












目次
Introduction
AWS Re:Invent のセッションの内容を受けて、実際に使ってみた内容をレポート形式で投稿します。
今回は Tabular 社が登壇された LT 枠のセッション How to build a platform for AI and analytics based on Apache Iceberg に対するレポートと検証内容を示したものとなります。

Description
Apache Iceberg has become the de facto table format standard. In this talk, hear the cocreator of Iceberg describe an AWS reference architecture for analytics and Al, based on an Iceberg-based table store in Amazon 53 that connects compute services such as Amazon Redshift, Amazon Athena, Amazon EMR, and Amazon SageMaker and includes streaming support via Amazon Kinesis, Kafka, and Flink. Universal compatibility is provided by the Iceberg table spec and REST catalog protocol, and capabilities such as cost and performance optimization and RBAC security is provided by Tabular's managed Iceberg service. Also, learn best practices for implementing this architecture. This presentation is brought to you by Tabular, an AWS Partner.
Apache Icebergは事実上のテーブルフォーマットの標準となっている。この講演では、Icebergの共同開発者が、Amazon S3のIcebergベースのテーブルストアをベースに、Amazon Redshift、Amazon Athena、Amazon EMR、Amazon SageMakerなどのコンピュートサービスを接続し、Amazon Kinesis、Kafka、Flinkによるストリーミングサポートを含む、分析とAlのためのAWSリファレンスアーキテクチャについて説明します。Icebergテーブル仕様とRESTカタログプロトコルによってユニバーサルな互換性が提供され、TabularのマネージドIcebergサービスによってコストとパフォーマンスの最適化、RBACセキュリティなどの機能が提供されます。また、このアーキテクチャを実装するためのベストプラクティスもご紹介します。このプレゼンテーションはAWSパートナーであるTabularがお届けします。
What is Apache Iceberg ?
