











![[re:Invent 2023レポート] Data processing at massive scale on Amazon EKS](/media/TBoiiMyjOQDaOH6bNK3D4oLQTNtIfJtEs3DKPMl8.png)
目次
Introduction
AWS Re:Invent の中で参加したセッションの振り返りとなります。セッションをレポート形式で投稿します。
今回は Data Engineer 、Developper 向け、Data processing at massive scale on Amazon EKS と題した Data On EKS のセッションに対するレポートとなります。

Description
Organizations use their data to make better decisions and build innovative experiences for their customers. They are also looking for modern methods of processing large volumes of data to gain greater insight. In this session, learn why organizations are choosing to build their data-intensive applications on Amazon EKS to decrease operational overhead by using AWS-managed services and also use innovations from the open source community. Learn best practices for architecting large-scale data processing with Spark using technologies like Karpenter.
企業はより良い意思決定を行い、顧客に革新的な体験を提供するためにデータを活用しています。また、より深い洞察を得るために、大量のデータを処理する最新の方法を模索しています。本セッションでは、AWSが管理するサービスを利用することで運用のオーバーヘッドを削減し、オープンソースコミュニティのイノベーションを活用するために、企業がAmazon EKS上でデータ集約型アプリケーションを構築することを選択する理由を学びます。Karpenterのような技術を使ってSparkで大規模データ処理をアーキテクトするためのベストプラクティスを学びます。
Agenda
セッションの流れは以下となっていました。

Kubernetes for data processing
データ処理に対して kubernetes を使用する理由は、Scalability , Orchestaration , Poratability , Standardization の点が重要であると述べています。
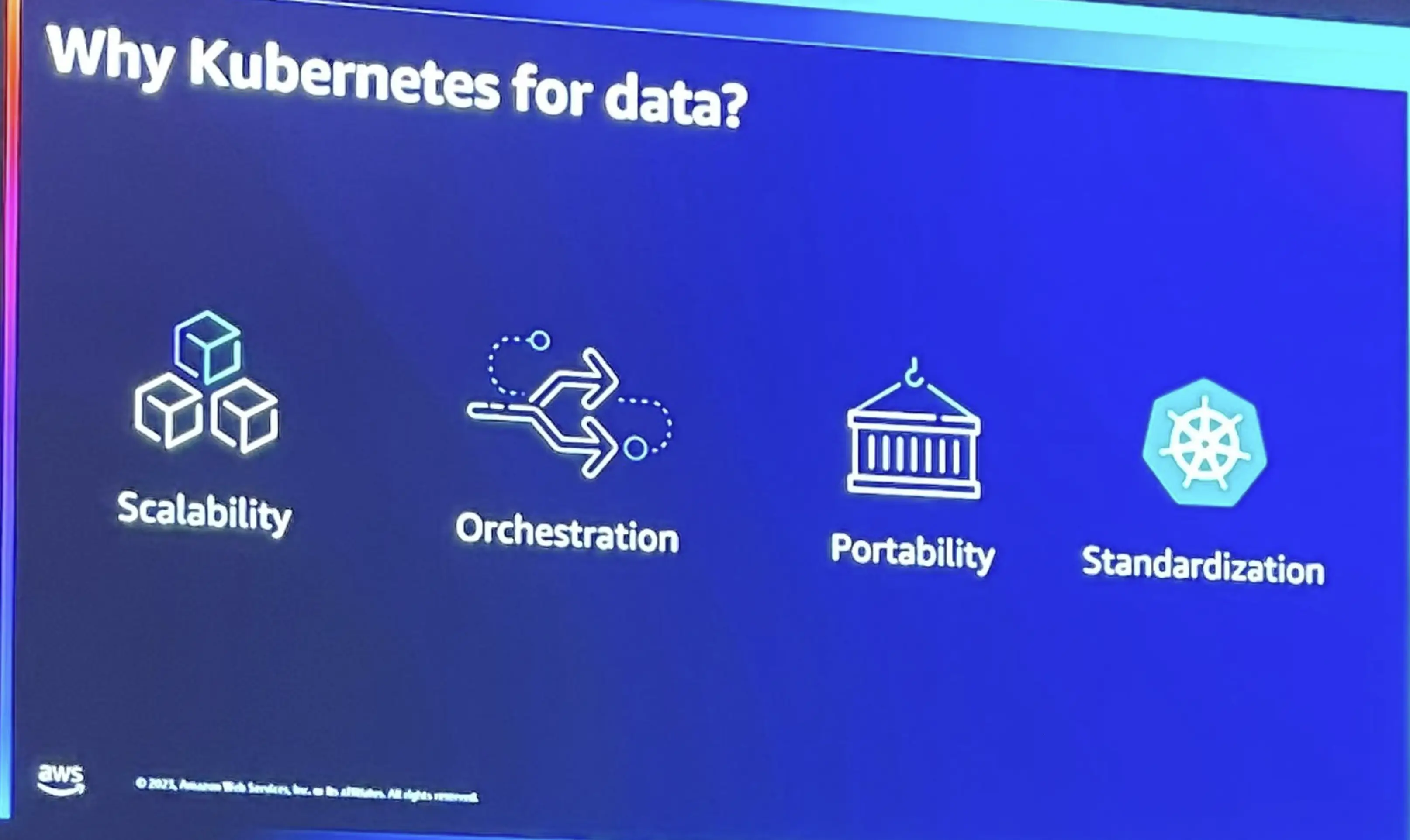
Kubernetes が提供するマイクロサービスアーキテクチャは、一時的なコンテナを使用し、最新ではなくなったり破損したコンテナは、自動的に新しいコンテナーを使用していきます。これは、サービスの可用性を維持します。また、ワークフローを作成して、コンテナー管理を簡素化し、データサイエンスであれば、実験ごとに専用のワークフローを作成する場合にも非常に役立ちます。また、Spark における 次のバージョンのすべてのジョブは非常に面倒なプロセスになるため、移植性によりある程度の柔軟性が得られます。
AWS では、多くの企業が Kubernetes を大規模に採用しているのを目にしています。kubernetes のデフォルトのコンピューティングで標準化を行っています。
Data on EKS(DoEKS) Project
この中で登場したのが、Data on EKS (DoEKS) コミュニティです。
https://awslabs.github.io/data-on-eks/
https://github.com/awslabs/data-on-eks

