











![[re:Invent 2023 レポート] Expert 400 Session - Break down data silos using realtime synchronization with Flink CDC (Problem and Architecture)](/media/cEgRjcxTrlxSmwt9w64QDztKEal3sVblaQuB54QD.png)
目次
Introduction
AWS Re:Invent の中で参加した Break down data silos using realtime synchronization with Flink CDC セッションの振り返りをレポート形式で投稿します。
今回は Data Engineer 、Developer 向け、Break down data silos using realtime synchronization with Flink CDC と題した Apache Flink のセッションに対するレポートとなります。

Description
Having multiple data silos causes data to be in different sources across the organization, which can make it difficult to perform analytics and democratize access to your data. To be able to bring all of your data into one place, you may need to set up different streams, batch jobs, or additional CDC components, which can add complexity to your architecture. In this session, explore how, by just using Flink CDC on AWS, you can simplify real-time synchronization and ingestion across transactional DBs and finally break down data silos.
複数のデータサイロがあると、組織全体でデータが異なるソースに存在することになり、アナリティクスの実行やデータへのアクセスの民主化が困難になります。すべてのデータを一箇所に集めるには、異なるストリーム、バッチジョブ、または追加のCDCコンポーネントをセットアップする必要があり、アーキテクチャが複雑になる可能性があります。本セッションでは、AWS上のFlink CDCを使用するだけで、トランザクションDB間のリアルタイム同期と取り込みを簡素化し、最終的にデータのサイロ化を解消する方法を探ります。
Agenda
セッションの流れは以下となります。

Data Integration challenges
最初に課題の定義から入ります。
データに基づく意思決定のプロセスでは、Enterprise data warehouse が中心となり、いくつものソースデータをData Warehouse へ投入し、これをBI へ供給するものとなっていました。
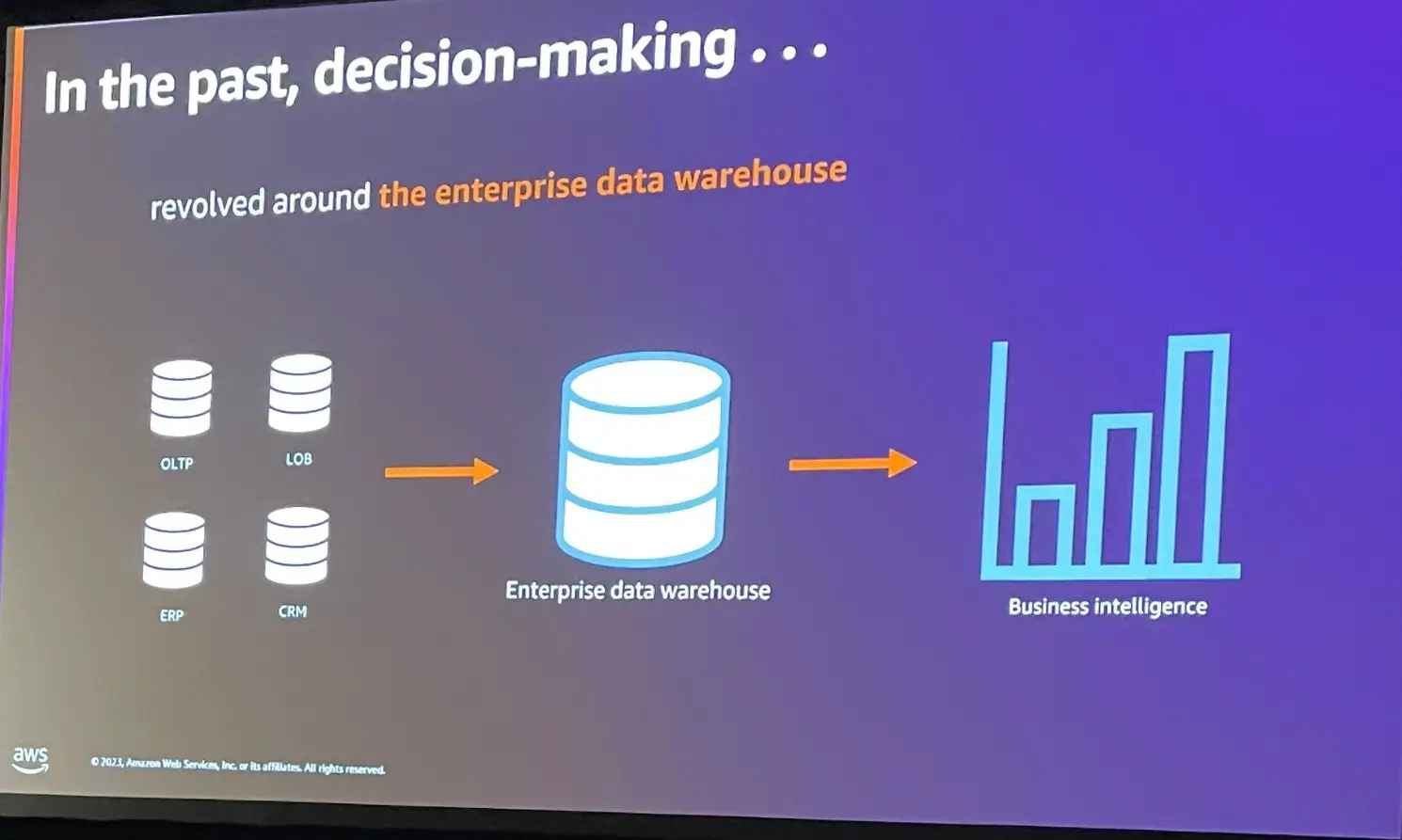
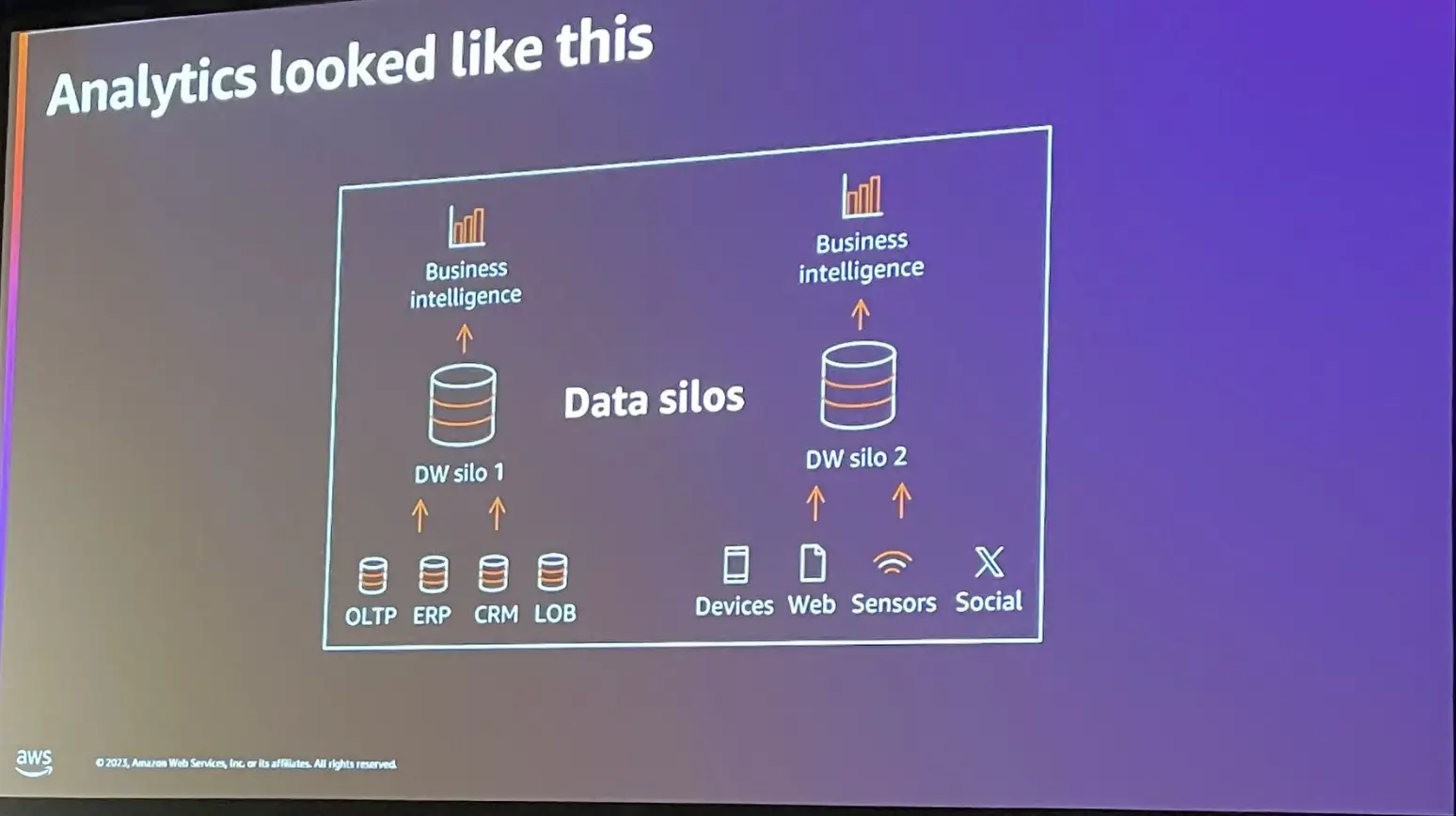
データサイロが企業毎に肥大化すると、データウェアハウスを追加導入し、既存のものとは異なる BI のダッシュボードを作成し、ここから最適な情報を見つけ出す必要があります。データサイロが増大する問題は、システムのコストやソリューションを、より高価なものにし、管理が複雑化する事によって組織全体の俊敏性を損失する事となり、結果的に SLA に準拠しない問題が生じると言います。
一方で、企業が保有するデータは、近年急激な増加傾向にあり、意思決定者は、以前よりも迅速で適切な分析を必要としています。

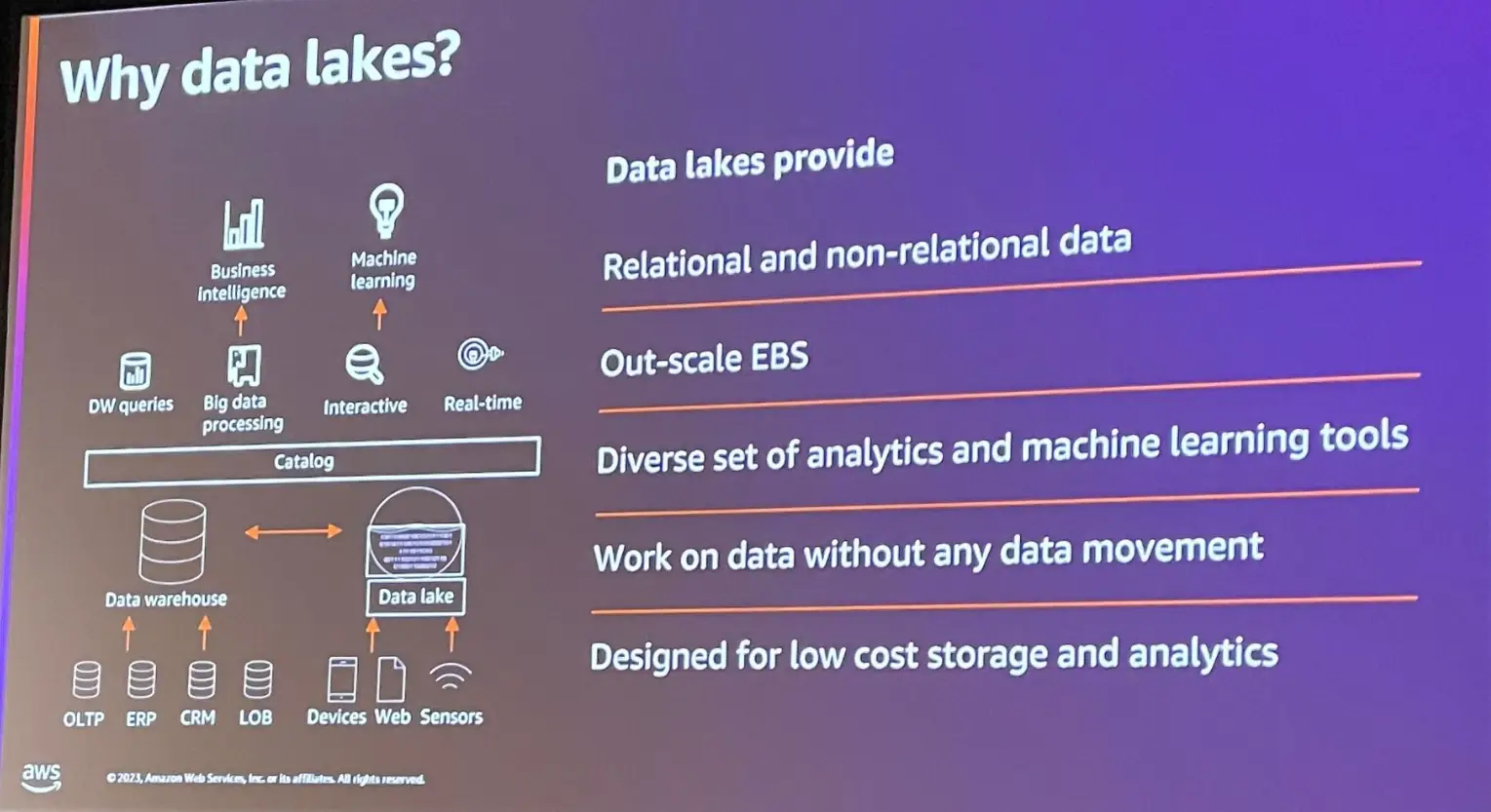
これらを解消するために、以前の Data Warehouse を中心としたアーキテクチャ、意思決定のプロセスは、データレイクハウスアーキテクチャへと進化を遂げてきました。
データレイクハウスアーキテクチャは、機械学習、BI、分析、データウェアハウジングなどの多くのソリューションを統合的なものとする結果となりました。
