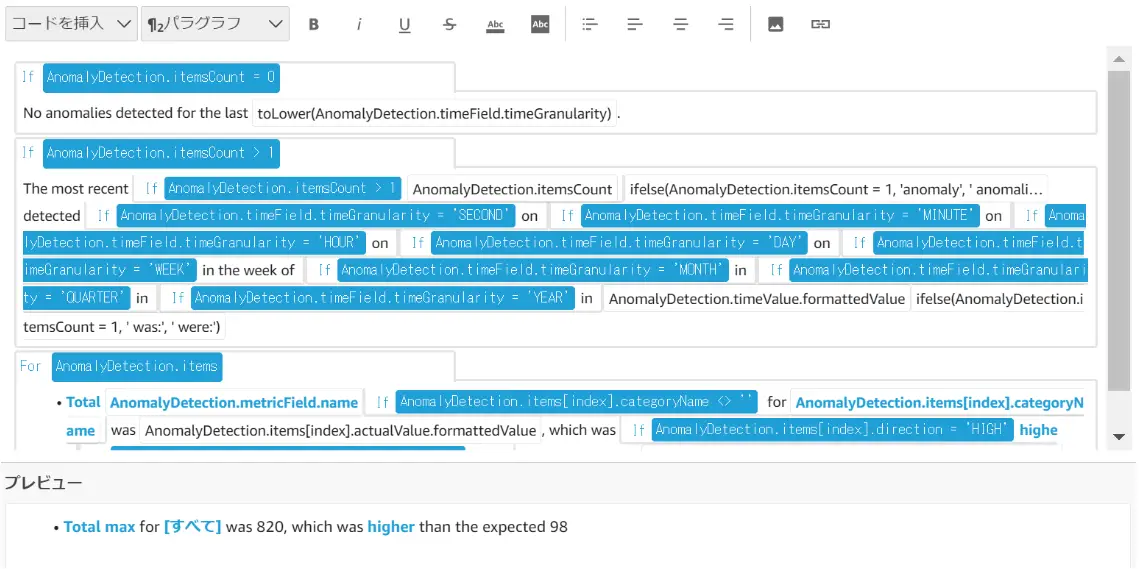
AnomalyDetection.actualValue.value は異常値発生時のメトリクスの実際の値を返すものです。MAX 値の 820 を返します。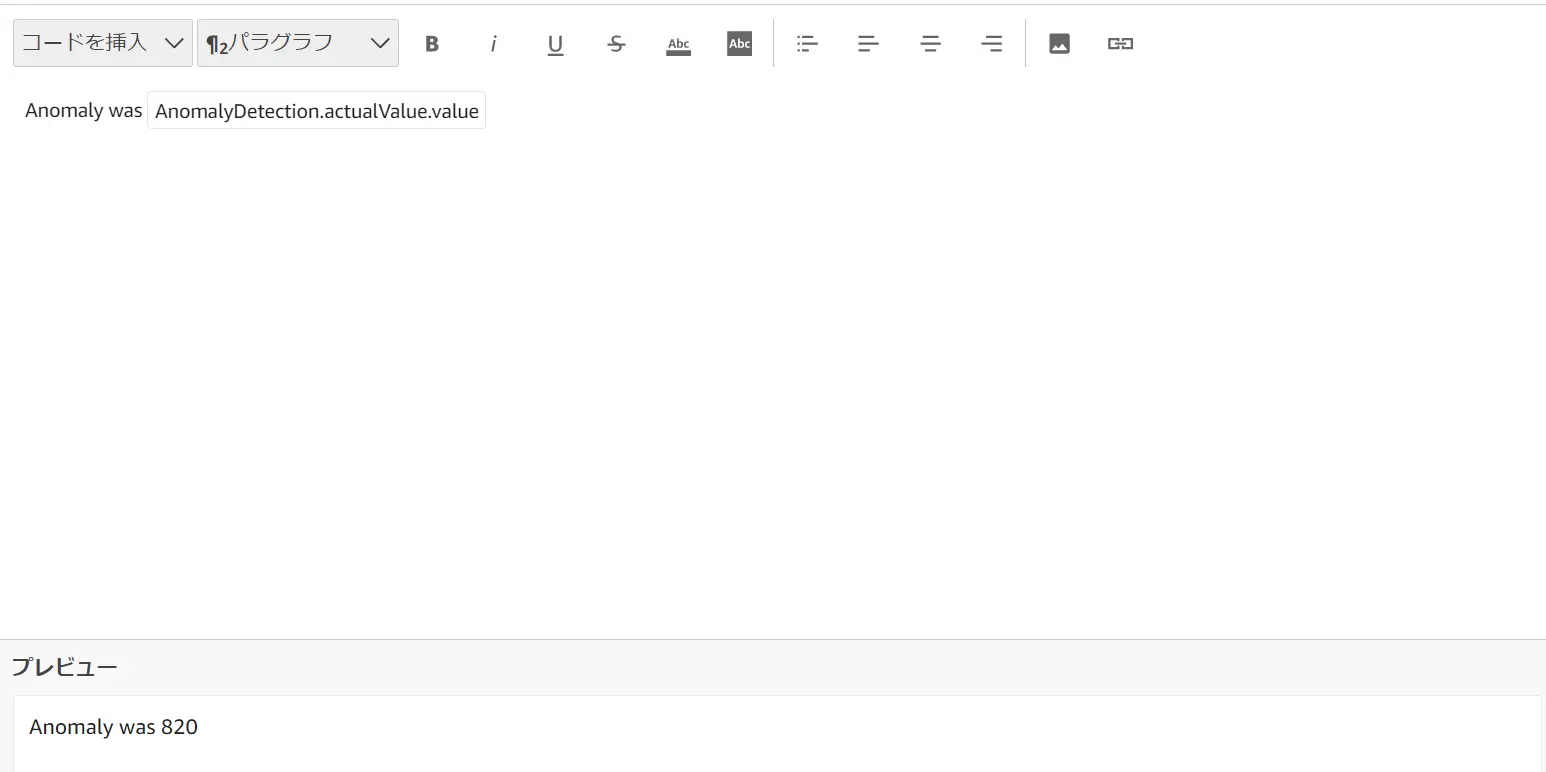
Forecasting and What-if analysis
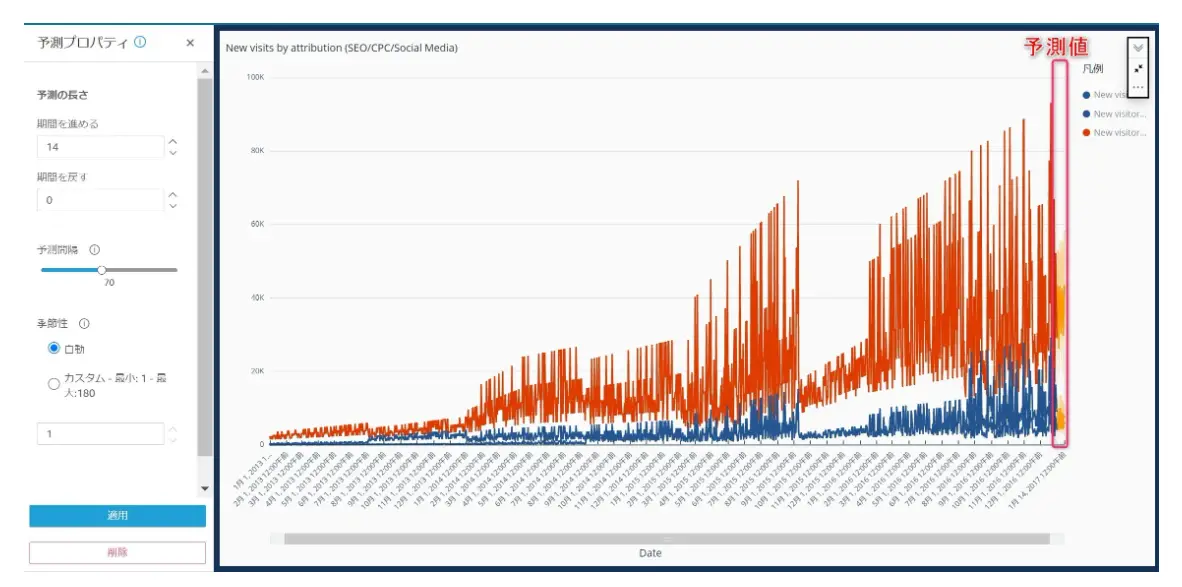
単一の日付フィールドと最大 3 つのメトリクス (メジャー) を使用するビジュアルに予測を追加できます。予測を追加する事で日付フィールドから最終日から予測値を適用する事が可能です。
以下の例は、先ほどの Date の日付を変更したものおよび Max フィールド、更には Random_count (2桁の乱数) が 722 レコード分追加された折れ線グラフを使用します。これらに予測を追加します。
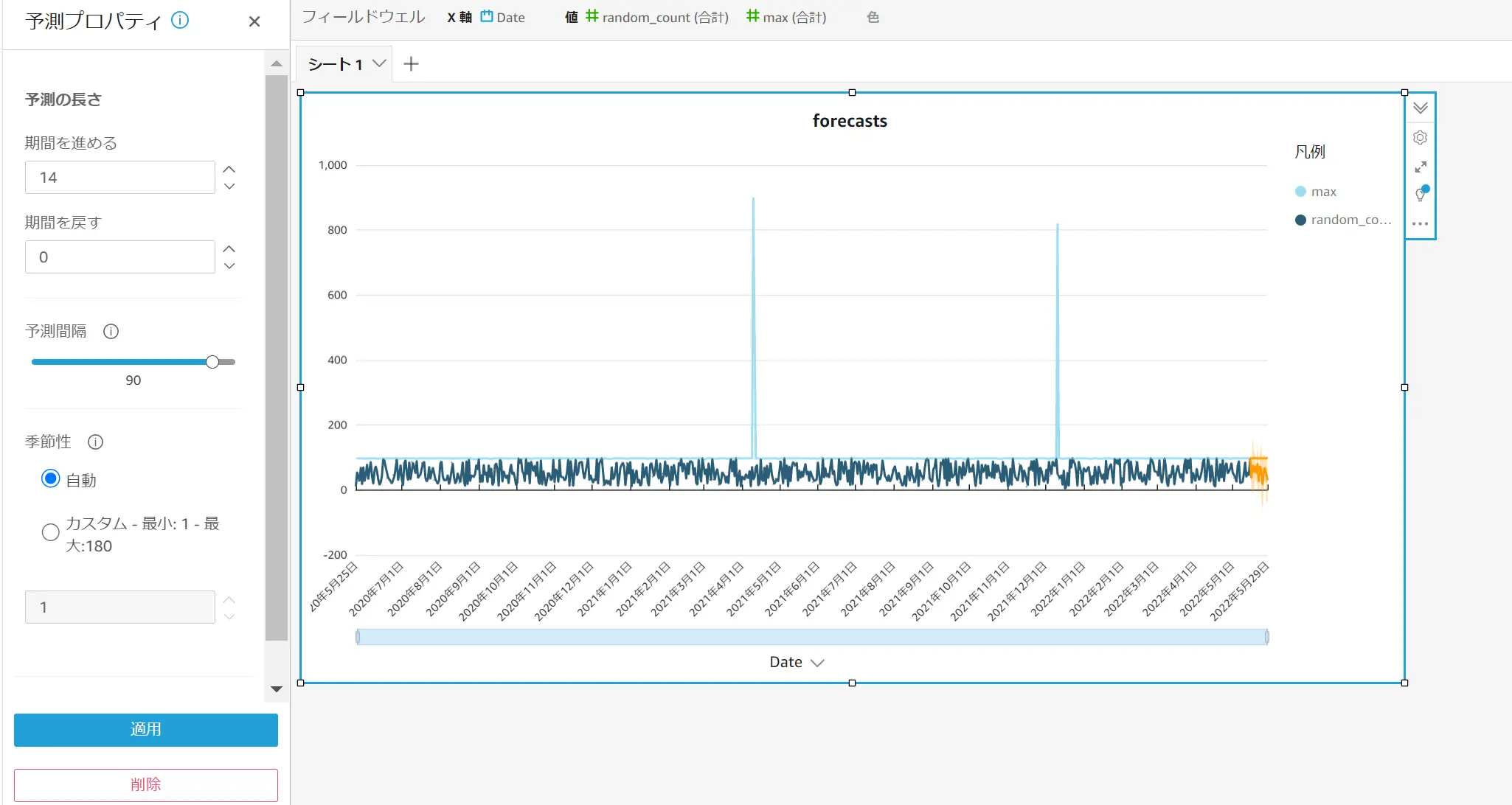
予測には、予測プロパティを使用します。予測の長さ、予測間隔、季節性を扱います。"期間を戻す"では、予測の基礎となるパターンと探す特定の期間、予測間隔は予測値の推定範囲を設定します。これは予測されるラインに対して、幅を設定するものです。季節性は、季節的データパターンに含まれる期間数を設定します。
追加された予測値を見てみましょう。Dateフィールドの最終日付が 2022/5/15 となっていますので、これ以降(下記 オレンジの範囲) が予測範囲となります。Max フィールドの値は先ほどの例のように一部のように 94~98 が平均値のため、横ばいが続く事が予測されています。 例えば 2022/ 5/21 では上限下限(予測間隔) とともに 97.16 が予測中央値と算出されました。
