












目次
こんにちは、那須です。
耐障害性テストを実施する機会が最近ありまして、いくつかの障害パターンを想定してテストしてみました。するとサービスは継続して提供できると想定していたものが、特定のシナリオではサービスがダウンしてしまう経験をしたので読者の皆様に共有します。
2024.03.27現在の結論(全部読んでられない方向け)
ALBとターゲット(EC2インスタンスやECSなど)が同じサブネットに配置されている環境で、そのサブネットが使えなくなった想定のテストをAWS Fault Injection Service(以降、AWS FIS)ですると、本来ユーザから見た時にはサービス提供が継続されるはずがでしたが実際にはサービスが停止してしまいました。AWS FISがNACLを使って疑似的に障害を起こすことによって発生した例なので、NACLで制御できるような設計になっていると安心です。
AWS FISを使ってサブネットが使えなくなる(通信障害が発生する)シナリオの耐障害性テストを実施する場合、サービスの構成によってはサービスダウンが発生する場合があります。なので本番環境で実施する場合には特に注意が必要です。手順の確認や影響範囲を事前に確認するために、まずは開発環境や検証環境で実施することをおすすめします。
対象読者
- これから耐障害性テストを行う予定がある方
- AWS FISを活用してサービスの信頼性を確認したい方
- なんでもいいのでカオスエンジニアリングの例が知りたい方
そもそもなぜ耐障害性テストを行うのか?
この記事をここまで読まれている方であれば、普段の業務でシステムの冗長構成を考えたりその効果を確かめたりしていると思います。その冗長構成、本当に片方で障害が発生した際にもう片方に切り替わってサービス提供できる状態になっているのか把握されていますか? 