目次
大友(@yomon8)です。
データレイクやデータ分析基盤の取り組みを行っていると、企業内の様々なデータに触れることになるのですが、やはりいつもSAP ERPの話は出てきます。改めてSAP ERPに入っているデータの重要さを感じます。
ただ、せっかくクラウド技術を活用したデータ分析基盤が存在しても、SAP ERPのデータをロードして、持ってくるには一手間必要になります。
この記事ではデータ分析基盤として弊社のお客様からも評判の良いBigQueryにSAP ERPのデータをロードする手順をStepByStepでお伝えします。
手順としては、GCPのネットワーク構築からSAP ERP構築、そのSAP ERPのデータをBigQueryにロードするところまで一気に書きます。そして作業は全てブラウザ上で完結します(ブラウザ上でコマンドは打ちますが)。SAPに関わり早10年超えてますが、凄い時代になったなと自分でも感じます。この辺りも意識して見ていただけると面白いかと思います。
こちらにPandasを利用した簡易版も記事を書きました。

ソースコード
この手順で利用するソースコードは以下のGitHub上で全て公開してあります。
https://github.com/beex-inc/sap-dataflow-bq-sample
唯一、SAP ERPへの接続に利用するSAP Java Connectorは入れておりません。Sユーザを使って以下のノートに記載された場所からダウンロードしてください。
2786882 – SAP JCo 3.1 release and support strategy
やることの概要
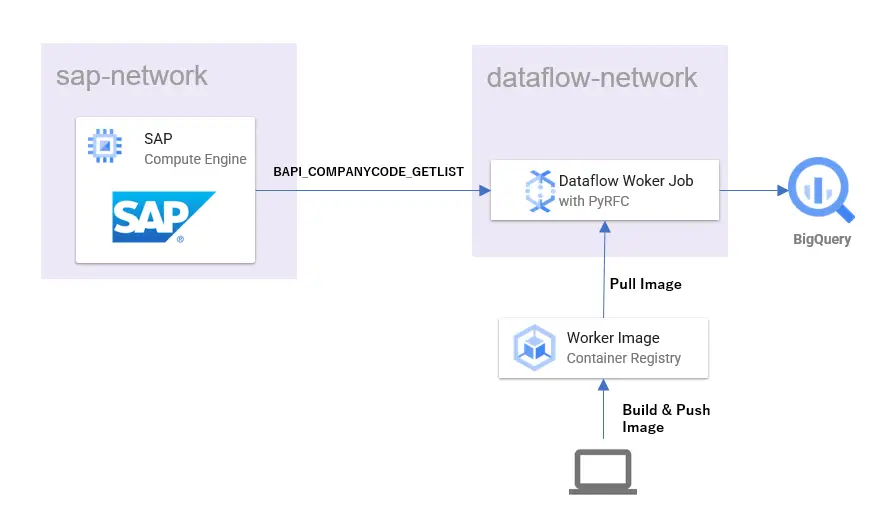
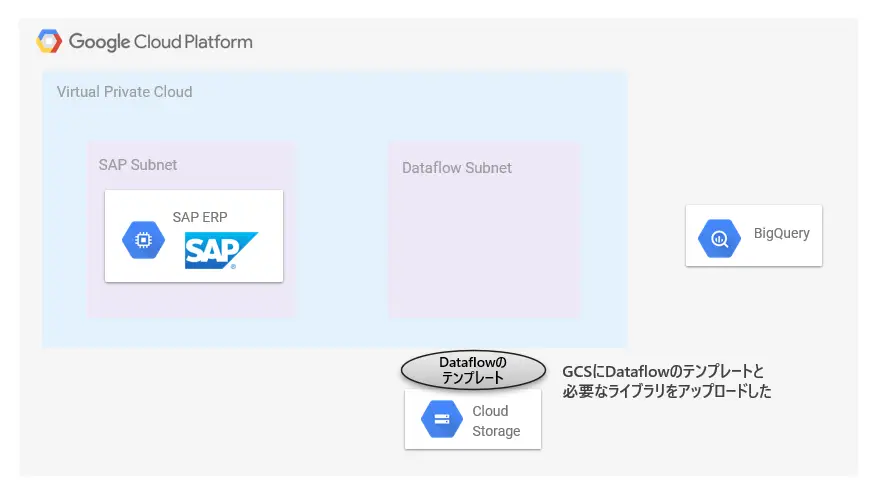
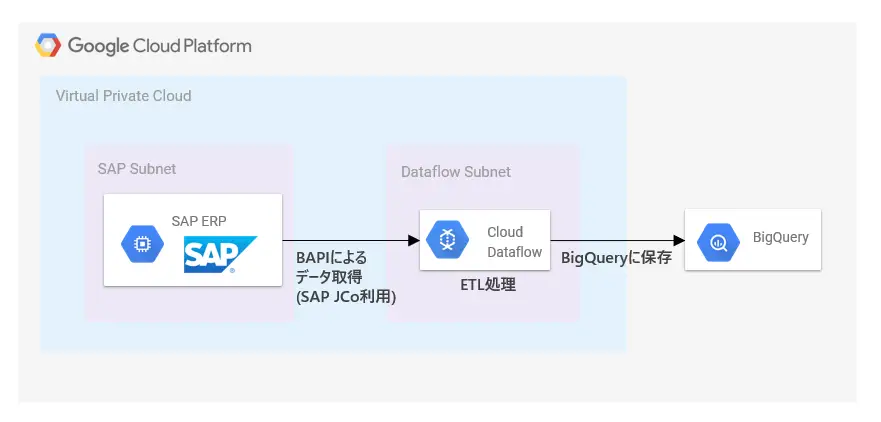
この記事でやりたいことはシンプルです。SAP ERPのデータをBigQueryにロードします。以下で言うとETL処理部分がメインになります。
Cloud Dataflow
SAPからデータを取得し、BigQueryにロードする処理で主に利用するサービスはCloud Dataflow(以下、Dataflow)です。GCPの提供するマネージドのデータ処理基盤です。