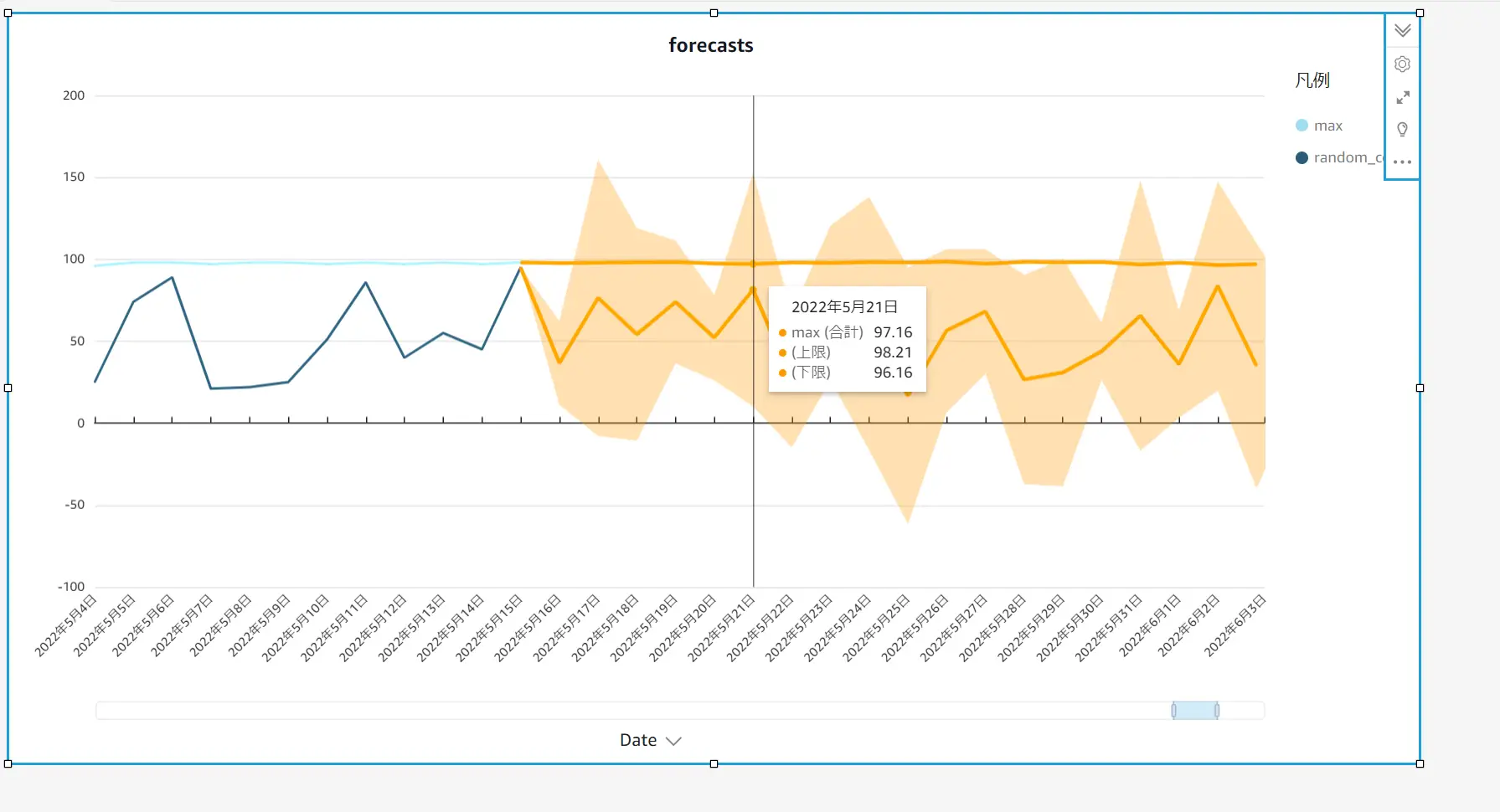
これに対して、Random_count は722行全て 2桁の乱数データとなります。これらのデータが予測プロパティの設定にされ、内部的な RCF アルゴリズム使用して 予測値を算出しています。2022/5/30 では中央値が 43.8 と推測され、上限・下限は乱数値のため可能性の幅が大きくなっている事が判ります。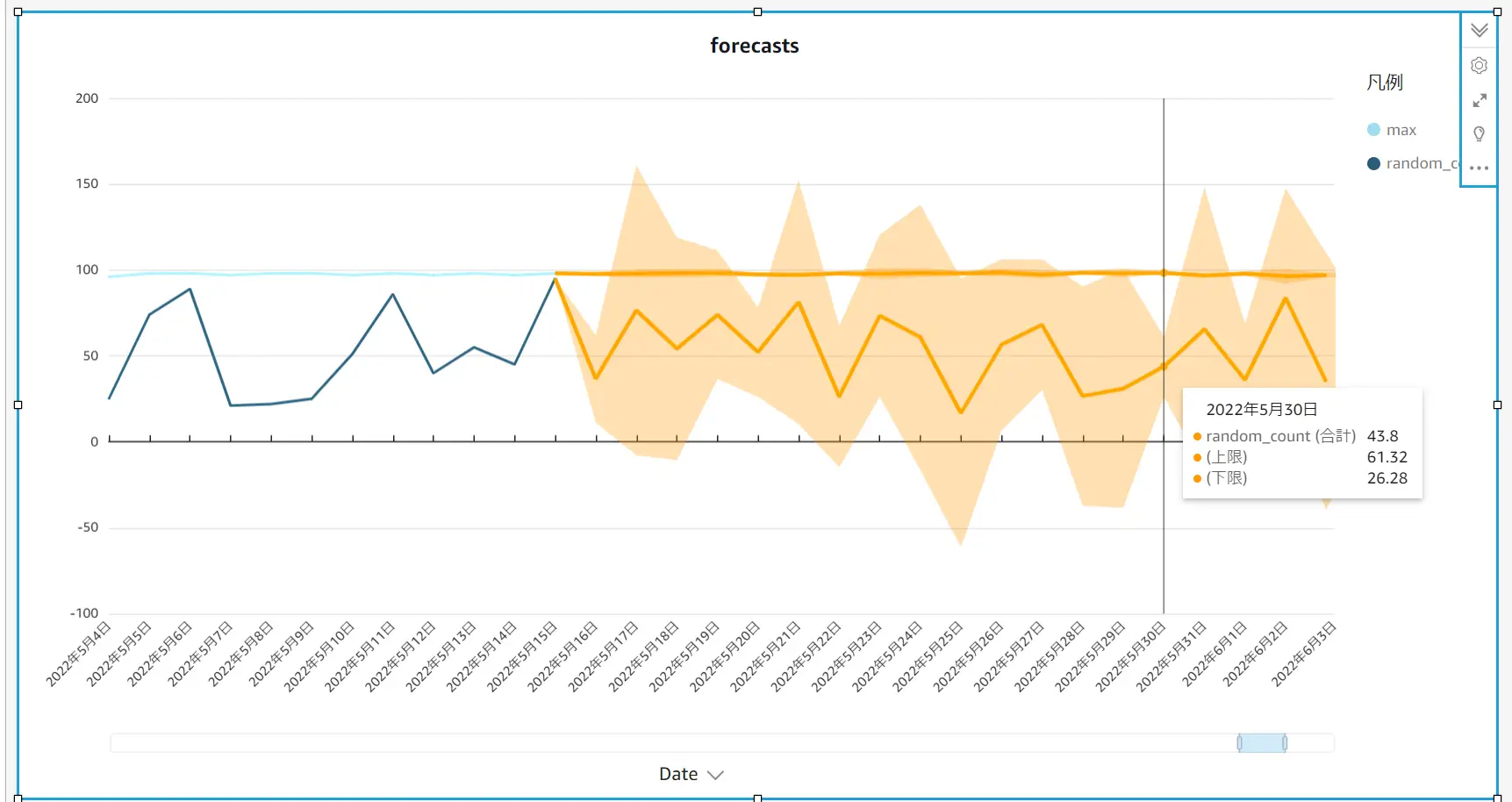
また、予測された1つのフィールドのみ What if 分析の適用が可能です。What if 分析は指定されたターゲット値を達成するための仮説の値を算出します。期間や、日付を設定する事で、Amazon QuickSight はWhat if 分析のターゲットを達成するように値を算出(シミュレーション)する事が出来るソリューションです。
Amazon QuickSight SageMaker Integration (SageMaker 統合)
上述した ML Insights は Amazon QuickSight に組み込まれた機能であり、機械学習のモデリング、アルゴリズムに関する知識を必要とせず実装出来るものとなります。これに対し、Amazon QuickSight Enterprise Edition ではSagemaker との統合が行われておりますので、SageMaker による独自のモデルを適用する事が出来ます。
データセットに対して生成したモデルとスキーマファイルを適用します。Amazon QuickSight からSageMaker モデルを使用する場合、モデルを処理する必要のあるメタデータを含む JSON スキーマファイルを事前に作成する必要があります。