DoEKS で使用するオープンソース ツールは、 Terraform Blueprint が提供されており、Amazon EKS へ簡単にデプロイをします。
OSS data platforms on Amazon EKS
DoEKS は多くのオープンソースのデータツールに対して機能をカバーし、テクノロジ―を使用していると言います。
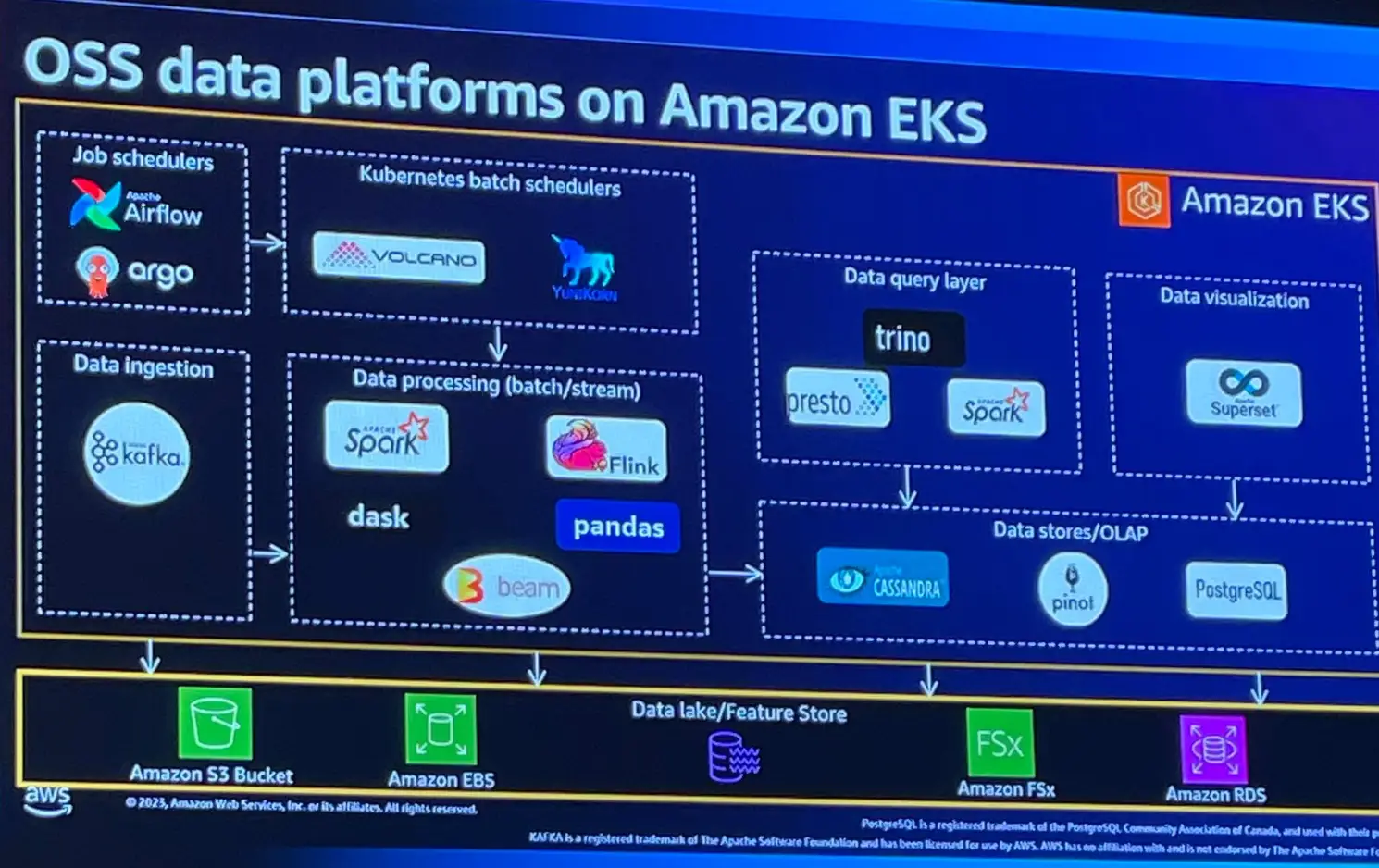
以下で公開されている情報は、DoEKS でカバーされるオープンソース データ ツール、Kubernetes オペレーター、フレームワークと、AWS Data Analytics マネージド サービスの統合を示しています。
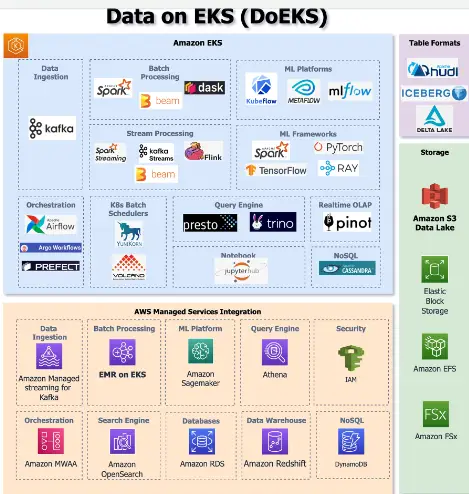
このうち、Apache Spark フレームワークについて言及をしています。
Spark 2.3 以降 Kubernetes をネイティブサポートし、事前に spark 用Pod を準備せず実行が可能となっています。