細かい説明はDataflowの公式ページから引用します。
- ・フルマネージドのデータ処理サービス
- ・処理を実行するリソースの自動プロビジョニングと管理
- ・リソース使用率を最大化する、ワーカー リソースの水平自動スケーリング
- ・Apache Beam SDK による、OSS コミュニティ ドリブンのイノベーション
- ・信頼性の高い一貫した 1 回限りの処理
開発に利用するApache Beam SDKのソースコードはGitHubで公開されており、困った時にはソース追って解決したりも可能です。また、公式のドキュメントもかなり充実していると思います。
https://github.com/apache/beam
SAPからのデータ抜き出し方
いくつか方法はあると思いますが、この記事では上にも書いたようにSAP Java Connectorを利用します。
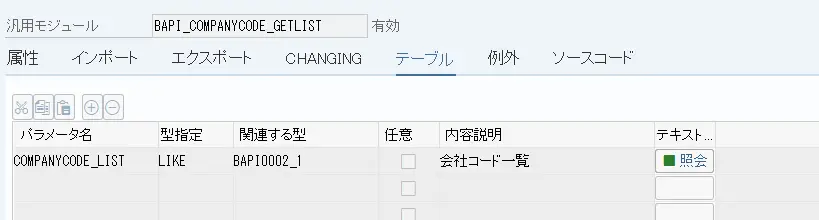
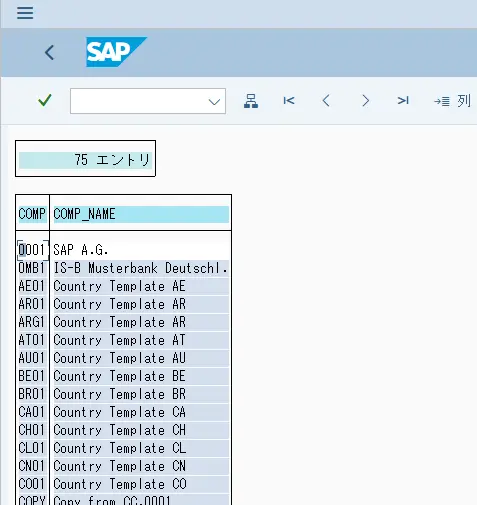
抜き出すデータはシンプルなものを選んで、「BAPI_COMPANYCODE_GETLIST」でリストを取得することにしました。
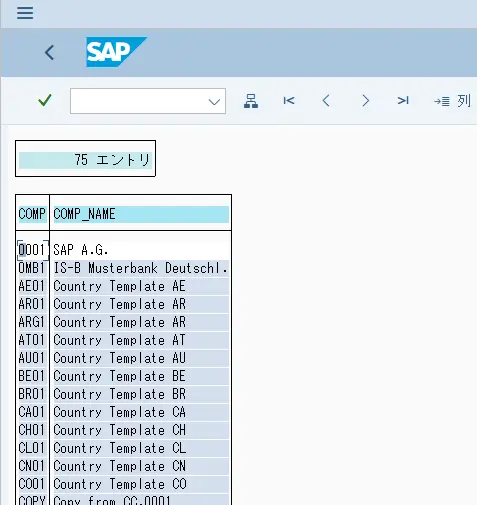
このBAPIを実行すると、以下のようにシンプルなリストが取得できます。これをBigQueryに入れてみます。
SAP JCoについてはこちらも参照してください。

実際に動かしてみる
ソースコードも公開しているので、それを使って動かしていきます。
作業前提
作業に必要なのは以下の3点です。前提さえ揃っていればブラウザで完結します。
- ・SAP CALが利用できるSユーザ
- ・検証に利用できるGCPプロジェクト
- ・ブラウザ
CloudShellの起動
ブラウザがあればOKというのは、GCPのCloudShellが利用できるからです。
GCPのコンソールの右上の方に以下のようなボタンがあるのでクリックします。
以下のようにLinuxターミナルが開き、作業用のマシンが起動されます。ここで作業を行います。
Gitリポジトリの取得
この作業で使うリポジトリをCloneします。
