












目次
Introduction
昨年の 11月より一般提供が開始された Microsoft Fabric について、個人検証として触れました。本記事では、 Microsoft Fabric の論理データレイクである OneLake と Azure Databricks との統合手順について記載を致します。
なお、本記事は、公式ドキュメントの以下の手順に沿って検証を実施したものとなります。
OneLake と Azure Databricks の統合
OneLake にデータを取り込み Azure Databricks を使用して分析する
OneLake
手順に入る前に OneLake について、少し調べてみましたので、一部機能を抜粋して記載します。
最初にMicrosoft Fabric のUI上 から OneLake の使用を開始するには、レイクハウスを作成する事で、利用が可能となるもののようです。レイクハウスのエクスプローラー画面では、ファイルのアップロードや、ノートブックを開いて処理が行えます。
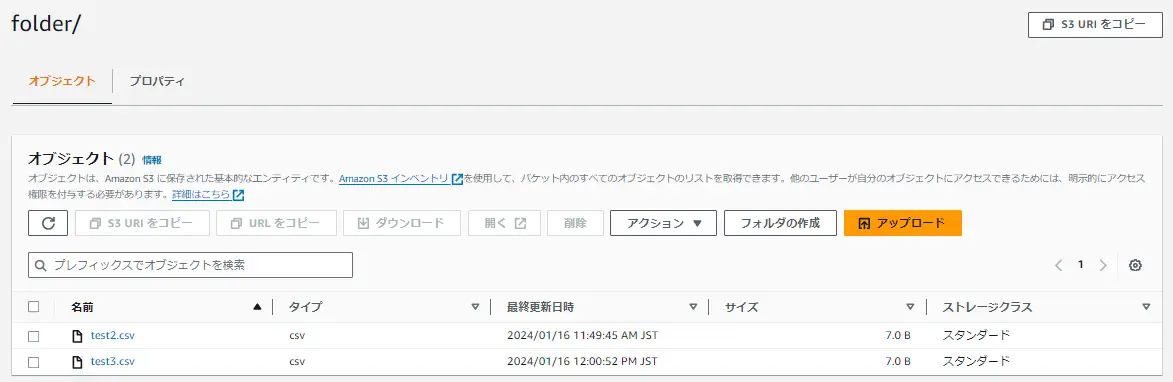
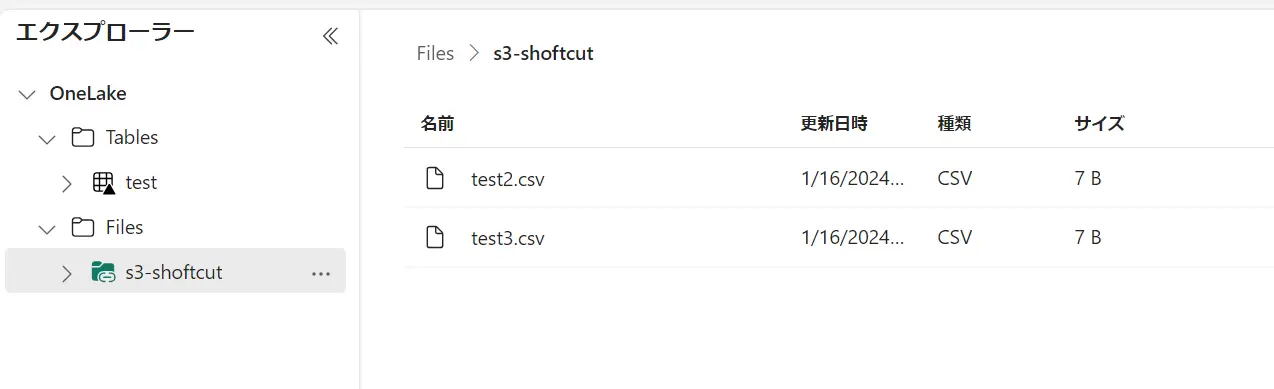
OneLake は、ショートカットの機能を持っています。ショートカットは、内部ソースにあたる、レイクハウスや、外部ソースにあたる Azure Data Lake Storage Gen 2 、Amazon S3 のオブジェクトをショートカットとして作成出来ます。
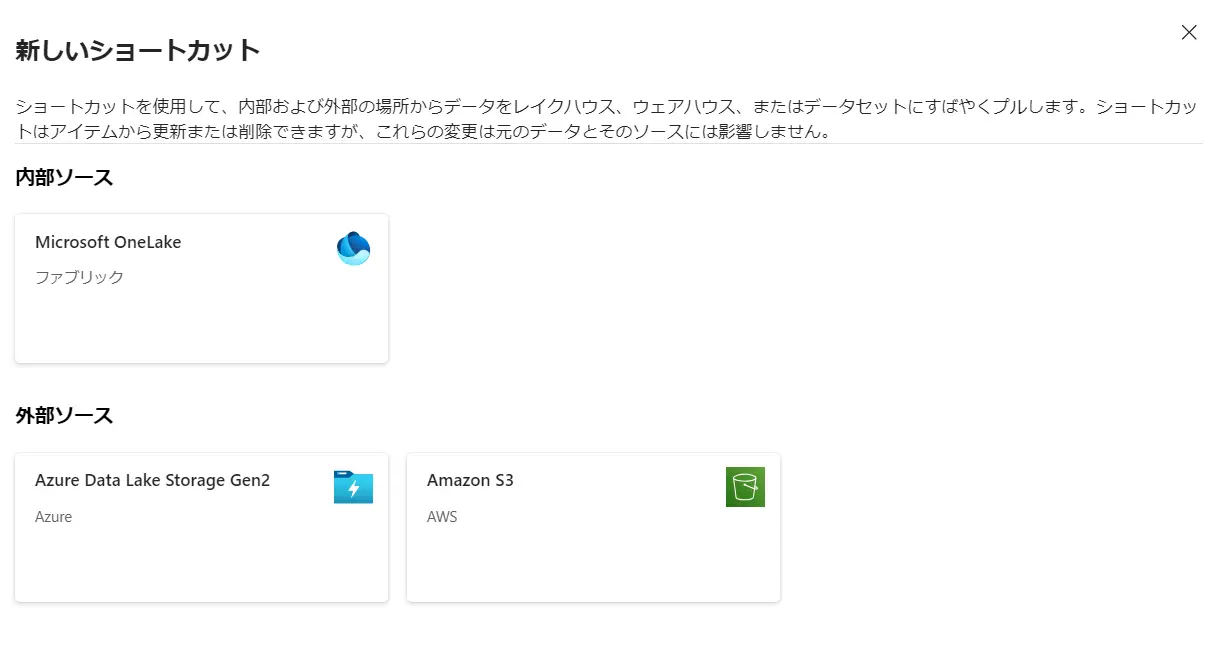
Amazon S3 ショートカットを作成すると、指定したバケット内のオブジェクトがショートカットとして作成されます。S3 へのアクセスは、 IAM ユーザーの認証情報を使用する方式です。
