目次
大友(@yomon8)です。
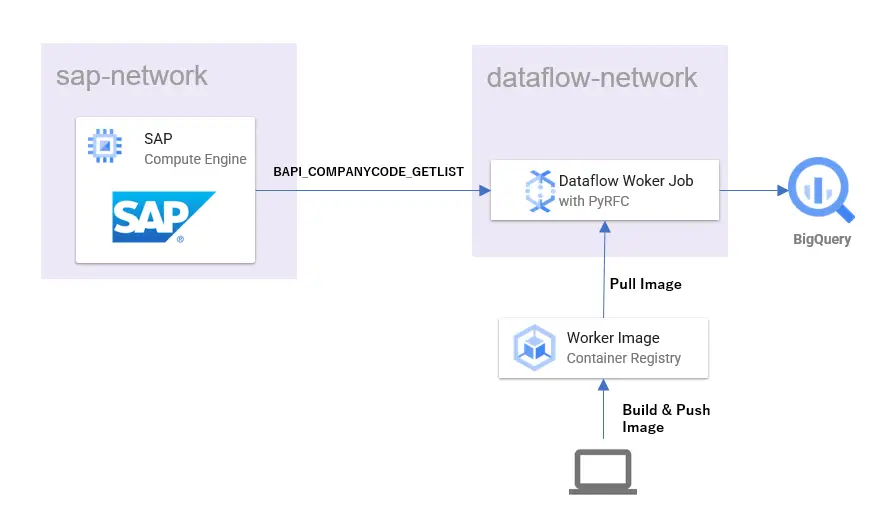
先日こちらのブログでGCPのマネージドのデータ処理サービスであるDataflowを利用して、SAP ERPのデータをBigQueryにロードする記事を書かせていただきました。

できるだけシンプルに抑えようと頑張ったのですが、それでもある程度コードを書いて行く必要があったり、Java自体が経験無い人には敷居が高いのではと思うところもあります。
今回はもう少し手軽に、SAP ERPのデータを少しだけ(手元のPCで扱えるくらい)を移行してBigQueryで見てみたい場合などに使える方法を書いていきたいと思います。
データのロード方法
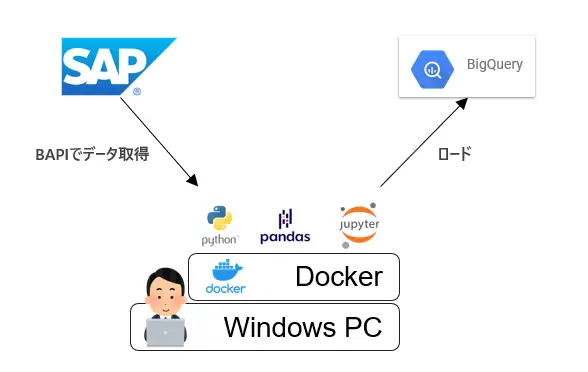
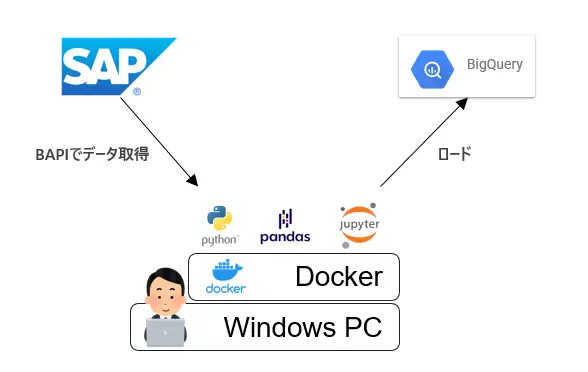
Windows PC上のDockerでPythonを動かし、SAPのデータをBigQueryにロードします。必要なものは検証可能なSAP ERPとBigQuery、そしてDockerインストール済みのWindows PCとなります。作業はWSL上で進めていきます。
準備
サンプルコードの取得
GitHubよりこの記事のサンプルコードをCloneして、ディレクトリに移動します。