# 公開しているリポジトリをCloudShellローカルにCloneしますgit clone https://github.com/beex-inc/sap-dataflow-bq-sample.gitcloneが終わったら、ディレクトリを移動します。この後の作業はこのディレクトリで行います。
# この記事を通してここが作業ディレクトリとなりますcd sap-dataflow-bq-sample/ネットワークインフラの構築
SAP ERPを構築するネットワークもTerraformでコード化してあります。
gcloudコマンドで以下のように認証を取得する必要があります。
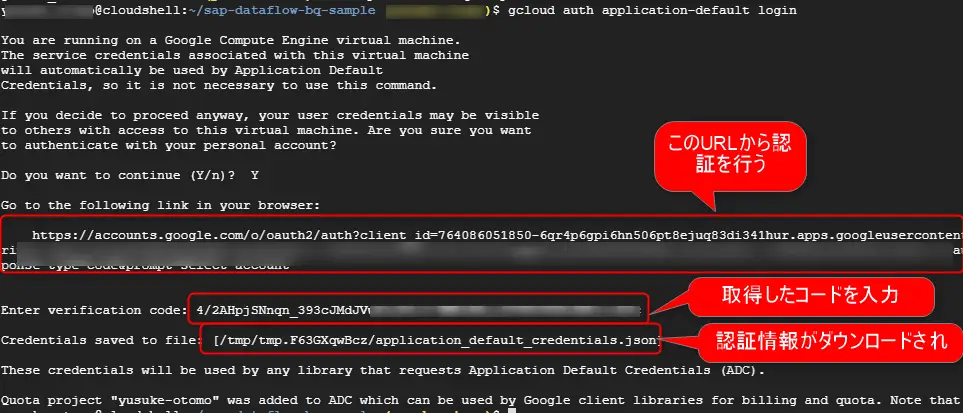
gcloud auth application-default login
表示されるURLに移動すると、以下のようにGoogleのアカウントでOAuth2の認可許可画面が出るので許可をします。コードが表示されるので、入力待ちになっているgcloudコマンド入力します。実際には「application_default_credentials.json」がダウンロードされて設定されるのでそれを利用した処理が可能になります。
 認証情報がダウンロードできたら、準備してある以下のスクリプトを実行します。
認証情報がダウンロードできたら、準備してある以下のスクリプトを実行します。
./bin/infra_setup.sh
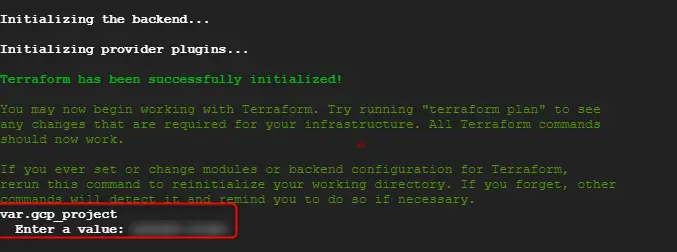
Terraformが動き出します。
以下のような画面でパラメータを問われるので、GCPのプロジェクトを入力します。
ここで作成されるのはVPC等のネットワーク関連と、BigQueryに空のデータセットが作成されます。
何を作っているか知りたい場合はこちらのファイルを確認してください。問題無ければYESを入力します。
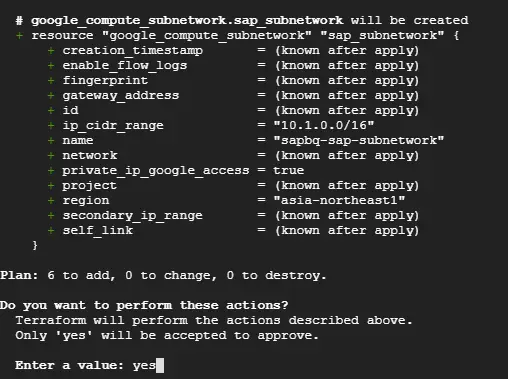
以下のように正常終了することを確認します。
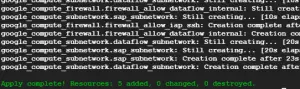 この時点で以下のようなVPCが構築されているはずです。
この時点で以下のようなVPCが構築されているはずです。

振り返り1
この時点の状態を確認しておきます。ネットワークと、BigQueryのデータセットが作成されました。