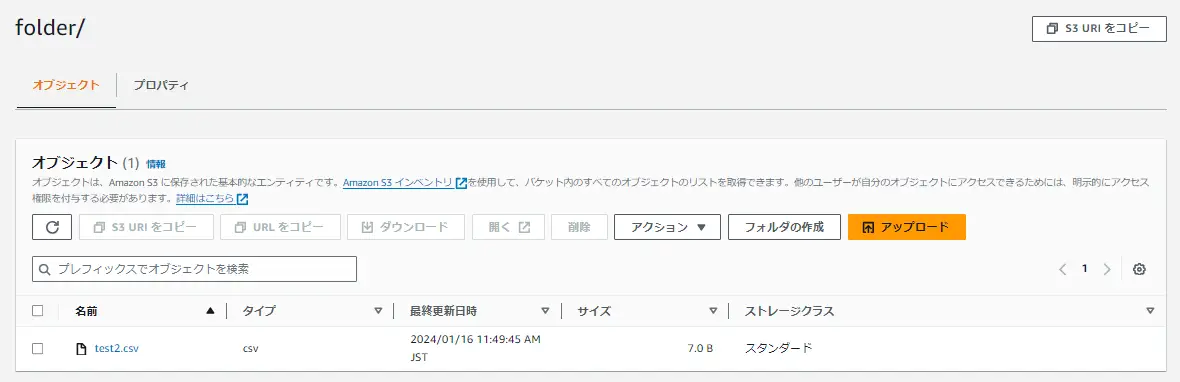
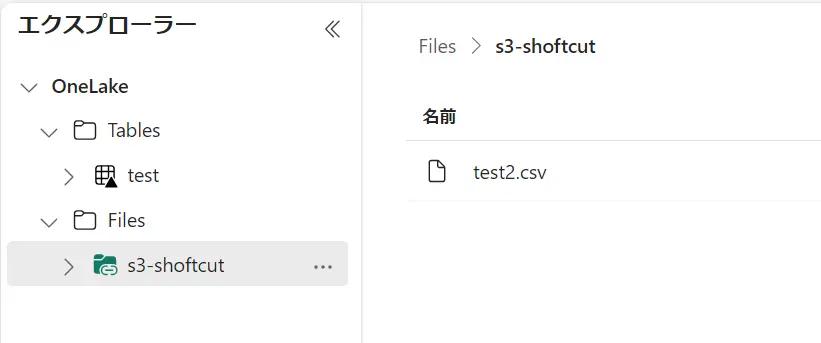
対象の S3 にファイルを追加した場合に、レイクハウスのエクスプローラーへも反映される事が確認出来ます。ショートカットの機能自体はシンボリックリンクのような動作挙動となるようです。
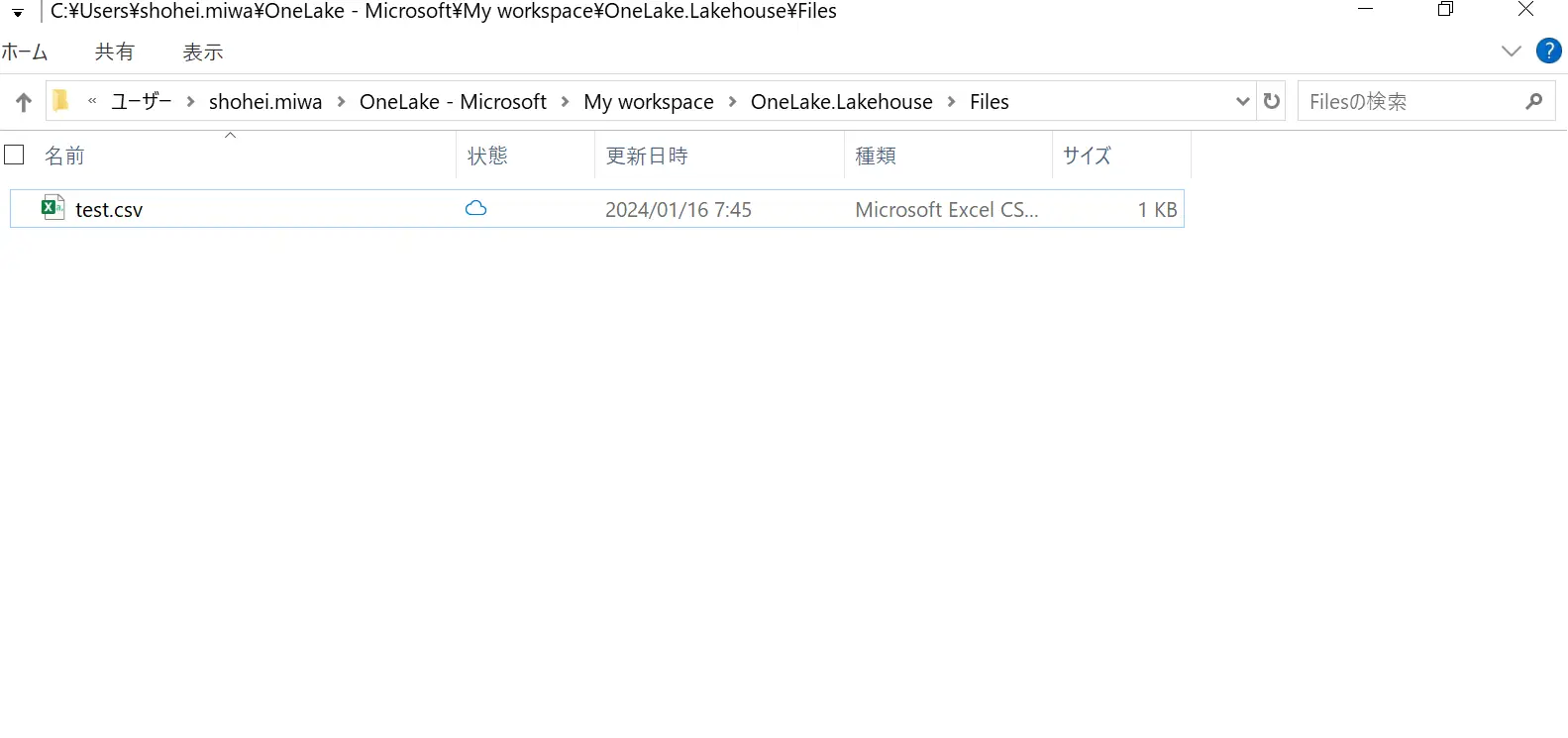
また、OneLake ファイルエクスプローラーというアプリケーションが Windows のファイルエクスプローラーと統合して、Windows 上から操作が出来ます。
OneLake ファイルエクスプローラーをインストールすると、Windows のエクスプローラー上へ、OneLakehouse のフォルダが作成され、Lakehouse 上に存在するファイルが確認出来ました。OneDrive に近いイメージを持ちました。
最後に、APIアクセスを試してみます。今回は Azure Storage Python SDK を使用したアクセスを試してみます。
OneLake へのアクセスは ADLS Gen2 と同様の SDK をサポートしており、azure-identity パッケージから Microsoft Entra 認証を実施します。必要に応じて azure-identity パッケージをインストールして操作を行います。
pip install azure-storage-file-datalake azure-identity下記は、DATA_PATH で定義した配下の結果を一覧表示する python ファイルの例です。ポイントとして、ACCOUNT NAME として定義している onelake は固定のようです。
#Install the correct packages first in the same folder as this file.
