












目次
@taokiです。
・今回はAWS機械学習サービス「SageMaker(セージメーカー)」を利用した、簡単な画像切り抜きツールの作成方法をご紹介したいと思います。
SageMakerとは

・使ってみた感じでは「数値・画像・文字などの学習データをjupiterマシーンに学習させることにより、AIモデル(※)やAIモデルAPIを生成することができる」がSageMakerの基本サービスかと思います。
※AIモデル・・・データを反復学習し、得られた結果を法則化したもの(だそうです)。
ロゴ

画像切り抜きツール
・今回はピクセル単位で物体ラベリングする、SageMakerのセマンティックセグメンテーション学習法を使います。(以下イメージ)
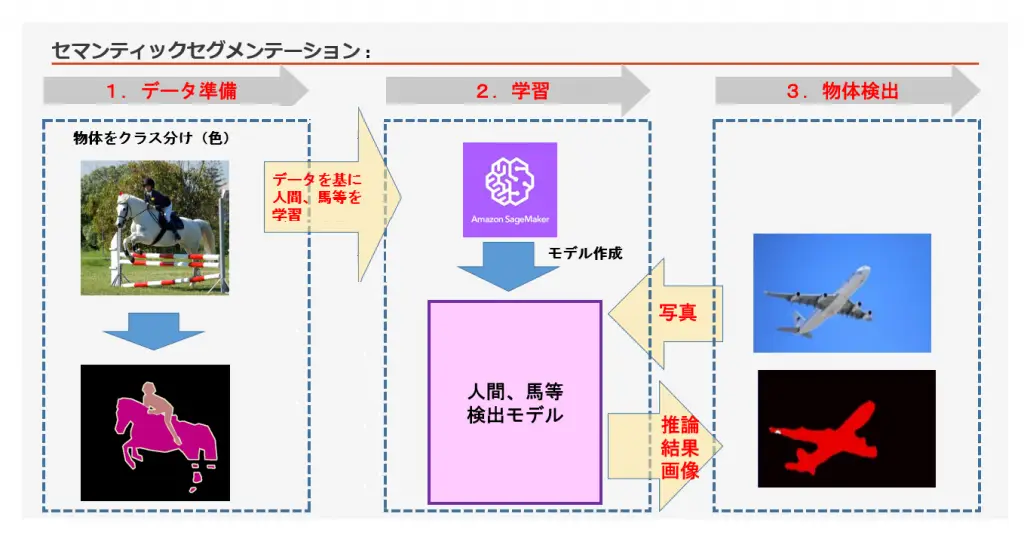
※クラス分け画像・・・薄いピンクは人間、濃いピンクは馬など、色で物体の種類を区別する。
今回は1500枚弱のクラス分け画像を使います。
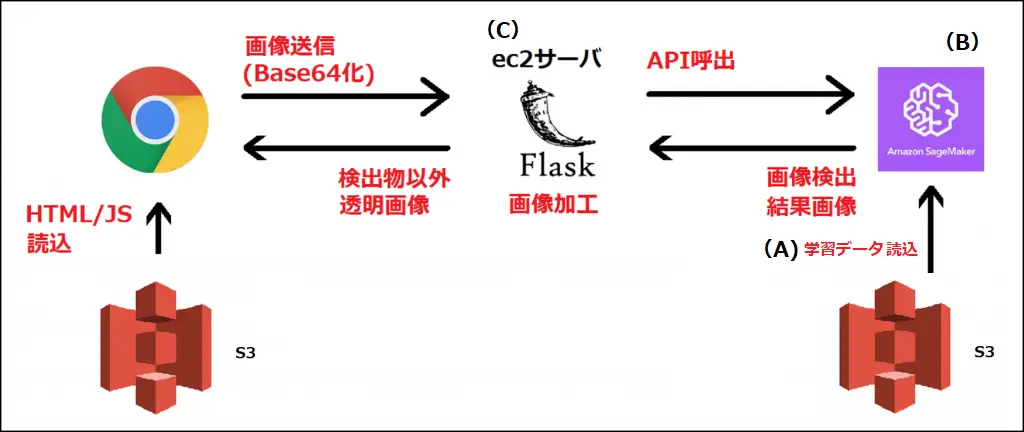
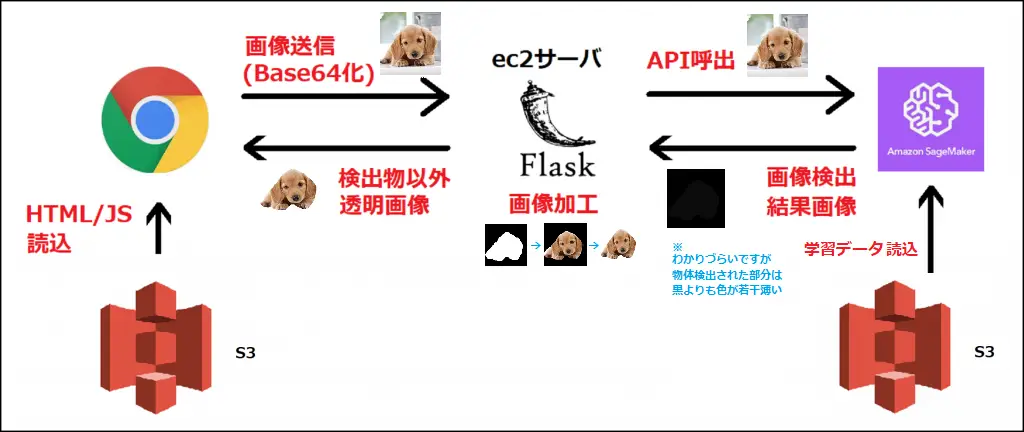
ツールのイメージ
・ブラウザ送信画像をAPIが物体検出し、ec2サーバで物体以外を透明にして返します。
