目次
本記事は、JSUGが選定した旬なテーマを掲載する新しいテーマ別臨時メールマガジン「JSUG EXPRESS VOL.6」連動記事です。
第6回のテーマは「クラウド活用」ということで、今注目の「データレイク」を取り上げます。
デジタルトランスフォーメーションによって既存の産業構造が大きく変革する昨今、企業はデジタル化推進のためにパブリッククラウドをベースにした最新のテクノロジーを採用するのがデファクトスタンダードとなりつつあります。SAPシステムをはじめとする基幹系システムのクラウド移行が本格化フェーズを迎える昨今、クラウド活用の次の一手として注目を集める「データレイク」を基礎から読み解きます。
データレイクとは
用語の出自
HadoopをはじめとするオープンソースBIツールベンダーPentaho社CTOのJames Dixonが、2010年10月New Yorkで開催されたHadoop Worldで、ビッグデータを整理するための新しい概念として、「データレイク」という概念を作ったのが最初のようです。
従来のレポートおよび分析を行う標準的な方法として、最も興味深い属性をあらかじめ識別し、それをデータマートに集約することで処理を行います。その際の問題点として下記2点を指摘しています。
・属性情報の一部のみが調べられるため、結果的に事前に決められた質問にだけ答えられる。
・データが集約された結果、最低限の可視性が失われている。
これらの問題点をふまえつつ、より最適化するための概念として「データレイク」を作ったとあります。(出典:Pentaho, Hadoop, and Data Lakes and wiki)
データレイクの定義
現時点で確立された定義はなく、関連する製品サービスを提供しているベンダー毎に様々な定義がありますが、AWS社の説明は下記の通りです。
「データレイクは、規模にかかわらず、すべての構造化データと非構造化データを保存できる一元化されたリポジトリです。データをそのままの形で保存できるため、データを構造化しておく必要がありません。また、ダッシュボードや可視化、ビッグデータ処理、リアルタイム分析、機械学習など、さまざまなタイプの分析を実行し、的確な意思決定に役立てることができます。」
技術的な要点としては、リレーショナルデータベース(RDMS)のベースとなっている関係モデル(リレーショナルモデル)に適合する構造化データに加えて、それにうまく適合しない非構造化データ(例:数値、文書、画像、音声、動画など)を含めて大量に保持し、活用できる点です。
本記事では一旦「データレイク」の定義を、「規模や形式にかかわらず、データを加工することなく、保存可能な単一のデータストア」として解説します。
データレイク登場の技術背景
古くは2003年に登場した Hadoop Distributed File System(以下、HDFS、大規模分散ファイルシステムのこと)の登場に始まり、2006年にはAmazon Simple Storage Service(以下、Amazon S3)に代表される極めて安価*で堅牢なストレージサービスがInternet経由でいつでも使えるようになったことに依ります。
*: 1GBあたり月額0.025USD=3円以下、容量10TBで月額250USD=3万以下、実際にはリクエスト数等別途課金は発生しますが、お客様にとっては特に気にされない程度に収まることが多いです。価格表はこちら。