データレイクアーキテクチャは、大量のデータをコスト効率よく保存し、耐久性や信頼性が高いものとします。特徴として、リレーショナルデータ、非リレーショナルデータ関係なくデータを保存し、基盤となるストレージに沿って自動でスケールが可能、機械学習やストリーム、分析など多くのユースケースに適用する事が出来ます。また、AWSでは Apache Spark や Amazon Athena クエリエンジンのサポートによりデータを移動する事なく分析が可能となります。
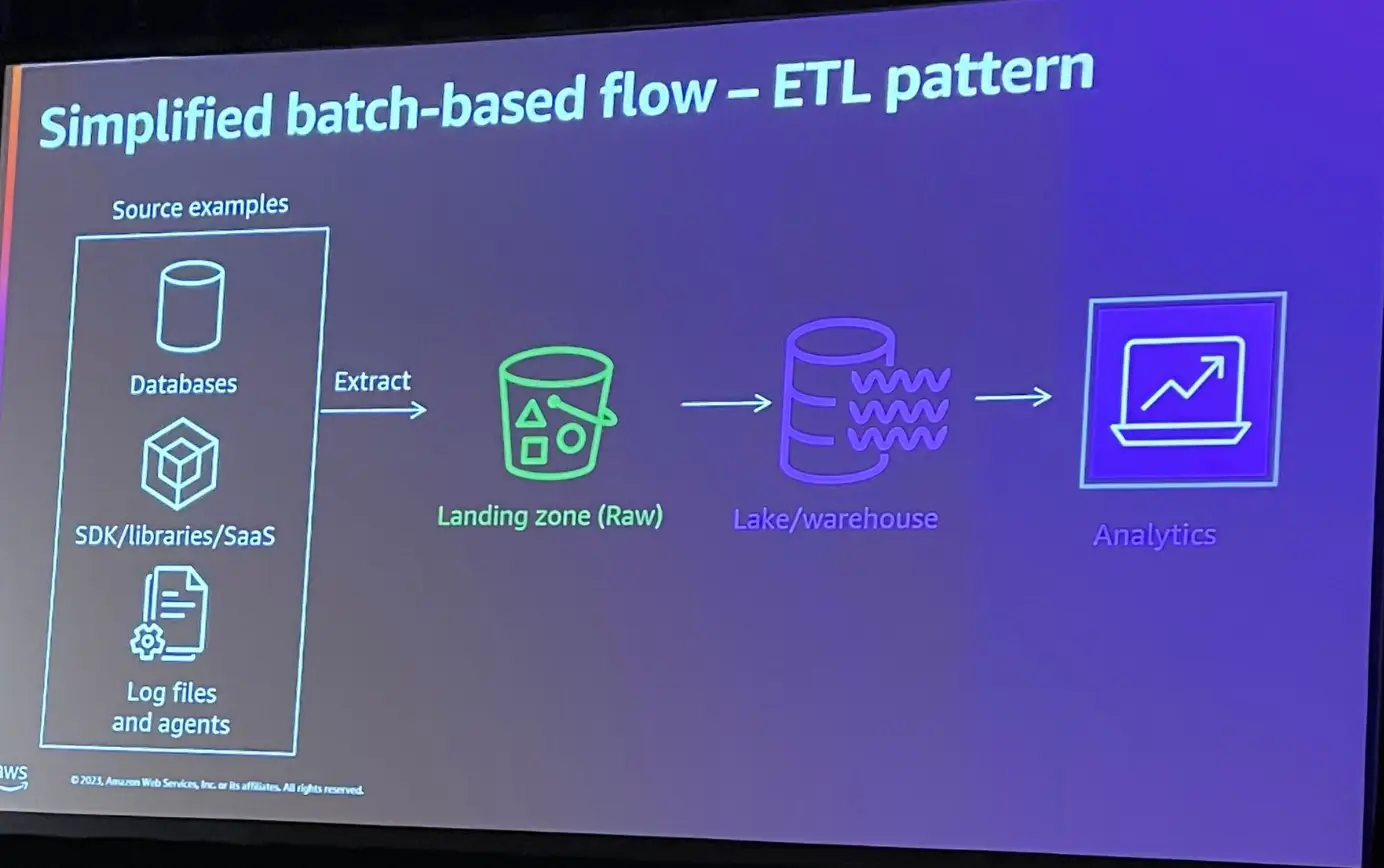
データレイクハウスアーキテクチャを作る場合に、ソースのデータを抽出するプロセスが必要となります。
このプロセスの多くのケースでは、スナップショットを取得するバッチ形式であり、ソースから大量なデータを移動し、ローデータとしてファイルに移動する必要があります。この後にもスケジュールされたバッチがあり、データの変換処理を行います。また、データウェアハウスやビジネスインテリジェンスアプリケーションがある場合、これらエンジンがサポートする形式のデータを提供する必要があります。このようなプロセスには2つの問題があると言及しています。
1つ目は、各プロセスは完了を待つ必要があり、これらには待ち時間が発生します。
2つ目は直列なプロセスであるという事です、先述したプロセスは常に1つのジョブを実行する必要があり、それ以外のプロセスでは待機時間を要するという事です。
これら問題点は、共通して時間に寄与する形でデータの価値を損失させる結果をもたらす事となると言います。
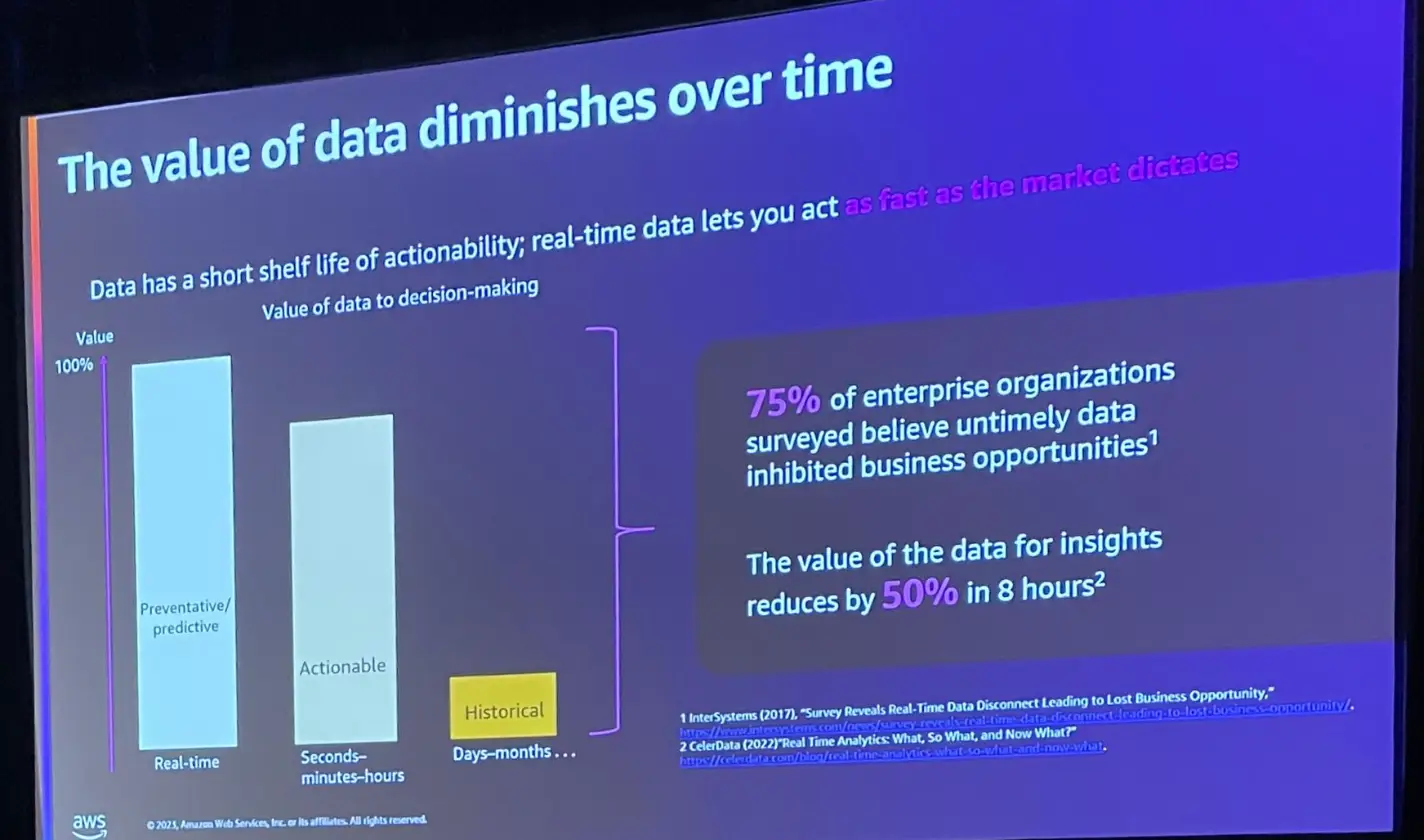
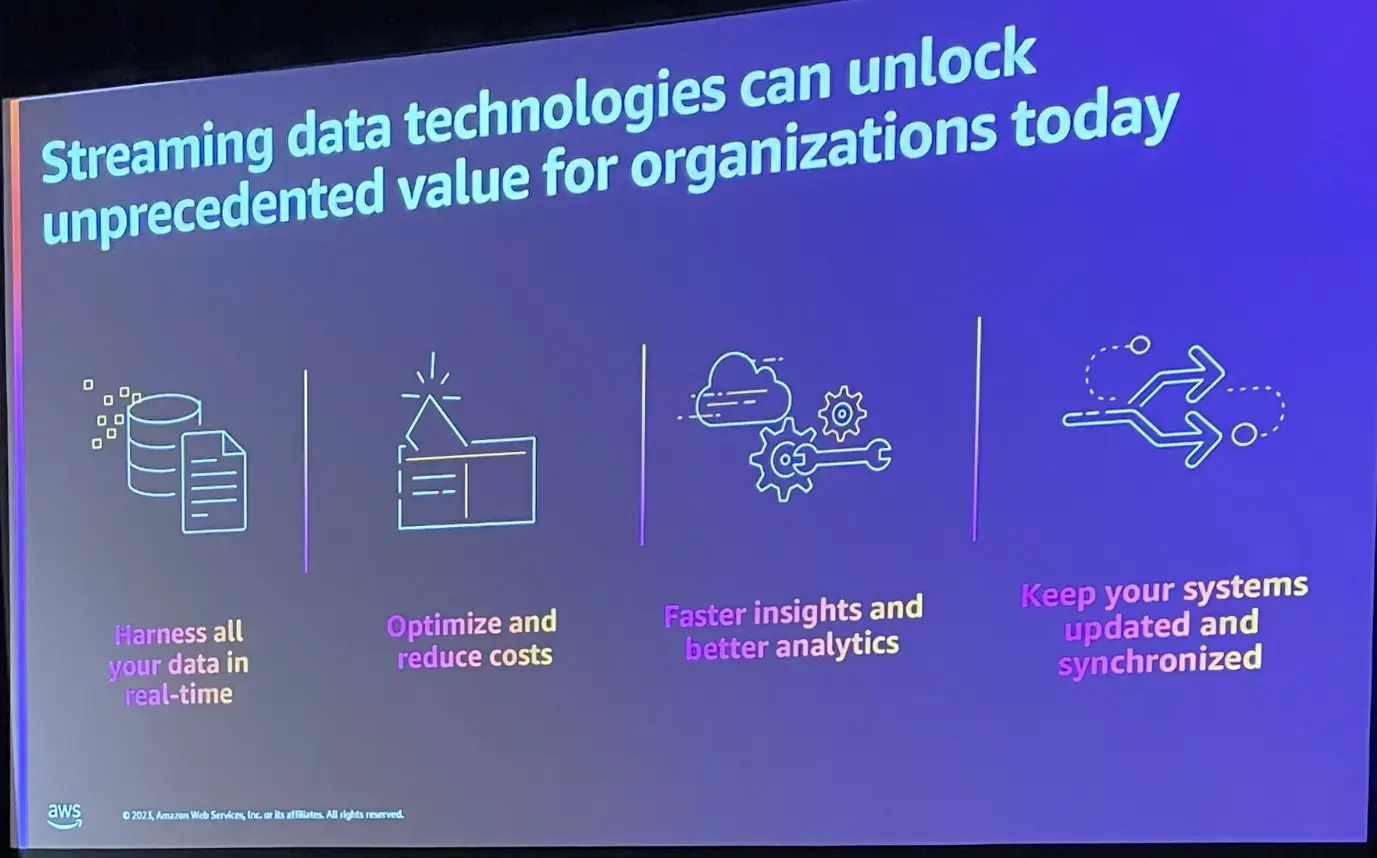
Streaming Data Technology
ストリーミングデータテクノロジーは、先述した問題を解消します。全てのデータをリアルタイムに利用できるようになり、変化するデータのみを処理する事によってプロセスのコストを最適化します。
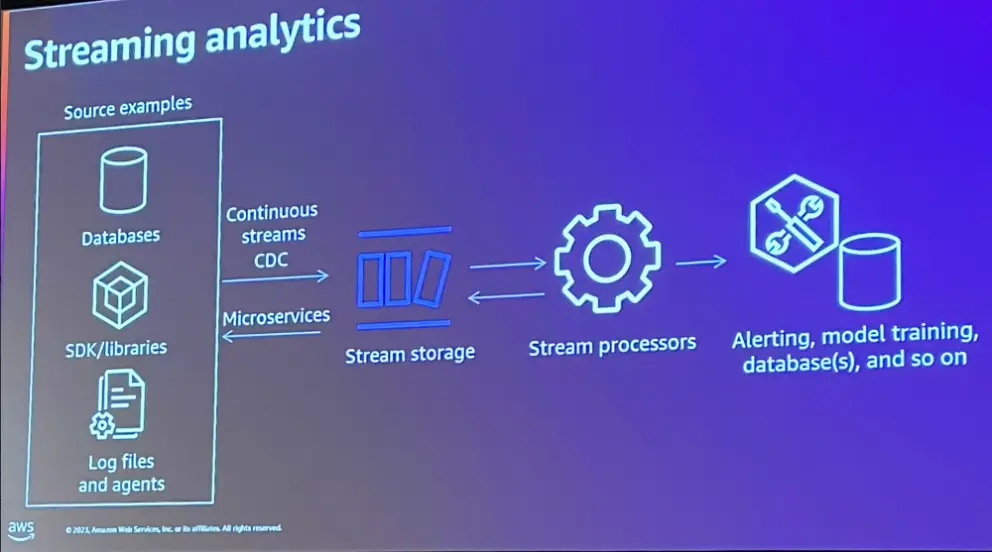
ストリーミングのアーキテクチャは先述のバッチプロセスとは対照的であり、データの変更のみをキャプチャします。このプロセスは CDC (Change Data Capture) と呼ばれます。