ツール作成手順
(A)データ準備
・以下のサイトから学習データ「VOCtrainval_11-May-2012.tar」を取得
サンプル画像
・上記解凍フォルダの「JPEGImages」の中身を以下S3の「train」「validation」へコピー、「SegmentationClass」の中身を以下S3の「train_annotation」「validation_annotation」へコピーする。(トレーニング画像とバリデーション画像は本来は別のものを使うのですが、今回は時短のため同じです)
s3://sagemaker-taoki20190323/segmentation/|- train|- train_annotation|- validation|- validation_annotation(B)モデル・APIの作成(SageMakerにて)
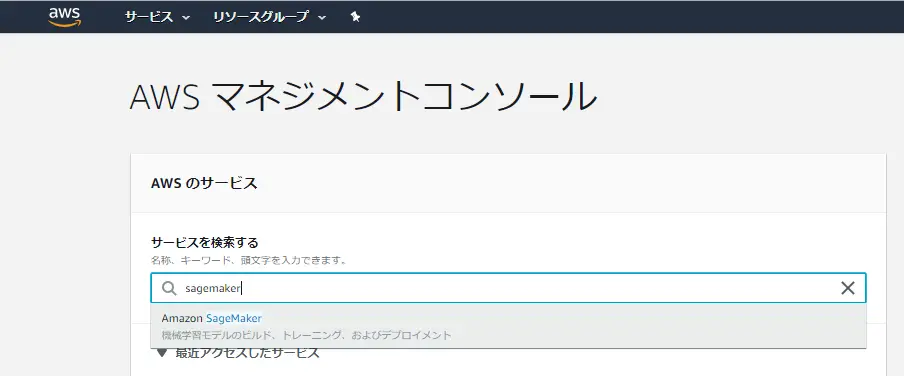
1)AWSマネジメントコンソール「sagemaker」入力・選択
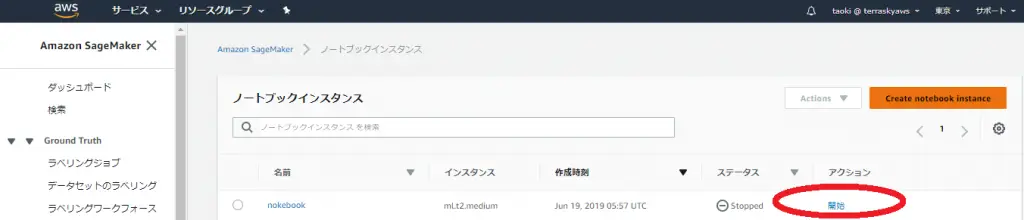
2)「notebook instance」(jupiterインスタンス)を作成