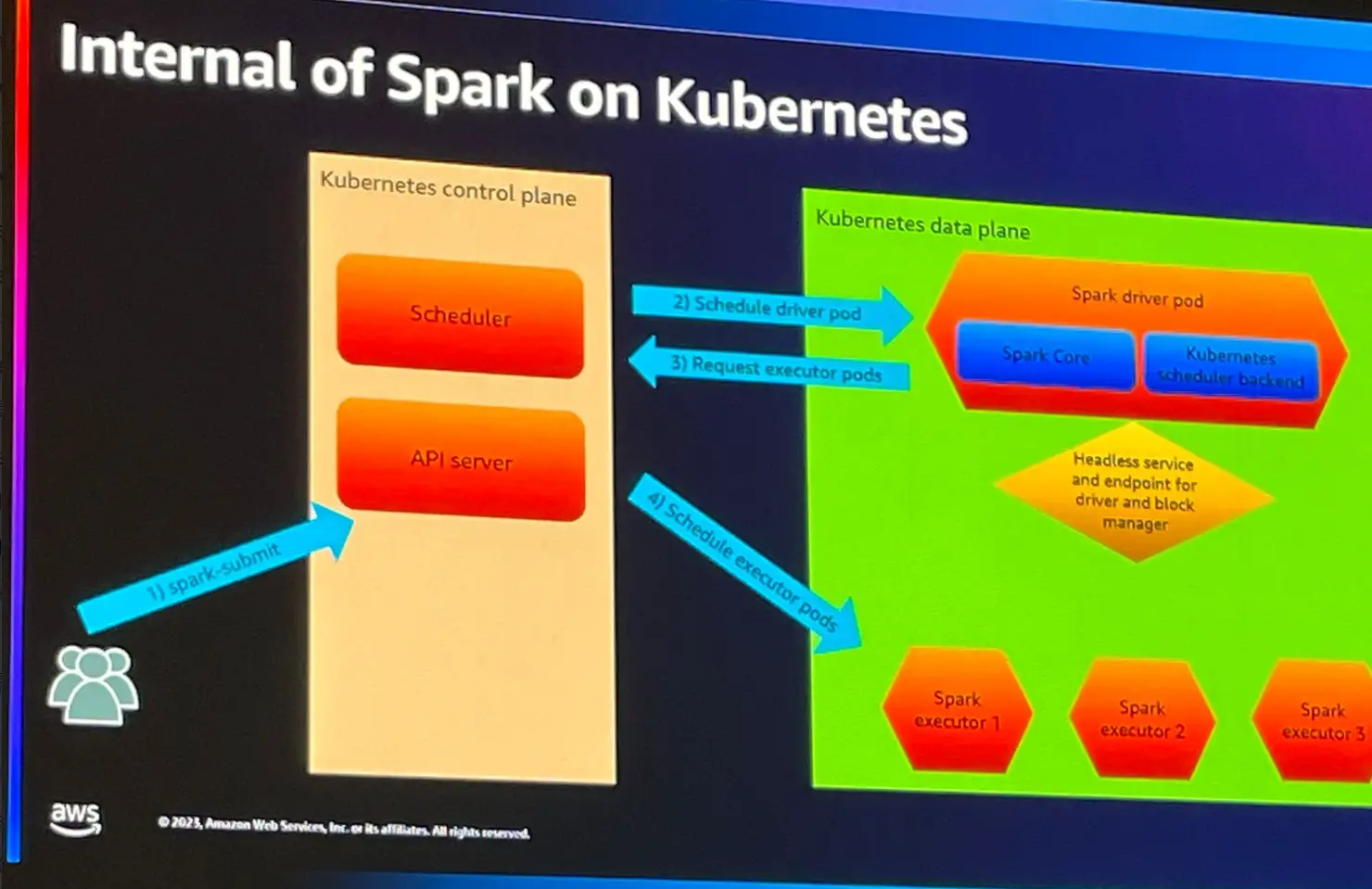
1. Spark Submit コマンドにより実行を行います。
2. Spark Driver 用のPod が Kubernetes 上へデプロイされます。
3.Spark Driver は、Executorに必要なPod を返します。
4. SparkDriverが指定された数のExecutorのPodをスケジュールデプロイし、計算が実行されます
参考情報: https://spark.apache.org/docs/latest/running-on-kubernetes.html
Pinterest’s data modernization journey
続いて Piterest による事例の紹介がありました。