CDC プロセスは、データイベントを生成し、CDC データを生成していきます。このデータには、削除、変更、追加など、イベントが発生した情報を含んでいます。これらは Apache Kafka 、Amazon MSK 、Amazon Kinesis などのストリーミングストレージを使用してデータが保存され、ストリームプロセッサへフィードするために機能します。
その後、システムのデータベースやデータウェアハウスなどへストリーミングデータを送信するものとなります。また、ストリームプロセッサの出力を受け取るためにストリーミングストレージをサブスクライブするマイクロサービスを持たせる事も可能となります。
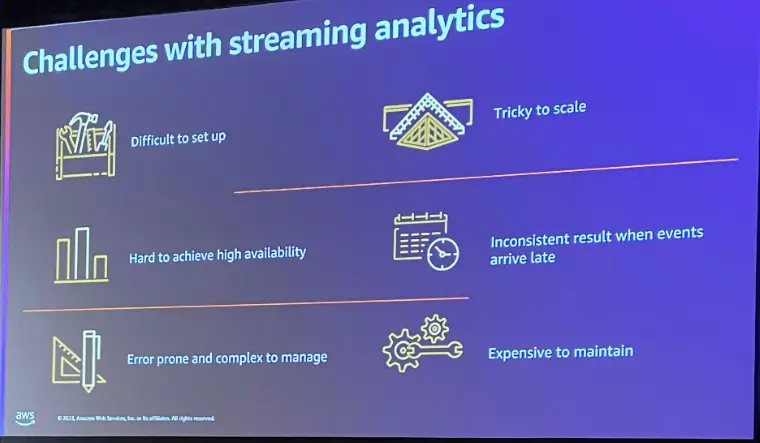
上述のストリーミングアプリケーションは、構築やセットアップが非常に難しいものであるという事がよく挙げられます。プロセスは基本的にステートフルであり、プロセッサのワーカーに障害が発生した際のシナリオ(可用性)を考慮する必要があります。
Apache Flink for streaming analytics
Apache Flink はオープンソースであり、イベント駆動型のアプリケーションとなります。先述のストリームアプリケーションが抱える問題を解決するとともに、バッチモードでの実行も可能にします。
Apache Flink は、コードレベルで記述できる API を提供しており、SQL クエリの記述のみでイベントに集計、変換処理を実装する事が可能です。また、水平方向へのスケーリングを行うように作られており、スループットに応じてスケールアウト出来ます。


Apache Flink は、Apache Kafka 、Amazon MSK などのストリーミングストレージに接続し、データを読み取る事が出来ます。また、RabbitMQ などのメッセージキューサービスや Apache Nifi などのデータフローとの接続もサポートしています。
そして、Flink は分散ファイルシステムの Hadoop の HDFS 、Amazon S3、データベースのApache Cassandra 、メッセージングの Apache Kafka などにデータを書き込む事が出来ます。
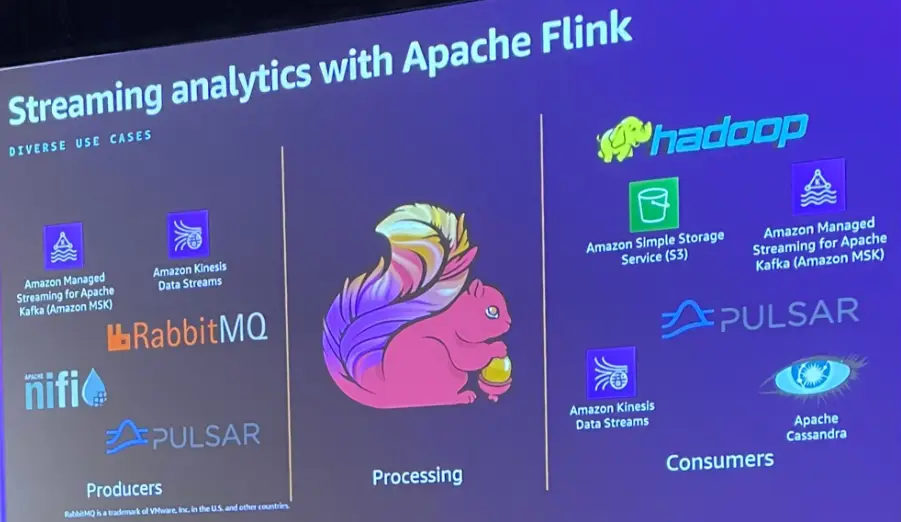