JSON ファイルには、モデルが必要とする入力フィールド、モデルが予測するための出力フィールド(新規フィールド)をJSON 形式で記述したものを適用します。
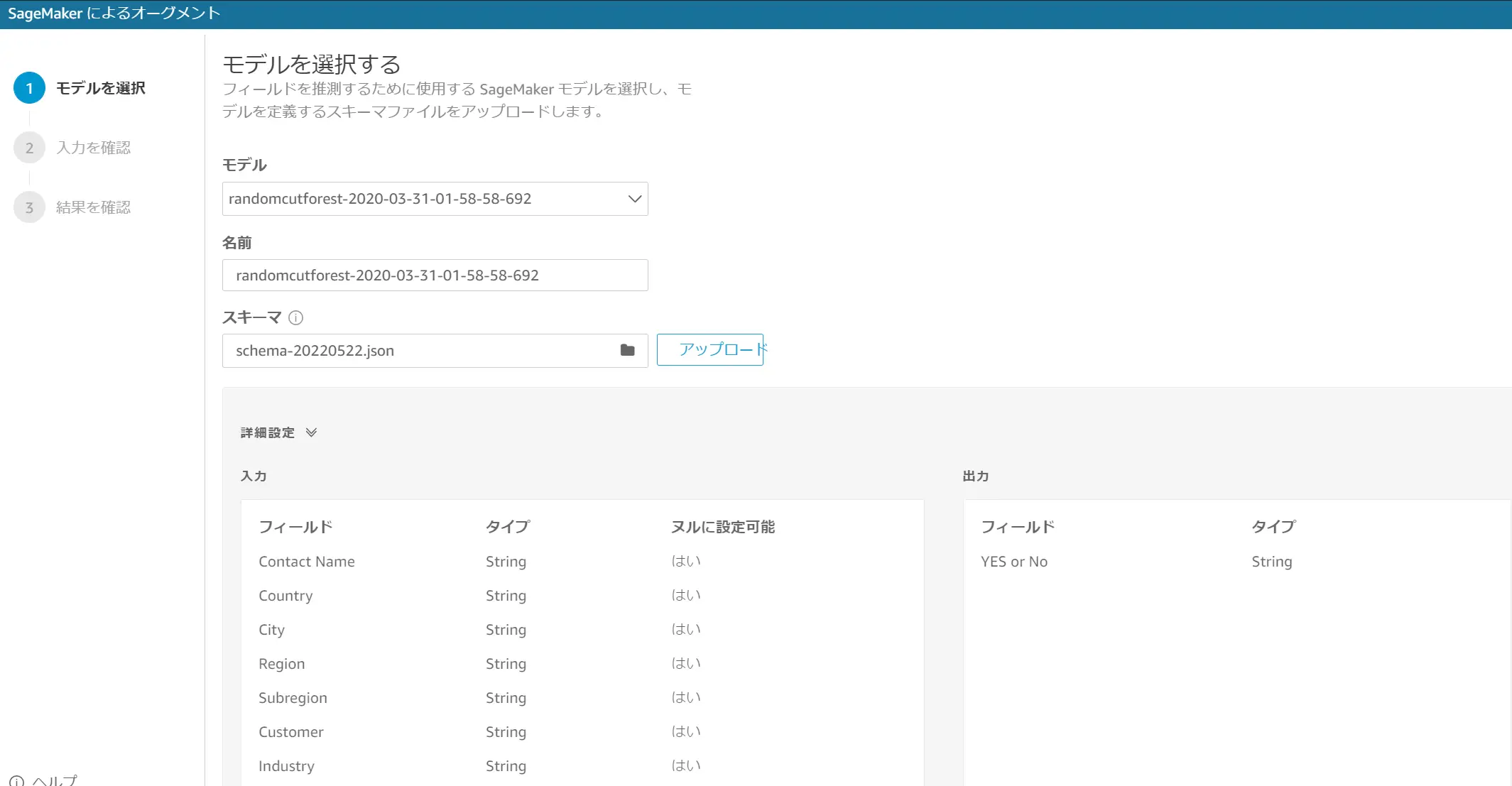
モデルの選択が完了すると、バッチ変換ジョブを実行して推論が完了するまで待機します。推論が完了すると、出力フィールドに推論の結果が反映されますので、分析画面上でフィールドとして使用が可能となります。
AmazonQuickSight Q (Amazon QuickSight Qについて)
自然言語処理を使用して質問に対して回答を提供します。Amazon QuickSight Q は、Enterprise Edition の中でもオプショナルな機能となっているため本記事ではご紹介出来ませんが、DemoCentral から実際の画面を確認する事が可能なようです。
Twitter Solution (ツイッターの活用)
Amazon QuickSight はTwitter のデータを取得する事が可能です。Twitter アカウントと連携し、対象のクエリの内容を行数分取得します。
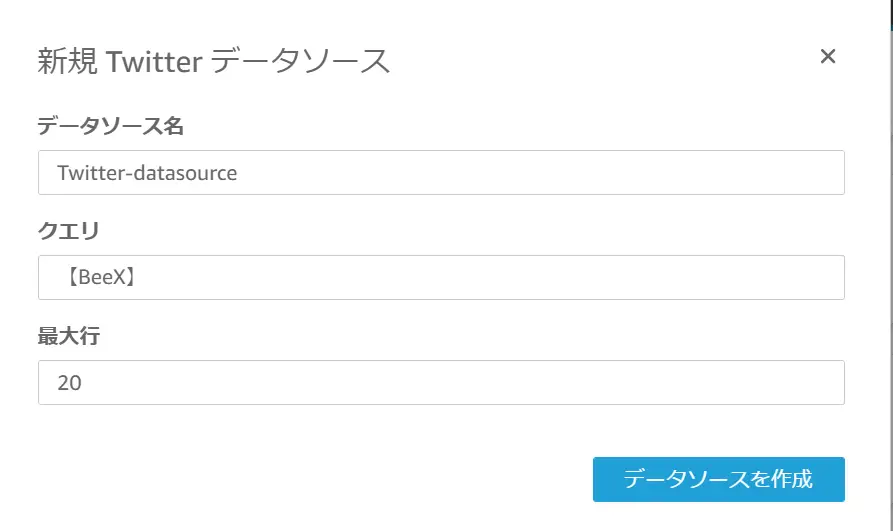
クエリから取得されたデータから各フィールドを取得し、分析に使用出来ます。以下に記載された内容は直近にツイートした内容です。例えば、特定のタイムラインをダッシュボードのヘッダーに追加する事でダッシュボードのテーマに沿った Twitter のリアルタイムな情報を公開する事が出来ます。Twitter のデータは SPICEに保存されるため、更新処理も可能です。

Analysis Development (分析の開発)