SAPの構築
ネットワークの構築が終わったので、そこにSAP ERPを構築します。といってもCALを使おうと思うので以下の手順の通りです。

ちなみに今回はこちらで構築してみました。
Advanced Modeを選択し、以下のようにTerraformで構築したネットワークを選択します。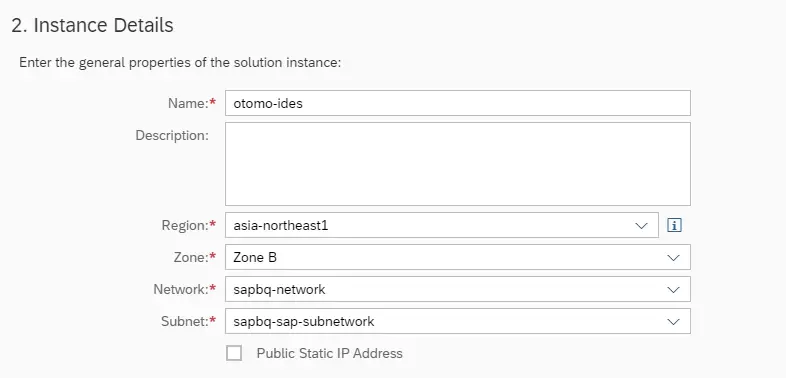 Firewallの許可もネットワーク内部からのみに制限します。
Firewallの許可もネットワーク内部からのみに制限します。
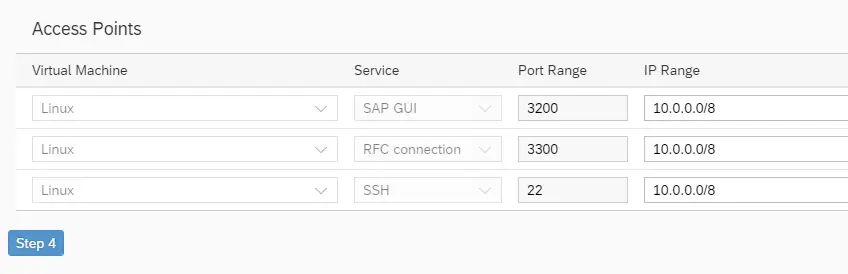 後はウィザードを完了して待ちます。SAPが起動してくると、外部IPが振られているのでこれも無効化します。
後はウィザードを完了して待ちます。SAPが起動してくると、外部IPが振られているのでこれも無効化します。
 そのままGCP Consoleから変更してしまいます。VM名をクリックして、編集モードにすると以下の変更ができるようになります。
そのままGCP Consoleから変更してしまいます。VM名をクリックして、編集モードにすると以下の変更ができるようになります。
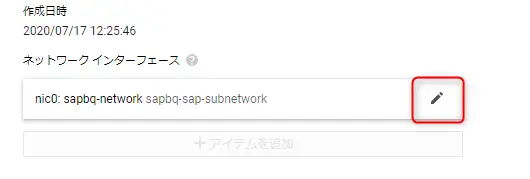
↓外部IPを「なし」に設定して保存します。
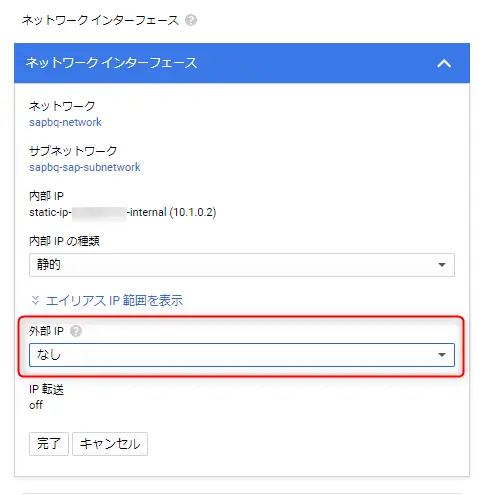
外部IPが外れました。

これでVMから見たら完全にプライベートになったわけですが、今回はCloud IAPを許可したネットワーク構成にしているので、以下のコマンドでログオン可能です。
※VM名やZoneは適宜変更してください。タブ補完できるので利用すると便利です。
gcloud compute ssh caltdc-xxxx-ssssss-linux --zone=asia-northeast1-b
sshでログオンしたらcurlでパブリックのサイトに接続できるか試してみます。
以下のようにGCPのAPIだけが利用できます。これは限定公開のGoogle アクセスというものです。今回は説明すると長くなってしまうので気になる場合はこちらなどをご覧ください。