#pip install azure-storage-file-datalake azure-identity
from azure.storage.filedatalake import (
DataLakeServiceClient,
DataLakeDirectoryClient,
FileSystemClient
)
from azure.identity import DefaultAzureCredential
# Set your account, workspace, and item path here
ACCOUNT_NAME = "onelake"
WORKSPACE_NAME = "<WorkSpace-Name>"
DATA_PATH = "<Lakehouse-Name>.Lakehouse/Files"
def main():
#Create a service client using the default Azure credential
account_url = f"https://{ACCOUNT_NAME}.dfs.fabric.microsoft.com"
token_credential = DefaultAzureCredential()
service_client = DataLakeServiceClient(account_url, credential=token_credential)
#Create a file system client for the workspace
file_system_client = service_client.get_file_system_client(WORKSPACE_NAME)
#List a directory within the filesystem
paths = file_system_client.get_paths(path=DATA_PATH)
for path in paths:
print(path.name + '\n')
if __name__ == "__main__":
main()
下記のように一覧が表示されます。
> python listOneLake.py
XXXXXXXXXXX/Files/_SUCCESS
XXXXXXXXXXX/Files/_committed_6096814903013356131
XXXXXXXXXXX/Files/_started_6096814903013356131
XXXXXXXXXXX/Files/part-00000-tid-6096814903013356131-1d341263-bf5a-404f-bbf7-44705f7baba7-3-1-c000.csv
XXXXXXXXXXX/Files/s3-shortcut
XXXXXXXXXXX/Files/test3.csv表示以外の操作も可能となります。DataLakeFileClient.upload_data メソッド を使用する事でファイルのアップロードも可能です。
# Install the correct packages first in the same folder as this file.
from azure.storage.filedatalake import (
DataLakeServiceClient,
DataLakeDirectoryClient,
FileSystemClient
)
from azure.identity import DefaultAzureCredential
import os
# Set your account, workspace, and item path here
ACCOUNT_NAME = "onelake"
WORKSPACE_NAME = "<WorkSpace-Name>"
DATA_PATH = "<Lakehouse-Name>.Lakehouse/Files"