3)上記インスタンスを開始
4)モデル・API作成プログラムを記入および実行(以下手順)
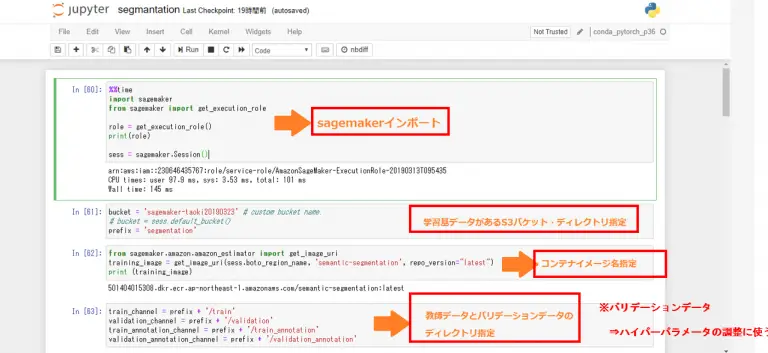
#SageMakerインポート
‰‰time
import sagemaker
from sagemaker import get_execution_role
role = get_execution_role()
sess = sagemaker.Session()
#学習データ格納するS3バケット・プレフィックスセットbucket = 'sagemaker-taoki20190323'prefix = 'segmentation' #jupiterコンテナイメージ名セットfrom sagemaker.amazon.amazon_estimator import get_image_uritraining_image = get_image_uri(sess.boto_region_name, 'semantic-segmentation', repo_version="latest") #学習データ格納するディレクトリ名セットtrain_channel = prefix + '/train'validation_channel = prefix + '/validation'train_annotation_channel = prefix + '/train_annotation'validation_annotation_channel = prefix + '/validation_annotation'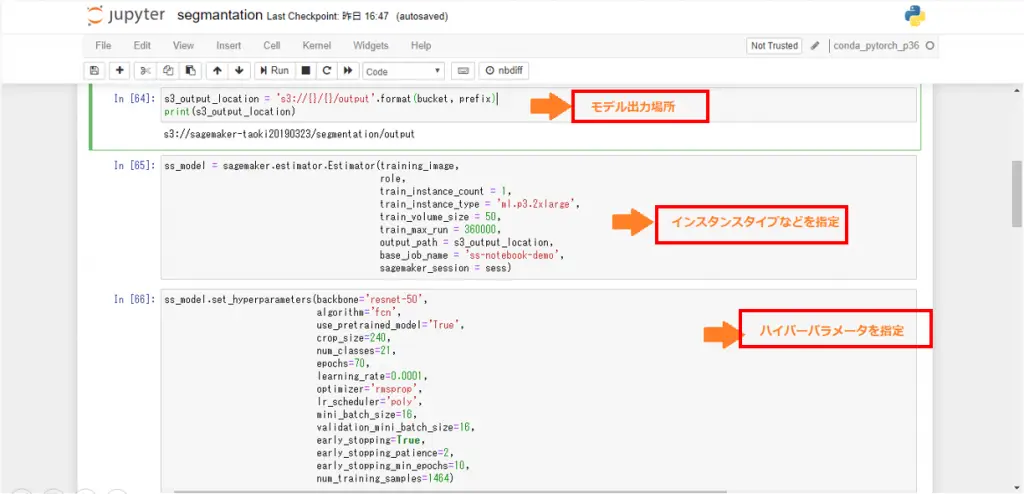
#モデル出力場所セットs3_output_location = 's3://{}/{}/output'.format(bucket, prefix) #インスタンスタイプセットss_model = sagemaker.estimator.Estimator(training_image, role, train_instance_count = 1, train_instance_type = 'ml.p3.2xlarge', train_volume_size = 50, train_max_run = 360000, output_path = s3_output_location, base_job_name = 'ss-notebook-demo', sagemaker_session = sess) #ハイパーパラメータセットss_model.set_hyperparameters(backbone='resnet-50', algorithm='fcn', use_pretrained_model='True', crop_size=240, num_classes=21, epochs=100, learning_rate=0.0001, optimizer='rmsprop', lr_scheduler='poly', mini_batch_size=16, validation_mini_batch_size=16, early_stopping=True, early_stopping_patience=2, early_stopping_min_epochs=10, num_training_samples=1464)※ハイパーパラメーターの詳細は別途ご確認ください。(内容が難しいので割愛します。。)
#上記でセットしたデータを取りまとめs3_train_data = 's3://{}/{}'.format(bucket, train_channel)s3_validation_data = 's3://{}/{}'.format(bucket, validation_channel)s3_train_annotation = 's3://{}/{}'.format(bucket, train_annotation_channel)s3_validation_annotation = 's3://{}/{}'.format(bucket, validation_annotation_channel)distribution = 'FullyReplicated'train_data = sagemaker.session.s3_input(s3_train_data, distribution=distribution, content_type='image/jpeg', s3_data_type='S3Prefix')validation_data = sagemaker.session.s3_input(s3_validation_data, distribution=distribution, content_type='image/jpeg', s3_data_type='S3Prefix')train_annotation = sagemaker.session.s3_input(s3_train_annotation, distribution=distribution, content_type='image/png', s3_data_type='S3Prefix')validation_annotation = sagemaker.session.s3_input(s3_validation_annotation, distribution=distribution, content_type='image/png', s3_data_type='S3Prefix')data_channels = {'train': train_data, 'validation': validation_data, 'train_annotation': train_annotation, 'validation_annotation':validation_annotation #モデル作成
ss_model.fit(inputs=data_channels, logs=True) #API作成ss_predictor = ss_model.deploy(initial_instance_count=1, instance_type='ml.c4.xlarge')(C)画像処理の作成(ec2にて)
画像加工イメージ
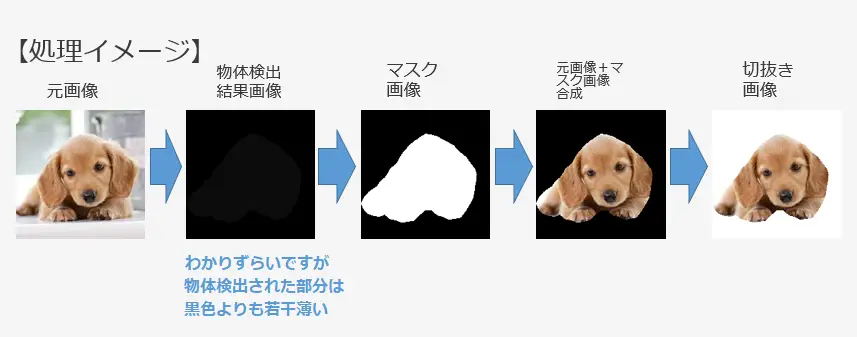
ツールイメージに併せると以下となります。
コードは以下です。(Python軽量フレームワーク「Flask」)