Pinterest が行っているデータ変換の概要が以下に示されています。このうち、バッチ変換処理では Hadoop クラスターを大規模なノード数を使用していると言います。
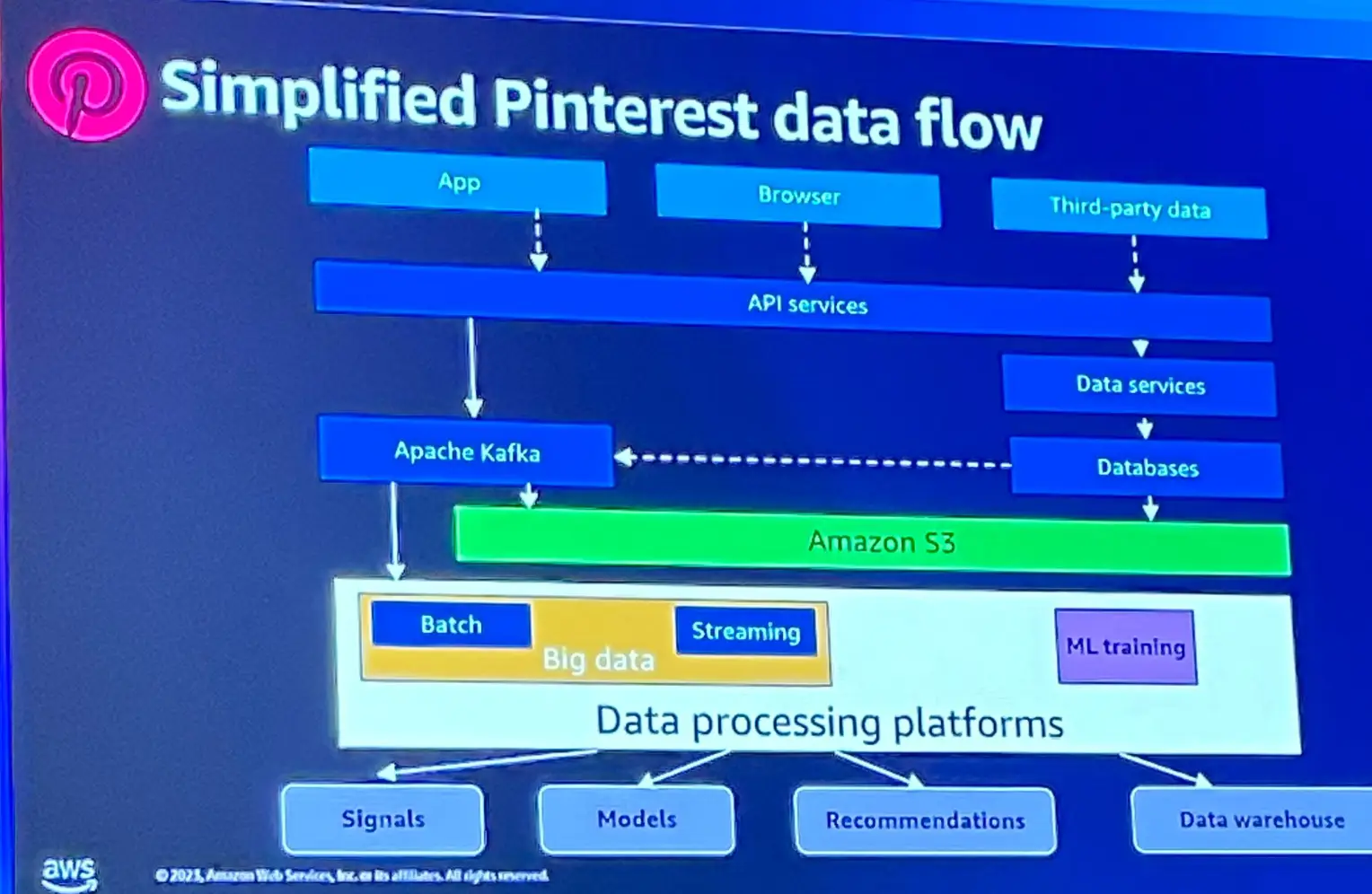
Hadoop は確立されたサービスですが、古くなっているサービスを更にクラウドネイティブに移行し、更に機敏なものへ移行したいと考えたと言います。