分析の開発工程では、あらゆる機能を駆使して画面を作成する事が出来ます。QuickSight で使用出来る機能をトピック形式でご紹介します。
Calculated fields (ParseDate / addDateTime Function)
Amazon QuickSight では、サポートされる日付形式が決まっています。
参考情報: サポートされている日付形式
例えば、2021/12/8_12:00 のようなデータはAmazon QuickSight で文字型として認識されます。このような場合、ParseDate関数 を使用して新たな計算フィールドを作成します。
以下の図では、Date が文字型で、DateType が日付型に変換された計算フィールドを示しています。
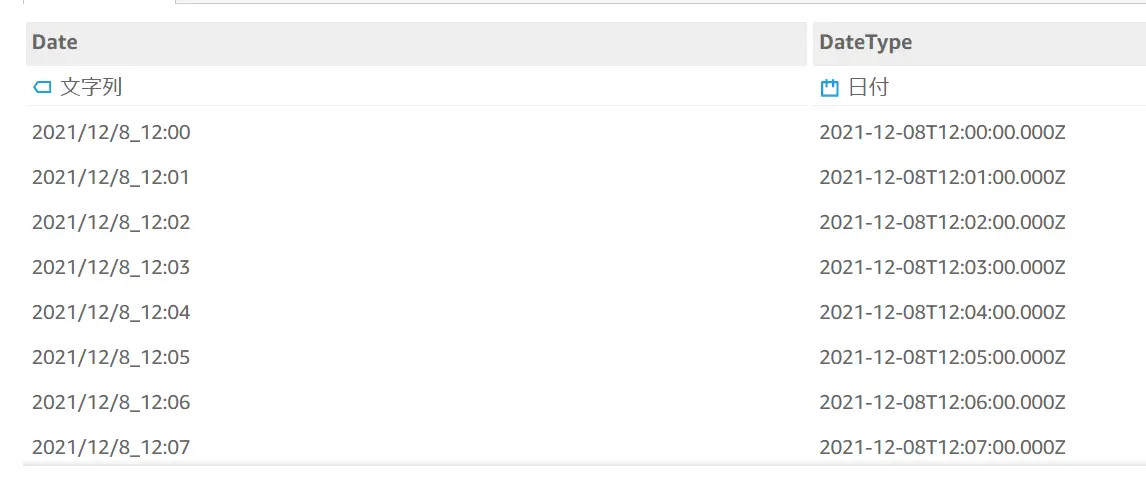
SubString 関数と Concat 関数をネストして中間にあるアンダースコアをスペースに変更しています。つまり、2021/12/8_12:00 から
2021/12/8 12:00 へ変換した上で ParseDate を指定しています。
parseDate( Concat( substring({Date},1,9), ' ' ,substring({Date},11,5)) , "yyyy/MM/dd HH:mm")また、Amazon QuickSight の日付型は標準で UTC 時間となります。日付型のデータを JST に変換する場合、addDateTime関数 を使用します。
adddatetime(9,"HH",(parseDate( Concat( substring({Date},1,9), ' ' ,substring({Date},11,5)) , "yyyy/MM/dd HH:mm")))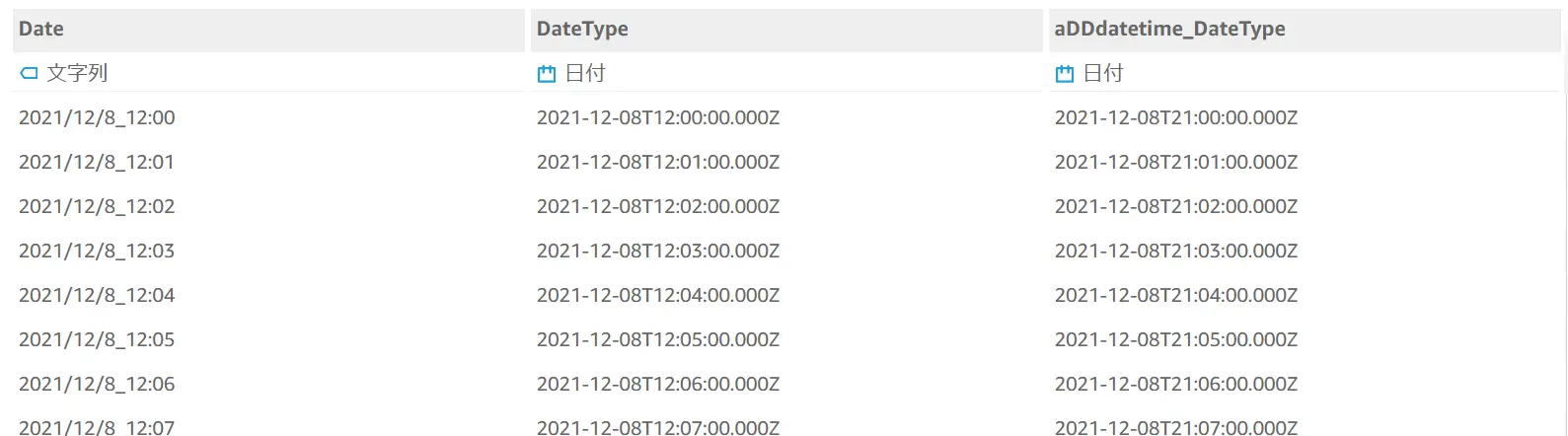