Flink オープンソースを EC2 や EKS 上で使用する場合、スケラビリティの管理や、ジョブの監視が必要になります。Amazon Managed Service for Apache flink はジョブで自動スケーリングを設定する事で、アプリケーションを継続的に実行し、自動でスケーリングします。また、開発環境となる Apache Flink Studio と呼ばれる Zeppelin ノートブック形式で提供されるサービスを使用し、インタラクティブにストリーミングデータを操作し、ノートブックをデプロイするだけで完了します。
このサービスは Apache Flink チェックポイントの作成とスナップショットを取得し、バックアップを確実に作成する事が出来ます。
そして、先ほど述べた Flink API を使用する事が可能で、SQL 、Java 、Python 、Scala からこのサービスを利用する事が出来ます。

Apache Flink for breakin data silos
ここから、テーマとなるデータサイロは打破する方法について触れていきます。
Flink CDC Connector は、Apache Flink のソースコネクタであり、データベースに対して直接接続が可能です。スナップショットの移行を実行したり、トランザクションデータをデータストアに転送したり、書き戻しが出来ます。Debezium コネクタ等のCDCのオープンソースは、Apache Kafka などへデータを取り込む必要がありますが、Flink API では、Datastream API 、SQL、Java を使用して Flink CDCを機能する事が出来ます。
現在、MySQL 、MongoDB、PostgreSQL、SQL Server、Oracle データベースがFlink CDCをサポートしています。

また、Apache Flink は内部で CDC を Dynamic Table という Materialized View を使用して、イベントおよびレコードを管理しています。
実際の動きをみていきます。Flink CDC は ソースデータを Table API を使用してクエリや変換処理によって加工し、結果をストリームへ送信します。
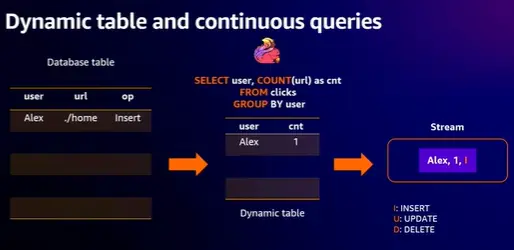
Flink の Dynamic Table の動作挙動は、一般的に以下の動きをします。