セッションの流れは以下となっていました。
 Iceberg は Netflix 社により開発され、現在では Amazon EMR 、Presto / Trino (Athena etc.) クエリエンジン、Amazon Redshift 、Snowflake 等でサポートされる Open Table Format の位置付けとなります。
Iceberg は Netflix 社により開発され、現在では Amazon EMR 、Presto / Trino (Athena etc.) クエリエンジン、Amazon Redshift 、Snowflake 等でサポートされる Open Table Format の位置付けとなります。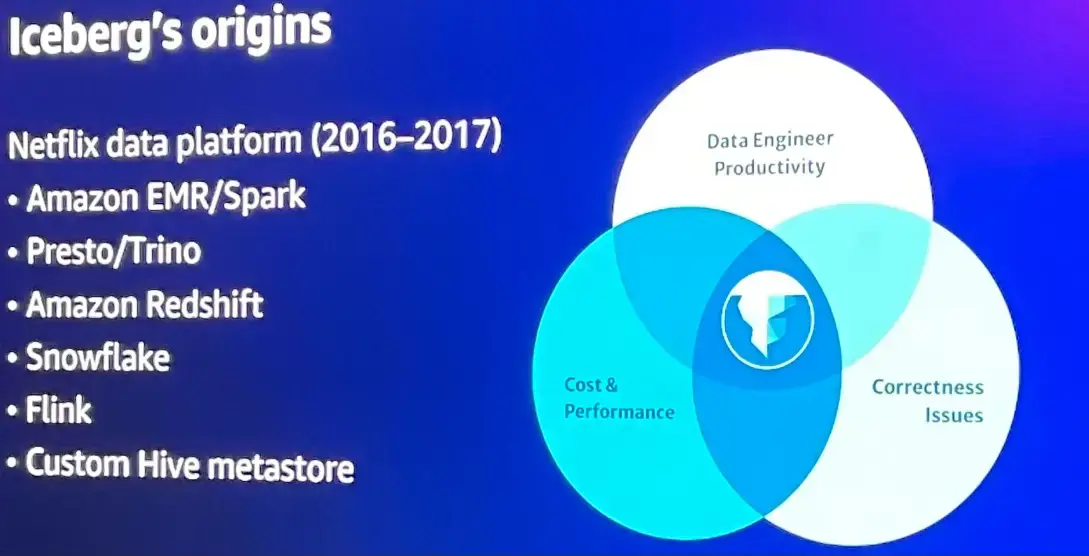 Iceberg は、以下の特性を持つと言います。
Iceberg は、以下の特性を持つと言います。
- S3 上のデータセットから構成が可能であること。
- ACID の特性を保有し、トランザクションとして機能すること。
- Merge into が利用可能である。
- Time travel クエリの利用が可能な事により特定地点の過去データへのアクセスが可能となる。
- Hidden Partitioning という明示する事なくテーブル上のパーティション値を自動生成するため高速にクエリを利用できる。
- Compaction により、蓄積されたデータファイルを圧縮する事が可能

Tabular on AWS
ここから Tabular on AWS の内容となります。