HDFSは Google社の分散ファイルシステム(Google File System)のオープンソース版であること、またAmazon S3はアマゾン ウェブ サービス(以下、AWS)社最初に提供した中核のクラウドサービスであることからお判りいただけるかと思いますが、最新のクラウドを支える最も重要なストレージ基盤の登場がデータレイクが登場する技術背景としてあります。(ここでいうストレージとは、データを格納するIT基盤のことですが、説明を簡略化するために本来分けるべき「データ」と「(DBスキーマなどの)メタデータ」を合わせてデータとしています。)
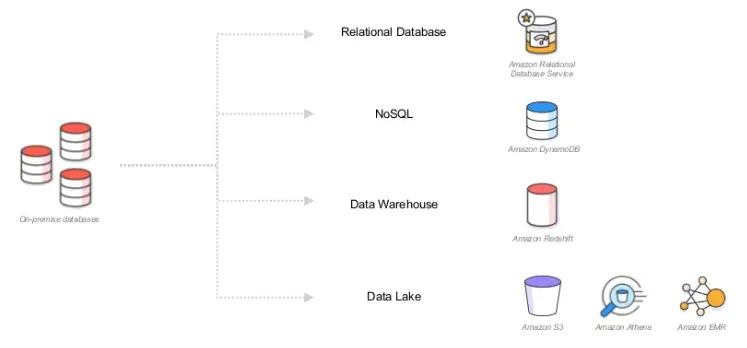
参考1:既存のRDMSシステムをAWSに置き換えると・・・
従来のオンプレミス環境でリレーショナルデータベースを基盤として稼働させていた分析系システムを、AWS社のPaaSのどれに置き換えることができるかを簡単にまおとめると下記の通りです
。出典:Best Practices for Building Your Data Lake on AWS
参考2:データウエアハウスとデータレイクの比較表
出典:AWS社資料データレイクとデータウェアハウスの比較 – 2 つの異なるアプローチをもとにSAP、AWS関連キーワードを弊社加筆
| 特徴 | データウェアハウス | データレイク |
|---|---|---|
| データ | トランザクションシステム、業務データベース、基幹業務アプリケーションからのリレーショナルデータ | IoT デバイス、ウェブサイト、モバイルアプリケーション、ソーシャルメディア、企業アプリケーションからの非リレーショナルデータとリレーショナルデータ |
| スキーマ | DW の実装前に設計 (スキーマオンライト) | 分析時に書き込み (スキーマオンリード) |
| 料金/パフォーマンス | 高コストのストレージを使用、クエリ結果の取得は最速 | 低コストのストレージを使用してクエリ結果をより速く取得 |
| データ品質 | 高度にキュレートされたデータで、事実の情報源として機能 | 任意のデータで、キュレートできるかどうかは不明 (raw データ) |
| ユーザー | ビジネスアナリスト | (キュレートされたデータを使用する) データサイエンティスト、データ開発者、ビジネスアナリスト |
| 分析 | バッチレポート、BI、可視化 | 機械学習、予測分析、データ検出、プロファイリング |
| AWS | Amazon RedShift | Amazon S3,Amazon Glue,Amazon EMR,Amazon Athena |
ERP6.0時代のSAP製品キーワード (周辺系は除く) | SAP BW SAP Business Object BI(BOBI) SAP BW on HANA | ー |
| 最新のSAP製品キーワード(周辺系は除く) | SAP HANA Platform SAP BW/4HANA SAP Business Object BI(BOBI) SAP HANA Enterprise Cloud SAP Analytics Cloud(旧BO Cloud) | SAP Cloud Platform Big Data Services SAP Vora |
SAP環境がある前提でのデータレイク導入ユースケース
オープンな技術を含めて、最新の技術トレンドを広く俯瞰した形でのユースケースについて考察されている下記のBlogを参考に、弊社にて独自に修正加筆させて頂きました。一部割愛した内容がありますので、ぜひ原文をご一読ください。
A future-proof Big Data Architecture by Werner Daehn (※ページ公開終了)
Special Thanks to Werner ,your insight is open and valuable for us!