LOCAL_PATH = "<local-path>"
FILE_NAME = "<file-name>"
class DataLakeHandler:
def __init__(self, account_name, workspace_name, data_path):
self.account_name = account_name
self.workspace_name = workspace_name
self.data_path = data_path
self.service_client = self.get_service_client_token_credential(account_name)
def get_service_client_token_credential(self, account_name):
account_url = f"https://{account_name}.dfs.fabric.microsoft.com"
token_credential = DefaultAzureCredential()
service_client = DataLakeServiceClient(account_url, credential=token_credential)
return service_client
def create_file_system_client(self, file_system_name):
file_system_client = self.service_client.get_file_system_client(file_system=file_system_name)
return file_system_client
def create_directory_client(self, file_system_client, path):
directory_client = file_system_client.get_directory_client(path)
return directory_client
def upload_file_to_directory(self, directory_client, local_path, file_name):
file_client = directory_client.get_file_client(file_name)
with open(os.path.join(local_path, file_name), mode="rb") as data:
file_client.upload_data(data, overwrite=True)
def main():
data_lake_handler = DataLakeHandler(ACCOUNT_NAME, WORKSPACE_NAME, DATA_PATH)
# Create a file system client for the workspace
file_system_client = data_lake_handler.create_file_system_client(WORKSPACE_NAME)
# Get the directory client where you want to upload the file
directory_client = data_lake_handler.create_directory_client(file_system_client, DATA_PATH)
# Upload the file to the directory
data_lake_handler.upload_file_to_directory(directory_client, LOCAL_PATH, FILE_NAME)
if __name__ == "__main__":
main()
ファイルはアップロードされました。