導入時にはテストしてるけど、運用が始まってからは一度もそんな確認をしたことないな…なんて方も多いのではないでしょうか? 本番環境でそんなことできないよ!というお声もありそうですが、では開発環境や検証環境で同じ構成を作って確かめていますか?
これはWebサービスでもモバイルアプリのようなサービスのバックエンドでも弊社が扱うSAPシステムのような基幹システムでも、すべて同じように考えられます。例外はあるかもしれませんが基本的にはありません。ユーザに迷惑がかかってからでは遅いのです。障害が発生したことはユーザにとってはどうでもいいことなのです。「クラウドで障害が発生したから仕方ない」というのはサービス提供側としては言いたくなりますが、ユーザからすると「知らんがな。はよ直さんかい!」となります。それで業務が止まるだけであればいいですが、Webサービスやモバイルアプリの場合はユーザの解約につながったりします(実体験あります)。そうなると売上が下がることになります。基幹システムも停止すれば自社の業務が止まるだけでなく、サプライチェーンそのものが止まる可能性もあります。そうなると様々な金銭的損失や機会損失が生まれます。
こんなことにはなりたくないですよね? だから定期的に耐障害性テストを実施することが重要なんです。まだやったことない方は機会を作ってやってみることをオススメします!
今回の事象
本記事ではAWS FISの具体的な設定の流れは説明しません。あくまで事象の共有になりますので、設定方法を知りたい方はAWSの公式ドキュメントをご覧ください。
試したことと実験結果
以下のような構成でサービスを提供しているとします。ALBとECS(コンテナ)は同じサブネット内にデプロイされています。
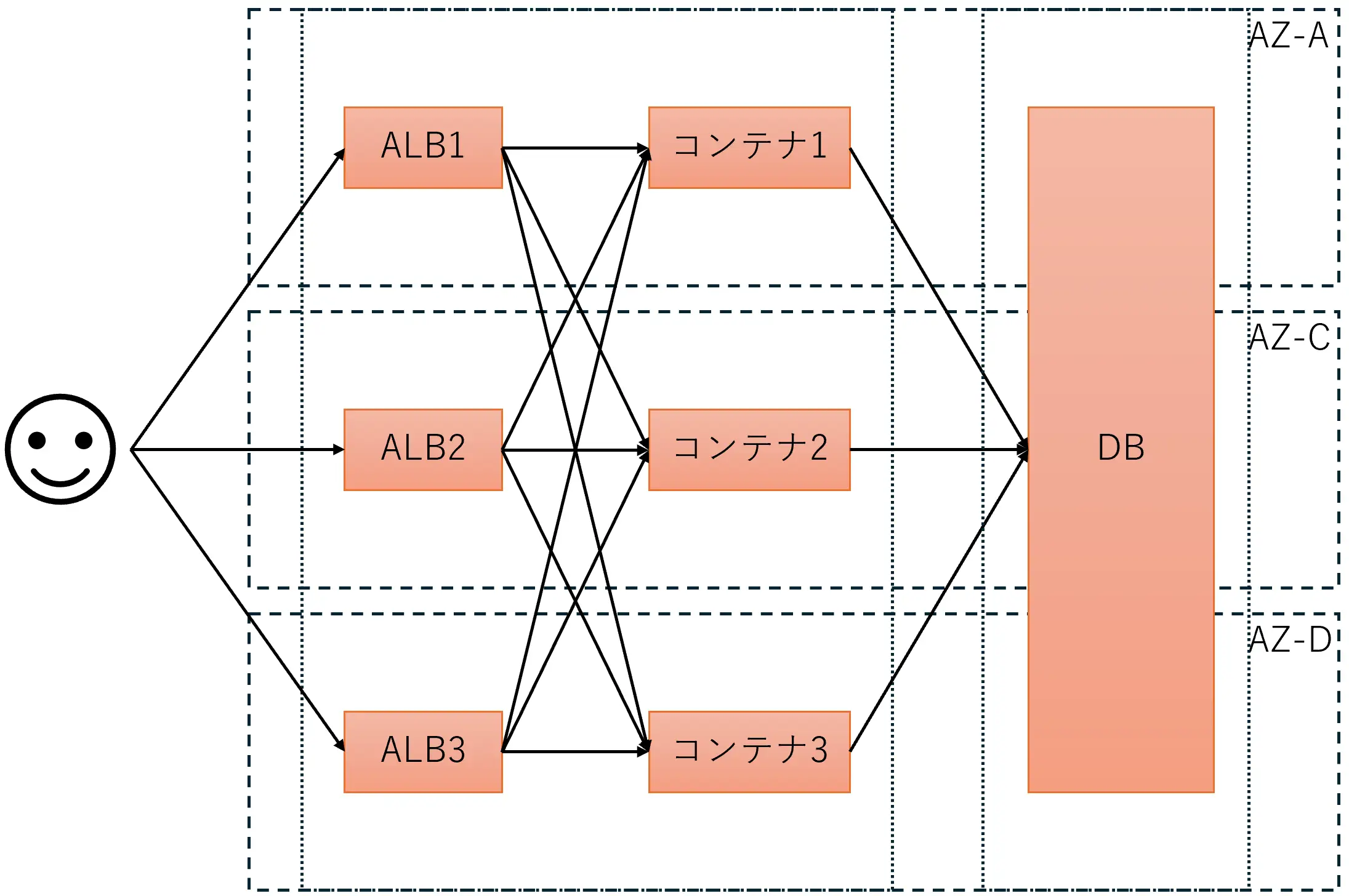