Conditional Formatting (条件付き書式設定 )
ビジュアルタイプがゲージグラフ / 主要業務メトリクス (KPI) / ピボットテーブル / テーブルの場合に使用出来ます。条件付き書式設定で可能な表現は、以下のように 条件に当てはまる値に対して色付けをしたり、アイコンを表示させることが可能 な機能です。例えば、日付フィールドに対して条件となる期間を設けて、対象の列に色付けをして区別を的確に表現します。
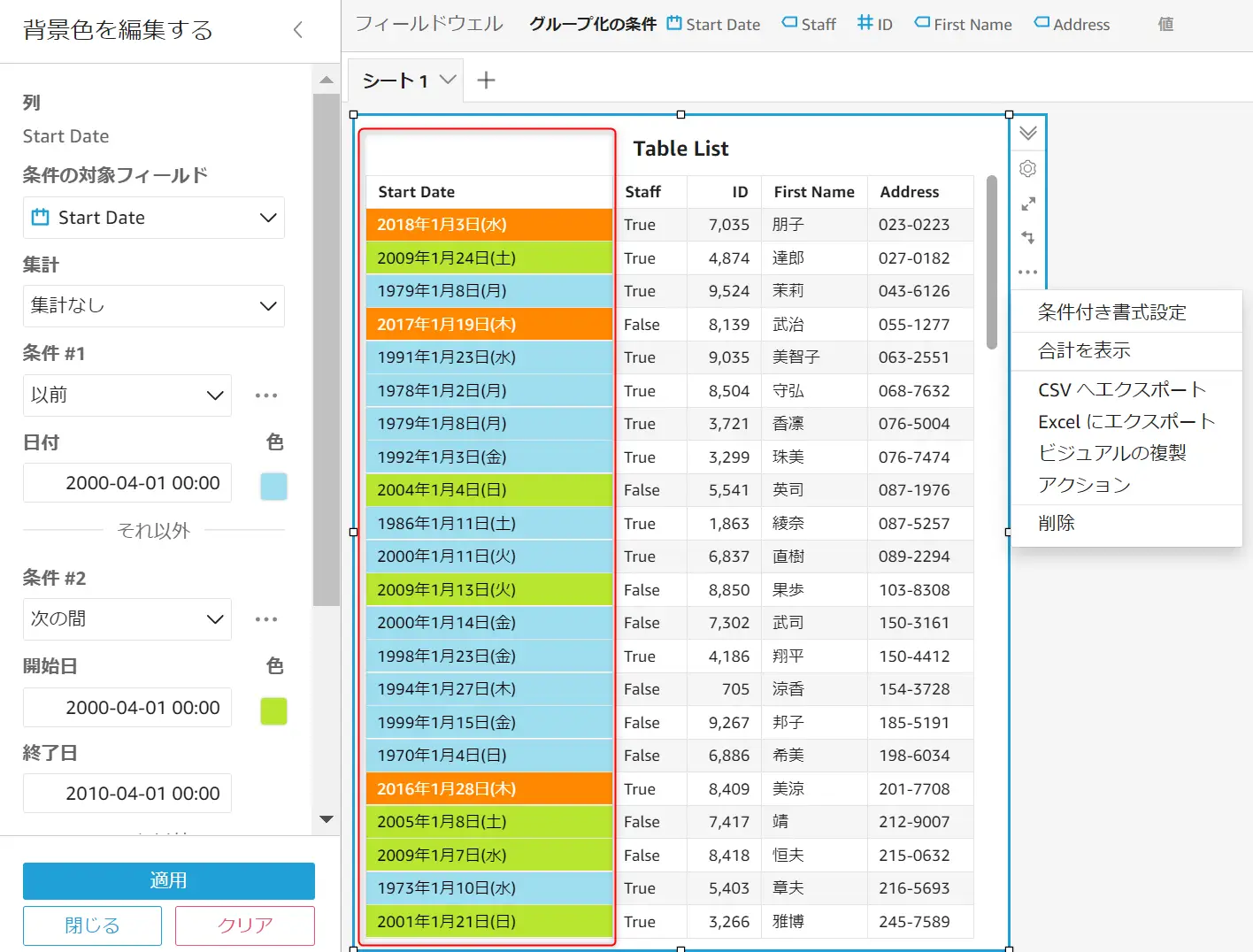
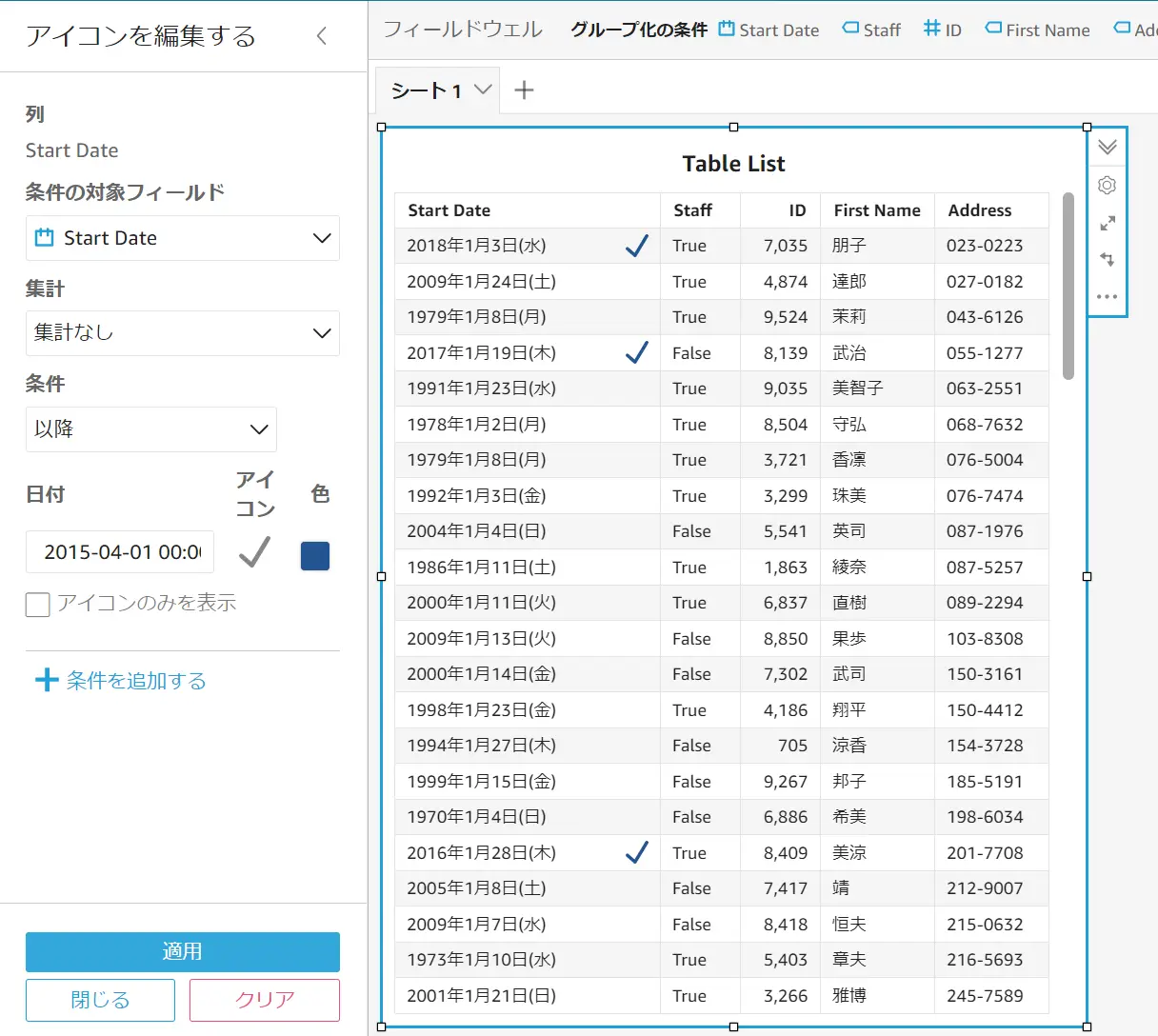
Cascading Filter (連動フィルタ)
特定のデータ範囲だけを表示させるために利用します。例えば、以下のように X 軸を時間軸とした、縦棒グラフと縦積み上げ棒グラフの 2つの形式のビジュアルが存在します。
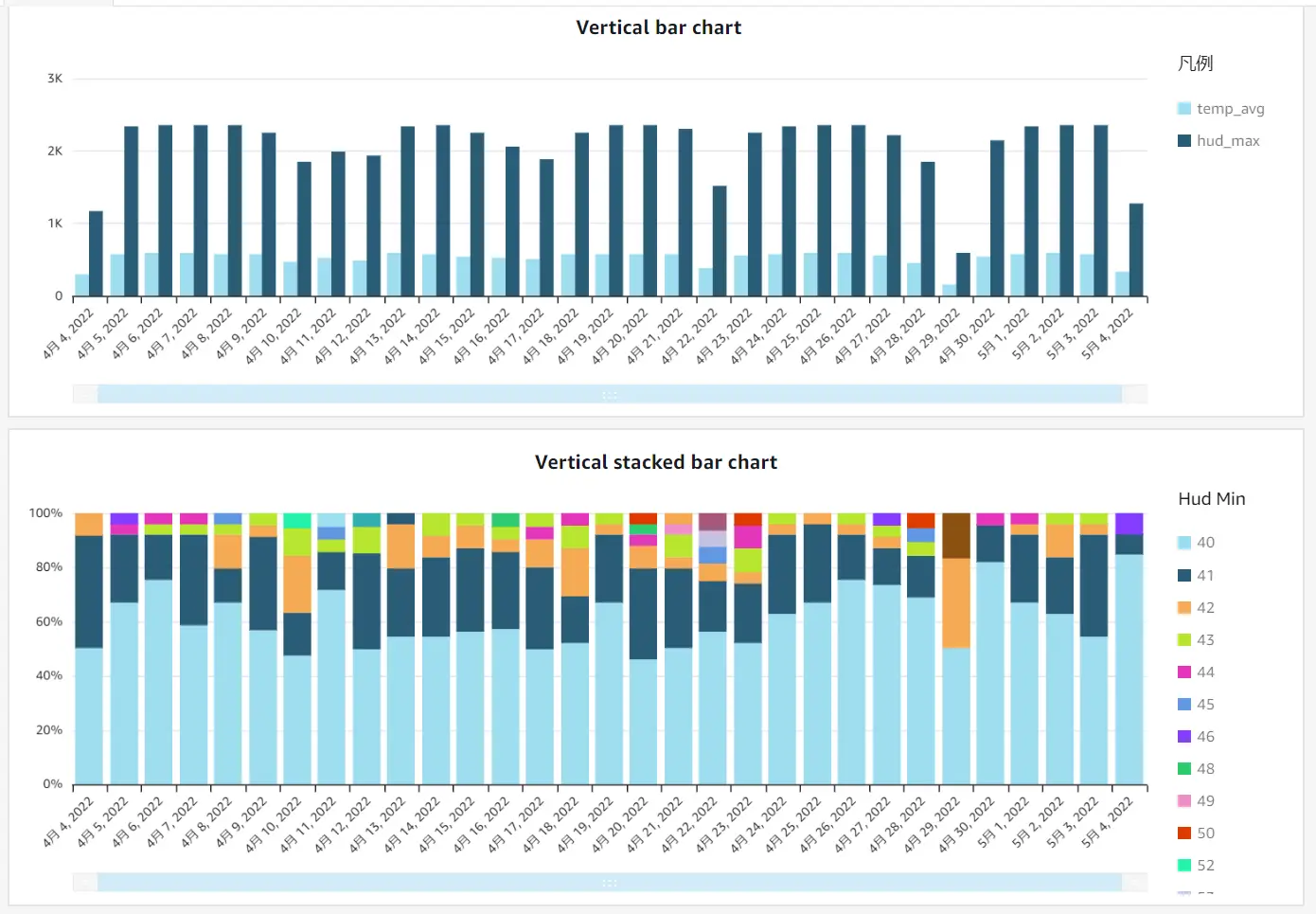
縦棒グラフ に対してアクションを使用し、指定したフィールドに対して、ターゲットフィルタを指定します。これを適用にする事により、縦棒グラフの特定の日付をドラッグ(以下の例ではdt_hour列の2022/4/21) する事で、縦棒グラフの他の棒はグレーアウトされ、下部の縦積み上げ棒グラフに使用される dt_hour 列が連動して 2022/4/21 のグラフのみが表示されます。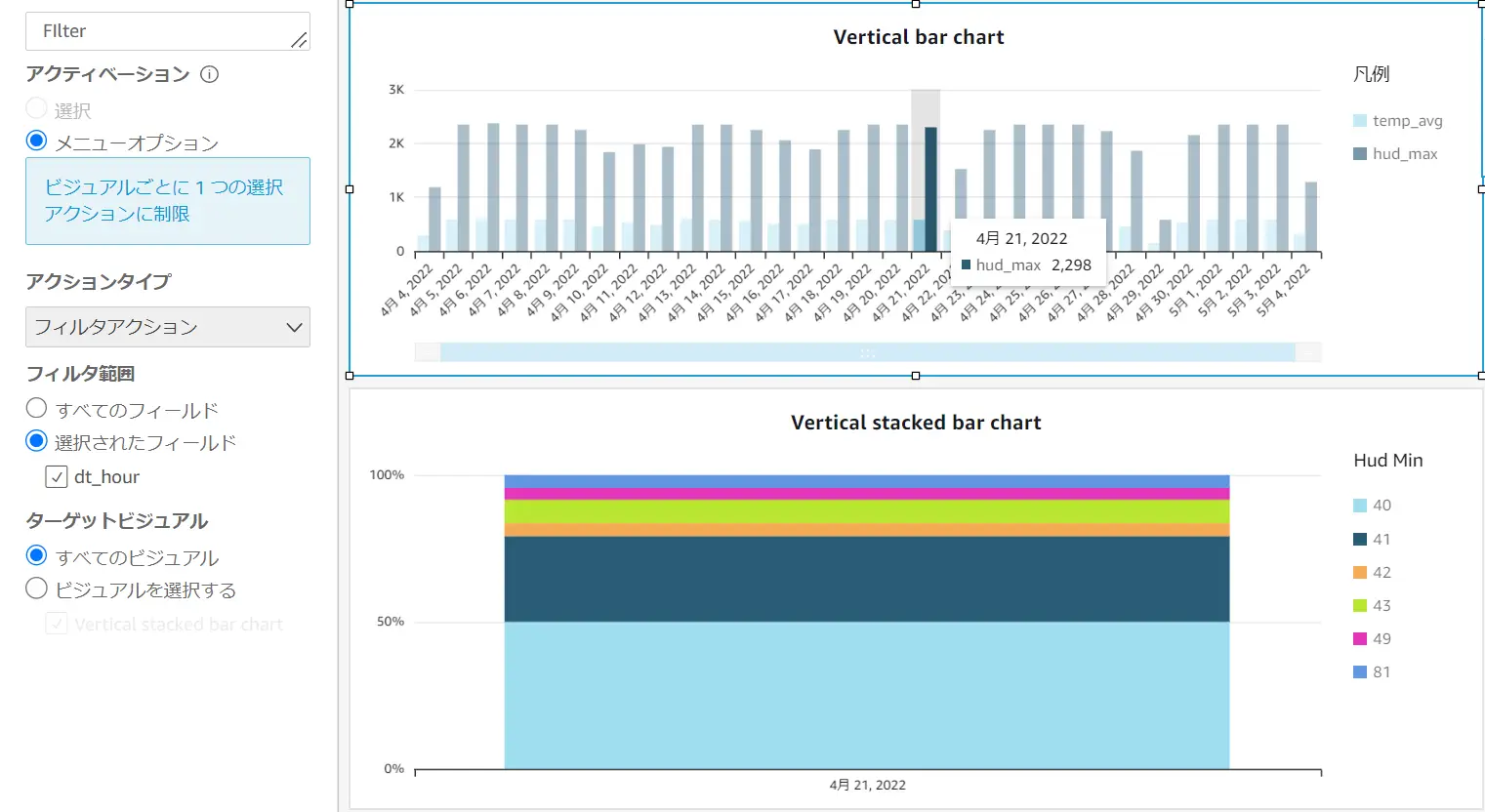
Drill down & Drill up (ドリルダウンとドリルアップ)
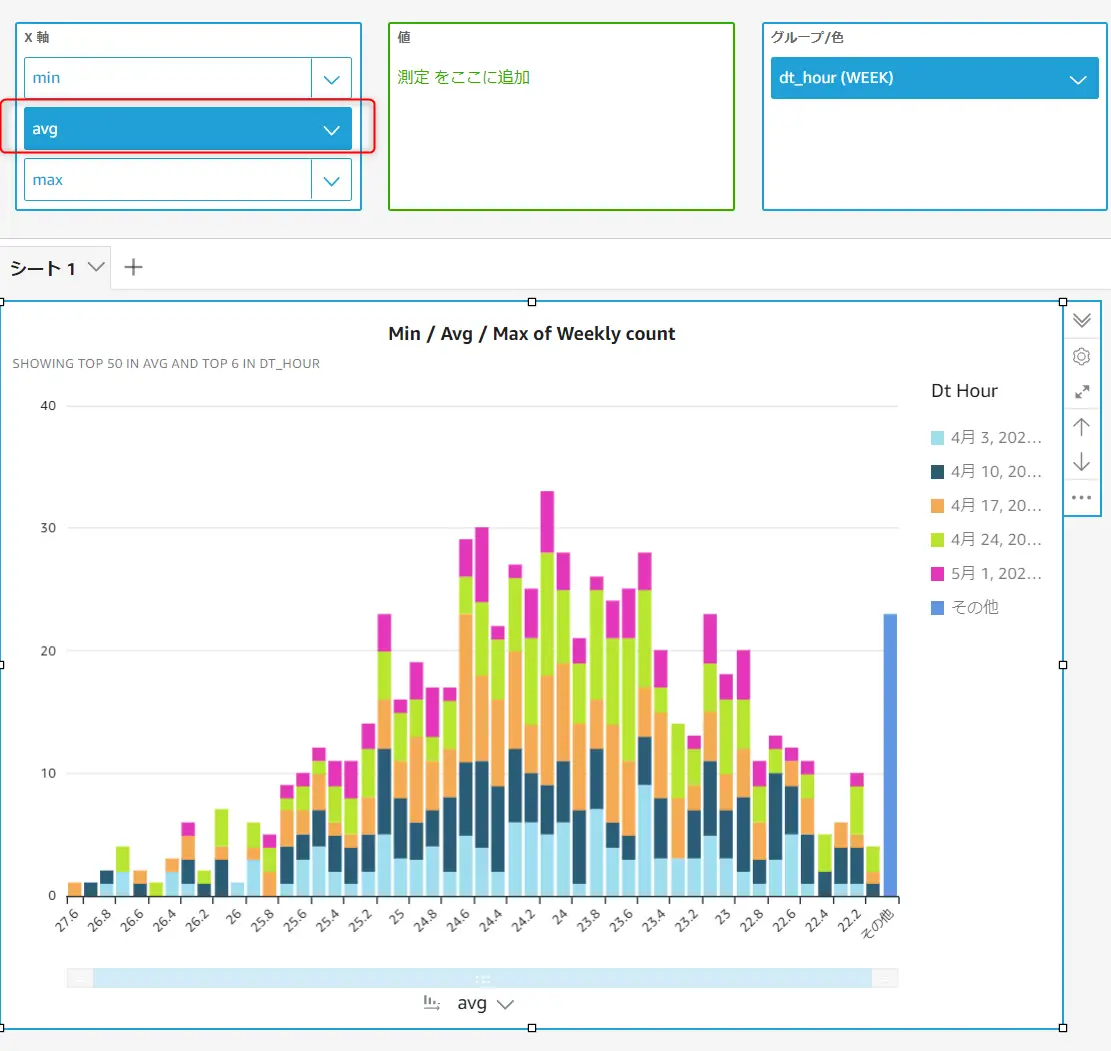
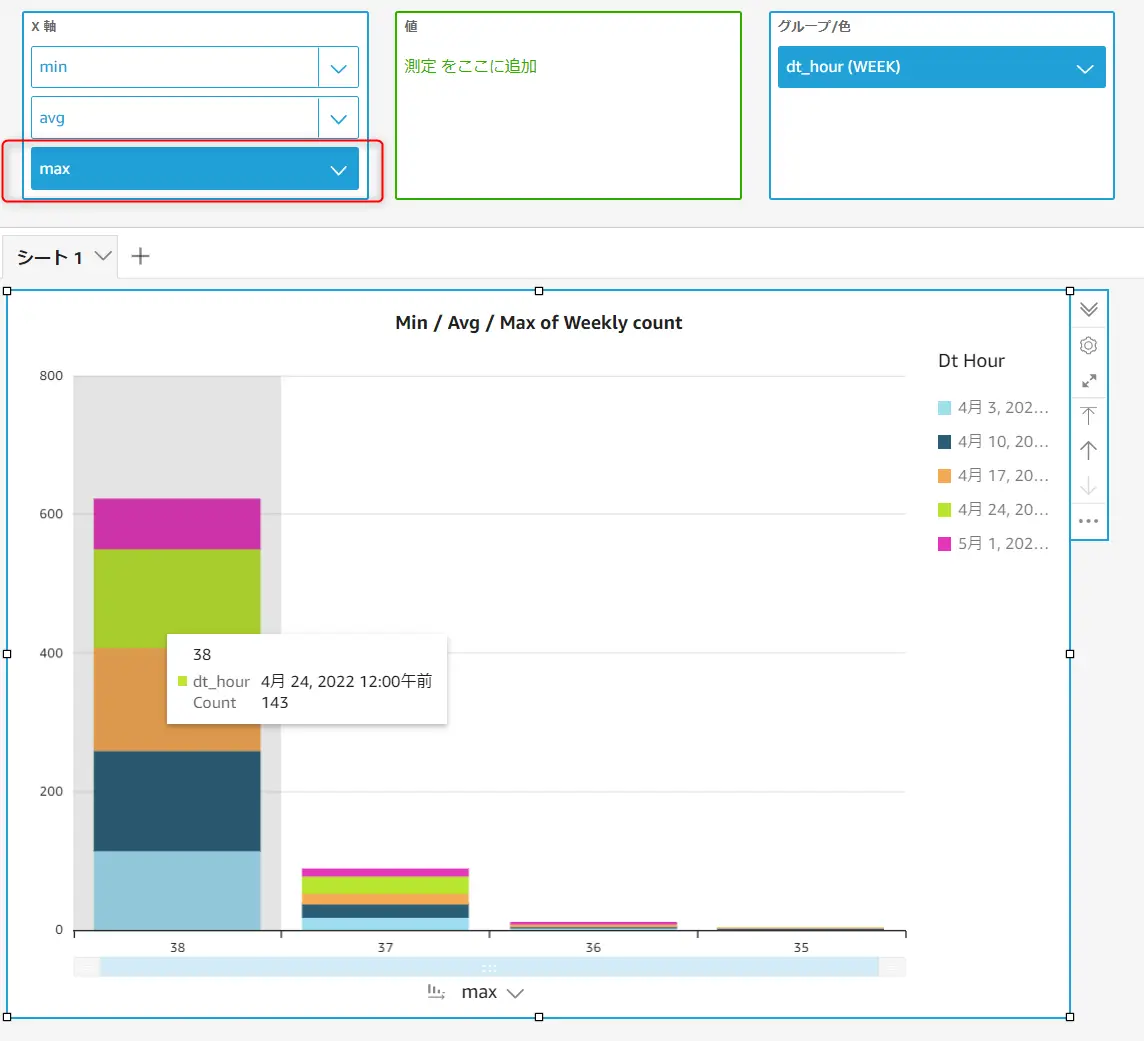