> python listOneLake.py
XXXXXXXXXXX/Files/_SUCCESS
XXXXXXXXXXX/Files/_committed_6096814903013356131
XXXXXXXXXXX/Files/_started_6096814903013356131
XXXXXXXXXXX/Files/part-00000-tid-6096814903013356131-1d341263-bf5a-404f-bbf7-44705f7baba7-3-1-c000.csv
XXXXXXXXXXX/Files/s3-shortcut
XXXXXXXXXXX/Files/test3.csv
XXXXXXXXXXX/Files/test4.csvOneLake integration Azure Databricks
ここから本題に入ります。
OneLake と Azure Databricks の統合パターンについて、以下にまとめの記述がありましたので、こちらを参考に、手順を実施しました。
* Using Azure Databricks with Microsoft Fabric and OneLake
Integrate OneLake with Azure Databricks
OneLake と Azure Databricks の統合 の作業については、以下の前提条件がございます。
- Fabric ワークスペースとレイクハウス
- Premium Azure Databricks ワークスペース。 このシナリオに必要な Microsoft Entra の認証情報パススルーは、Premium Azure Databricks ワークスペースでのみサポートされています。
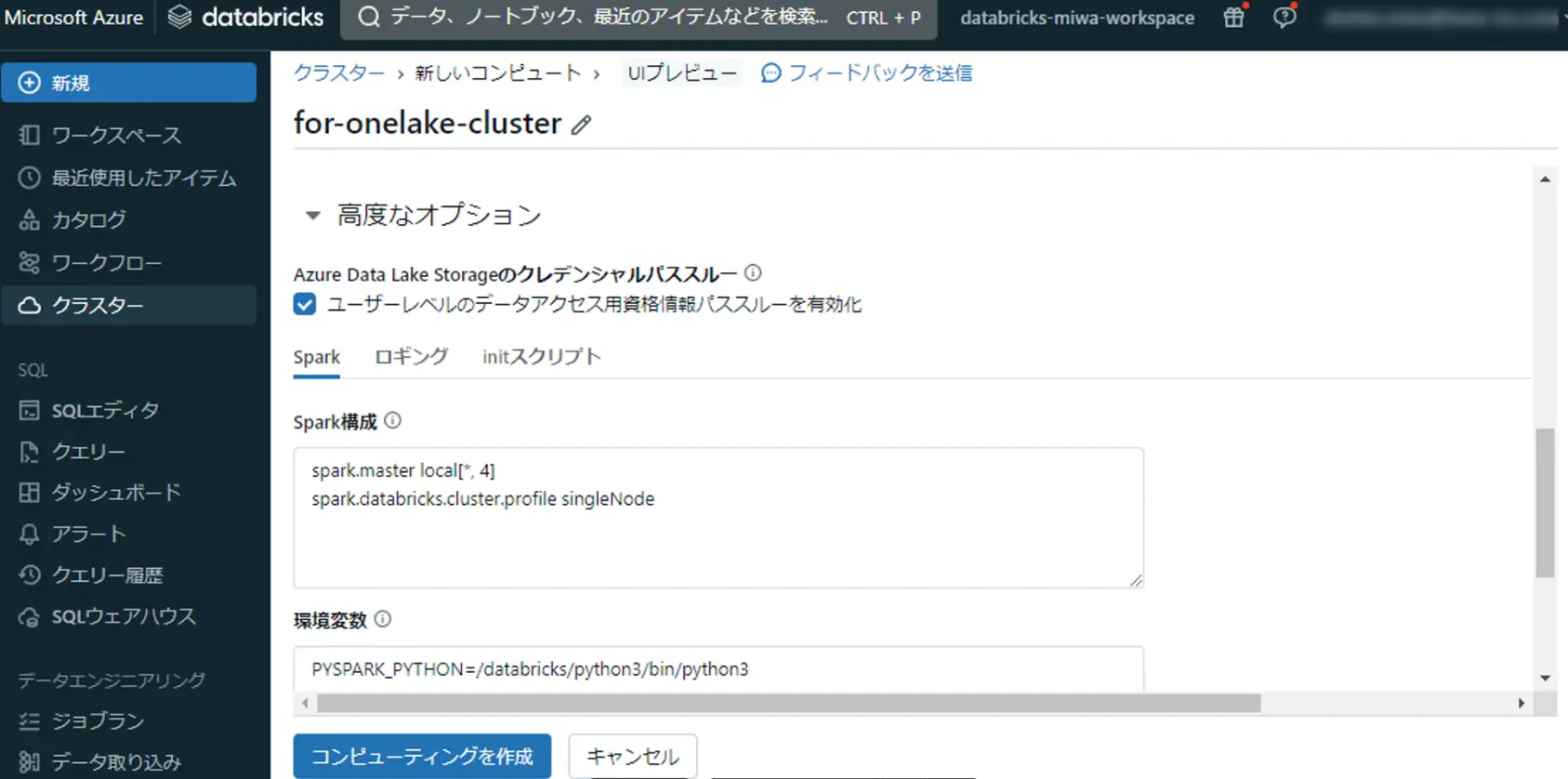
まず、Databricks ノートブックからレイクハウスの Files へ出力を行います。ここでは、ノートブックが使用するクラスターは、 Azure Data Lake Storage のクレデンシャルパススルーにチェックをします。
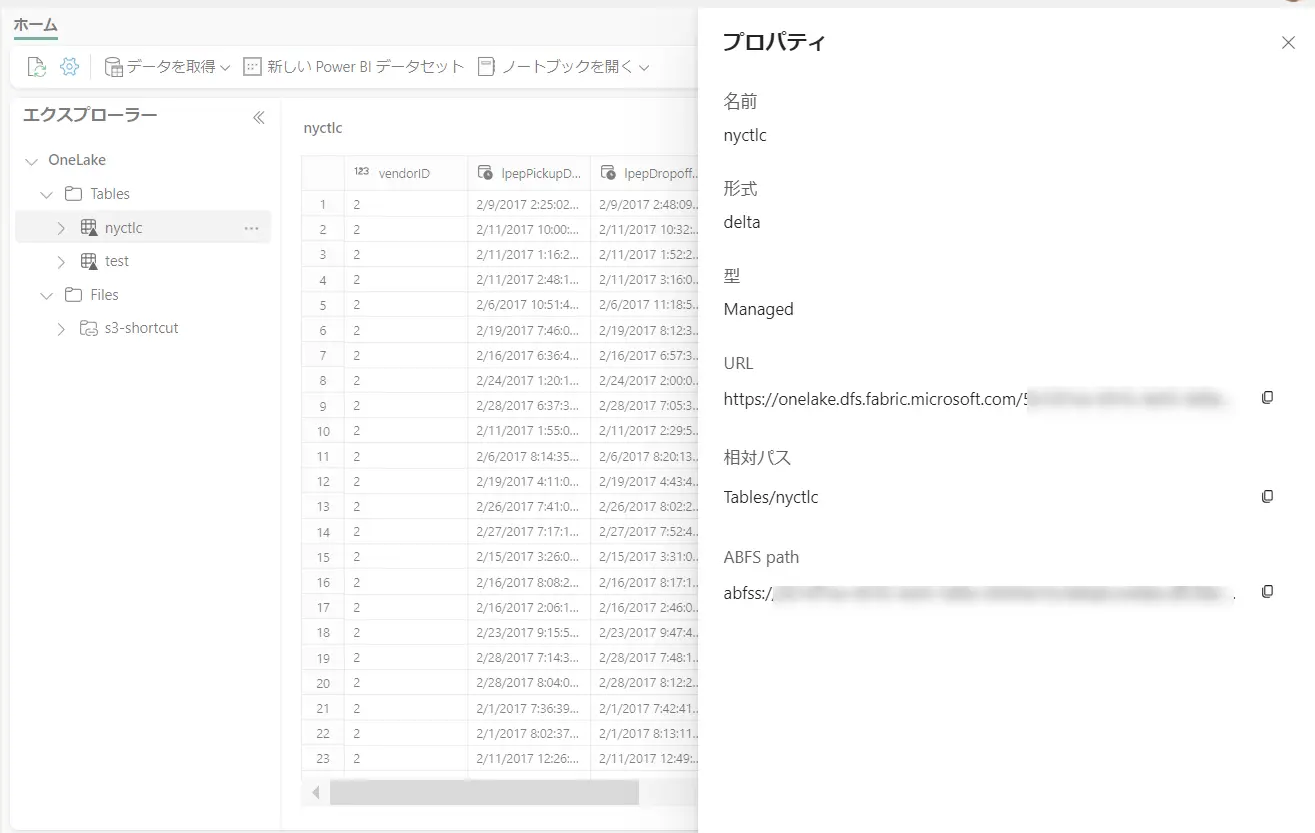
レイクハウス内のファイルへの操作を行う場合、対象フォルダの ABFS path を使用していきます。これは、対象のフォルダのプロパティから確認する事が出来ます。
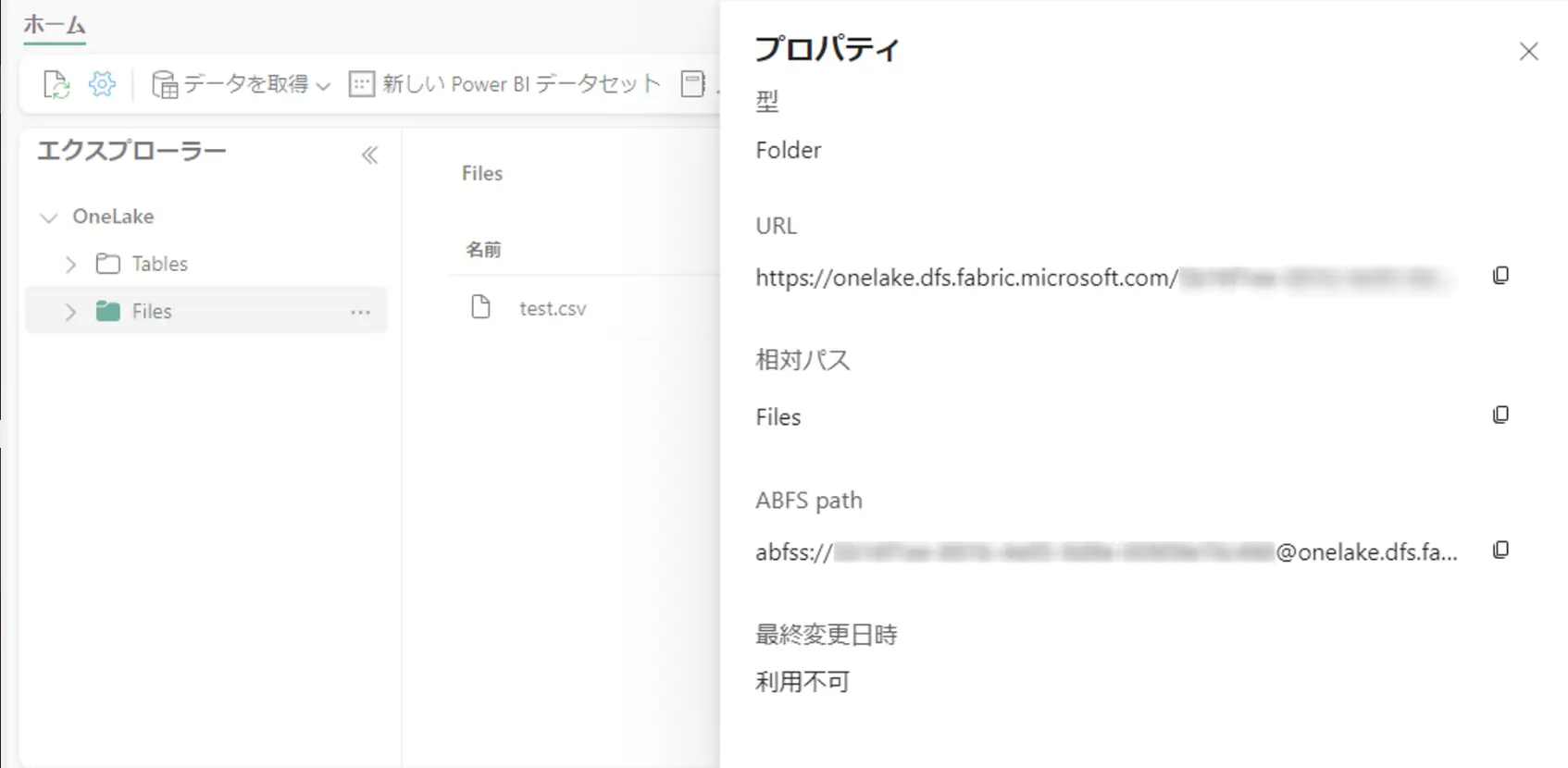
Databricks 側の ノートブック上から ABFS path を変数として定義します。
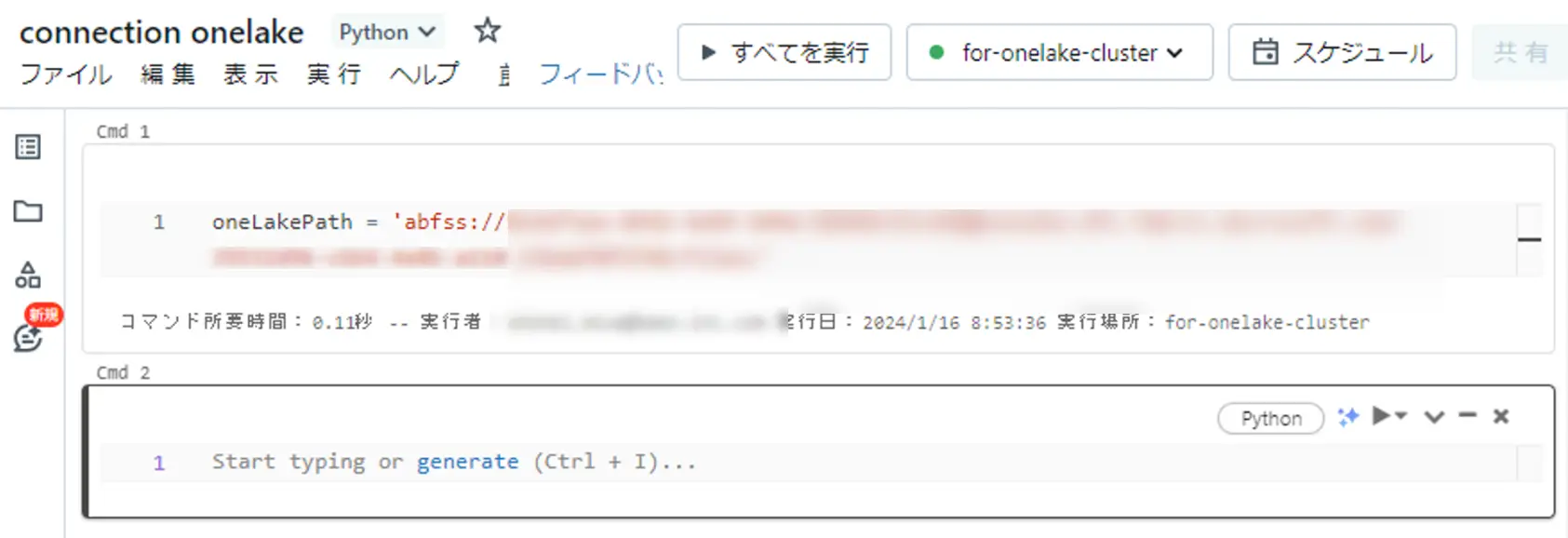
ここから、公式の手順に沿って、ノートブック上から各処理を行います。
以下は、Databricks パブリックデータセットをデータフレームに読み込み、加工抽出後に、データフレームを Fabrics レイクハウスに書き込みをします。書き込みをする際に、先ほど変数定義した ABFS path を使用しています。
2.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")
3.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)
4.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)
5.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath)
display(lakehouseRead.limit(10))
処理後に OneLake レイクハウスを確認すると、出力が確認出来ました。
なお、ショートカットへの出力はサポートされないようなエラーが出ましたので、ご注意下さい。("This operation is not supported through shortcuts.")