- Stream (Source Data) が Dynamic Table に変換されます。
- Continuous query は Dynamic Tableで評価され、新しい Dynamic Table が生成されます。
- クエリの結果として得られる Dynamic Tableは、Stream に再度変換されます。
この例ではWeb URLをクリックしたデータを取得しているソースデータから Dynamic Table を使用し、データを取得し、 Apache Flink アプリケーション内で継続的なクエリが実行され、オペレーターに出力されます。いわば変更データをソースデータベースから直接取り込み続けながら、Dynamic Table 上で追加、変更を行い、レコードをストリームとして送信する挙動を説明しています。
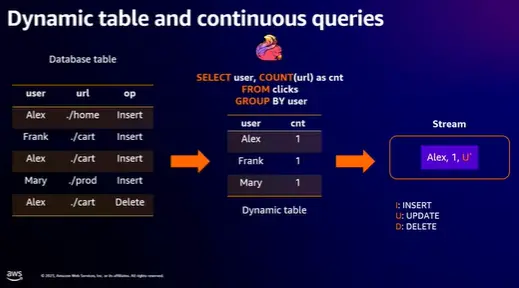
ただし、Dynamic Table が Flink アプリケーションで内部的に変更されているにも関わらず、ここで集約されたイベントが全てストリームへ送信される場合に問題があります。
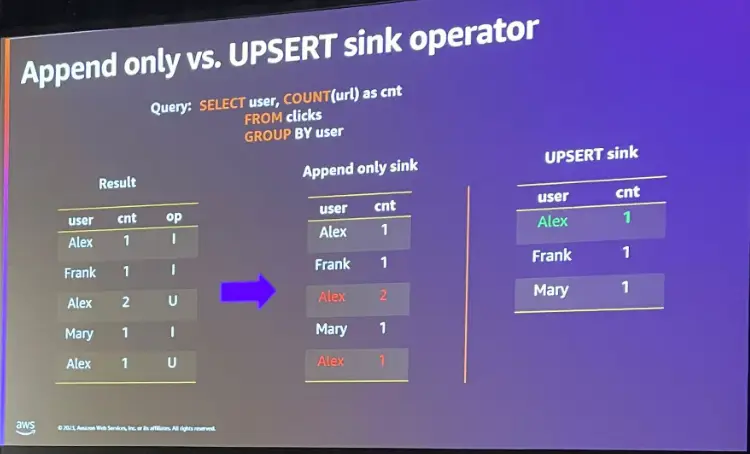
CDCデータは、ソースから取得したストリームデータの宛先となる Sink を決める必要があります。下記の図における Result はソースから取得したストリームの結果ですが、Append Only Sink のケースでは本来含まれてはならないデータが入ります。
本来は 主キーに基づく upsert sink が必要となります。これにより Flink CDC Connector とクエリによって Dynamic Table が Flink アプリケーションで行った結果と同じデータを得る事が出来ます。
Transaction Data Lake
先ほどの例から学んだように、CDC データの書き込みには、upsert が実行可能な Sink 、冪等なデータシンクを使用する必要があります。しかし、冒頭にあったデータレイクを活用する場合、S3 に対して、Upsert と Delete の実行が行える機能が必要になります。

後述の Open Table Format はこの問題を4つの観点から解決します。
- データをストリーミングする際に、Snapshot Isolation が可能であること。