移行後の EKS プラットフォームを Moka と呼び、大規模なデータ処理を行う事は、多くの周辺サービスを構築する必要性を示唆していると言います。
Spinner と呼ばれる Airflow ベースに実装されたDAGの定義情報を Archer が EKS クラスターへ送信し、EKS クラスター内部では、Apache Yunicorn をスケジューラとして使用しています。スケジュールされたジョブを実行する際に ECR からイメージを取得しています。このほかにも、Jupyter や Spark SQL UIなど多くの機能を提供するために取り組んでいると言います。
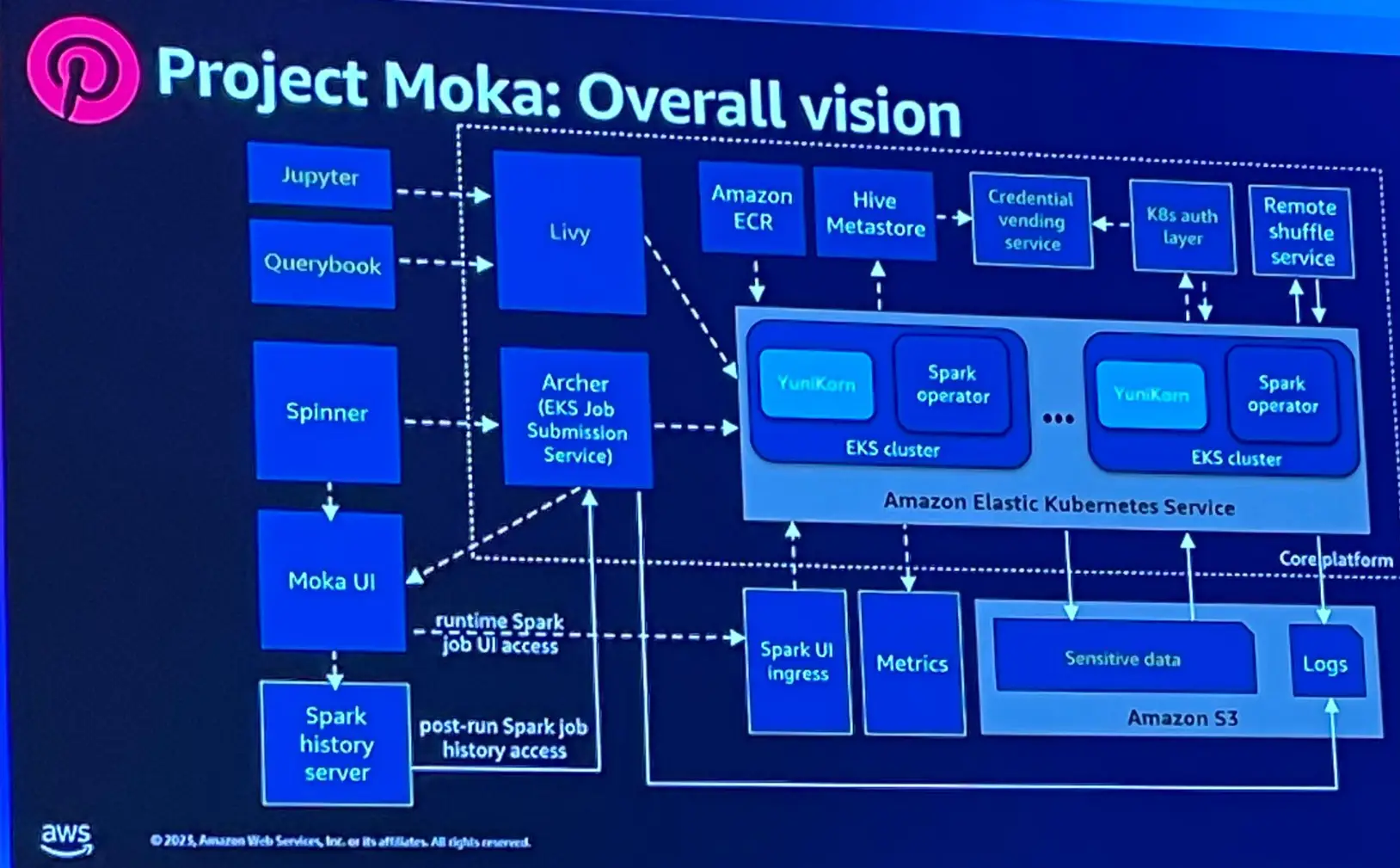
 このプロジェクトで得た成果について述べていました。
このプロジェクトで得た成果について述べていました。
1つは、Graviton への移行へ成功し、大幅なコスト削減をしたこと、そしてオープンソースコンポーネント OTEL や Fluent bit などを組み合わせて互換性の問題なくアクセスする事が出来るという事にあったと言います。また、DoEKS / EKS blueprint の活用についてもここで成果として述べられていました。

Best practices for Apache Spark at scale
最後にApache Spark をEKS で実行するときのベストプラクティスについての説明がありました。
一つ目がCIDR の検討事項です。プラットフォームの担当者は、EKS がどこまで ip を利用するか不明なため、割り当てられた ip が不足しジョブが実行できない問題が発生する事があります。Amazon VPC CNI により、ENI に、セカンダリIP を割り当ててPod と関連付ける事で セカンダリ CIDR を活用する事が出来ると言います。
参考情報: https://docs.aws.amazon.com/eks/latest/userguide/cni-custom-network.html

DNS の問題として、Core DNS の不明なホスト例外が挙げられています。
これを回避するためには、Core DNS Pod の水平スケーリングと、ノードローカルDNS キャッシュの利用が挙げられています。CoreDNS は、デプロイされたノード数に関係なく 2 つのレプリカがデプロイされます。但し、実行するノード数が増える事で2つでは処理仕切れないケースがあるため、起動しているノードに応じて Core DNS のPod をスケーリングする事を推奨しています。ノードローカルDNS キャッシュは、各ノード上でDNSキャッシュを提供し、クエリのレスポンスをノード内でキャッシュすることで、クラスタ内のDNSクエリの応答時間を短縮する kubernetes の機能であり、これの利用を推奨しています。