ピボットテーブルを除くすべてのビジュアルタイプで、ビジュアル要素のフィールド階層を作成できます。表示されるデータは、ドリルダウンした先のフィールドの値によって絞り込まれます。以下の例では、X軸に min / avg / max をドリルダウンレイヤとして追加しています。
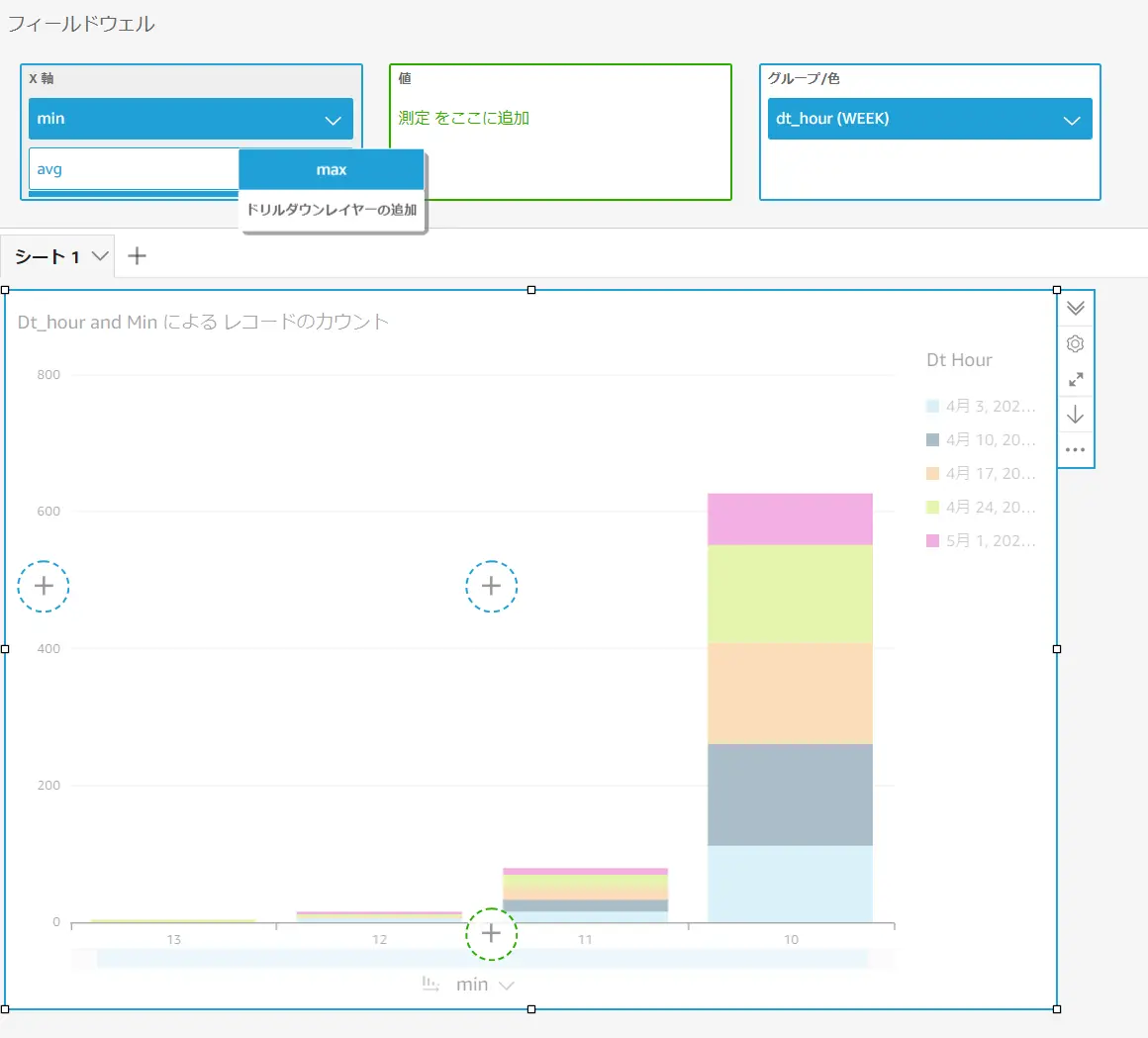
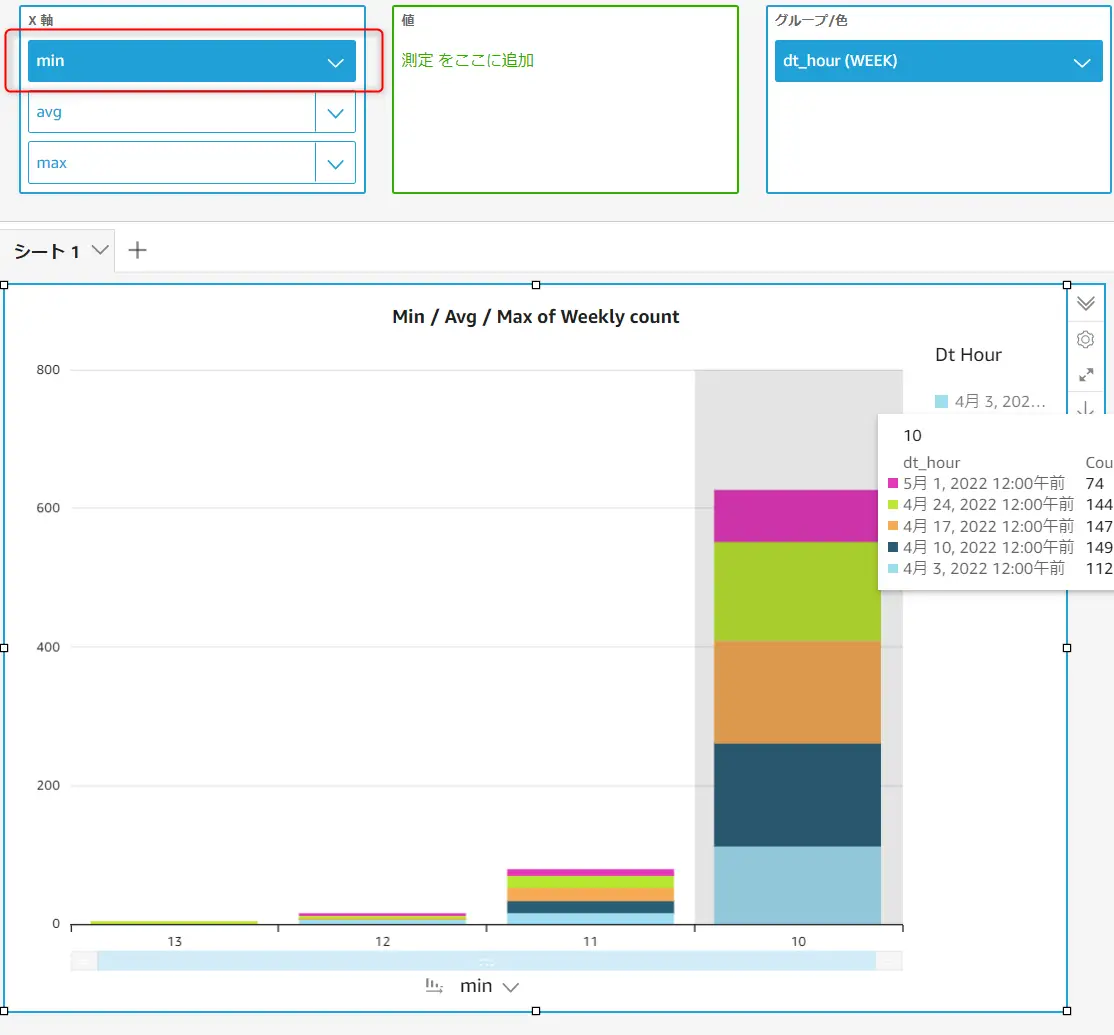
追加されたX軸のドリルダウンは、ドラッグすると、フィールドの変更が反映されます。つまり、一つのビジュアルの中で複数の表現できる事が特徴となるかと思います。
Control(コントロールの作成)
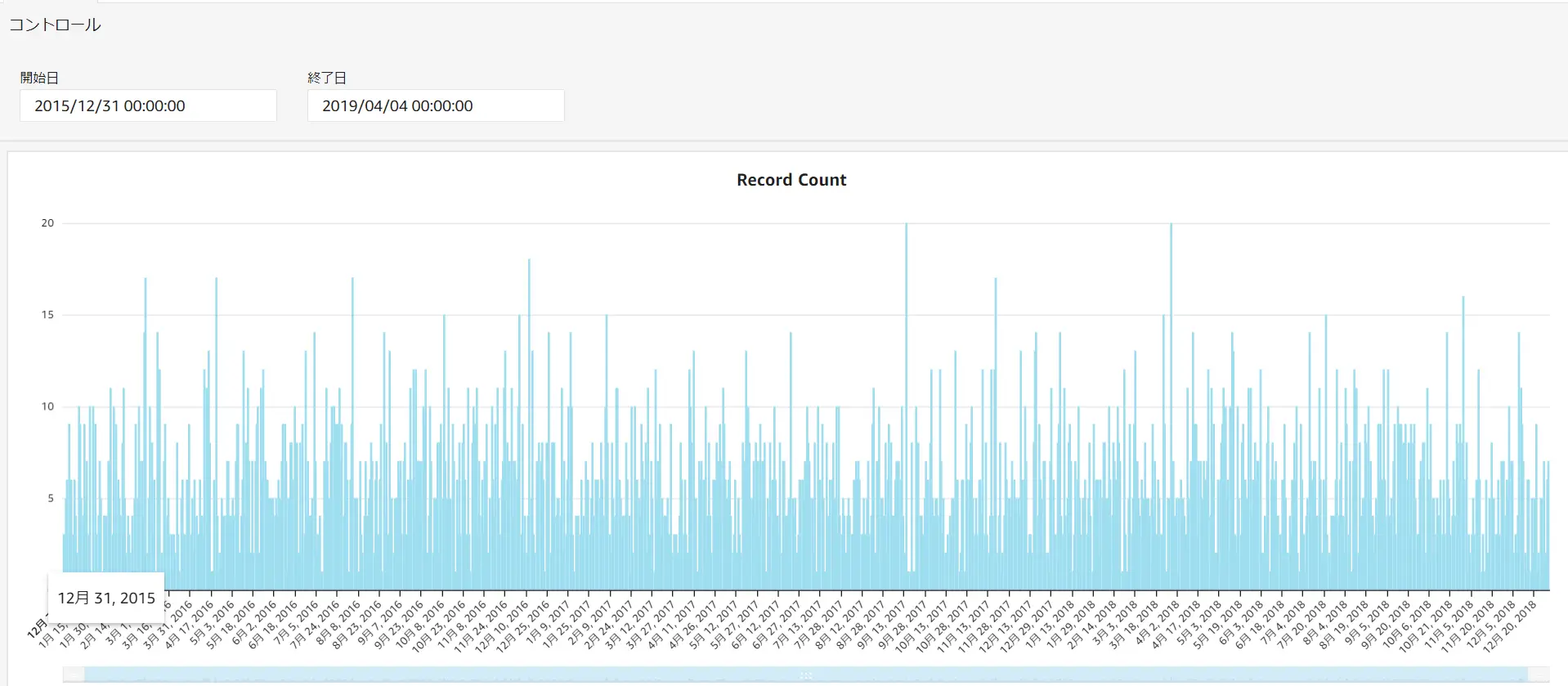
コントロールは、シートの上部にある GUI です。これは、パラメーターやフィルタと組み合わせて作成されます。
下記は、開始日と終了日というパラメーターをコントロールに追加しています。
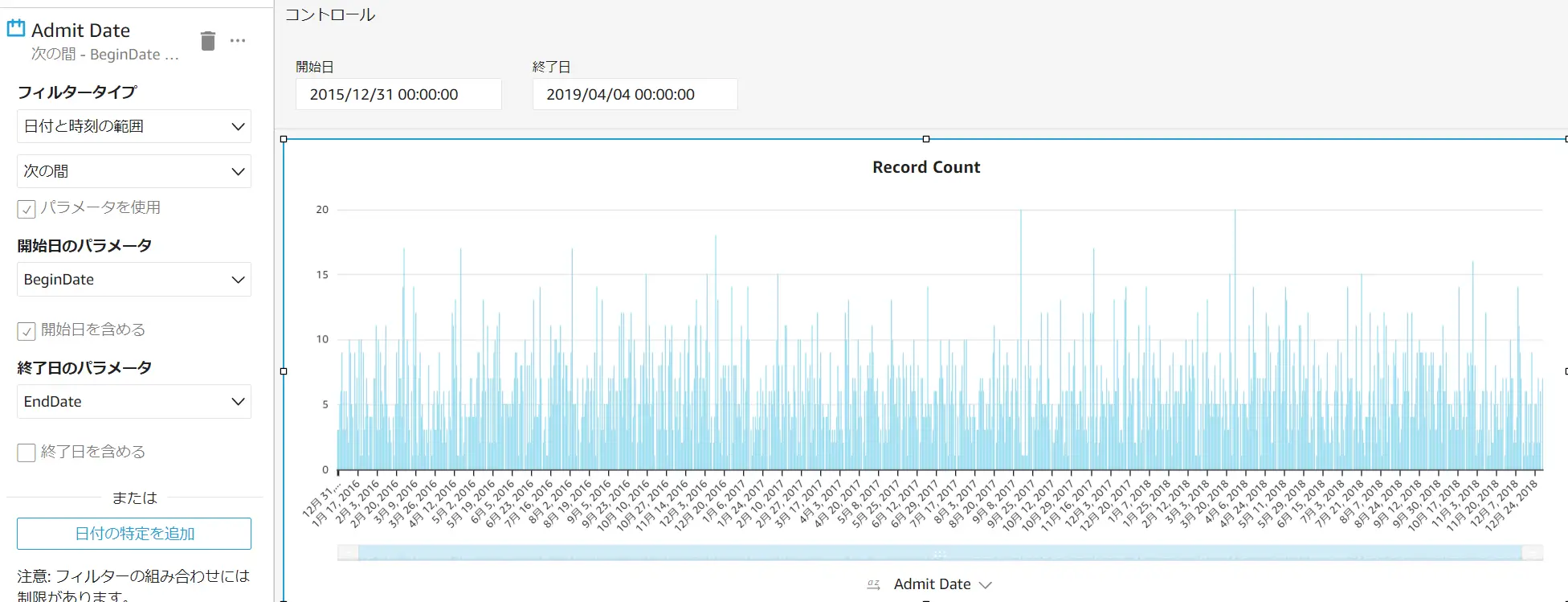
作成されたコントロール画面に対して、フィルター機能でフィールドに対してパラメーターを適用させることで機能します。 例として、開始日を2018/12/01 へ変更すると、2018/12/01 を開始とするデータが表示されます。
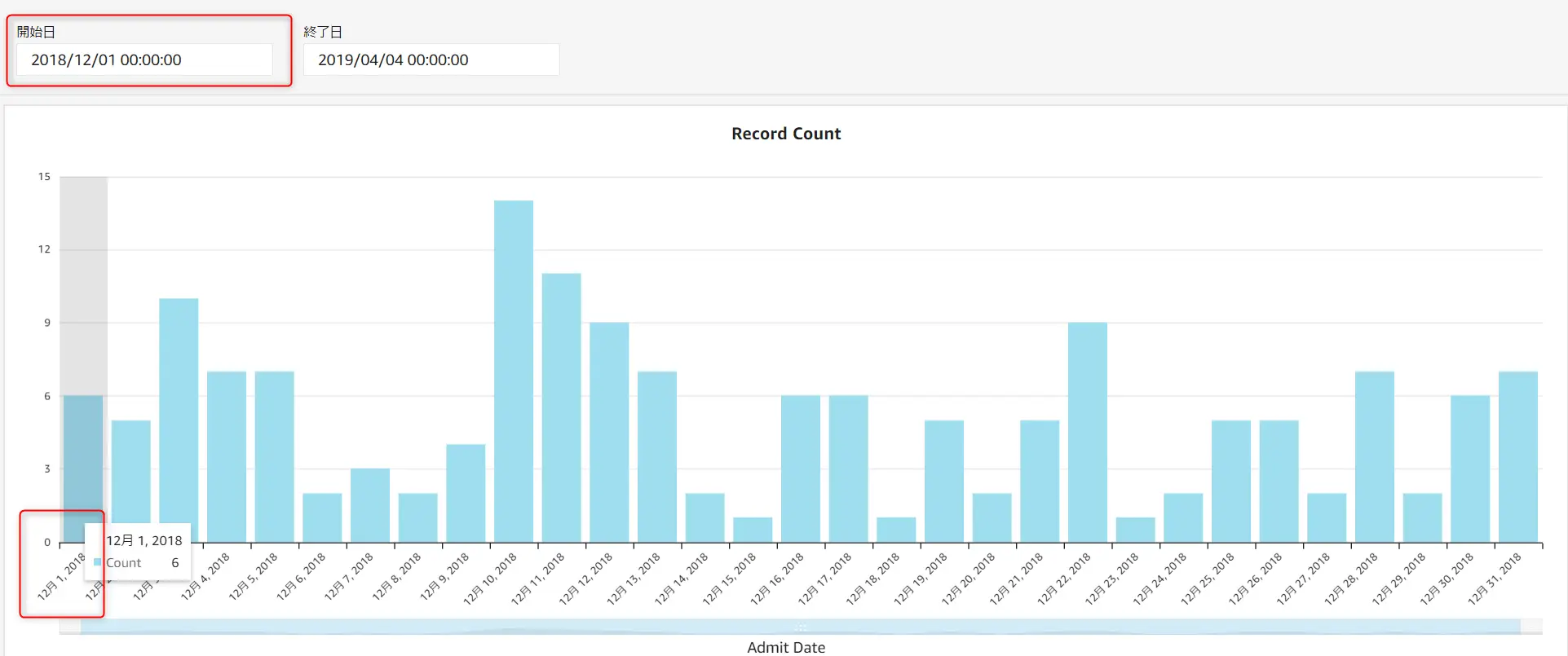
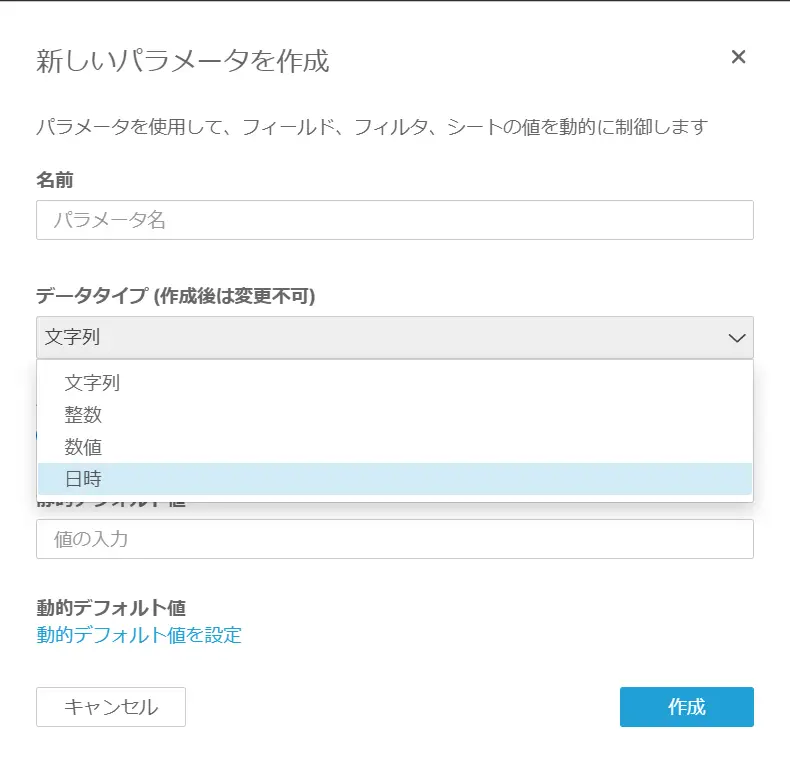
パラメーターは日付に限りません。文字列、整数、数値のデータタイプをサポートしています。
Idea Base to utilize Custom Visual Contents (カスタムビジュアルコンテンツの活用)