著者はSAP社のコンサルタントの方です。2017年10月の記事ということで、1年以上経っておりますが、基礎技術面でオープンな見解を展開されており、弊社の現場経験としても腹落ちする内容でした。具体的には、ERPシステムやDWHシステムが既存環境として既にあり、そこにデータレイクを導入する場合の基本技術の解説と弊社での経験に基づいた理想と現実を述べています。基礎編と比べて、最新クラウド用語やオープンソースのキーワードがちりばめられておりますので、少しとっつきにくいかもしれませんが、あらかじめご了承ください。
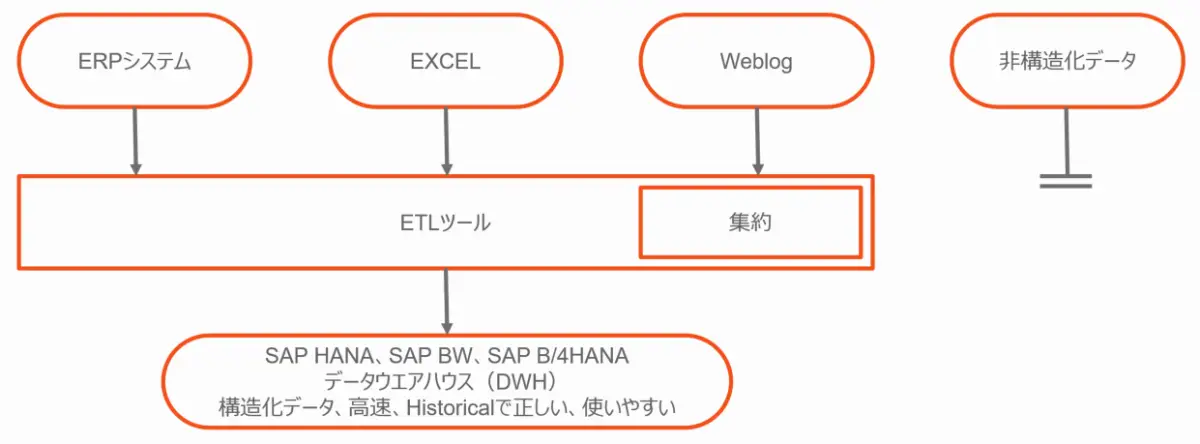
データウェアハウスのアーキテクチャ
従来のデータウェアハウス(DWH)アーキテクチャでは、構造化されたデータソースとしてERPシステムやExcelシートなどがあります。 これらのデータは、ETLツールによってソースシステムから日々読み込まれ、DWH上にあらかじめ定義された構造に変換されます。 データ量が多すぎるソースについては、事前定義されたロジックによって集約後DWHに格納されます。
非構造化データは通常ロードされません。
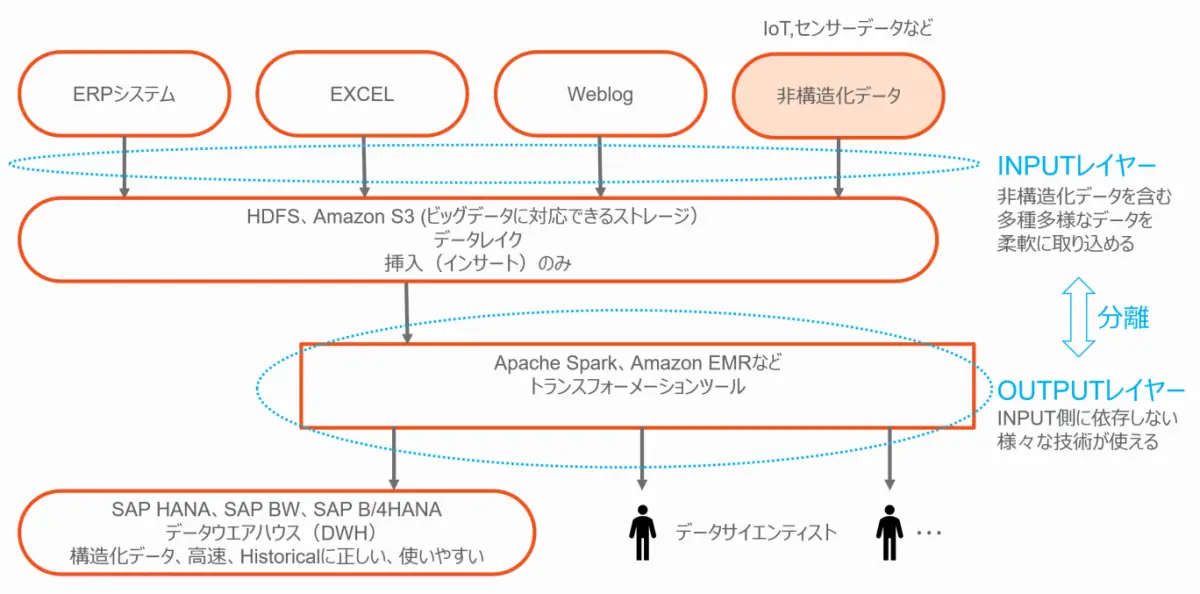
第1段階としてステージング領域としてのビッグデータ
本段階では、すべてのデータを保存して利用可能にすることです。ここでは、ウェブログなどの非構造化データを含め、全ソースからのデータをデータレイクに提供しています。そのデータを活用するのは、DWHとデータサイエンティストになります。
注:データレイクはソースシステムのコピーではなく、常にデータは追加(インサート)されます。それゆえHistoricalに(過去から現在の経緯でみれば)、常に正しいことになります。
第1段階のビッグデータ・アーキテクチャ
理想
データレイクには履歴データが含まれており、データウェアハウスはそれから再構築することができます。 例としてERPシステム内の「取引先情報」の削除があります。 この情報は、レコードを追加することによってデータレイクに追加(インサート)され、追加の列には削除フラグが保持されます。 正確には各レコードに2つの追加列、change_timestamp(=データがData Lakeによって受信されたときのタイムスタンプ)とchange_type(=削除されたyes / no)があります。以上がリアルタイム性の確保という意味では理想的なアーキテクチャです。