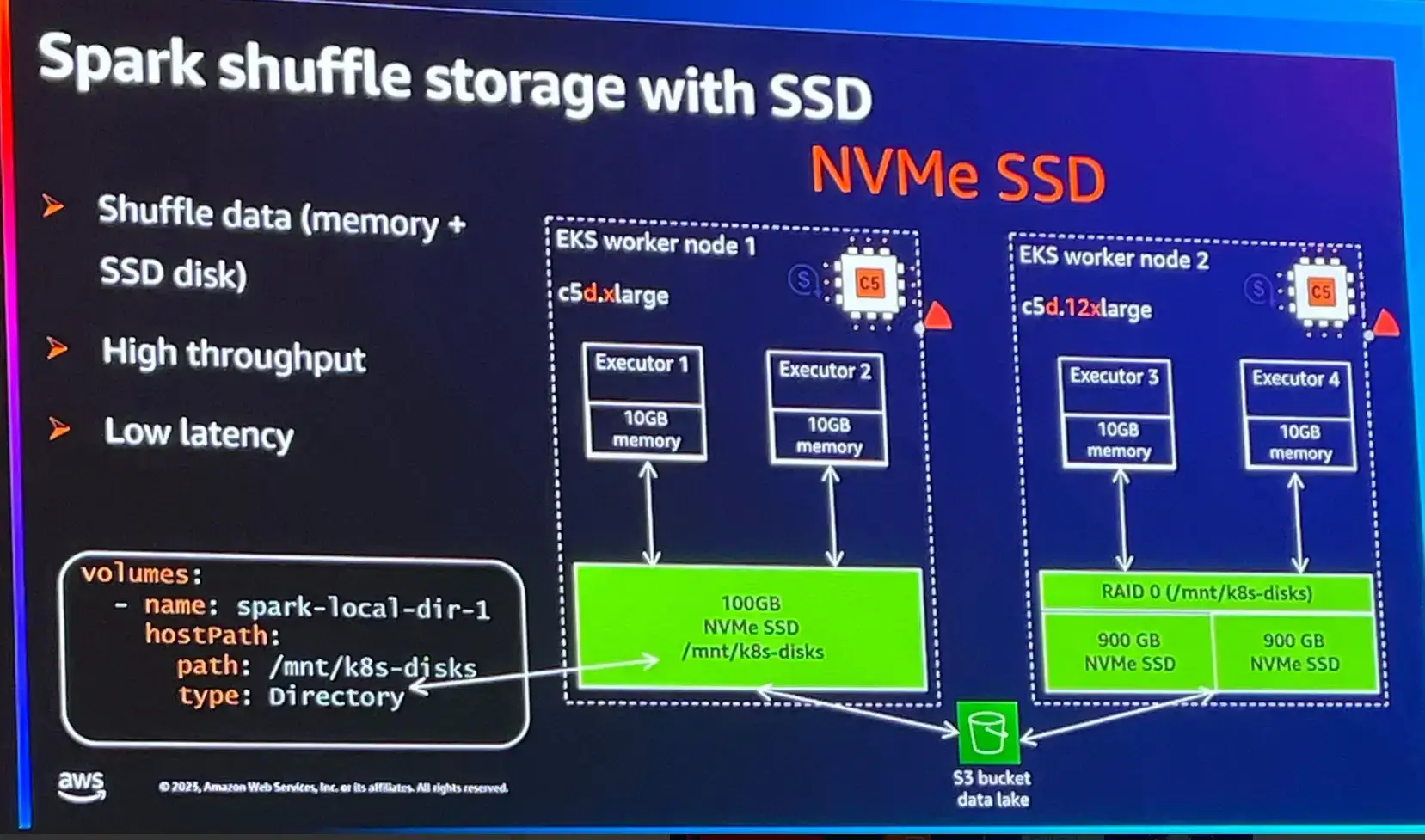
Spark を EKS 上で実行する場合、 NVMe SSD ベースのインスタンスの使用が推奨されます。
各インスタンスで使用可能なディスクに対して1つのマウントパス(特定のストレージ)が提供される事です。
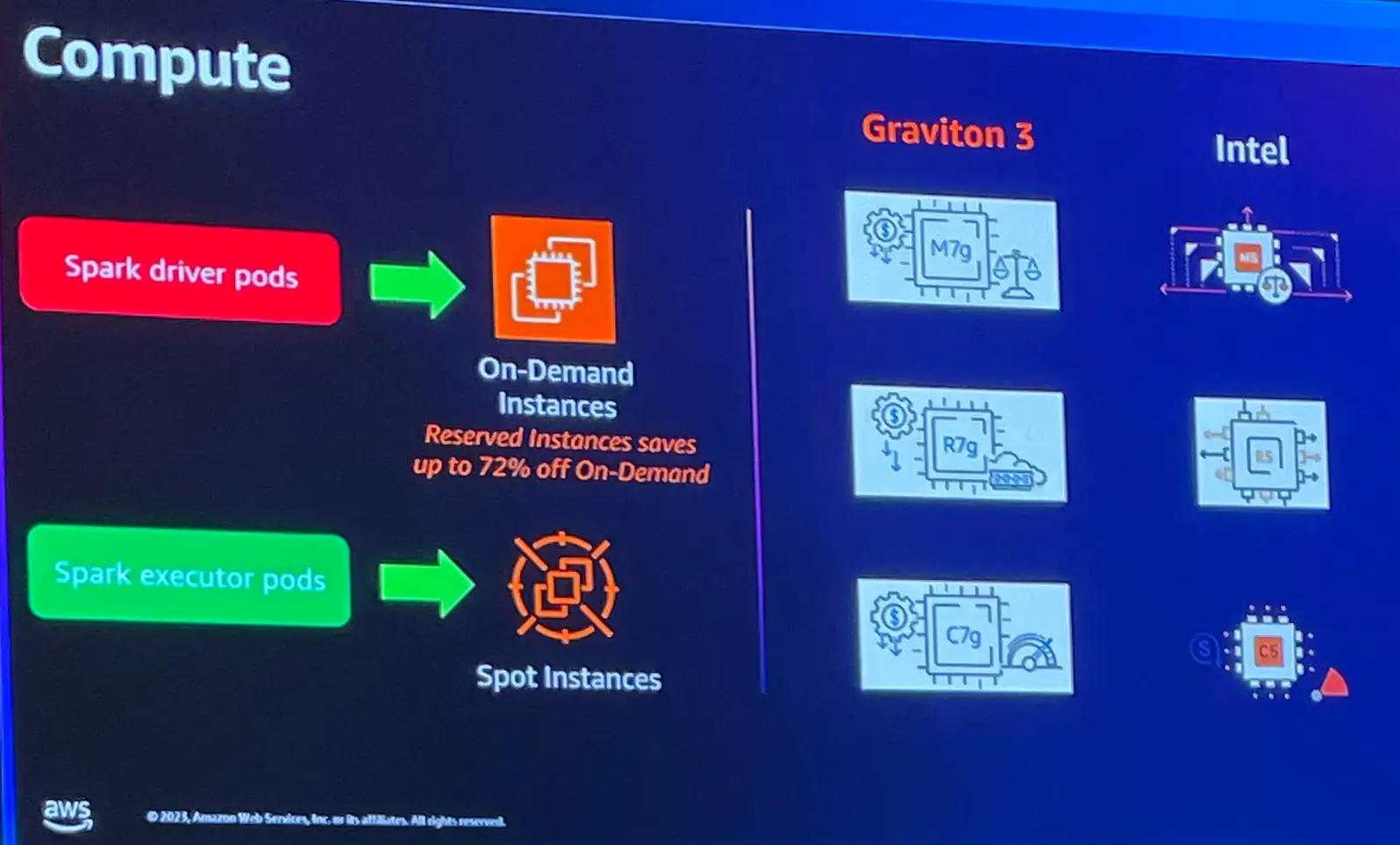
Spark driver は強制終了されると、ジョブ全体が削除されます。従って、オンデマンドインスタンス上で実行する事が推奨されます。Executor は、Spot インスタンスを使用しスケールアップ・スケールダウンを実現します。また、コンピューティングについては Graviton 3を推奨しています。
Karpenter は、Auto Scaling グループや Cluster Autoscaler を必要とせず、EKS へインストールしている事で、Pod を監視し、ジョブが終了すると自動でスケールダウンを機能を持ちます。
これらを NodePool 内にマニュフェストとして定義するだけで、インスタンス部分をオンデマンドで定義する事が出来るとのことです。EKS 上の spark はこれらによりスケーリングのコスト削減を見込めることが出来るため推奨していると言います。