git clone git@github.com:beex-inc/sap-pandas-bq-sample.git
cd sap-pandas-bq-sample/
SAP NW RFC SDK の取得
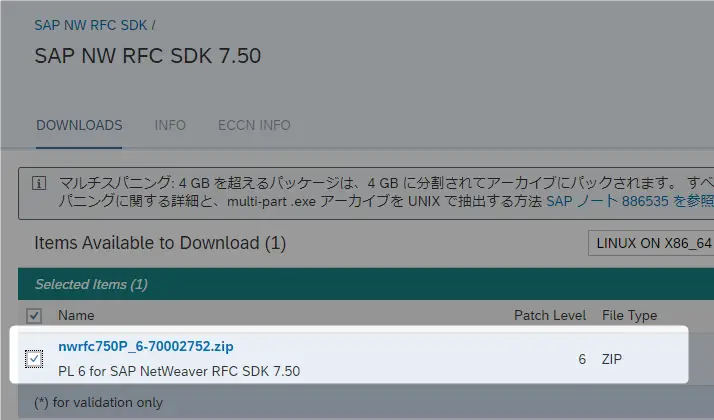
以下のノートのリンクより、SAP NW RFC SDK 7.50をダウンロードします。
2573790 – Installation, Support and Availability of the SAP NetWeaver RFC Library 7.50
以下のようなZIPがダウンロードできます。
注)この記事を書いている時点ではパッチレベル6ですが、このレベルが上がることで記事の一部の処理などが動かなくなる可能性もあります。
sap-pandas-bq-sampleディレクトリの配下でZIPを解凍します。
unzip nwrfc750P_6-70002752.zip
この時点でのディレクトリ配下の状態です。
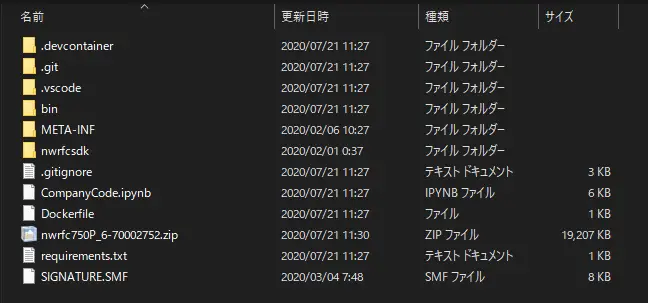
META-INFとSIGNATURE.SMF、nwrfc750P_6-70002752.zipは不要なので消してしまっても問題ありません。
イメージのBuild