Tabular は、Iceberg テーブルに基づくデータウェアハウスストレージを提供し、多くのクエリエンジンやフレームワークへの接続を容易にします。ここでは、Tabluar on AWS を使用した場合の AWS マネージドサービスと Tabular の関係性を示しています。
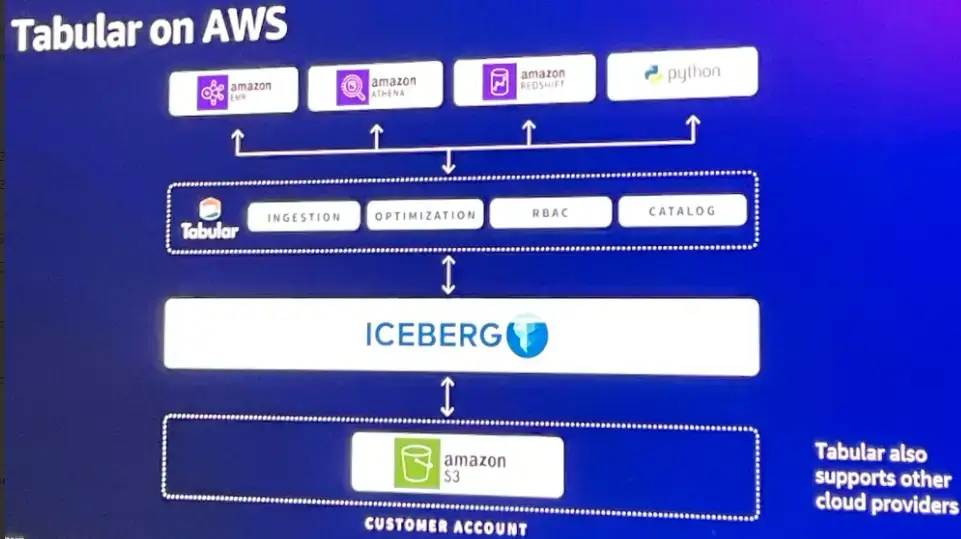

Try Tabular Product
Session 参加後に Thank you mail の案内に含まれた Tabular の Free Trial を実際に使用してみました。本稿は、以下を参考に検証した履歴となります。
* Tabular Product Demo
こちらの Demo は、非常にシンプルであり、Tabular から Cloud formation を利用し、AWS S3 IAMロールを作成し、S3 と Tabular 上の Iceberg テーブルが接続を行うものです。
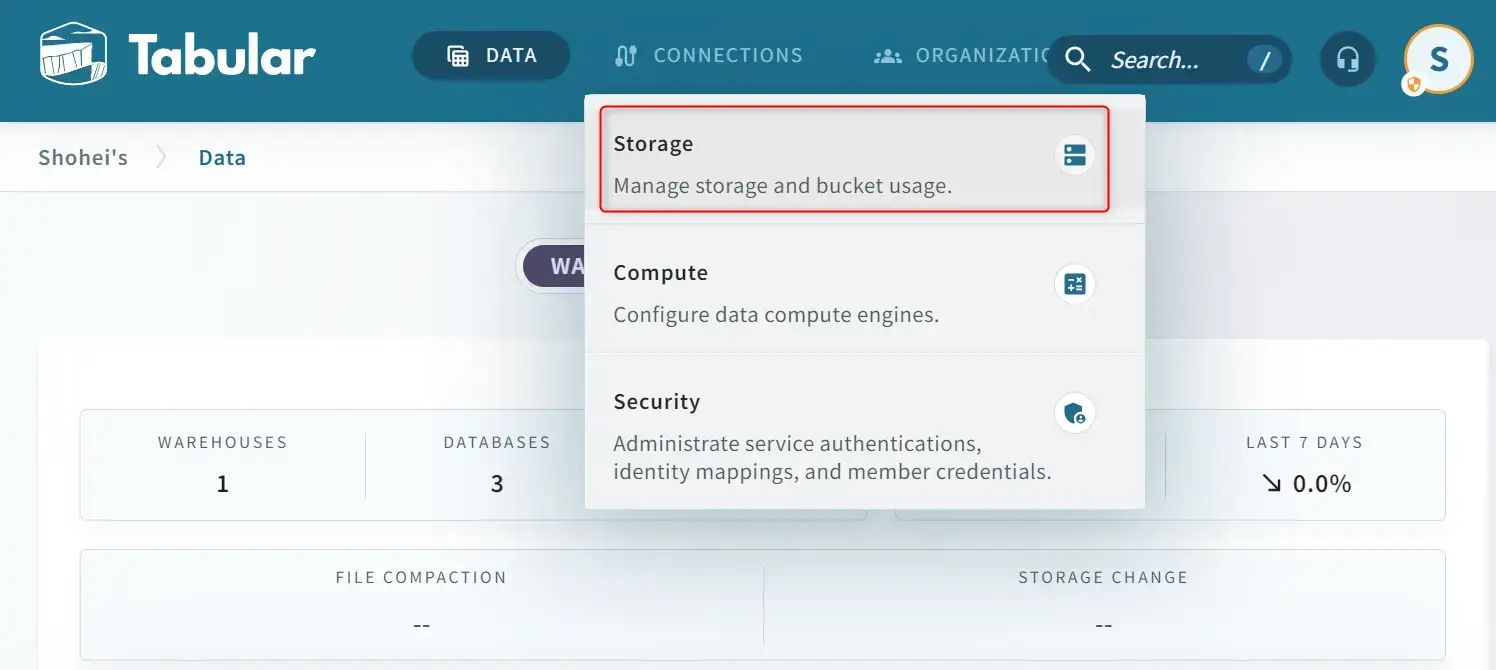
Tabular への ログイン画面 から Storage を選択し、Amazon S3 を選択します。
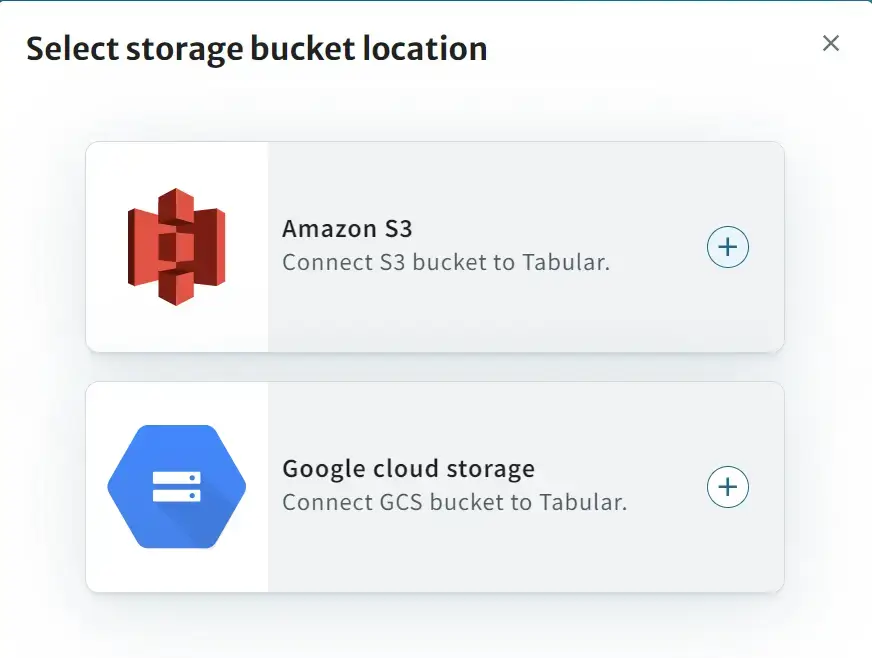
作成するリージョンを選択後、S3 を作成する AWS アカウントへログインを行うと、Cloud Formation Stack のクイック作成リンクへと遷移します。ここで指定するパラメーターは特に変更を行いません。
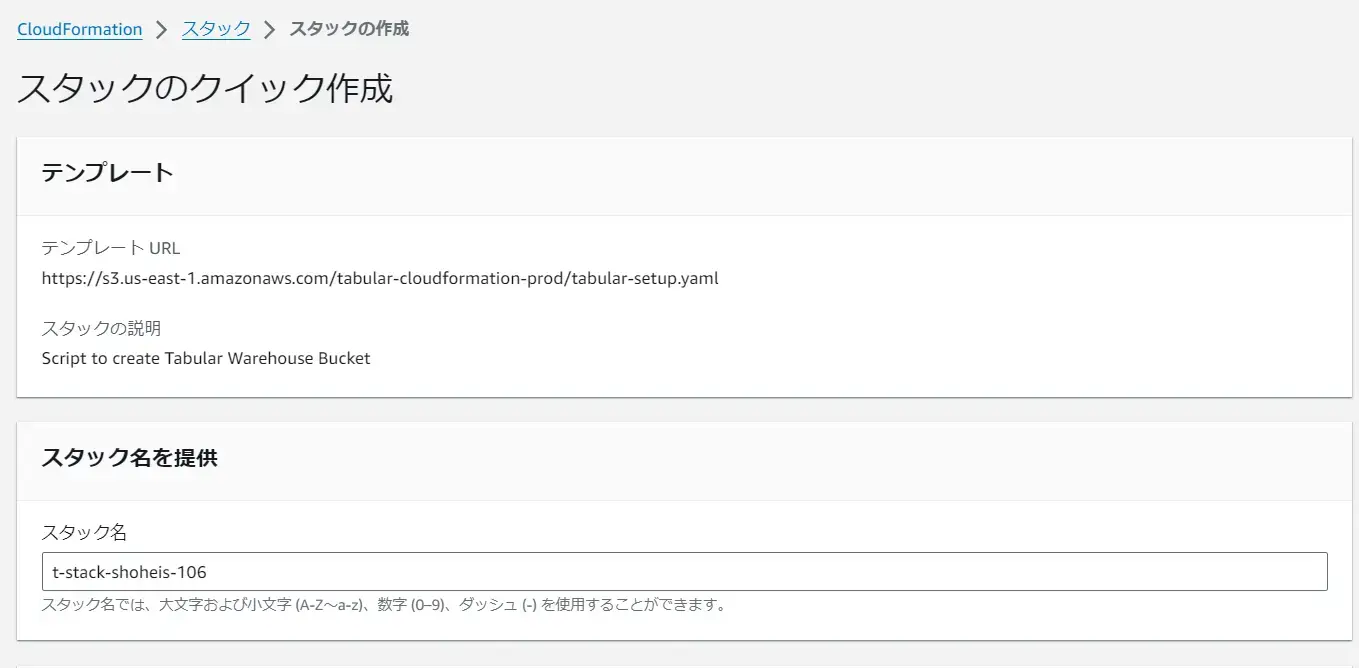