現実
実際の現場では、ERPに格納されているマスタデータは、月次で更新かけるというのが、会社全体のデータ整合性確保と実運用との親和性という観点では現実的かもしれません。逆にIoTのセンサーデータなどで局所的に使われるマスタデータの場合には、当然整合性の確保自体がシンプルになりますので、結果的に理想形で運用もありかと思います。
理想
データをわかりやすいデータウェアハウス構造に変換するために、従来のETLツールは当然使用可能です。 しかし、データサイエンティストが興味深いアルゴリズムを見つけたと仮定すると、データウェアハウスをロードするときに、これらのアルゴリズムが使用できるとさらに有益です。ちなみに データサイエンティストが選んだ現在の最適なツールはApache SparkやAmazon EMRですが、ETLツールほどユーザーフレンドリーではないものの大変強力なので、この絵ではETLつーると共に使用することを前提としています。 これらによってすべてが可能となり、どちらか一方をケースバイケースで利用することになります。
ここで覚えておきたいことは、ETLツールの抽出(Extract)と変換(Transformation)についてです。抽出機能を使用してソースシステムから変更データを抽出し、それをデータレイクに書き込むことができます。日本語環境を前提にした場合、この時点で文字コード変換を済ませておくことが、システム全体の(可読性に欠けるデータをデータレイクに格納して、つど変換するよりは)効率的によいか思います。その後にデータレイクからこのデータが読み込まれ、通常のDWH用変換することになります。
現実
データサイエンティストがメインユーザであれば、削除フラグ的なものも包括して分析かけることができますが、国内ではまだまだデータサイエンティストの方が少ないこともあり、一般ユーザーがメインになることが多いかもしれません。
一般ユーザーレベルでの基幹システムの活用を想定した場合、SQLを使える程度に止まるという現実とすると、より整理されたデータがデータレイクにあって欲しいということになり、このあたりもエンタープライズならではの使いこなしを考慮する必要があります。
データレイクは、とにかく生データを放り込んでおく場所なのか?