Dockerのイメージをビルドします。以下のスクリプトを実行します。
$ ./bin/build.sh
ビルド処理は数分ほどで完了します。完了すると以下のようなメッセージとなります。
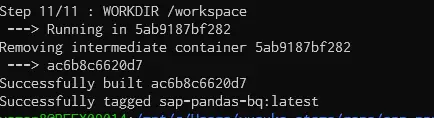
実行
実行は以下のスクリプトを実行します。
$ ./bin/run.sh
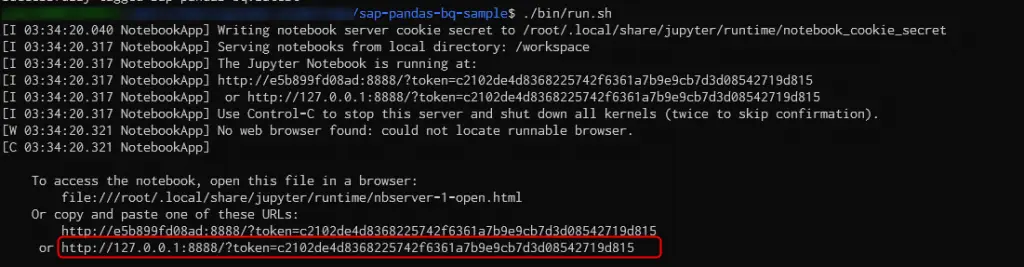
以下のような画面になるので、ブラウザから赤枠のURLにアクセスします。
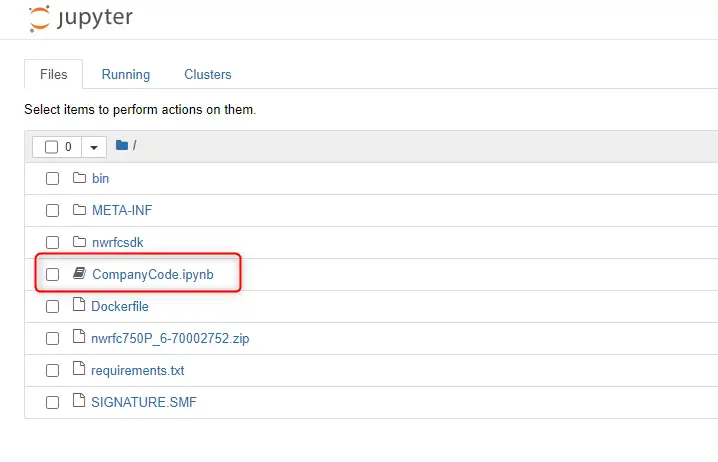
以下のようなJupyter Notebookの画面が開くので、CompanyCode.ipynbを開きます。
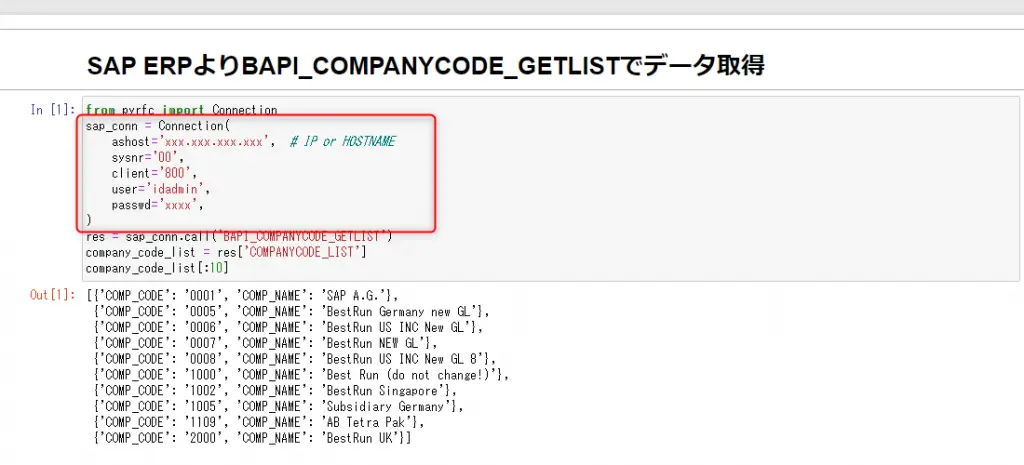
SAP ERPよりBAPI_COMPANYCODE_GETLISTでデータ取得
SAP ERPのログオンデータを自身の環境のものに修正して実行すると、会社コードのデータがsap_connの変数に格納され、BAPIが実行されます。
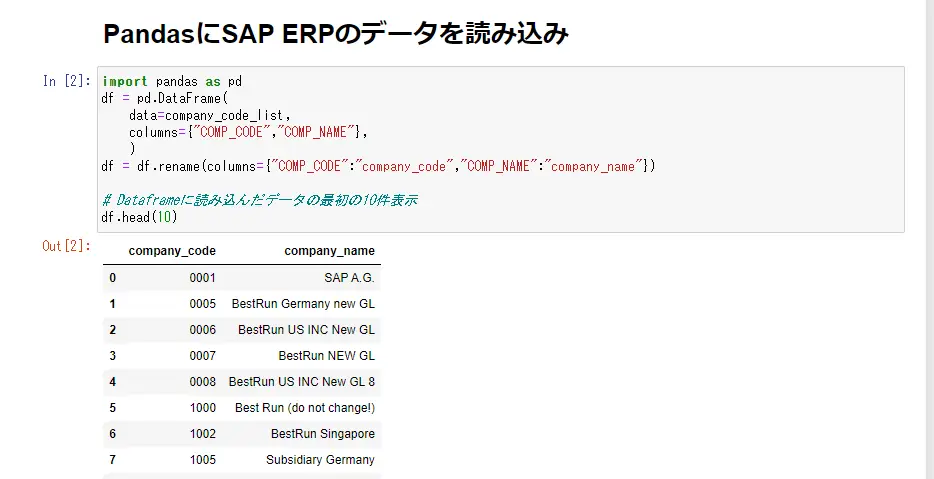
PandasにSAP ERPのデータを読み込み
BAPIから取得したデータをPandasのDataframe形式に変換します。