過去にAZ単位で障害が発生した事例もありますのでAZ単位で障害を起こそうと思いましたが、まずは小さくサブネット単位で障害を起こしてみることにしました。利用するAWS FISのアクションは「aws:network:disrupt-connectivity」です。実験対象サブネットは以下の部分です。結果はCloudWatch Synthetics Canaryで毎分リクエストを送信してその結果から判定します。
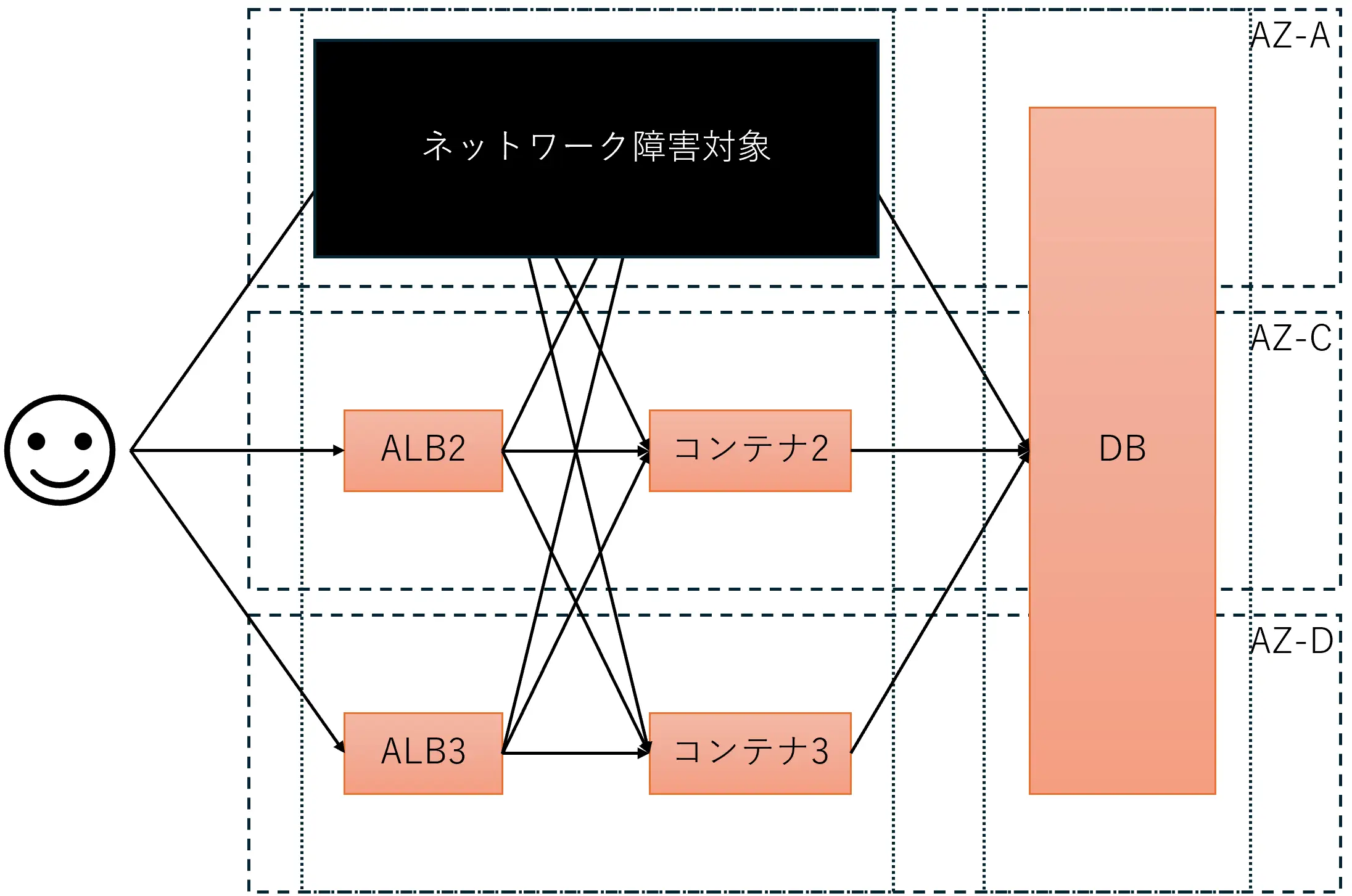
すると本来ならサービス提供にはほぼ影響がないはずなのに、なぜかリクエストの約1/3は失敗してしまいました。幸いにも検証環境でテストしていたので実際のユーザが悲しむ結果にならずに済みました。
原因
aws:network:disrupt-connectivityアクションは、実態としてVPCのNACLで実験対象サブネットとそれ以外のサブネットとの通信を遮断する動きをします。その際、実験対象サブネット内に閉じた通信は問題なく疎通できます。サブネットを超える通信だけが遮断されている状態ですね。その状態だと、同じAZ内のALBの実態(インスタンス)とターゲットのECSコンテナは通信できる状態なので、ヘルスチェックが通ります。ヘルスチェックが通るということは、ALBとしてはそのAZは生きていることを意味するので、そのAZにあるALBの実態は「私にもリクエスト投げてください!」というリクエスト待ち状態になります。
この状態でALBのDNS名を名前解決すると3AZ分の宛先が返ってくるので、リクエストは実験対象サブネットにあるALBにも転送されてしまう、ということになります。これが原因でリクエストの約1/3が失敗してしまうという事象を引き起こしていました。
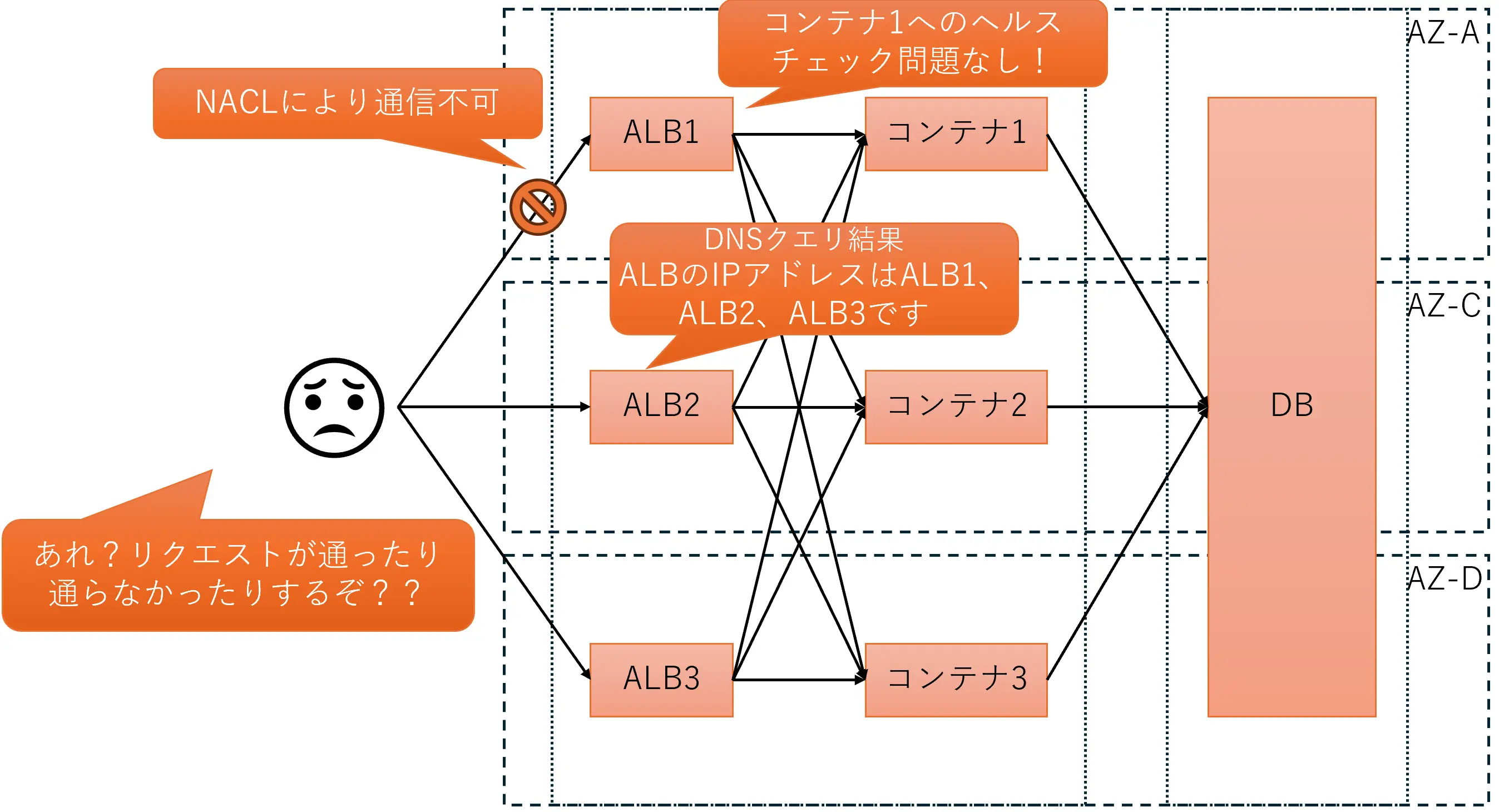