importjsonimport boto3import base64import loggingfrom flask import Flask, requestfrom PIL import Imageimport numpy as npimport ioimport cv2 app = Flask(__name__) logger = logging.getLogger()logger.setLevel(logging.INFO)ENDPOINT_NAME = 'ss-notebook-demo-2019-09-20-08-51-44-630' @app.after_requestdef after_request(response): # CORS許可 response.headers.add('Access-Control-Allow-Origin', 'http://taokibacket.s3-ap-northeast-1.amazonaws.com') response.headers.add('Access-Control-Allow-Headers', 'Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token,X-Requested-With') response.headers.add('Access-Control-Allow-Methods', 'GET,PUT,POST,DELETE,OPTIONS') response.headers.add('Access-Control-Allow-Credentials', 'true') return response @app.route('/img_data', methods=['POST'])def img_data(): # Base64の画像データ受信してバイナリに変換 img_data = json.loads(request.get_data())['img'] img_data = img_data.replace('data:image/png;base64,', '') img_data = img_data.replace('data:image/jpeg;base64,', '') image = base64.b64decode(img_data) with open('receive.jpg',"wb") as f: f.write(image) cimg = Image.open('receive.jpg','r') cimg.save('receive.png', 'PNG') # 画像判定APIをたたく client = boto3.client("sagemaker-runtime", region_name="ap-northeast-1") response = client.invoke_endpoint( EndpointName=ENDPOINT_NAME, ContentType='image/jpeg', Accept='image/png', Body=image) # 画像検出結果画像を保存 body = response['Body'].read() with open('analisys.jpg',"wb") as f: f.write(body) pil_img = Image.open('analisys.jpg','r') pil_img.save('analisys.png', 'PNG') # 検出物体(黒色以外)を白色に変換 org = Image.open('analisys.png') rgb_img = org.convert('RGBA') trans = Image.new('RGBA', org.size, (0, 0, 0, 0)) width = org.size[0] height = org.size[1] for x in range(width): for y in range(height): pixel = rgb_img.getpixel((x, y)) if pixel[0] != 0 and pixel[1] != 0 and pixel[2] != 0: trans.putpixel((x, y), (255, 255, 255)) continue trans.putpixel((x, y), (0, 0, 0)) trans.save('mask.png') # 元の画像と物体を白色変換した画像を白色を透明にしつつ合成(重ね合わせる) im1 = Image.open('receive.png') im2 = Image.open('mask.png') mask = Image.open('mask.png').convert('L').resize(im1.size) im = Image.composite(im1, im2, mask) im.save('composition.png') # 黒色を透明にする org = Image.open('composition.png') rgb_img = org.convert('RGBA') trans = Image.new('RGBA', org.size, (0, 0, 0, 0)) width = org.size[0] height = org.size[1] for x in range(width): for y in range(height): pixel = rgb_img.getpixel((x, y)) if pixel[0] == 0 and pixel[1] == 0 and pixel[2] == 0: trans.putpixel((x, y), (0, 0, 0, 0)) continue trans.putpixel((x, y), pixel) trans.save('result.png') with open('result.png', 'rb') as f: result_read = f.read() return {'body' : base64.b64encode(result_read)} # 検出物体以外が透明になった画像をBase64でフロントへかえす return {'body' : base64.b64encode(result_read)} if __name__ == '__main__': app.run(debug=True, host='0.0.0.0', port=5000)・HTML/Javascriptの作成
一般的なもので作成しました。(説明省略)
ツール実行
やっとツールを試すところまで来ました。ブラウザからページを開き画像を選択して送信します。