# 繋がらないcurl https://www.beex-inc.com/ # 繋がらないcurl https://www.yahoo.co.jp/ # GCPのAPIは繋がるcurl https://bigquery.googleapis.com/discovery/v1/apis/bigquery/v2/restSAPを起動します。
# SIDはABAなのでabaadmを利用 sudo su - abaadm # SAPの起動startsap # dpmonでプロセスが起動していることを確認します dpmon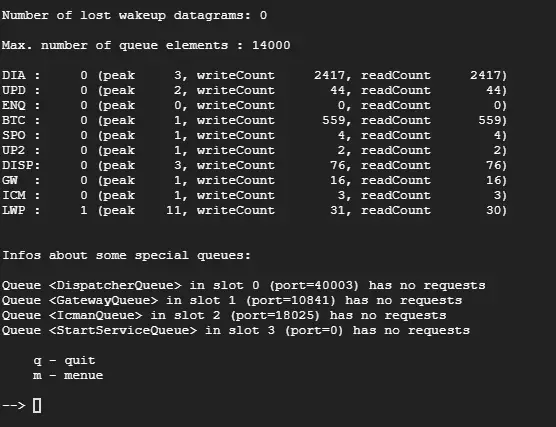
振り返り2
ここまでの作業での状態を確認しておきます。SAP ERPが準備できました。

Dataflowビルド・デプロイ
データソースであるSAP ERPと、データロード先であるBigQueryも準備できたので、ついにETL処理を作ります。
SAP JCoの準備
SAP JCoの準備をします。
※この手順を作る時間の7割はSAP JCo関連に費やしています・・
2786882 – SAP JCo 3.1 release and support strategy
以下がSAP JCoをダウンロードして解凍したフォルダですが、必要なのは「sapjco3.jar」と「libsapjco3.so」の2ファイルです。
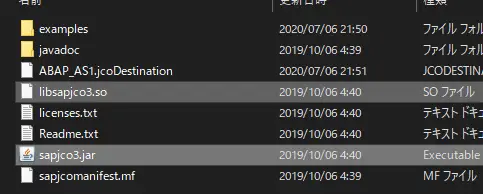
この2ファイルをCloudShellにアップロードします。CloudShellは便利でファイルのアップロードもブラウザから可能です。右上の3点リーダーから「ファイルをアップロード」を選択します。
アップロードされたファイルはHOMEに配置されるので、作業ディレクトリ直下のlibディレクトリに移動します。
# アップロードしたファイルを作業ディレクトリのlibフォルダに移動mv ~/sapjco3.jar ~/libsapjco3.so ./lib # ファイルが移動されていることを確認ls ./lib/libsapjco3.so sapjco3.jarDataflowテンプレートのステージング
SAP JCoがlibフォルダに配置できたら、Dataflowのジョブをビルド・デプロイしていきます。
今回はDataflowのテンプレートという機能を利用するので、ビルドしたArtifactをGCSに配置する必要があります。
