目次
先日、幕張メッセで開催されたAWS Summit Tokyo 2019にて弊社代表の広木よりこちらのセッションをご提供させていただきました。
セッションの後半では、Lift & ShiftにおけるShiftの一例としてデータレイクへの取り組みをご紹介させていただきました。
この記事では、セッションでは時間の都合上お伝えしきれなかった、細かい技術トピックについて、実際に手を動かしているエンジニア視点からポイントをいくつか書かせていただこうと思います。
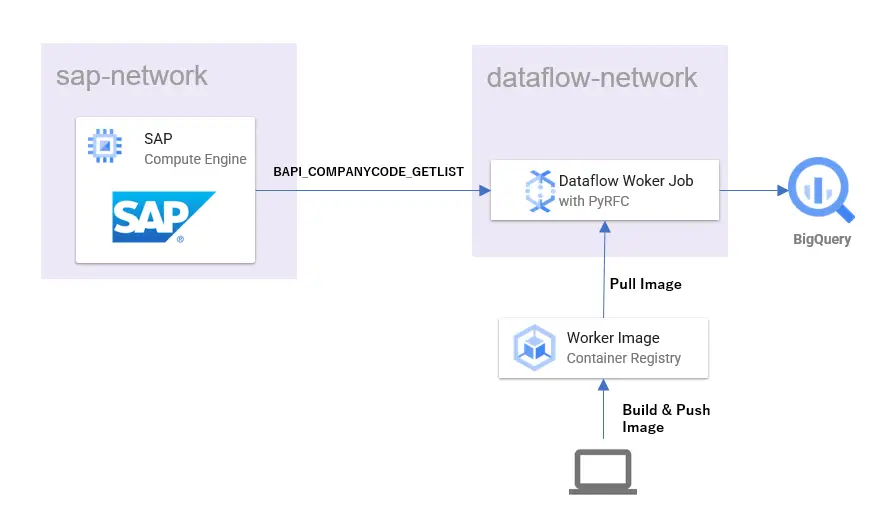
堅牢なVPC環境とPaaS系サービスの併用の難しさ
エンタープライズの環境では社外からのアクセスを制限した、堅牢なVPC環境を構築していることが多いと思います。
データレイクで利用されるPaaS系サービス(AWS GlueやAthenaやRedshift Spectrumなど)の中には、このようなVPC環境との組み合わせで利用しようとする場合、その利用に技術的な難しさがある場合があります。
一つ一つ説明すると長くなってしまうので、ここでは一般的な例を、一つ挙げたいと思います。
AWSによるデータレイクの中心となるサービスとして、S3があります。
例えばこのS3について、バケットポリシーを利用して、データへのアクセスを社内のVPC Endpointからのみ限定しているとします。
このような、ネットワークアクセス制限をかけているS3バケット内のデータをPaaS系サービスで分析しようとする時に問題が出る場合があります。
例えば、Athena、Redshift SpectrumやQuick Sightといったサービスは、VPC外に存在するので、サービスからS3にアクセスする場合もVPC外からのアクセスとみなされてしまいます。このようなアクセスはVPCからのアクセスに絞っているバケットポリシーによってアクセス拒否されてしまいます。
この例の場合、回避策の一つとしてAthena、Redshift SpectrumやQuick Sightなどで利用するIAMロールを、以下のリンクにあるような方法でバケットポリシーから除外する方法があります。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/quicksight-deny-policy-allow-bucket/
このような、PaaS系サービスの利用におけるネットワーク起因の問題は、手元に環境が無く、ネット上の情報も少ないために、根本原因解明までの調査は困難を極めます。
この点はセキュリティ要件の高いエンタープライズの環境で、データレイクを構築するのに避けては通れないポイントだと考えるので、挙げさせていただきました。
基幹システムのデータ特性に合わせたインプット方法
データレイクの活用例として、良く紹介されているセンサーやログのデータは、新しいデータをデータレイクに追記していうことで、要件を満たせる場合が多いと思います。
しかし、基幹システムで利用される業務データは単純なデータの追記では対応できないものがほとんどです。
例えば、締め日までには変更が随時入る伝票データなどを考えてみます。削除についても論理削除が多くなります。このようなデータは、追記ではなく、ある単位でのデータ洗い替えをするといった工夫が必要になってきます。
しかし、AWS Glueで提供されているSparkのフレームワークあるDynamicFrameでは、本記事執筆時点では追記にしか対応しておらず、更新系の処理には対応していません。このような場合、DynamicFrameに頼らずDataFrameも活用したETL処理の開発が必要になってきます。例えば特定のパーティション配下を更新するための手法の一例として、以下の記事で書いています。

金額計算に必要なDecimalをGlueで扱い場合の注意点
ご存知の通りFloatやDoubleといった浮動小数点数の計算には誤差が生まれるため、金額などのデータの型にはDecimalが使われていることが一般的です。幸いデータレイク上で保管されるファイルの形式のParquetはDecimal型をサポートしています。
ここで注意点があります。AWS Glueで利用されるSparkのフレームワークである、DynamicFrameでは、Decimalを扱う際の制限がありますので注意が必要です。

AWS Glueにグラフィカルなワークフローが追加された
ここまでエンタープライズでデータレイクを使うにあたり、難しい部分を挙げてきましたが、AWSサービスも日々機能改善がされています。ここでは、先日のAWS Summitで発表されたワークフロー機能をご紹介します。
AWS Glueでは、ファイルの中身を調査するCrawler、SparkによるETL処理や、Pythonスクリプトを実行できるジョブ、それらを起動するためのTriggerなどの複数コンポーネントの連携が必要になります。
従来はコンポーネント間連携を行うためにも、CloudWatchイベントやLambdaを使って構築する必要があったため、複雑な構成に陥りがちでした。
新機能のワークフローを使うことで、コンポーネント間の連携を、GUIを利用して定義したり、実行状況の追跡が行えるようになりました。
多様なシステム、データが入ってくるデータレイクだからこそ、柔軟なワークフローの構築や、ETLの実況状況の追跡の観点から嬉しいアップデートです。
以下の記事を読んでいただければ、どのような機能なのかイメージを持ってもらえると思います。

所感
実際にデータレイクのプロジェクトを進めていると、企業内のデータの話がどんどん集まってくるのですが、本当に多様なデータが存在していることに驚かされます。
ここで言うデータの多様性は、巨大なDBに入っているとか、大量のカラムがあるCSVであるなどの技術的な部分に留まりません。それぞれのデータには、それぞれのデータの意味や経緯があり、そのデータを持っているオーナーがいて、データをデータレイクに入れるには、今後の展望や思いがあります。
そういうことを勉強させていただきながら一緒にプロジェクトを進めていけることに、エンタプライズデータレイクのプロジェクトの面白さがあると感じています。
本記事ではエンタープライズデータレイクにおける、技術的トピックと、その背景について簡単に書かせていただきました。
長文最後までお読みいただきありがとうございました。

この記事をシェアする
![[re:Invent 2022 レポート] Eli Lilly 社は SAP 移行と運用をどのようにしているのか](/media/fFfbMpbGNg2nfc7OLvAH31FZjKX4cTDjYAoevX3v.jpeg)