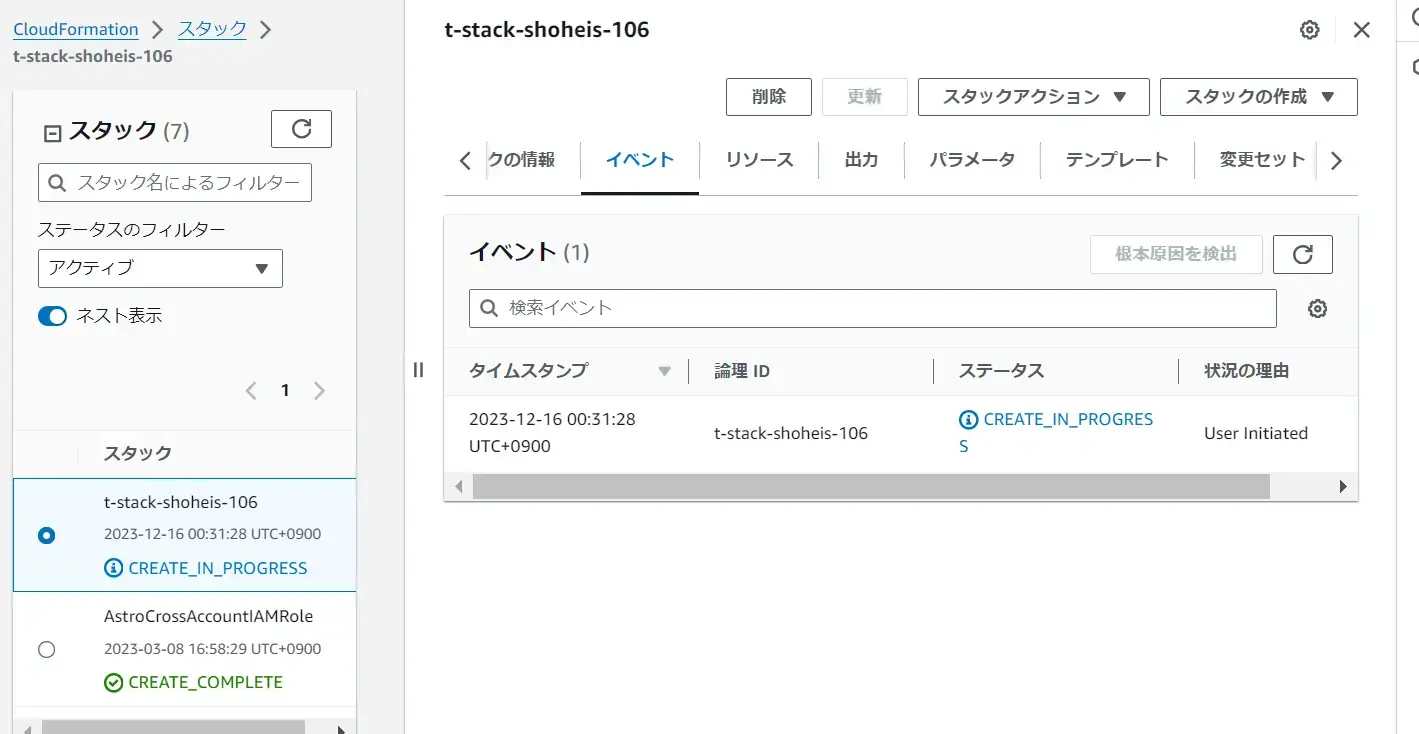
作成が完了すると、Tabular の画面上に Cloud Formation の出力から作成された S3バケット名、IAM role の Arn を入力します。Bucket のアクセス権はデフォルトの EVERYONE とします。
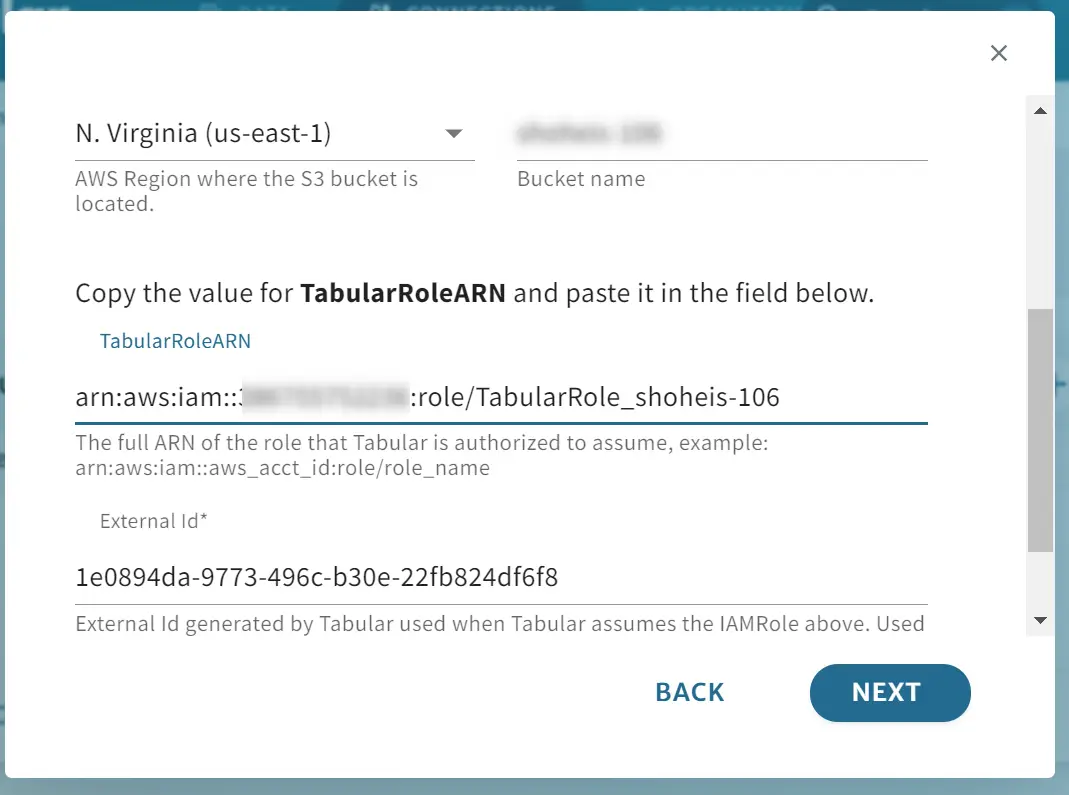

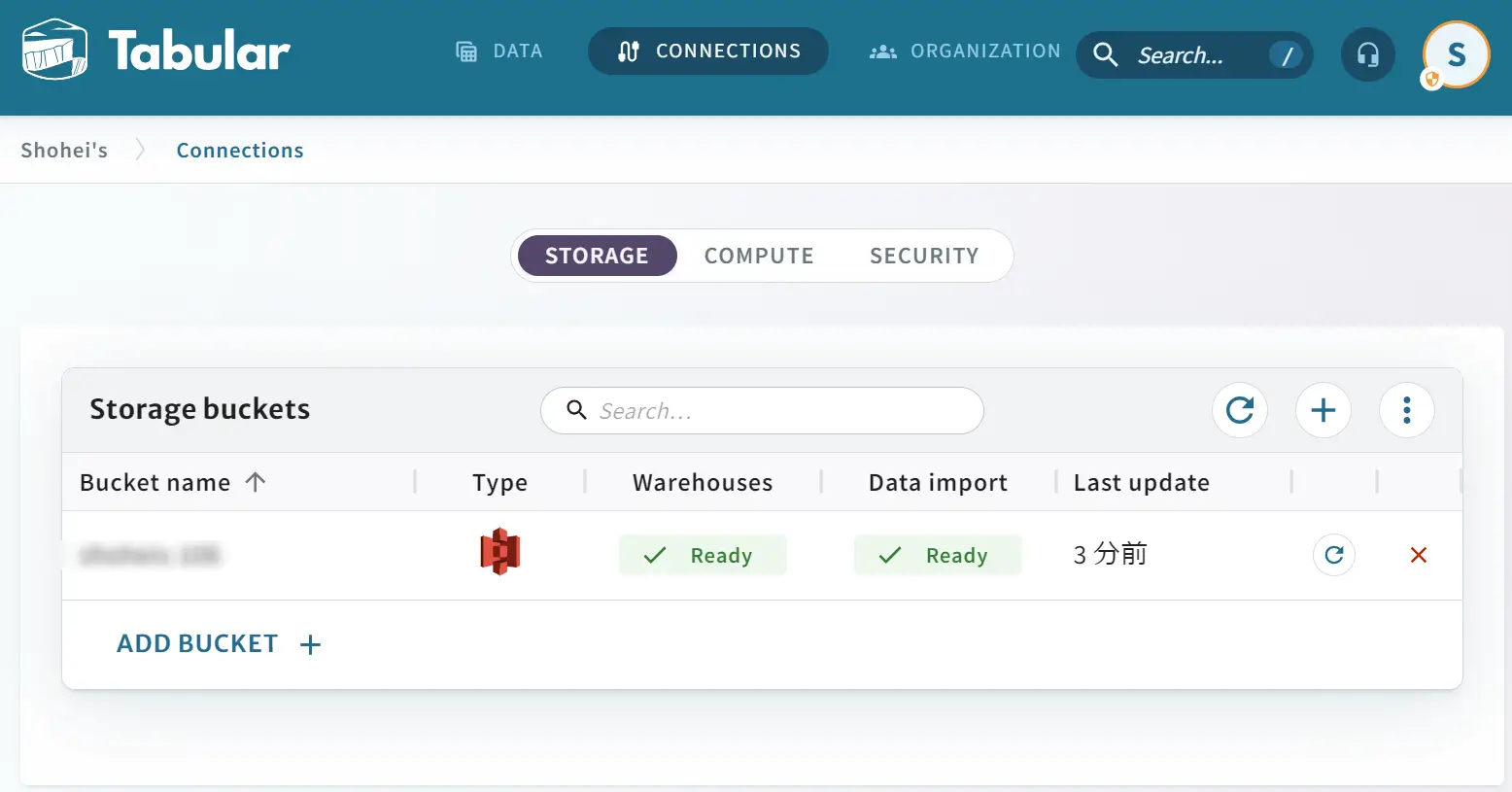
これにより Tabular 経由から作成された S3 バケットが確認出来ました。
続いてWarehouse をTabular 上で作成します。storage bucket の項目へ先ほど作成した bucket を選択します。
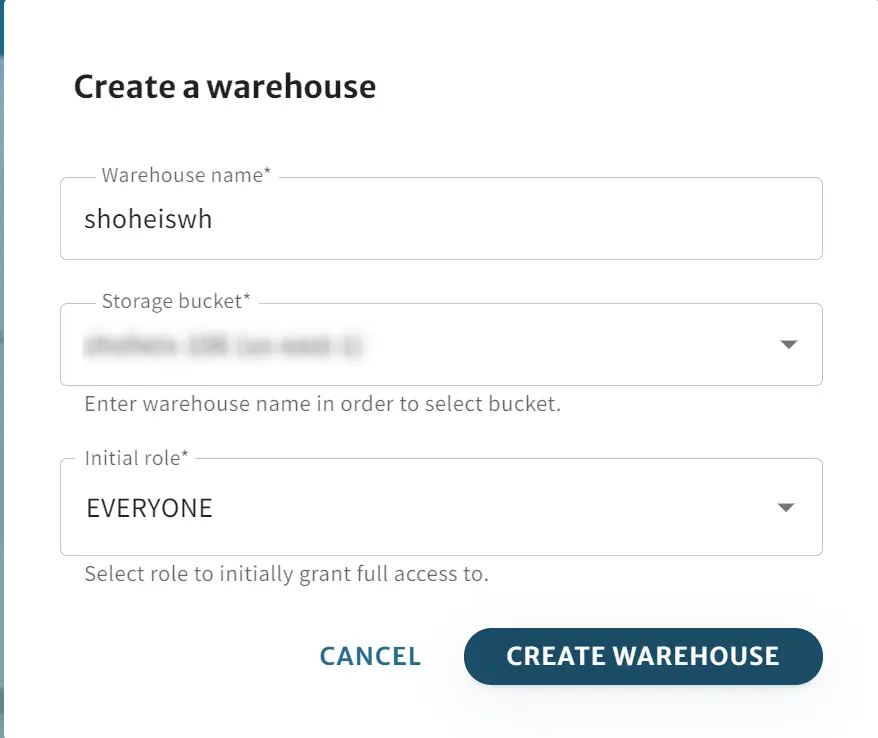
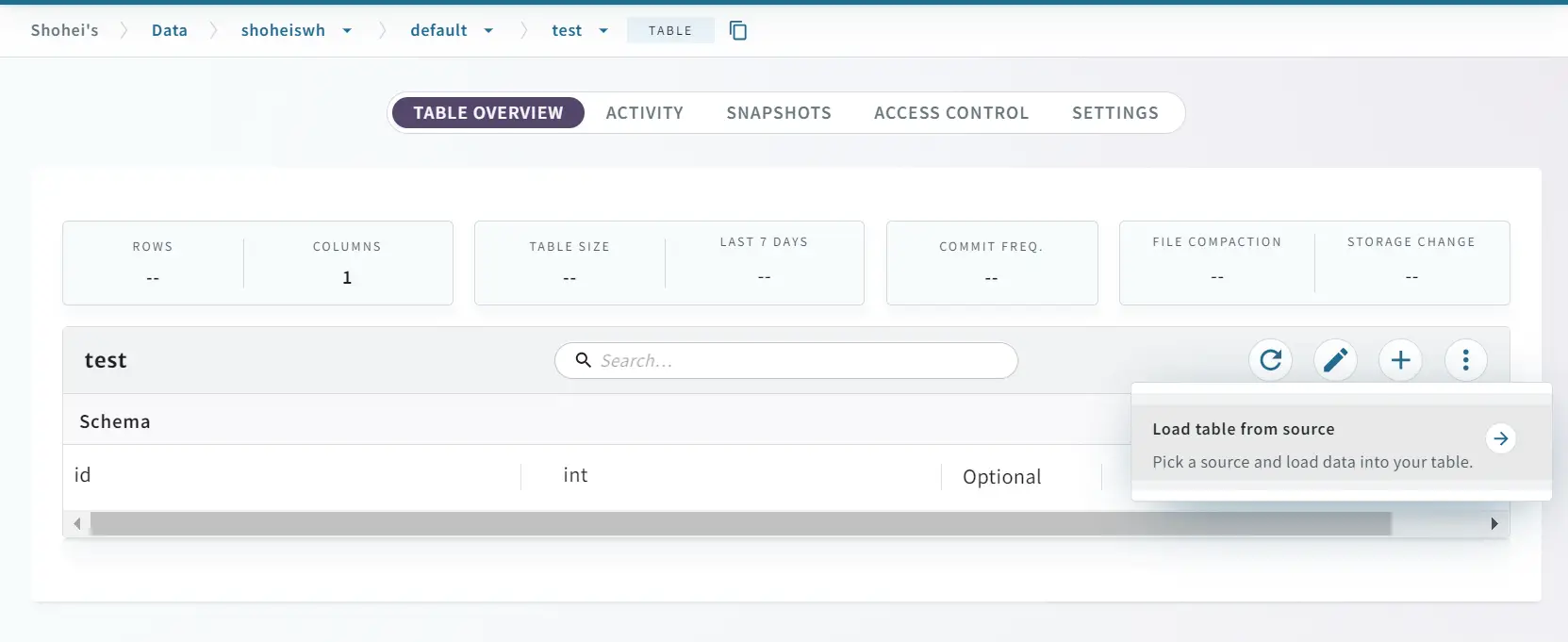
Warehouse の作成が完了すると、続いて default データベース上にテーブルを作成していきます。demo の内容同様に id を int 型でスキーマ定義します。
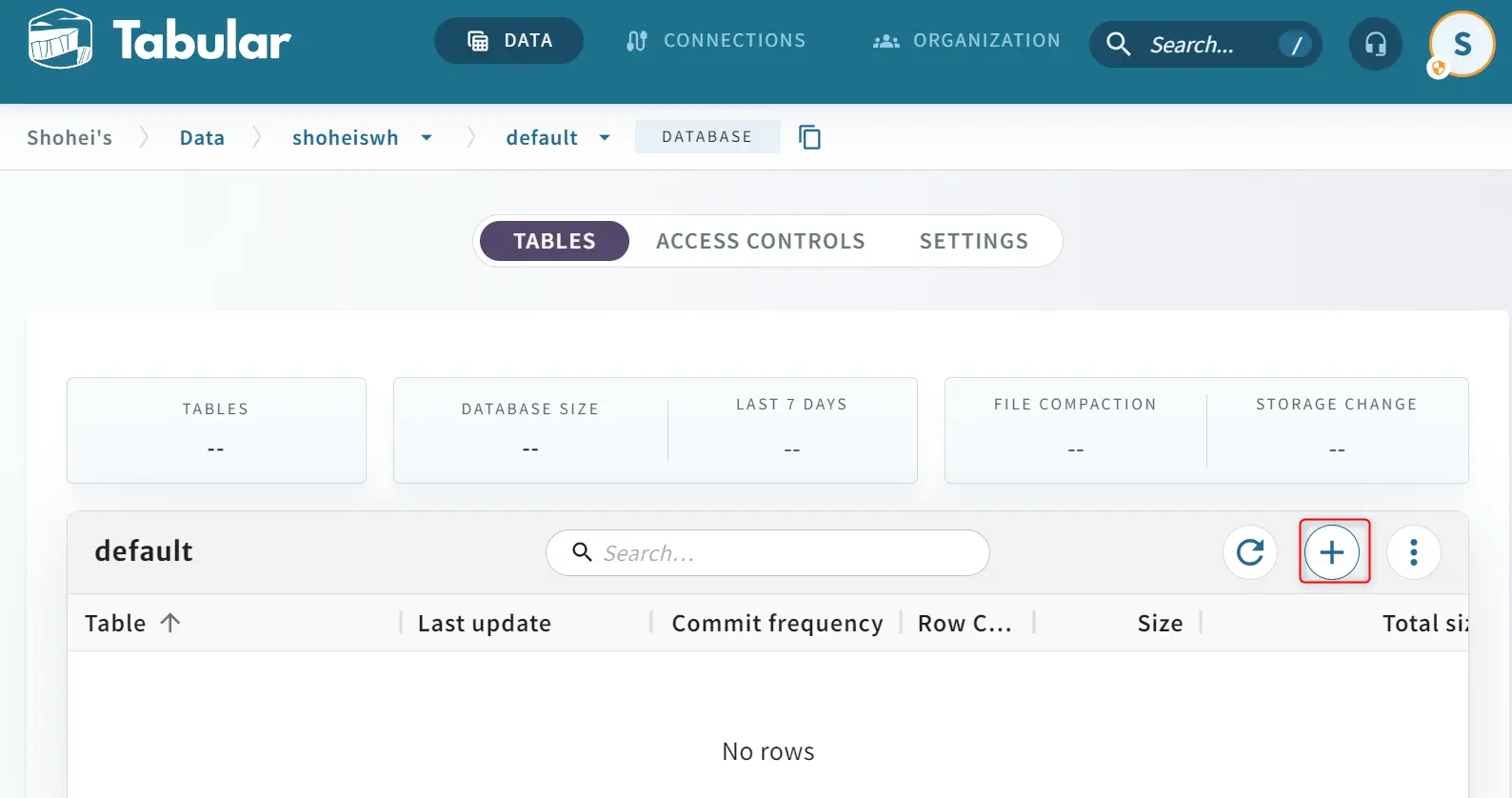
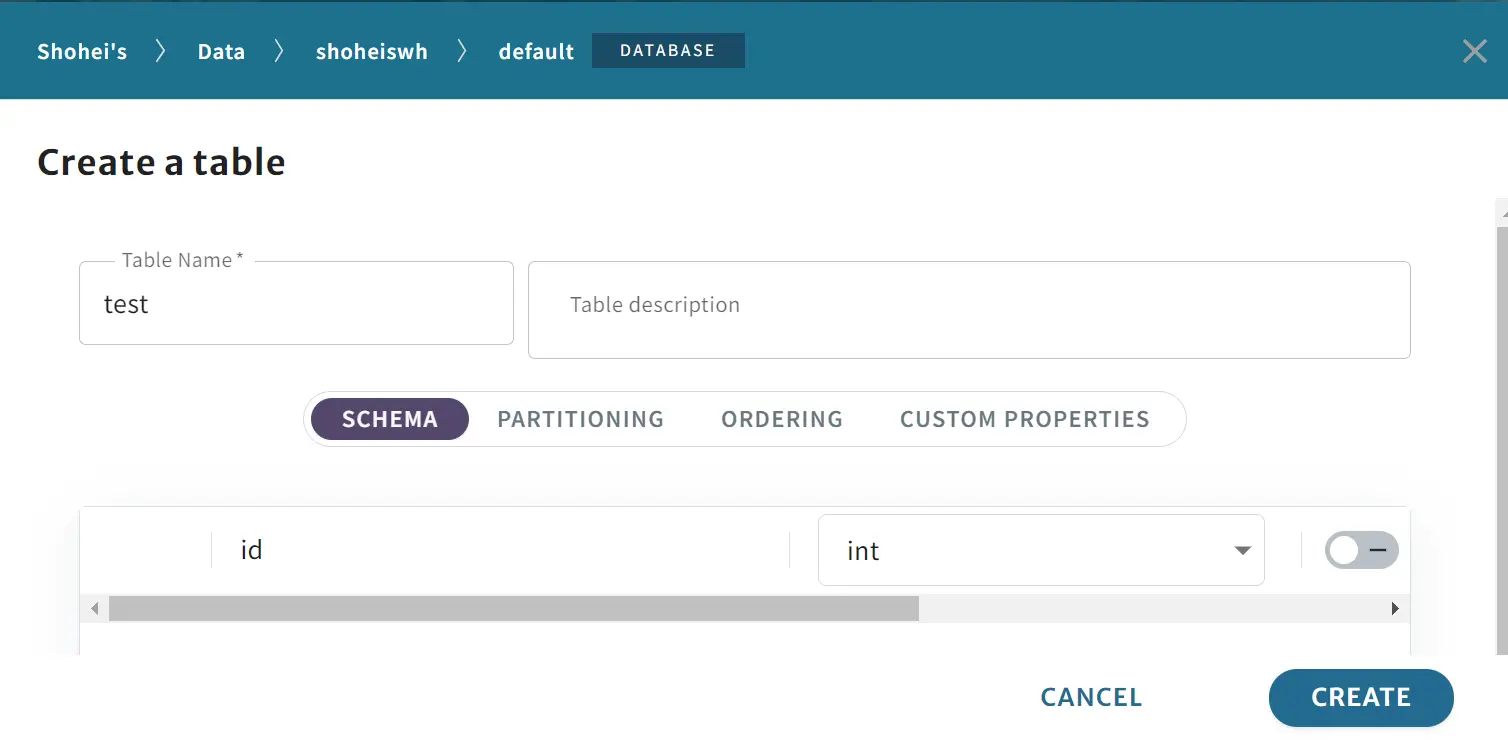
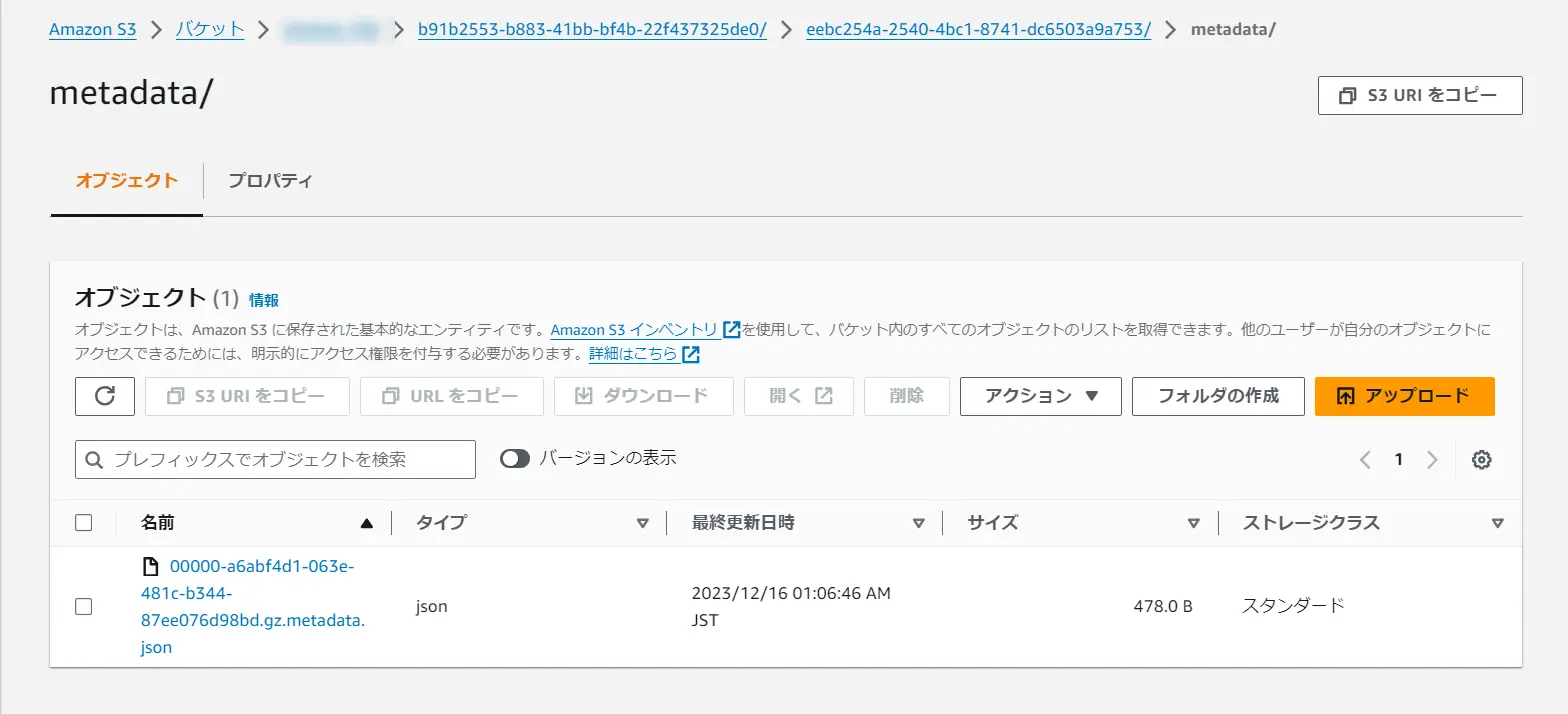
作成が完了すると、作成したバケット側で metadata フォルダが生成されている事が確認出来ます。