カスタムビジュアルコンテンツは、ビジュアルタイプの一つで、ウェブページ、オンラインビデオ、フォーム、イメージを埋め込むことができます。https のURL形式を入力し、URLスキームのイメージがビジュアルとして表現されるものとなります。
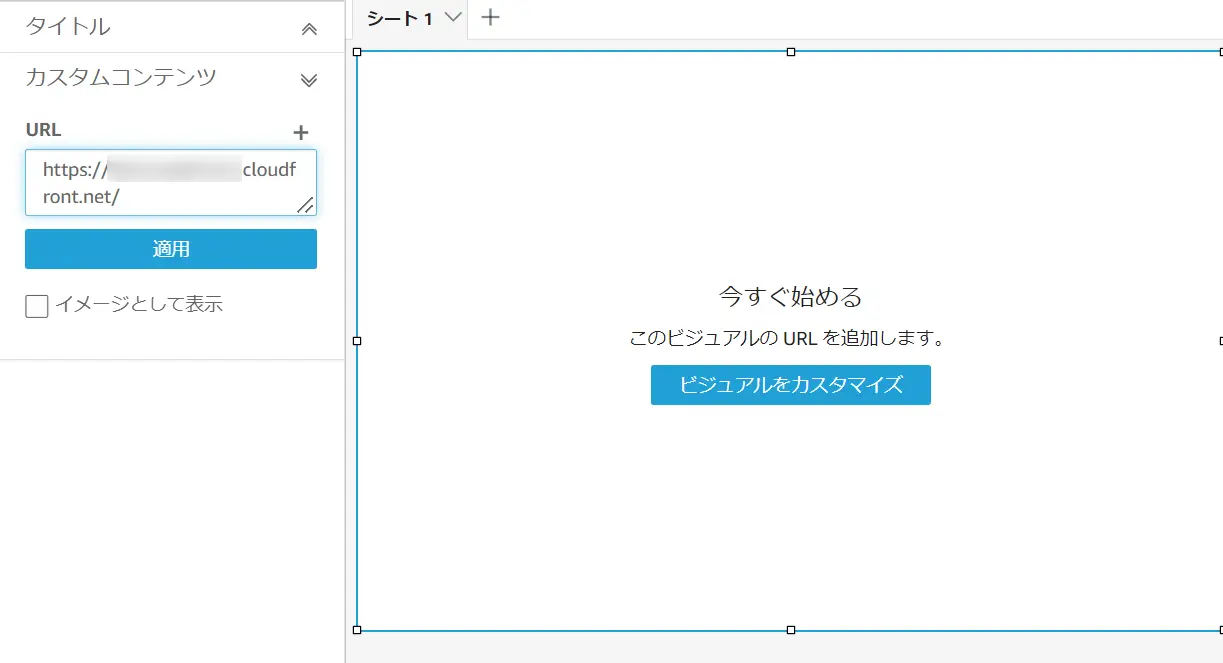
以下の例では、レイアウトをフリーフォームとして設定し、他のビジュアルと前後関係を持たせます。これにより、背景としてのイメージを埋め込みが可能となります。レイアウトのフリーフォーム設定は、重複するビジュアルに前後関係を付与する事が可能な設定です。複数のビジュアルの重ね付けから UI を作成する場合に有用なレイアウトの設定かと思います。
以下の例では、Google Map の埋め込みを使用しています。これは Iframe を使用して一意のURL を公開しています。なお、Amazon QuickSight 標準の地理空間グラフのビジュアルは、OpenStreetMap が使用されているようです。
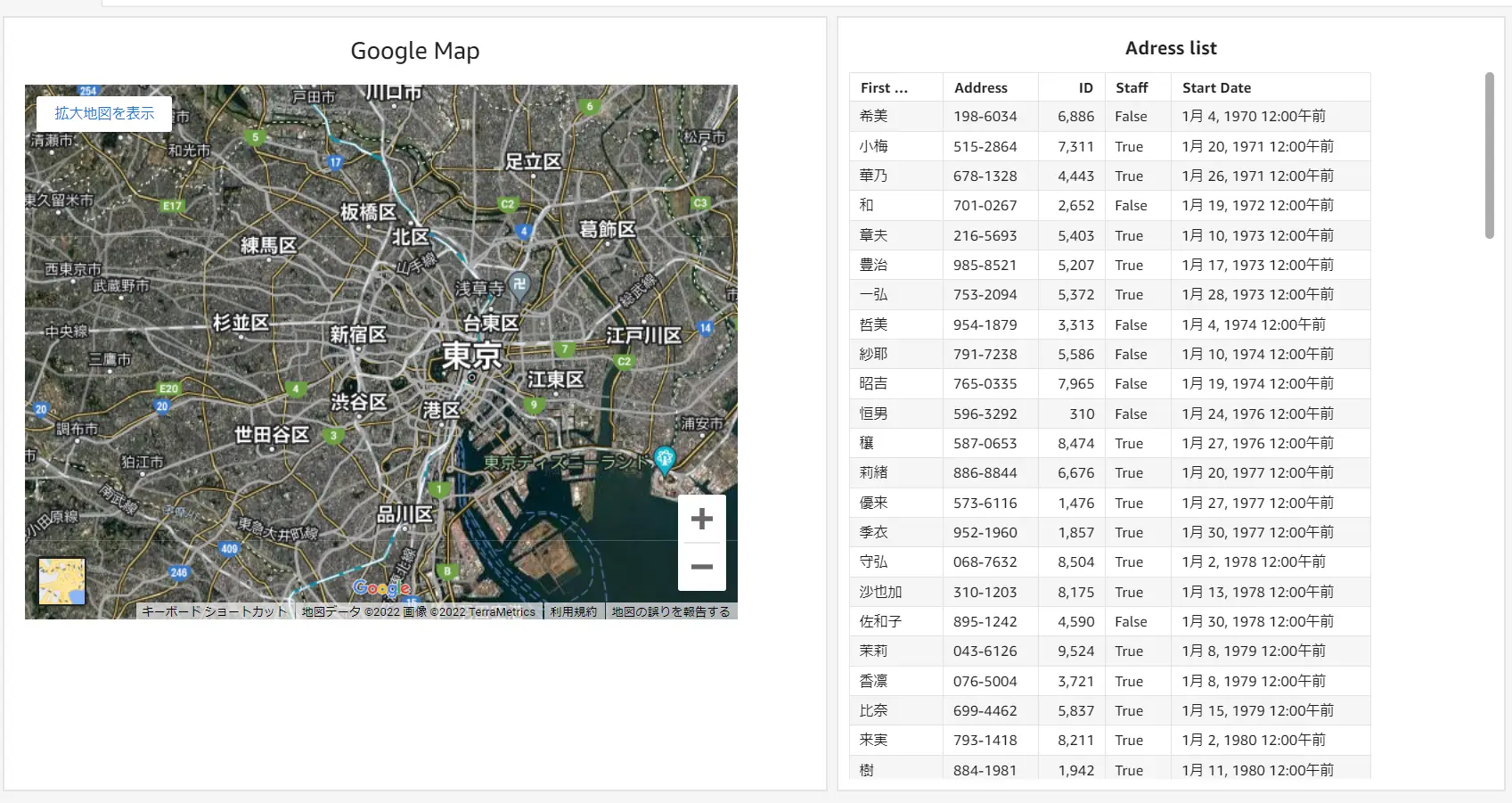
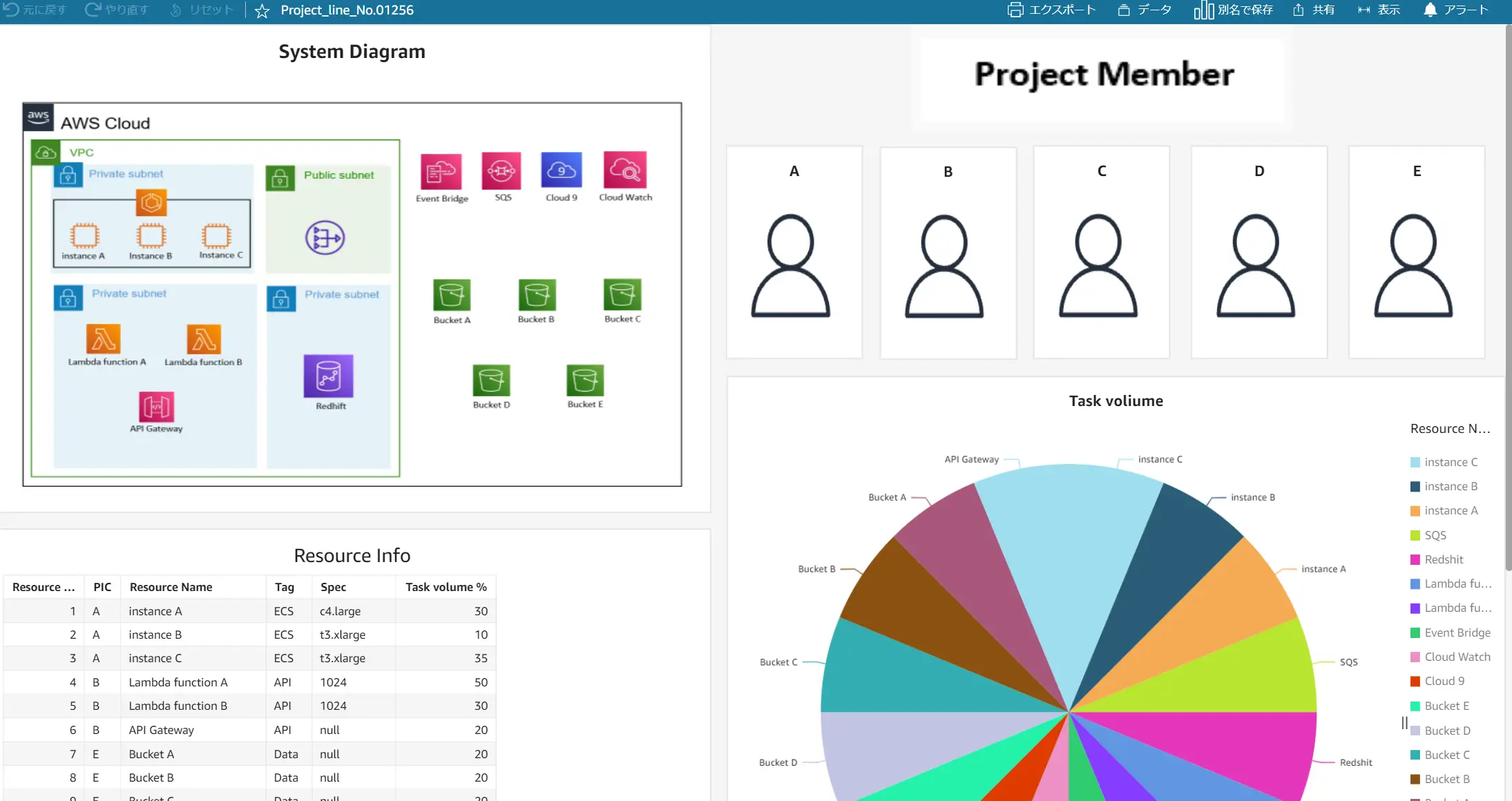
以下の例では、複数のカスタムビジュアルコンテンツを埋め込んでいます。これはプロジェクトの概要と状況を可視化したダッシュボードの一例です。プロジェクト状況のみならず、詳細設計などの共有など、用途はアイディア次第で大規模にダッシュボードを活用する事も可能かと思います。
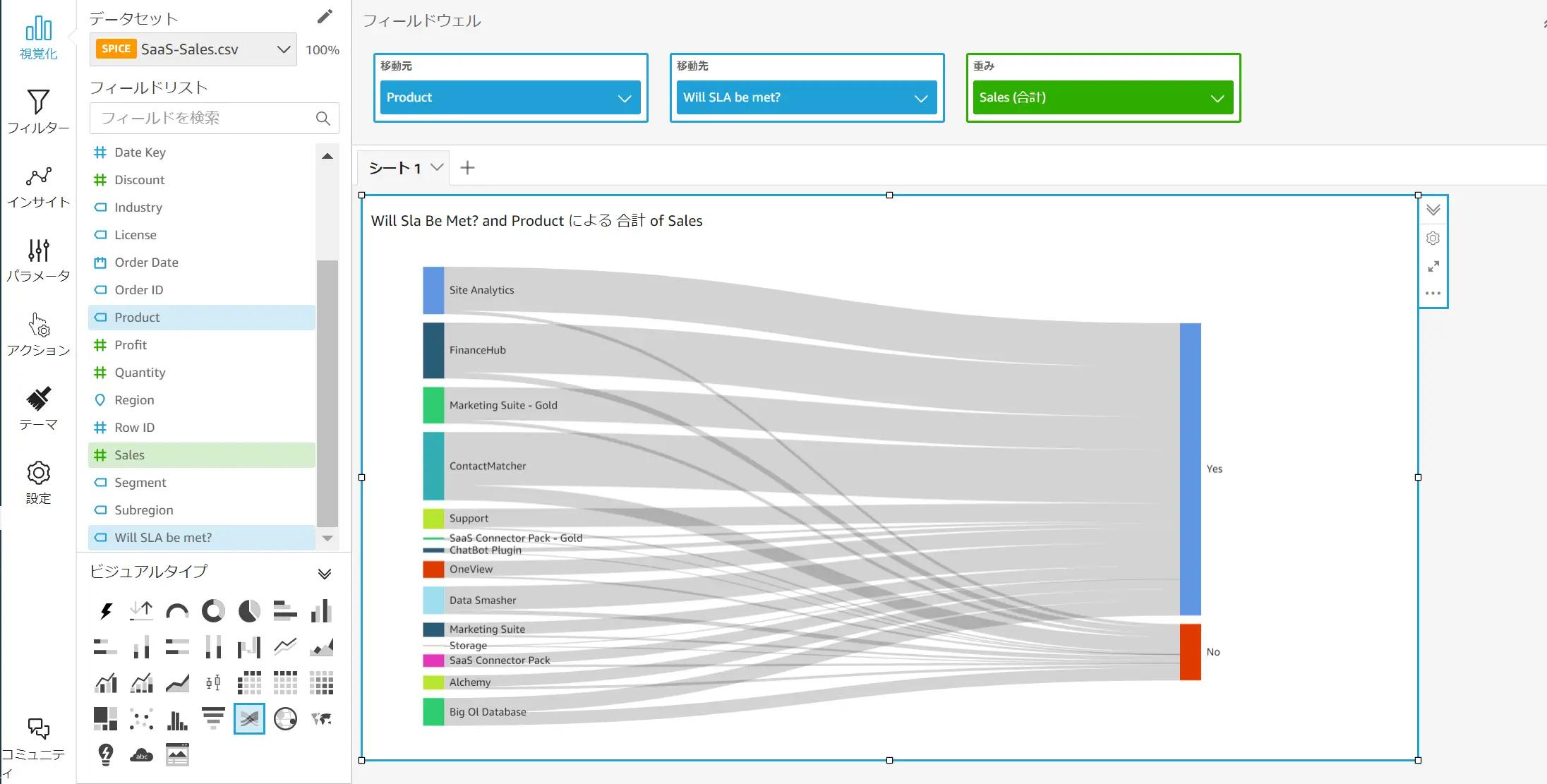
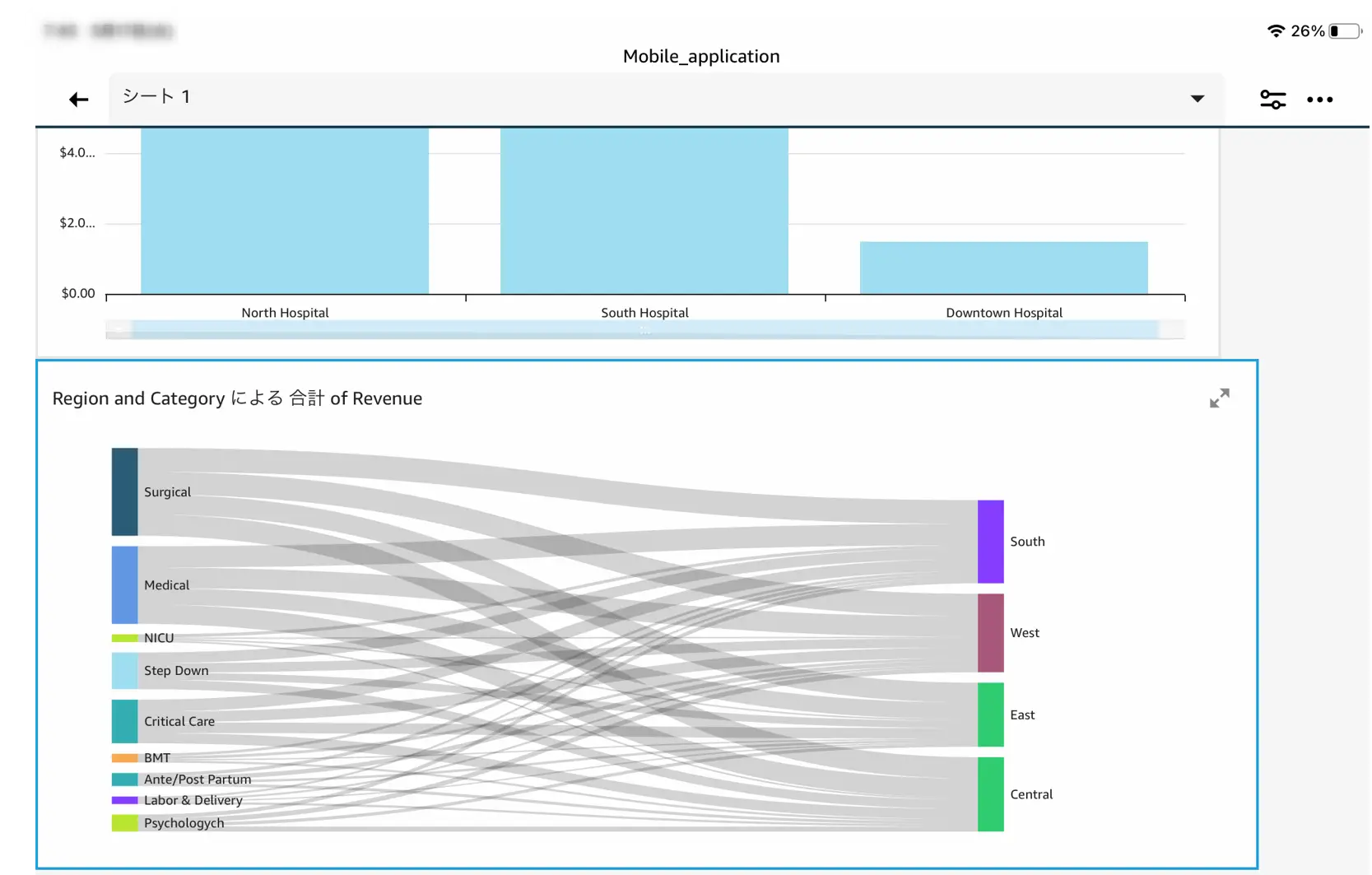
Sankey diagram (サンキーダイアグラムの活用)