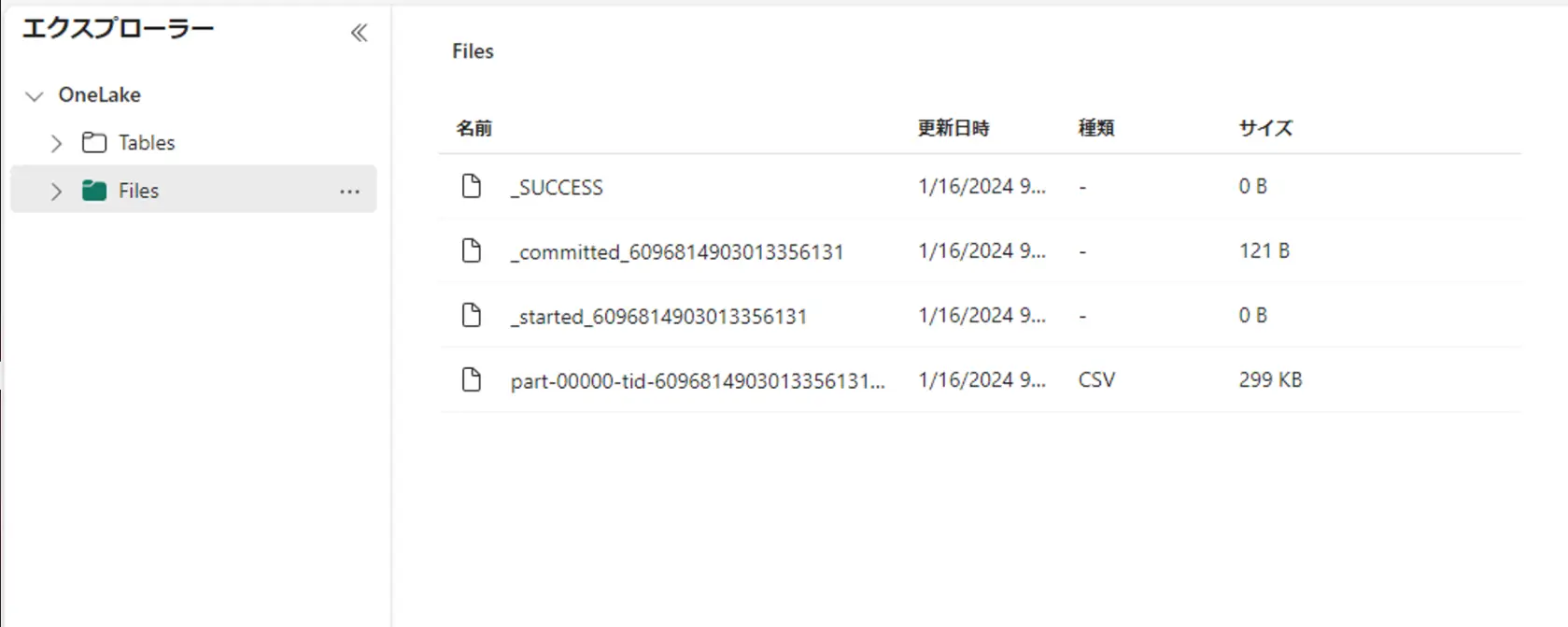
Ingest data into OneLake and analyze with Azure Databricks
続いて、レイクハウス上のデータを読み込んで、Databricks 上で分析を行うプロセスを実施していきます。
レイクハウス上から、新しいデータパイプラインを選択し、ソースデータを選択します。ここでは、手順にあるように NYC Taxi を選択していきます。
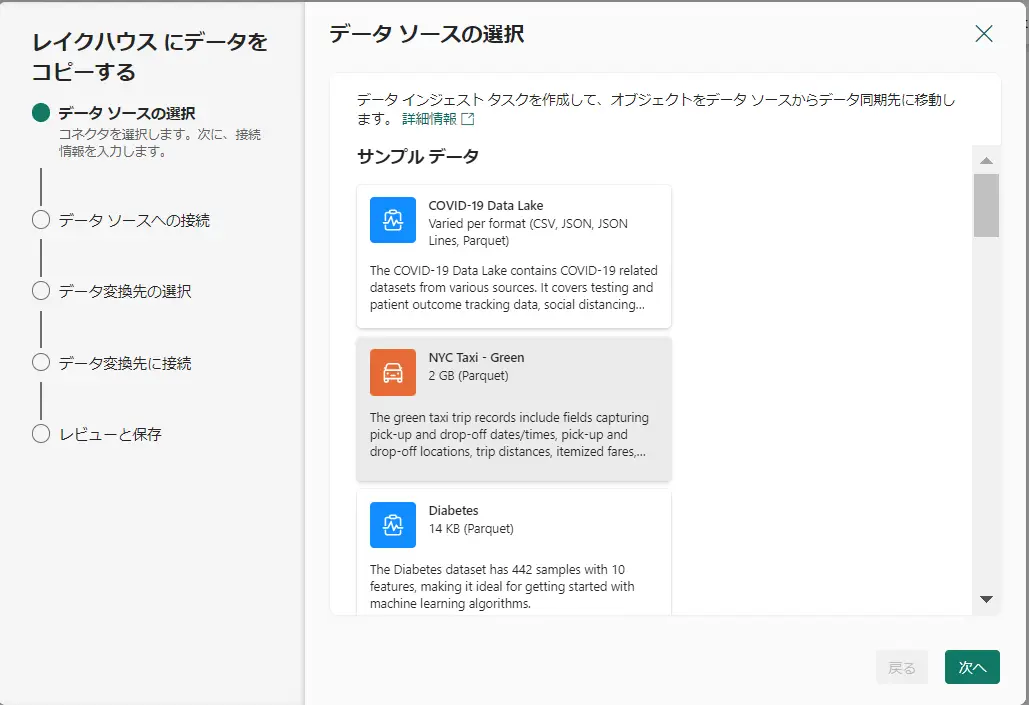
変換先のレイクハウスを選択します。今回は検証のため、パイプライン作成元のレイクハウスを選択します。その後の選択画面から新しいテーブルとして、nycsample テーブルを作成します。
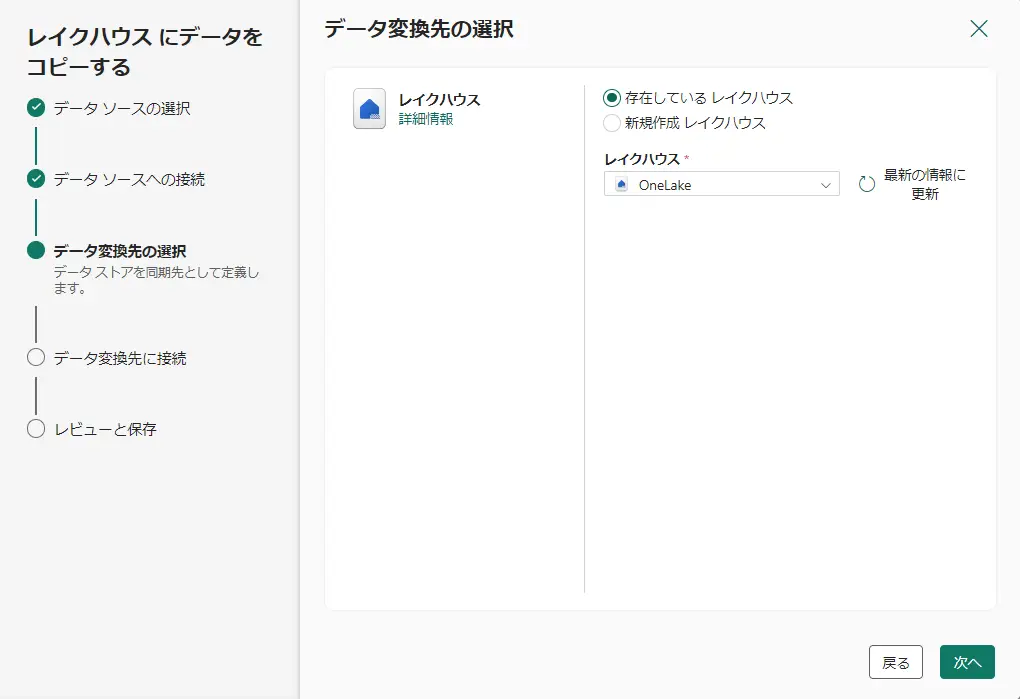