⇩

切り抜けた!学習データが少ないせいか細かいところにゴミが残っている感。。学習データを何万枚とかに増やすと精度は上がりそう。SageMakerにラベリングジョブという、世界の方々にラベリングを発注依頼できる元気玉のような機能があるようなので、それを使えばマンパワーで万枚準備できそうです。
他の人も切抜いてみました!
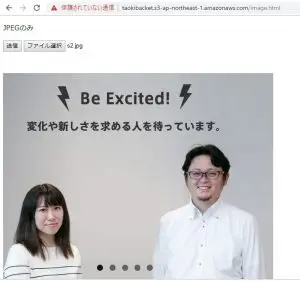
⇩
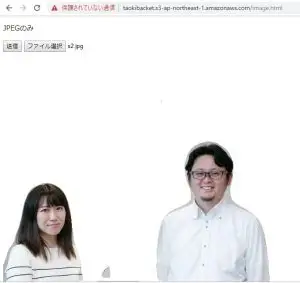
同じくややゴミが残りますが、、人間として認識しているようです。
【結果】

以上、SageMakerによる画像切り抜きツールのご紹介でした。次回はSageMakerの数値関連によるAIモデルで何か試せたらと思います。閲覧ありがとうございました!
参考URL:https://dev.classmethod.jp/machine-learning/2018advent-calendar-sagemaker-20181201/
- カテゴリー

この記事をシェアする

![[re:Invent 2023 レポート] Platform engineering with Amazon EKS](/media/QNVy79WE7NMY0dHNto1OhQTZHvqMMJFdtfHzTkFo.png)
![[re:Invent 2023 レポート] Expert 400 Session - Break down data silos using realtime synchronization with Flink CDC (Problem and Architecture)](/media/cEgRjcxTrlxSmwt9w64QDztKEal3sVblaQuB54QD.png)