ここから実際にデータを Load してみます。今回は id 列に3行追加する csv ファイルを用意して、アップロードします。その際に処理方法を指定してます。今回は fileloader.write-mode として append を選択しています。
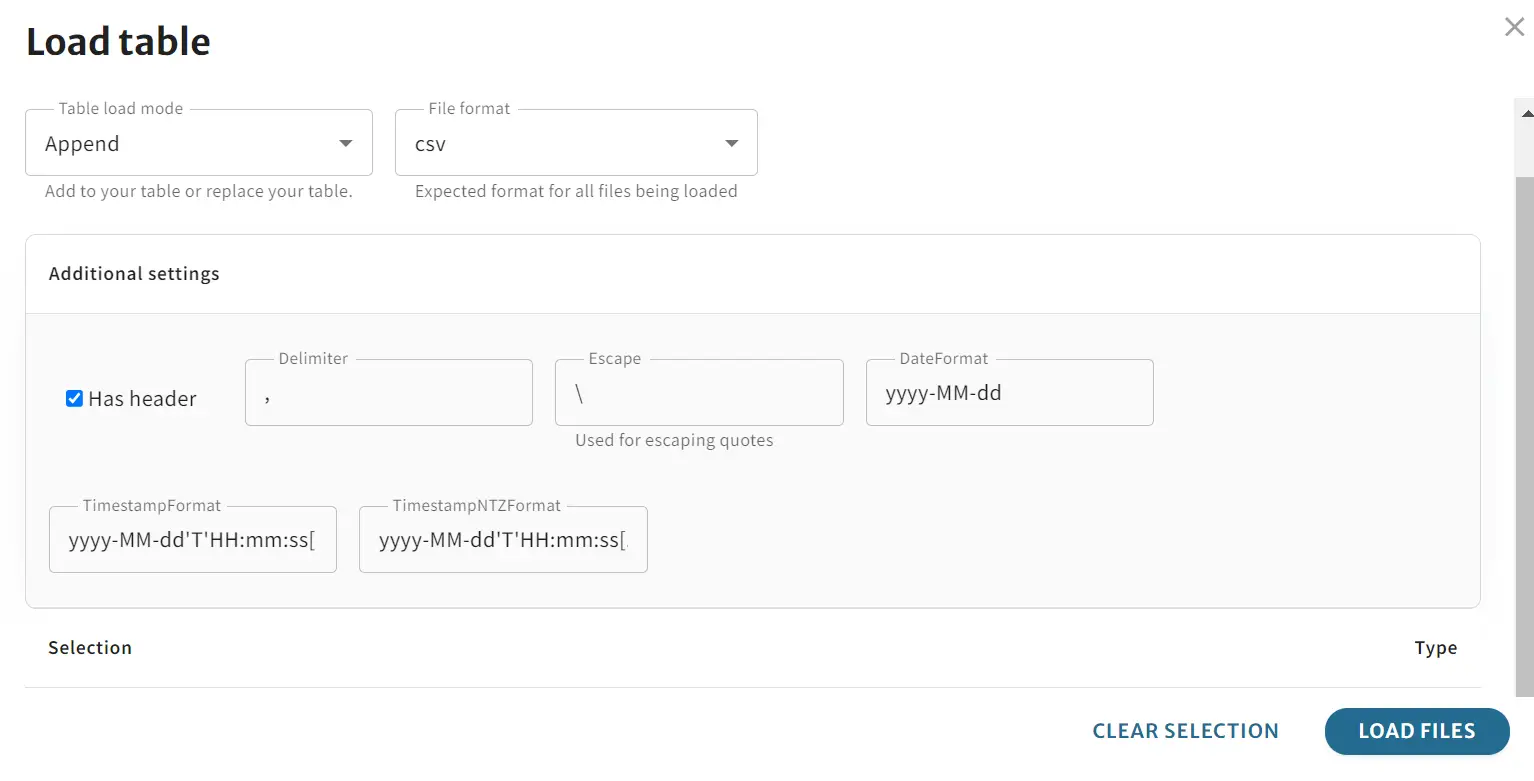 ここまでがデモの内容です。
ここまでがデモの内容です。
Connection Iceberg Table
ここから実際に Iceberg テーブルへ接続します。今回は Athena for Pyspark を使用して接続を試みます。
https://docs.tabular.io/athena-pyspark
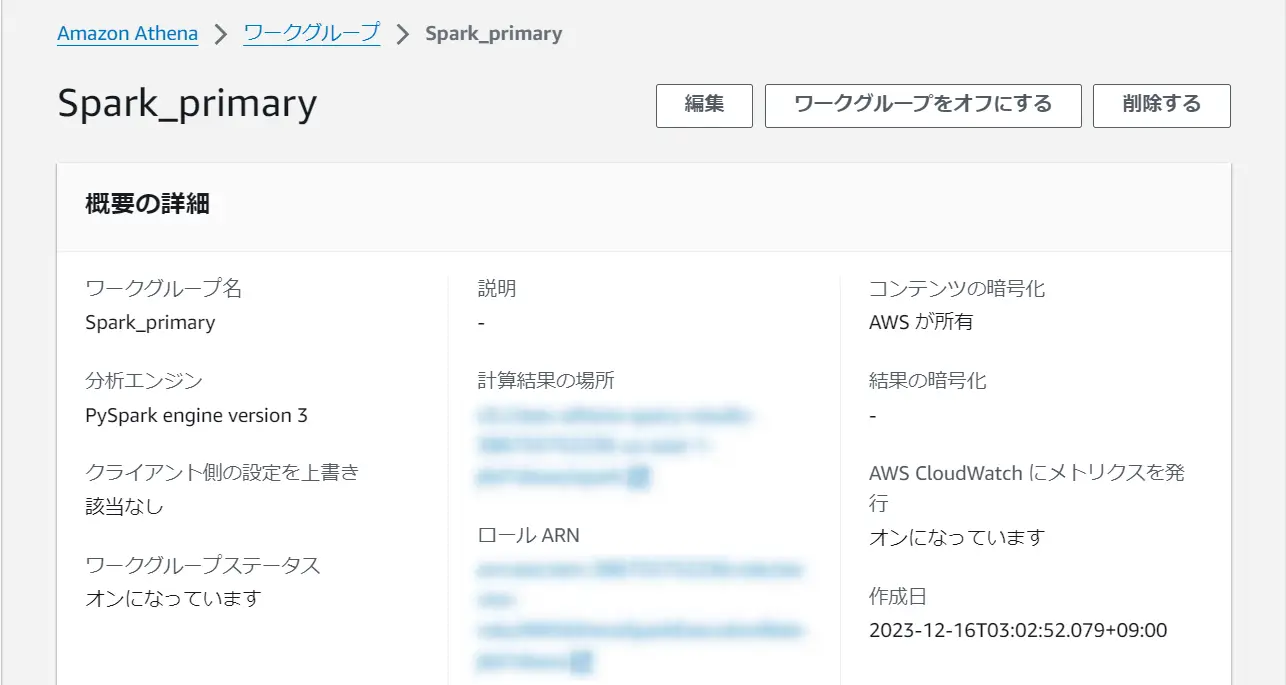
Athena 上で Spark 用のワークグループを作成し、エンジンを PySpark v3 で設定します。ノートブックエディタからノートブックの設定を行います。
その後、Tabular 側で AWS IAM role Mapping の設定を実施して、Athena ノートブックエディタの画面から操作していきます。
最初に、spark カタログの構成 をノートブック作成時にJSON形式で入力し、対象の warehouse などの情報をセットします。
{
"spark.sql.catalog.<warehouse>": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<warehouse>.catalog-impl": "org.apache.iceberg.rest.RESTCatalog",