利用するGCSを作成します。この手順では「otomo-sapbq-sample」というバケットを作成して話を進めていきます。
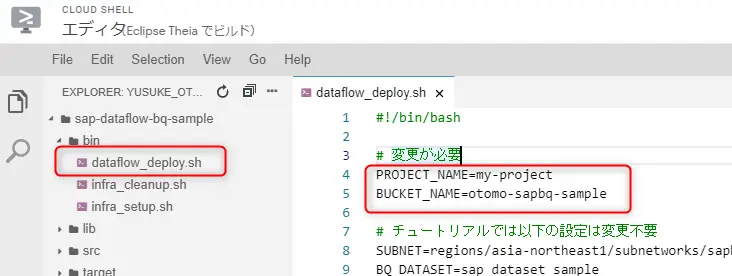
# バケットを作成gsutil mb -l asia-northeast1 gs://otomo-sapbq-sample次にデプロイ用のファイル ./bin/dataflow_deploy.shを編集します。CloudShellにはエディタまでついているのでこれを使います。
この手順では以下の2項目だけ変更で大丈夫です。
後はそのままスクリプト実行してデプロイします。必要なライブラリがダウンロードされるので5分くらいはかかります。
./bin/dataflow_deploy.sh
GCSにテンプレートのjsonがアップロードされたことが確認できます。

SAPJCoのステージング
通常はここまでの手順でデプロイは完了、Dataflowのジョブを実行できるのですが、SAP JCo周りの調整が必要です。
SAP JCoのを使う際に、今回一番大きな制約はSAP JCoのjarファイルはrenameが許可されていないことです。sapjco3.jarと違う名前のjarに纏めると実行できなくなります。Dataflowでデプロイされたjarファイルは別のIDを付けられて保存されるのでSAP JCoが動かなくなります。
ということで、自分でstaging環境に生のSAP JCoのファイルをそのままアップロードします。
# staging環境にSAPJCo関連のライブラリをアップロードgsutil cp ./lib/sapjco3.jar gs://otomo-sapbq-sample/staginggsutil cp ./lib/libsapjco3.so gs://otomo-sapbq-sample/stagingSAP JCoのための Dataflowテンプレートの調整
上記でステージングしたSAP JCoファイルを参照するように、Dataflowのテンプレートを変更する必要があります。
まずはテンプレートをダウンロードします。
gsutil cp gs://otomo-sapbq-sample/template.json .