データレイクの話をする場合に、避けては通れないトピックです。
大量の生データを極めて安価に保持できるようになった現在、「データレイク」が注目されているわけですが、「データレイク」の対義語として「データスワンプ」があります。スワンプ(Swamp)とは沼地のことで、現場で使えないデータが溜まっている様子を例えています。
データスワンプ化するのを防ぐためのアプローチとして「データマネジメント」や「データガバナンス」を考えて実装する必要がありますが、本記事ではそれらに取り組む際に有用なフレームワークとしてDMBOKをご紹介します。
下記がDMBOK1の要素ですが、V2になって「Data Integration & Interoperability(データインテグレーション&相互運用性)」が追加されました。
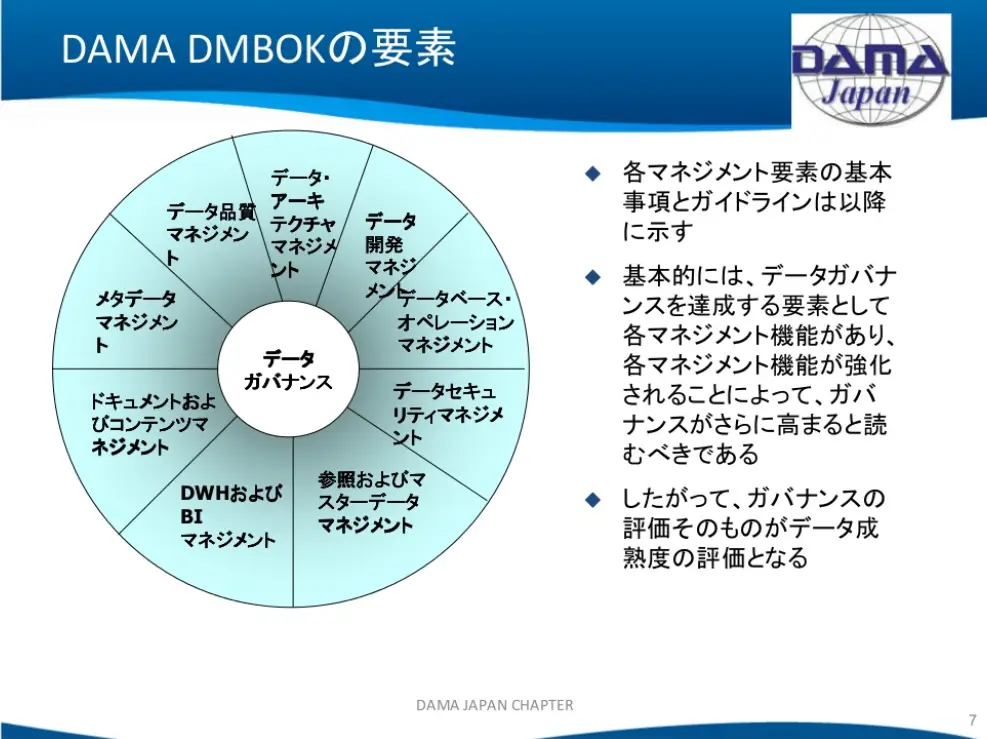
なお、DMBOK概要については、こちらの記事「データマネジメントとは何か」をご一読されることをお勧めします。上記でご紹介した説明スライドもSlideShareで公開されており、下記にある最後のコメントは胸に染みるものがありますw
というわけで、最後に出てくる、というか、残ったのが「リファレンス&マスターデータ」、「メタデータ」、「データクオリティ」あたりになります。
この辺、みんな「大事だよね」と総論では評価されるものの、なかなか具体的なインパクトが分かりづらく、理解されづらい領域なのではないかと思います。
なぜなら地味なのです。地味すぎるのです。
まとめ
「データレイク」というキーワードが指すものが何者なのか、少しあたりをつけられれましたでしょうか。なお、データレイクの基本動作については、少しとっつきにくいかもしれませんが、アーキテクチャ的に集中型から分散型になり、その結果スケーラビリティ(拡張性)やアジリティ(俊敏性)が確保されているのが少しでもお判りいただければ幸いです。
なお、データレイクがその力を発揮するためには、澄んだ水のようにすぐに使えるデータが格納されている必要があり、それを維持管理する仕組みとしてDMBOKで定義されたような裏側で支えるための仕組み作りが必要になるとともに、最新のクラウドサービスに代表されるITの活用がキーになります。
ちなみに「理想と現実」で取り上げたトピックについては、ビッグデータの「4V」のひとつ「Variety」に関するものです。それぞれのデータが前提としている状況はさまざまであり、無条件に簡単に結合・統合することはできません。ここに 「Variety」 に対処する現実の困難さがあり、殊エンタープライズの世界においては長年稼働してきた複数のシステムから成り立っていることもあり、顕在化しやすいと考えています。その際には複雑な背景、事情から現時点でITですぐに解決するには限界があるとも考えており、このあたりのさじ加減が今後重要になってくるのではないかと弊社では考えております。

長文最後までお読みいただきありがとうございました。
- タグ

この記事をシェアする
![[re:Invent 2022 レポート] Eli Lilly 社は SAP 移行と運用をどのようにしているのか](/media/fFfbMpbGNg2nfc7OLvAH31FZjKX4cTDjYAoevX3v.jpeg)