"spark.sql.catalog.<warehouse>.credential": "<credential>",
"spark.sql.catalog.<warehouse>.uri": "https://api.tabular.io/ws/",
"spark.sql.catalog.<warehouse>.warehouse": "<warehouse>",
"spark.sql.defaultCatalog": "<warehouse>",
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"
}このあと、マジックコマンドで SQL を実行し、データベース名が返ってきたら、接続が成功しています。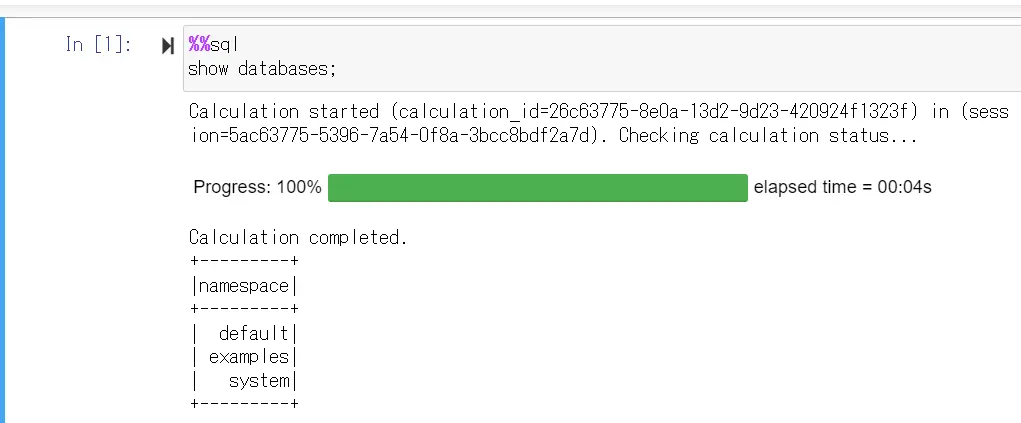
先ほど投入したテーブルを確認すると、csv で投入した値が適切に返ってくることが分かりました。では、その後、1行削除を行います。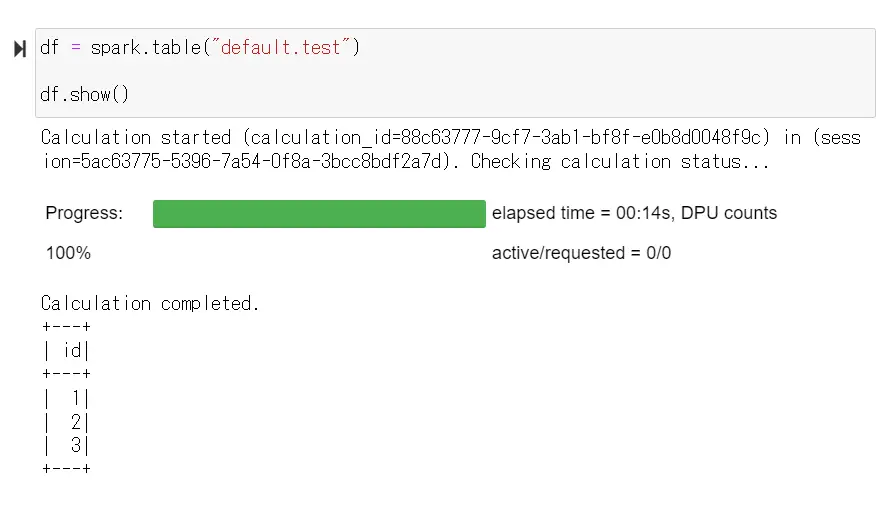
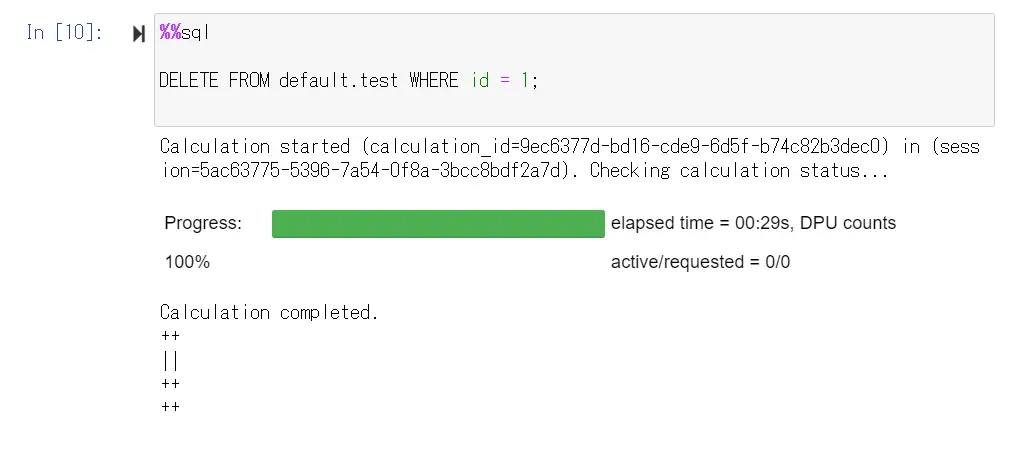 削除後に Tabular の SNAPSHOT を見てみましょう。レコードが視覚的に減少している事が分かります。ここから投入当初にロールバックできるかどうかを確認してみます。
削除後に Tabular の SNAPSHOT を見てみましょう。レコードが視覚的に減少している事が分かります。ここから投入当初にロールバックできるかどうかを確認してみます。