- 主キーが利用できるため、CDC に適合していること、upsert が利用できること。
- リアルタイムの同期を実現するために、小さい大量ファイルの問題に対処する必要があり、このケースはクエリ処理が最適ではなく、テーブルフォーマットを利用する事で同期圧縮やストリームとは別のジョブを実行する事で圧縮する事が出来る。
- プライバシーの規制に準拠する場合、upsert / delete が利用できるテーブルフォーマットにより、データの一貫性を維持する事が出来る。

最新のデータレイクでは、Open Table format が使用されます。Apache Hudi 、Apache Iceberg 、Delta Lake は flink との接続をサポートします。そして、これらのフレームワークは Flink の問題であった課題を解決できます。また、次に活用が出来るのは、これらの Open Table format を使用して S3 に対して書き込みが可能な Apache Flink コネクタ(直接統合)です。


これらを元に、AWS上のユースケースを見ていきます。
このケースでは簡素化を行うため、ソースデータをRDS for Mysql とし、Amazon Managed Service for Apache Flink を使用します。Flink CDC Connector によりテーブルからデータを利用する事が出来ます。これは最初からデータを取得していくかトランザクションログからデータを取得するかを指定し、Flink ジョブ の開始以降の最後の変更をキャプチャするものでよいものとなります。これを データレイク上に書き込む場合、先述のOpen table format を利用して書き込みを行い、Athena からクエリを発行する事が出来ます。
また、Amazon MSK を利用してデータウェアハウス(Redshift)へストリームデータを取り込み、集計を操作するケースも実現が出来ます。
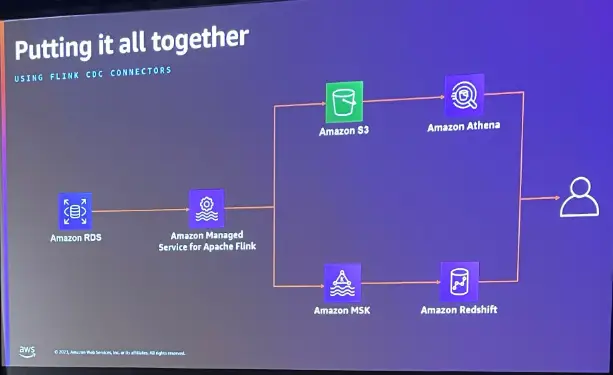
では、複数のアプリケーションによって生成されたデータに、アクセスする場合はどうでしょうか。Flink CDC Connector の使用は、このようなユースケースに適合しない可能性もあります。