テンプレートの中身を見ると、以下のようにSAP JCoの名前が別の名前にリネームされています。リネームされたSAP JCoは使うことができません。

ということで以下のように変更して、先程アップロードした元々の名前のSAP JCoを参照するように変更します。

これをアップロードします。
gsutil cp ./template.json gs://otomo-sapbq-sample/template.json
[オマケ]この項目が少し煩雑な作業が発生してしまいました。コマンドで済ませたい場合は以下のコマンド一本打ってください。テンプレートのSAP JCoの名前を書き換えます。
gsutil cp gs://otomo-sapbq-sample/template.json - | sed -e 's/\(.*\)sapjco3.*.jar\(.*\)/\1sapjco3.jar\2/g' | gsutil cp - gs://otomo-sapbq-sample/template.json
振り返り3
ここまでの状態の振り返りです。Dataflowを実行する準備が整いました。SAP JCoが無ければコマンド数本のはずなのですが、結構大変でした。
Dataflowジョブ実行
SAP JCoの調整も終わったのでやっとDataflowのジョブを実行できます。
以下のようにSAP ERPへの接続パラメータを付与してジョブを登録します。ジョブは先程修正したテンプレートを元に実行されます。sapPasswordの部分はIDESのドキュメントに記載されているパスワードにしてください。
※なお、今回は検証環境かつ単純化のために認証情報を引数で渡してますが、本来はSecret Mangerなどに保管して利用することをお勧めいたします。
gcloud dataflow jobs run otomo-sample-job-001 \ --region asia-northeast1 \ --disable-public-ips \ --gcs-location=gs://otomo-sapbq-sample/template.json \ --parameters sapAsHost=10.1.0.2,sapSysNR=00,sapClient=001,sapUser=idadmin,sapPassword=xxxxxx正常に起動すると以下のように表示されます。
Dataflowジョブの確認