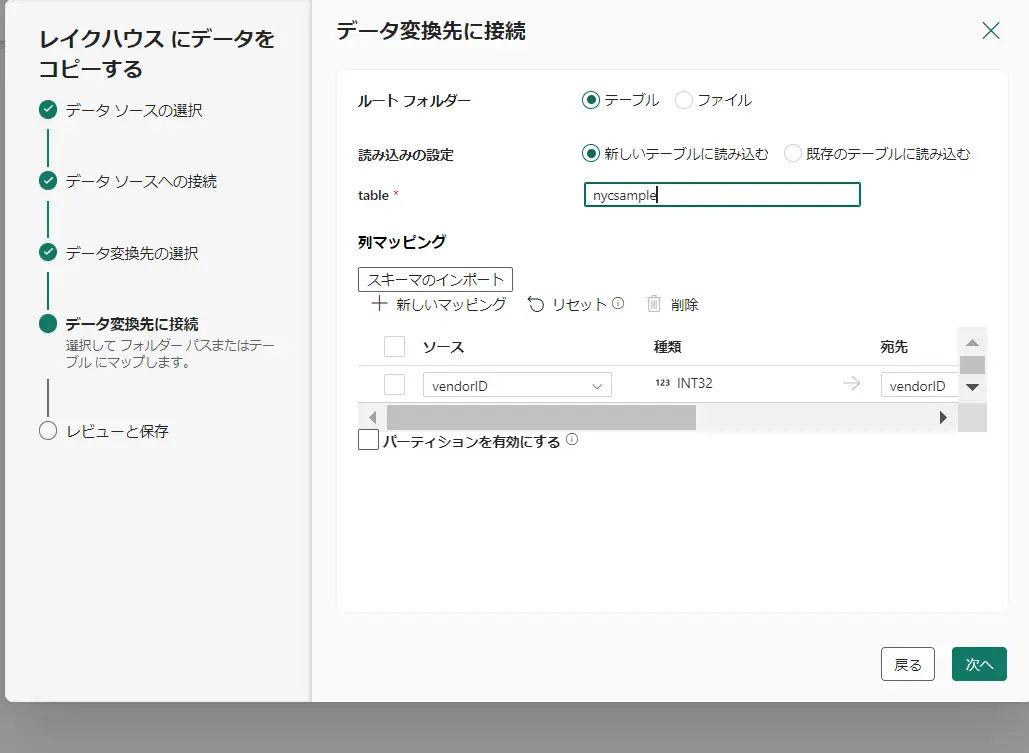
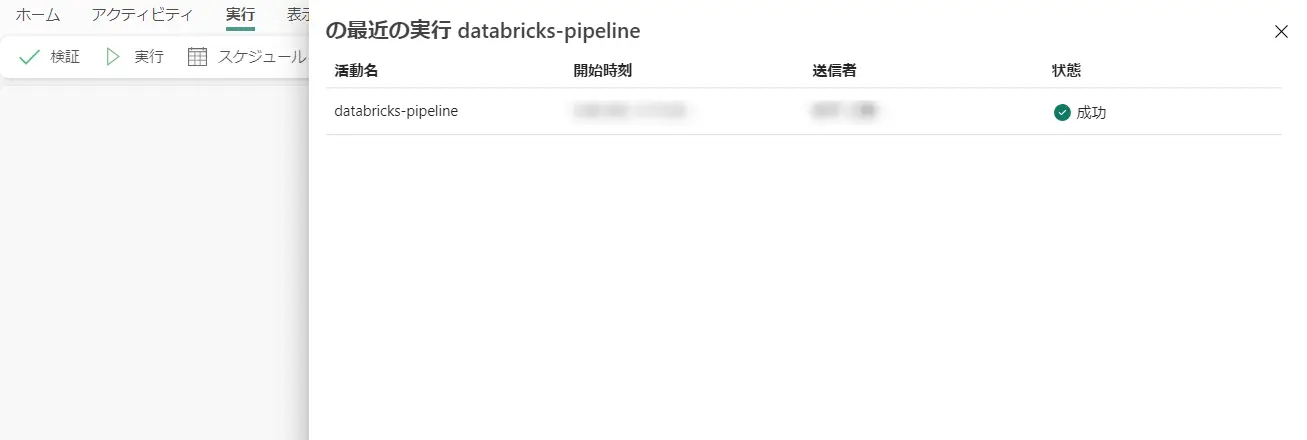
最後にデータ転送をすぐに開始するを選択、保存をすると、Fabric Data Factory のパイプラインとしてCopy Activity が動作します。実行状況が成功の状態へ遷移すると、次の作業に進みます。
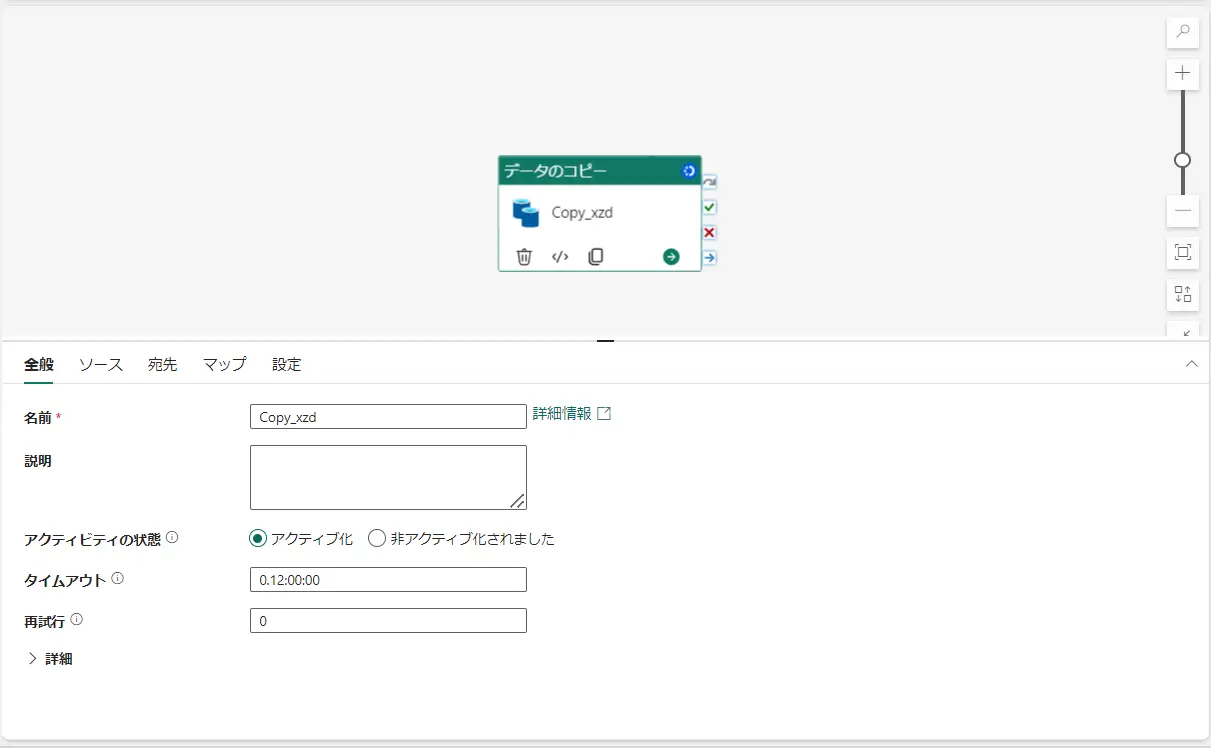
生成されたテーブルの ABFS patn を先ほど同様にコピーします。
Databricks ノートブック上からコピーした ABFS path をコピーし、実行すると、レイクハウス上のテーブルを spark のデータフレームが読み込み、SQL クエリの結果を返します。