この場合、Kafka Connect からDebezium の CDCを実現します。データベースからデータ変更キャプチャのイベントを取得し、その情報を Amazon MSK クラスターへプッシュする事が出来ます。このケースでは、Flink CDC Connector を使用していませんが、Flink アプリケーションは Dynamic Table を利用します。Flink SQL API を使用して変換処理を行い、データレイクや Kafka トピックに加工データを送信します。このプロセスでは、必要に応じて AWS Glue からストリームプロセスを実行したり、 EMR クラスター内の環境をより詳細に制御する Flink アプリケーションを実行する事も出来ます。

Summary
ここまで見てきた内容のサマリーです。
Apache Flink を使用すると、ストリーム分析だけでなくバッチ処理に対しても実行出来るようになります。また、Flink CDC Connector は幅広いソースをサポートします。
Apache Flink は、バッチ処理をサポートするため、既存のバッチプロセスをApache Flink に切り替え、Flink フレームワークに慣れてきてから抽出に対しての洞察を得る事で適切なストリーム分析を実装する事が出来ます。我々は通常データに対してバッチでアクセスをし、データベース内にそのデータにアクセスをしているとしても、これらに対する変更は、リアルタイムで起こっています。Dynamic Table を持つ Flink を利用する事で、処理時間を短縮し、より適切な情報に基づく意思決定を行う事が出来ます。
Flink CDC を使用する事で、 MSK の利用なく、簡略化された状態でデータを利用できるようになります。これには sink が冪等である事が要件です。今回はS3データレイクにおける Table format について紹介がありました。

本投稿は、登壇者が話された課題からアーキテクチャまでの一連の主旨を咀嚼し、執筆致しました。こちらは非常に有意義なセッションでした。
次回は引き続き本セッションの Demo の内容と、セッションの最後に紹介のあった Call to action の実装を行う投稿を致します。
以上、最後まで閲覧頂きありがとうございました。
- カテゴリー
- タグ

この記事をシェアする