ここではカラム名をリネームしていますが、Pandasは様々なデータ加工ができるフレームワークなので、調べて触ってみると面白いです。
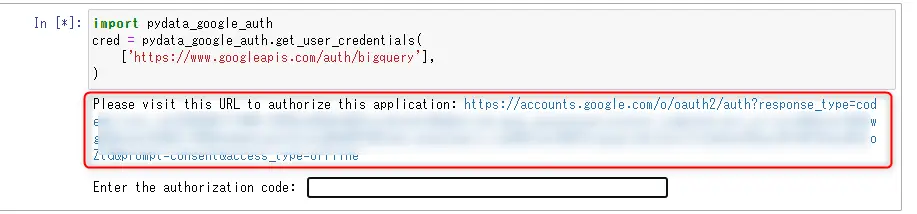
GCPへの認証
BigQuery接続のために、GCPに認証を行います。
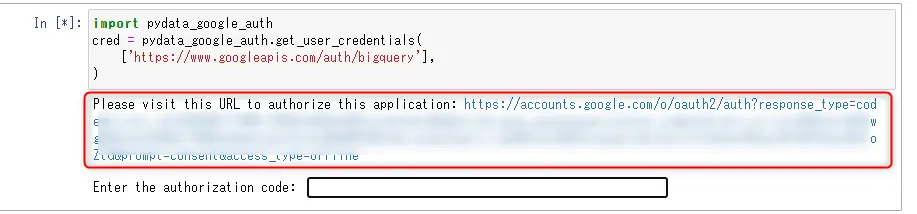
以下のブロックを実行すると、認証用のURLが発行されるのでそこにアクセスします。
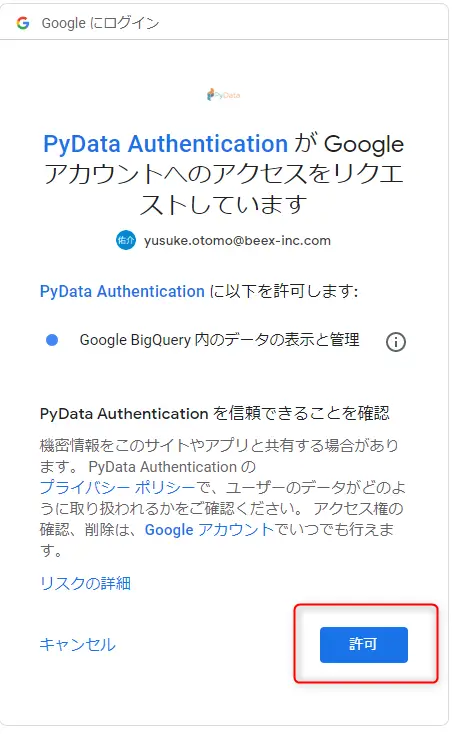
Googleアカウントで認証すると、以下のようにBigQueryへのアクセス許可を求められるので許可します。
コードが発行されるので、そのコードをJupyter Notebookの以下の赤枠に入れて実行します。これで認証情報がcred変数に格納されます。
BigQueryにロード
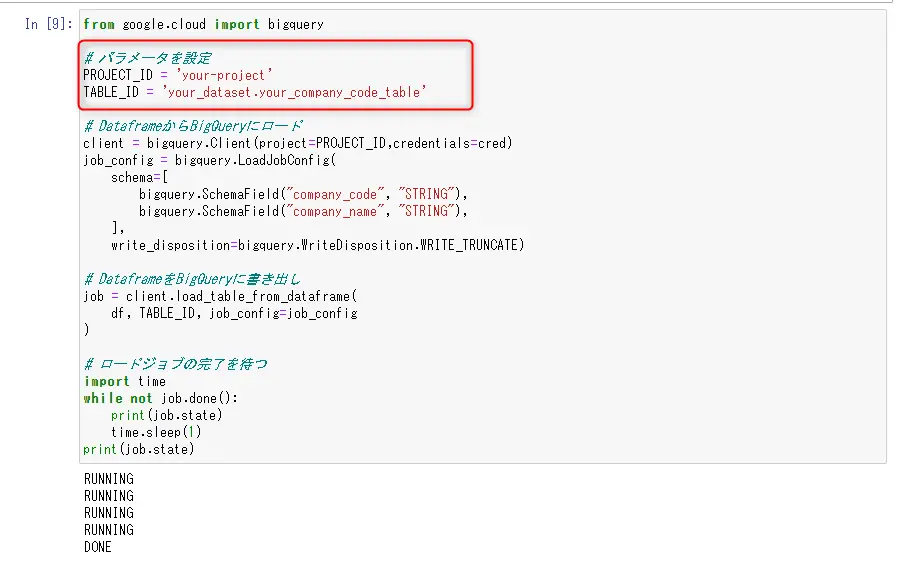
Pandasは広く使われていることもあり、BigQueryのSDKを利用して直接BigQueryにデータをロードできるAPIも提供されていますので、そちらを利用します。内部的には一旦Parquet形式に変換されロードされているようです。