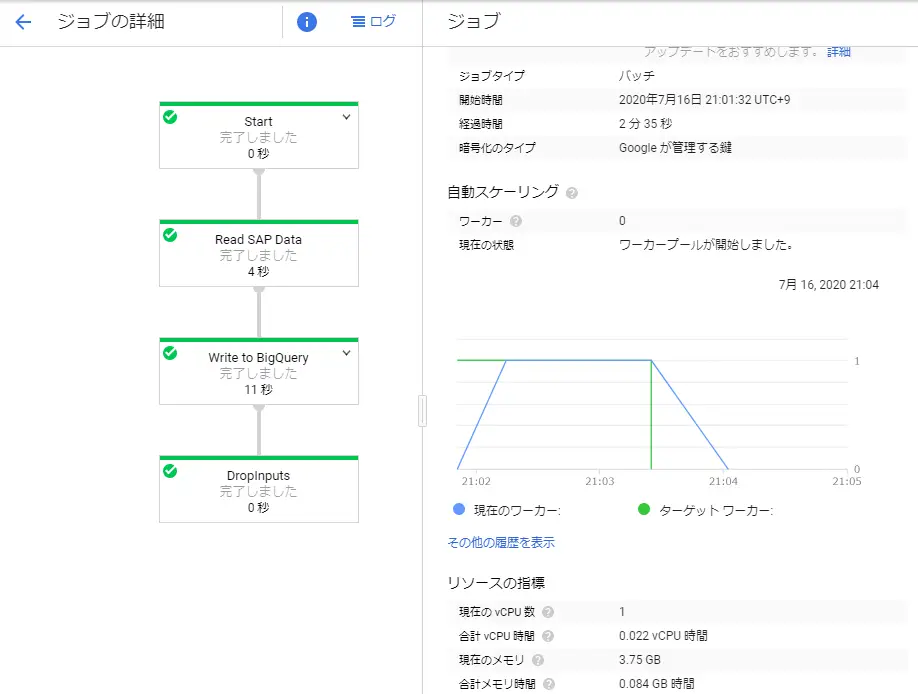
これで最初に貼りましたこの絵の処理が一通り動いたはずです。
DataflowのジョブはGCP Consoleから確認すると、以下のようにグラフィカルに進捗を見ることができます。
以下は全て正常終了した時の画面です。1CPU、3.75GBのインスタンスが1台立ち上がっていたことがわかります。秒単位の時間課金となります。
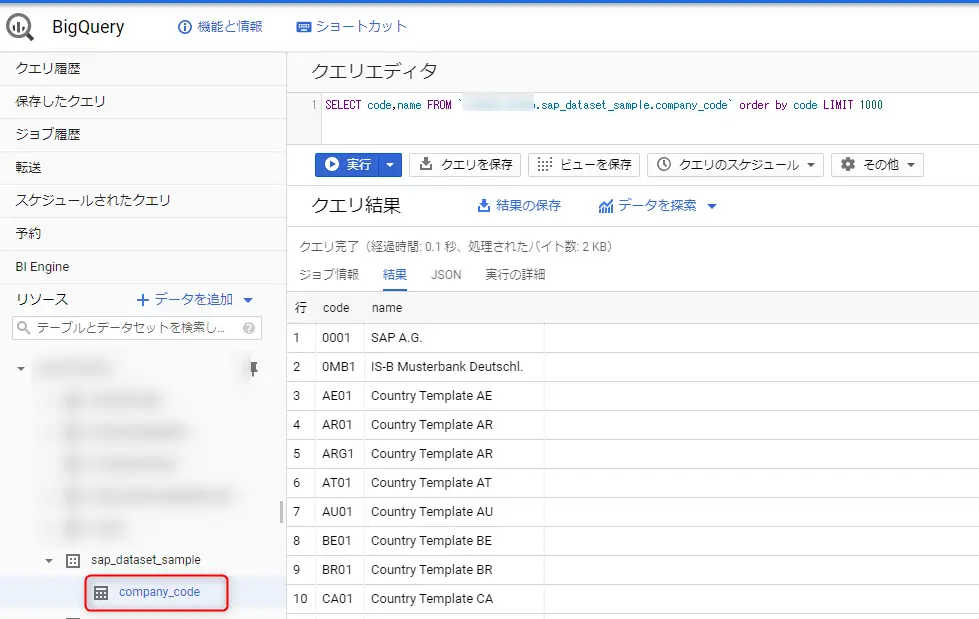
以下のようにBAPIの出力と同じデータがBigQueryでも確認できます。
環境のCleanup
CALで作成したSAP ERPはインスタンス画面の右上からTerminate可能です。
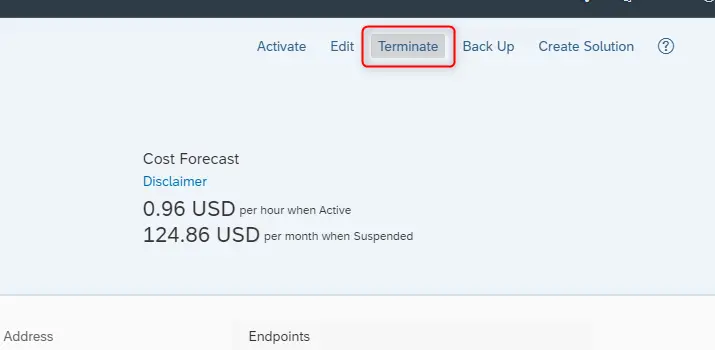 VMが完全に削除されるまで、暫く経ってから以下のスクリプトを実行することで、作成したBigQueryのテーブルとネットワークもTerraformから削除することが可能です。
VMが完全に削除されるまで、暫く経ってから以下のスクリプトを実行することで、作成したBigQueryのテーブルとネットワークもTerraformから削除することが可能です。
./bin/infra_cleanup.sh
さいごに
ここまで長い手順になってしまいましたが、ネットワーク構築からStepByStepで書いてきたことを考えれば、一昔前ならブログの一記事に収まる内容では無かったと思います。
また、今回はサンプルを作ってみたかったこともあり、DataflowからSAP JCoを直接利用していますが、別のプログラムでPubSubやGCSにデータを出力して、それをDataflowで読み取る方がシンプルな場合もあります。
そして、今回はBigQueryにデータを入れるところまでで切りましたが、この先は別記事でお話できればと思います。
また、実際の実装まで踏み込んで説明はできませんでしたが、その辺りはコードを直接見ていただければと思います。
https://github.com/beex-inc/sap-dataflow-bq-sample
- カテゴリー

この記事をシェアする
![[re:Invent 2022 レポート] Eli Lilly 社は SAP 移行と運用をどのようにしているのか](/media/fFfbMpbGNg2nfc7OLvAH31FZjKX4cTDjYAoevX3v.jpeg)