olsPath = "abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample"
df=spark.read.format('delta').option("inferSchema","true").load(olsPath)
df.show(5)
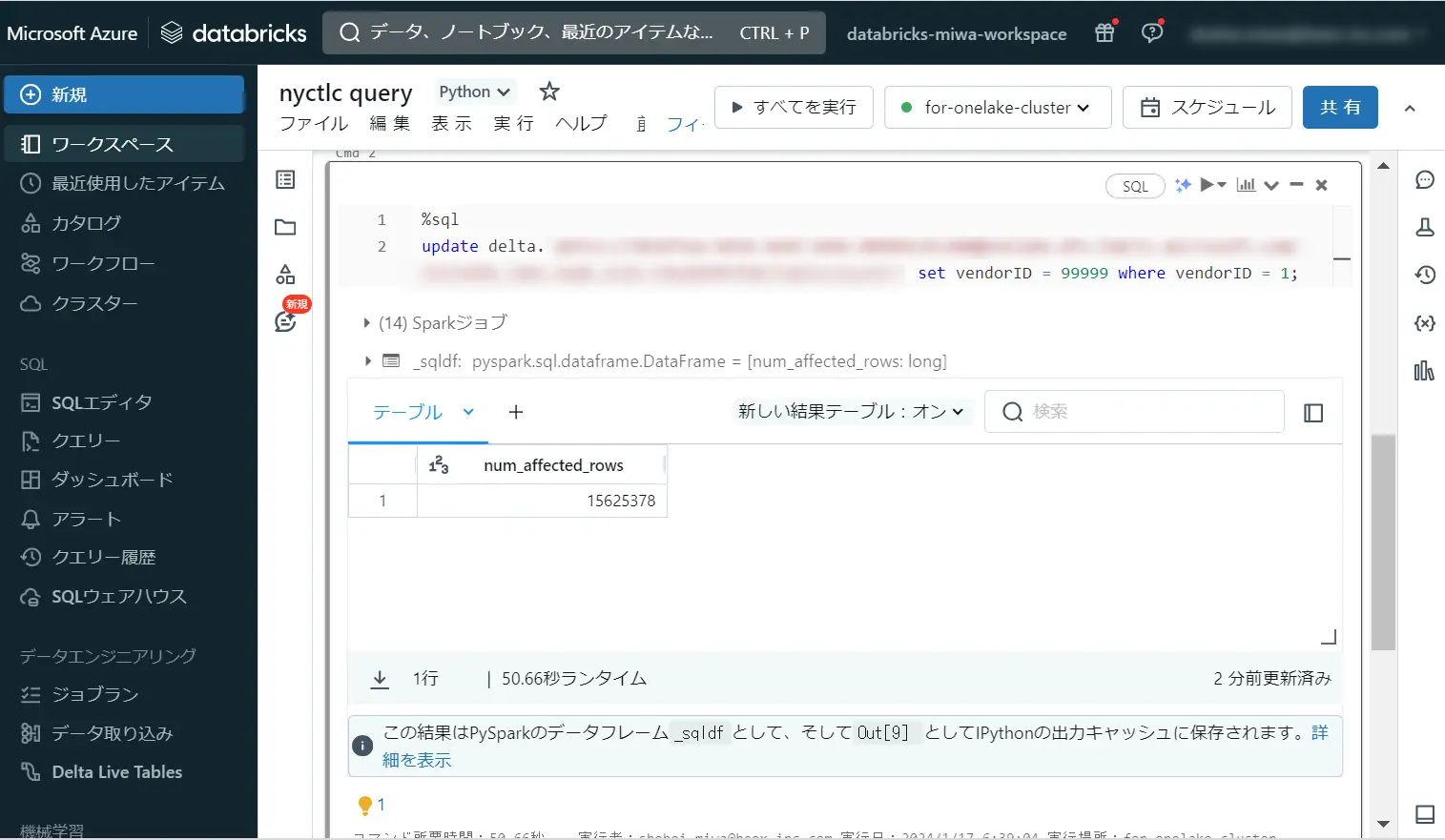
%sql
update delta.`abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Tables/nycsample` set vendorID = 99999 where vendorID = 1;
検証は以上となります。
実装の際は、公式ドキュメントをご確認の上お願いいたします。
最後まで御覧いただきましてありがとうございました。

この記事をシェアする