PROJECT_IDとTABLE_IDだけ自身の環境の値に変更して実行します。
実行するとBigQueryへのロードジョブが開始されます。ジョブのステタースは1秒毎に取得表示します。完了するとDONEと表示されます。
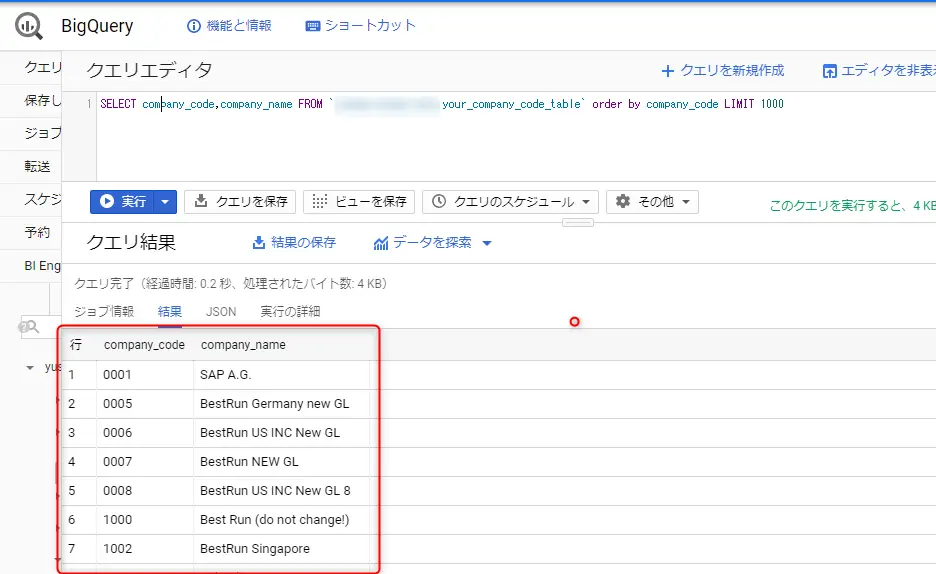
BigQueryにデータがロードされました。
CleanUp
以下のコマンドでこの手順で作成したイメージファイルを削除可能です。
docker rmi -f sap-pandas-bq
さいごに
簡易な方法でSAP ERPのデータをBigQueryにロードする方法をご紹介しました。
データをPandasまで持ってきてしまえばBigQuery以外にも色々なデータソースに持っていけるようになるので、簡単ながら汎用性の高い方法でもあります。
記事の中で使っているソースコードはこちらに公開していますので、ご覧ください。
https://github.com/beex-inc/sap-pandas-bq-sample
- カテゴリー

この記事をシェアする
![[re:Invent 2022 レポート] Eli Lilly 社は SAP 移行と運用をどのようにしているのか](/media/fFfbMpbGNg2nfc7OLvAH31FZjKX4cTDjYAoevX3v.jpeg)