結論
あくまで現時点の結論にはなりますが、ALBとそのターゲットが同じサブネットに配置されているような構成ではAWS FISのaws:network:disrupt-connectivityアクションでサブネット障害を想定した耐障害性テストを実施しても正しい結果は得られないので注意しましょう。ALBとそのターゲットがそれぞれ別々のサブネットに配置されている場合は、ターゲット側のサブネットでaws:network:disrupt-connectivityアクションを実施するとALBからのヘルスチェックが失敗するので、この記事でご紹介したようにユーザから見た時にサービスが落ちるようなことにはなりません。
今回の件で得られた教訓は、各リソースはなるべくサブネットを分けて配置した方がいい、ということです。少なくともALBとターゲットはサブネットを分けようと心に決めました。
さいごに
AWS FISを活用してネットワーク(サブネット)障害を想定した耐障害性テストで起こった事例をご紹介しました。今回はうまくいかなかった事例をご紹介しましたがそれ以外のAWS FISのアクションでは想定通りの結果が得られていますので、可用性の高いシステムを運用されている方はぜひ試してみてください。障害が発生しても大丈夫なように設計してるから大丈夫!と思っていても、実際にやってみたらサービス停止してしまった…なんてことがあるかもしれませんよ。いきなり本番環境でするのは難しいと思いますので、開発環境や検証環境で本番と同じ構成を一時的に作って実験してみてはいかがでしょうか。

この記事をシェアする

![[re:Invent 2023 レポート] SAPシステムのレジリエンスを高めるためにやったこと](/media/thDCkaLG0hn0kLHqnJyRuFBX8BiKanmJIsLTO5Ik.jpeg)