トレンドのサンキーダイアグラムは、 1 つのメジャーと 2 つのディメンション から作成され、工程やカテゴリに対するフローと流量を可視化する用途で使用されます。 メジャーは重み付けの役割を果たし、流量を示す線の幅が重み付けの値に応じた太さに比例します。
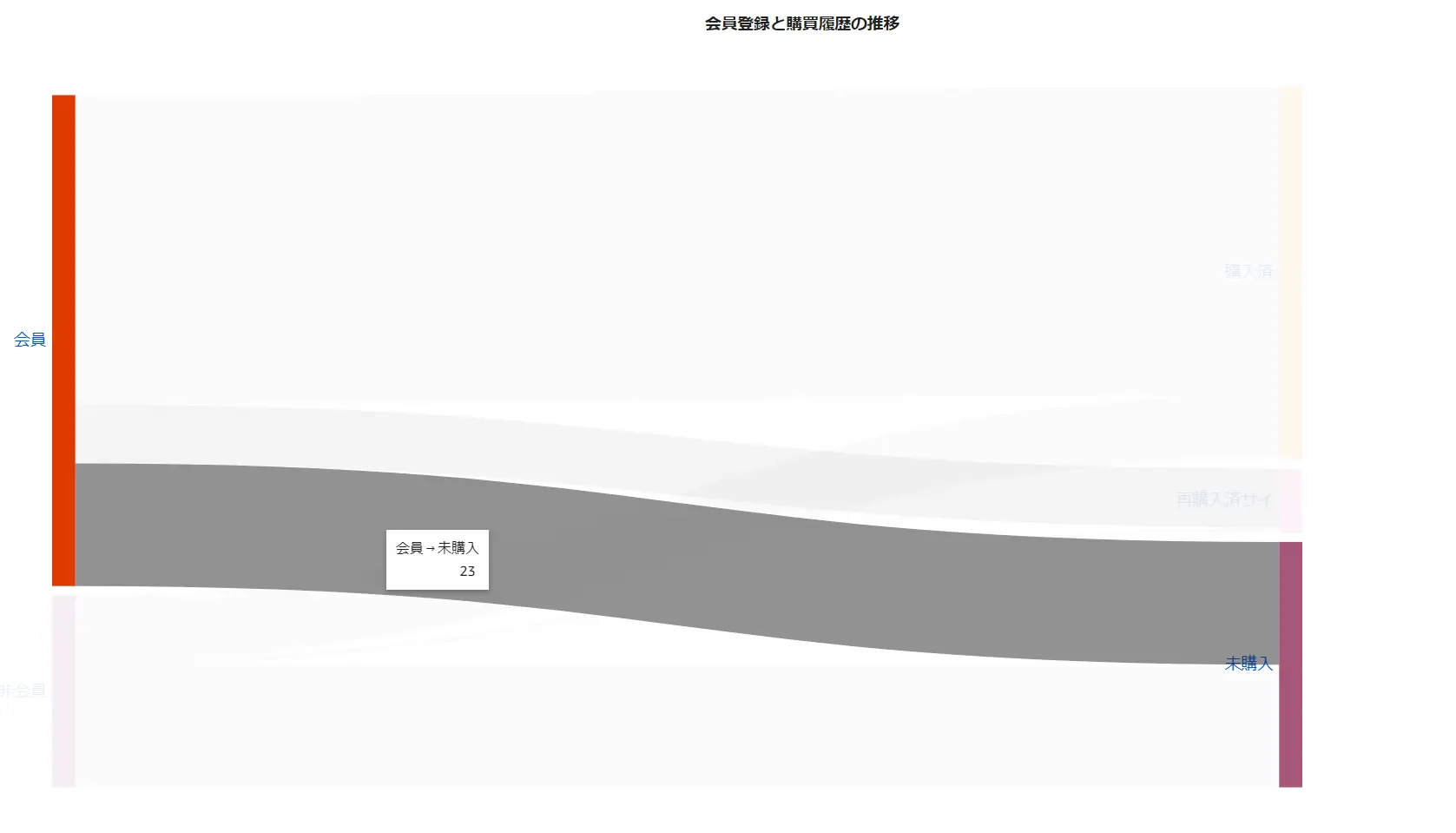
以下は、会員登録者と非会員登録者の購買の推移をサンキーダイアグラムで示す例です。
カーソルを合わせると、非会員が購入に至った曲線、会員が未購入である事を示す曲線が重み付けで定義した数値に沿った形で線の太さを表現します。

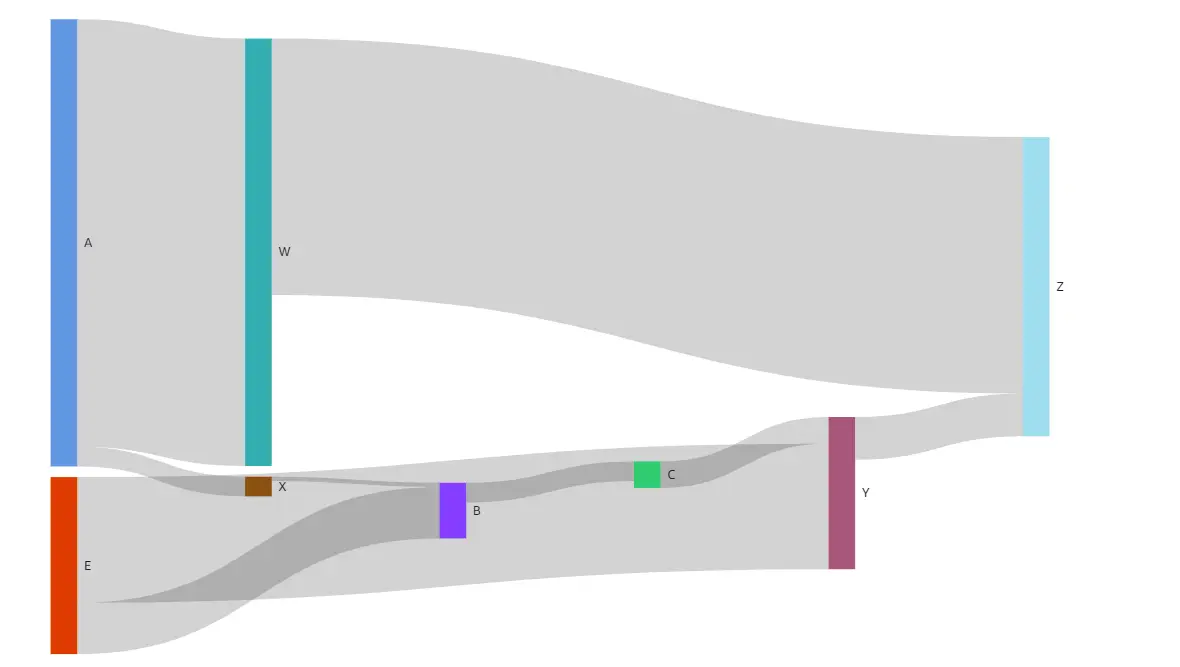
上記は非常に単調な例です。ディメンションフィールドのカテゴリが多ければ多いほどサンキー図の表現はダイナミックになります。また、マルチレベルのサンキー図を表現する際は、ソースとターゲットに重複するカテゴリが含まれている事が条件として、以下のような段階式の表現 をとります。
Mobile Application for Amazon QuickSight (モバイルアプリケーションとしての Amazon QuickSight)
Amazon QuickSight は、 iOSおよびAndroidデバイス向けのQuickSight Mobileをリリースしています。
以下は実際に iOS から見たポータル画面、ダッシュボード群です。
参考情報: Amazon QuickSight announces the all-new QuickSight Mobile app
長文となりましたが、以上となります。
また、改めて AWS のデータ周辺の記事を投稿しようと思います。
最後までご覧いただきましてありがとうございました。

この記事をシェアする