Kubernetes にはデフォルトのバッチスケジューラーが付与されていますが、スケジューラーには Apache Yunikorn / Volcano の使用が推奨されています。
このうち、Gang Scheduling の機能は、非常に優れており、pod 単位のスケジュールではなく、アプリケーションとしてデプロイされる機能を持ち、Spark のようにドライバーの作成、エグゼキューターの要求という段階プロセスが要求されるジョブ実行には有効であると言います。

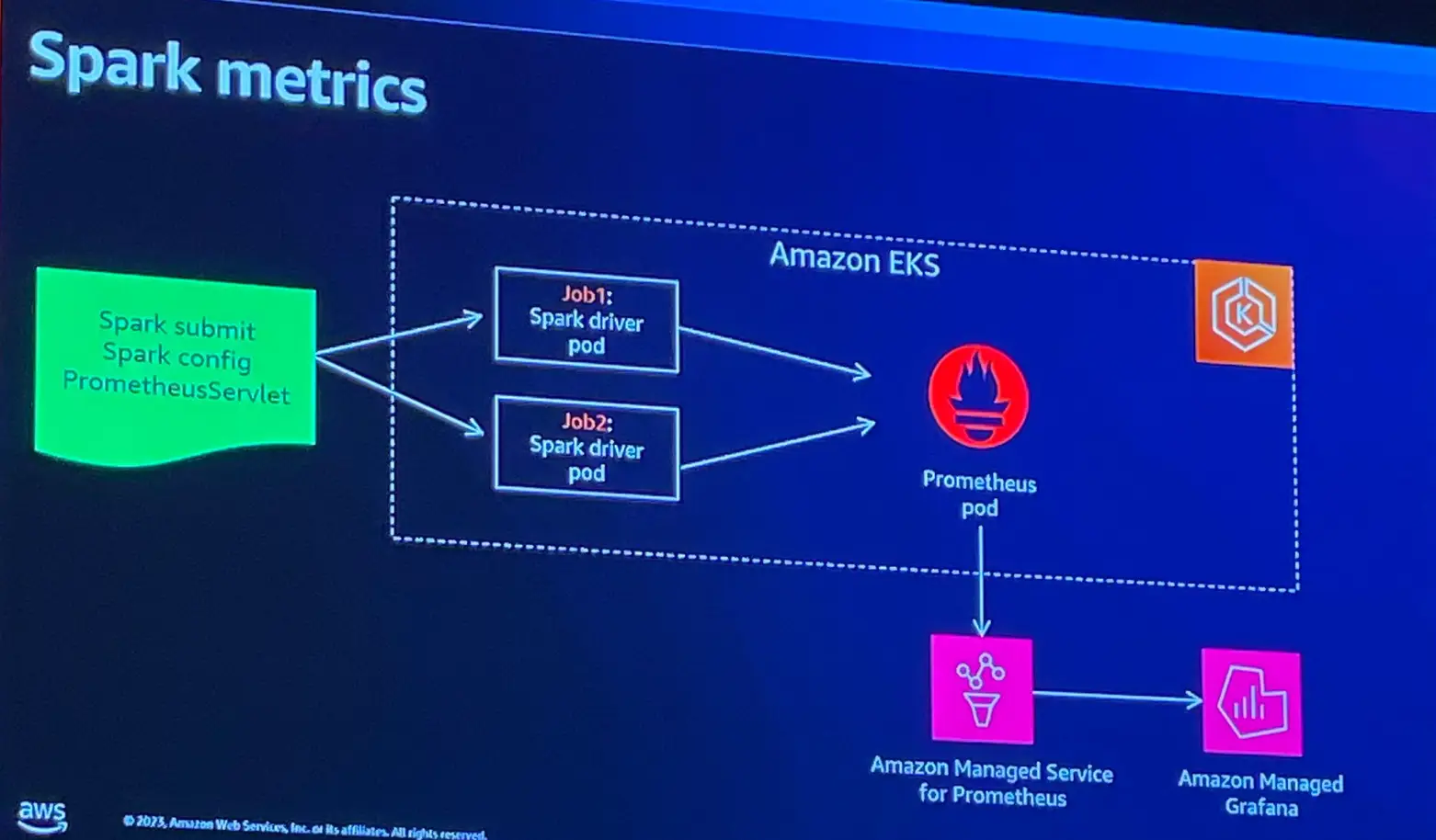
続いて metrics 監視です。Kubernetes 上で spark ジョブを監視するには、メトリクスの保存と書き込みを Prometheus で行い、Grafana によりメトリクスを視覚化する事を推奨しています。ノードリソースの使用率のみならず、更に詳細なレベルのメトリクスの取得が可能であると言います。なお、これらは、いずれも AWS マネジドサービス として展開されているため、いずれもの利用を推奨するとのことです。
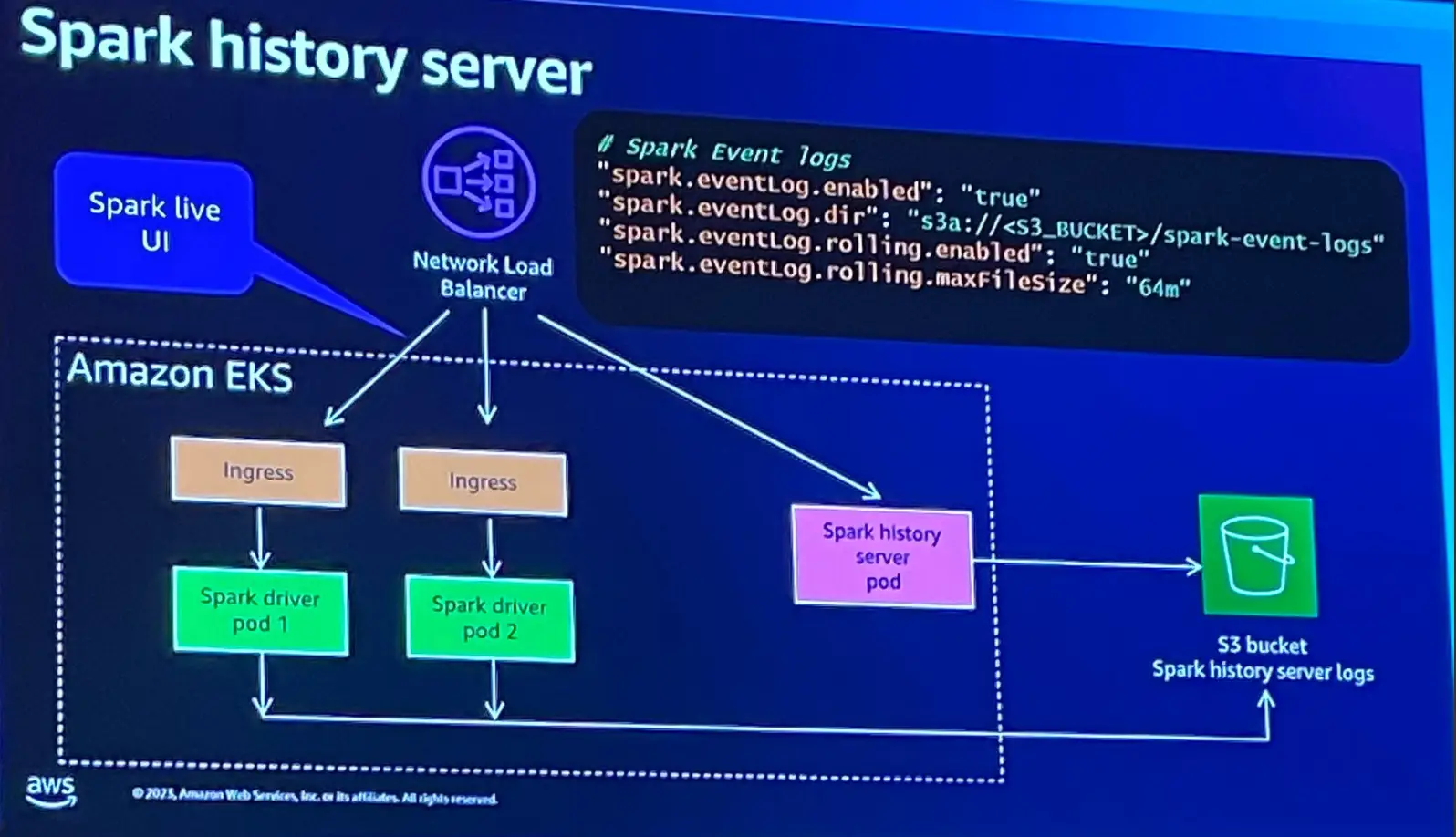
続いて Spark History Server (WebUI) についてです。Spark ジョブの実行履歴を視覚化する機能は、Blue Print のオプションを使用し、イベントログをS3バケットへ書き込み出来る様にすることで、履歴メトリクスとライブメトリクスの視覚化が行えると言います。
また、Spark ログの抽出には Fluent bit を使用し、フィルターを使用する事を推奨しているようです。
Best Practice については以上となります。
最後に、DoEKS についての紹介がありました。

以上となります。
最後まで閲覧頂きありがとうございました。
- カテゴリー

この記事をシェアする

![[re:Invent 2023 レポート] Platform engineering with Amazon EKS](/media/QNVy79WE7NMY0dHNto1OhQTZHvqMMJFdtfHzTkFo.png)
![[re:Invent 2023 レポート] Expert 400 Session - Break down data silos using realtime synchronization with Flink CDC (Problem and Architecture)](/media/cEgRjcxTrlxSmwt9w64QDztKEal3sVblaQuB54QD.png)