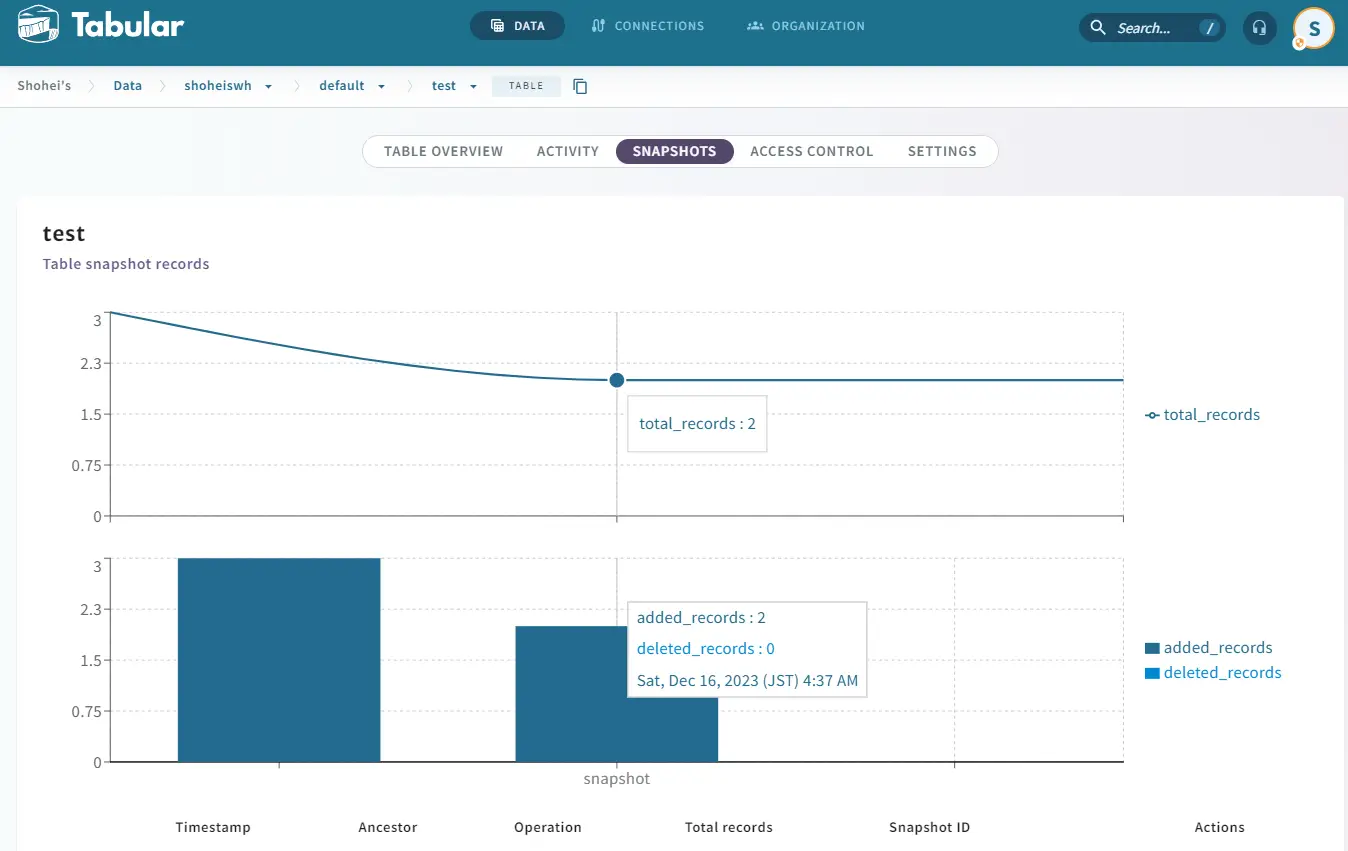
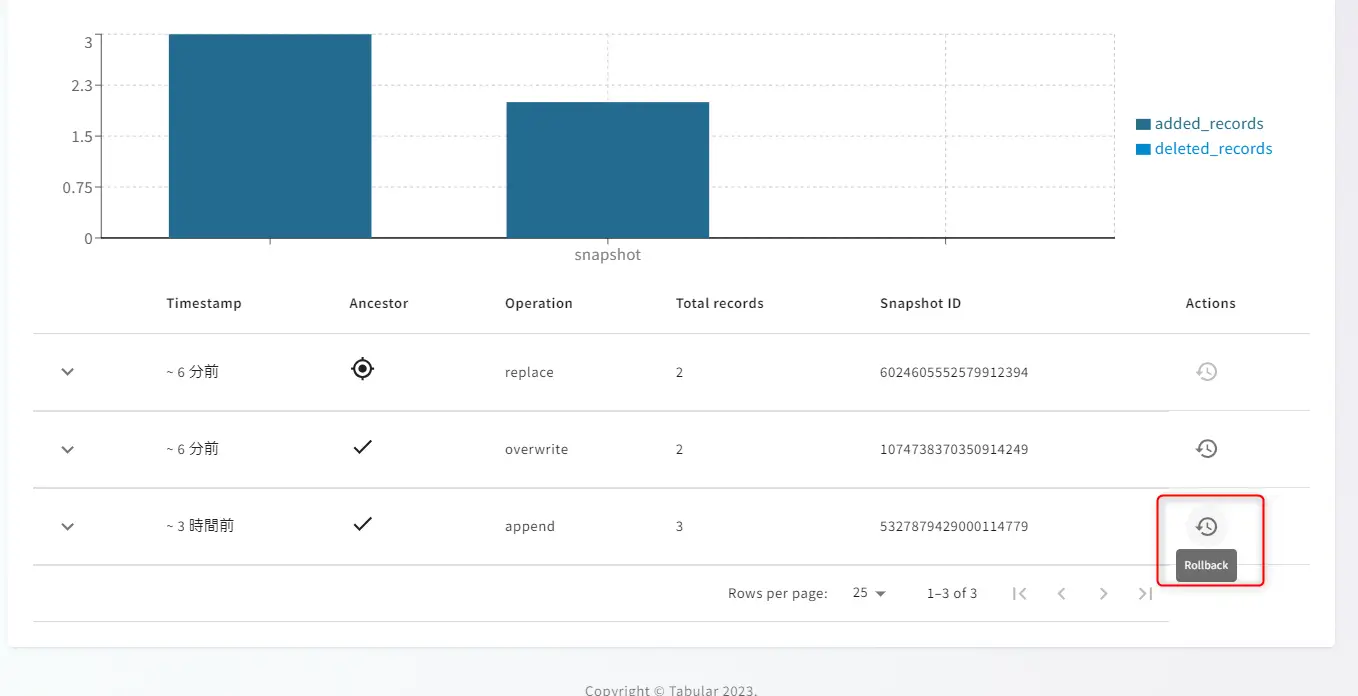
削除されたレコードが戻っている事が確認出来ました。テーブルが視覚化された状態から snapshot の断面を復元できるのは便利だと思いました。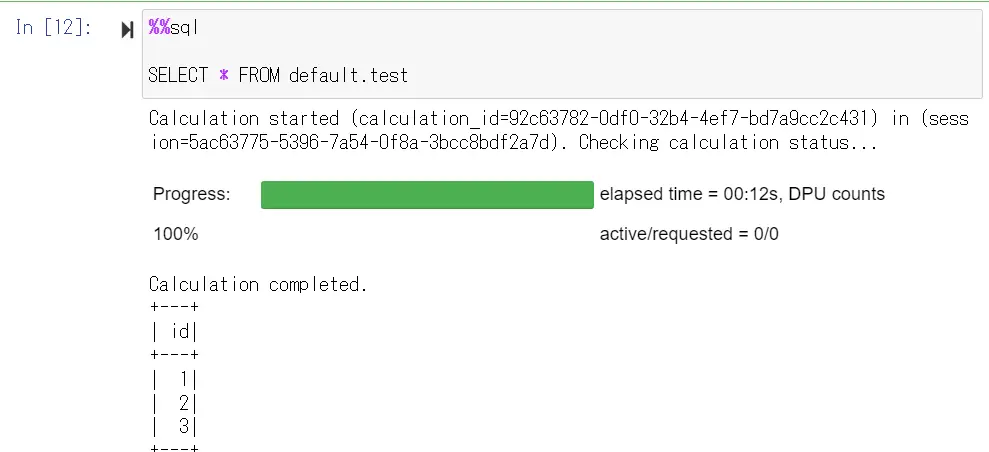
Iceberg については、理解が出来ていない事が多いですが、Table format として多くの活用が見込まれます。ここは引き続き理解を深めたいと思いました。また、Re:invent を通じて新しい製品に巡り合えた事も非常に嬉しく思います。
以上となります。
最後まで閲覧頂きありがとうございました。
- カテゴリー
- タグ

この記事をシェアする

![[re:Invent 2023 レポート] Platform engineering with Amazon EKS](/media/QNVy79WE7NMY0dHNto1OhQTZHvqMMJFdtfHzTkFo.png)
![[re:Invent 2023 レポート] Expert 400 Session - Break down data silos using realtime synchronization with Flink CDC (Problem and Architecture)](/media/cEgRjcxTrlxSmwt9w64QDztKEal3sVblaQuB54QD.png)



