目次
こんにちは、半田(@handy)です。
オンプレ上のSQL ServerにあるデータをAWSにアップロードして分析をしたい場合、使用するツールによって様々な構成が考えられます。
今回はOSSのEmbulkとDigdagを使用して、可能な限りコストを削減しつつオンプレ上のSQL Serverへの負荷を抑えながら、定期的にAWS上にアップロードするための構成についてご紹介します。
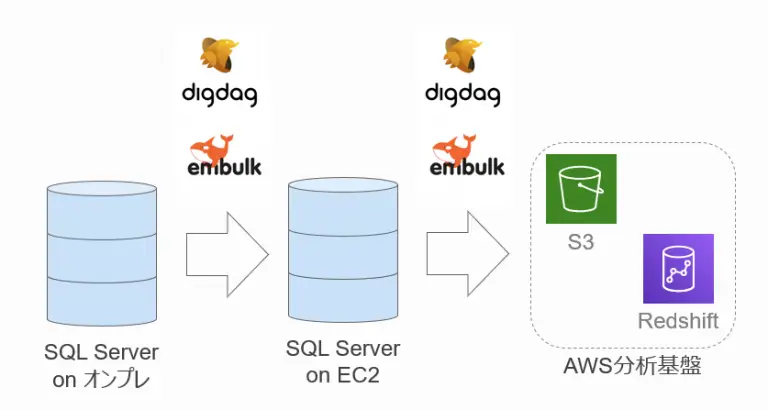
構成図
以下が簡易的な全体構成図になります。
オンプレとAWSの間にEC2上に構築されたSQL Serverを挟んでいますが、これは次の制約を解決するためにこのような構成になっています。
制約
構成を考えるにあたって、お客様の要件とオンプレのシステム側の要件によりいくつか制約がありました。主なものとしては以下の5つになります。
この中でも、特にオンプレサーバのCPUやメモリなどのリソースへの影響は避けたいという要望が強くありました。
そのため中間にレプリケーション用のSQL Serverを入れることによって、リアルタイムデータはレプリケーションしたSQL Serverにクエリできるようにし、オンプレ上のSQL Serverに対して直接クエリしないようにしています。
お客様要件による制約
- コストは可能な限り削減
- オンプレサーバへのリソース影響は避けたい
- リアルタイム、またはニアリアルタイムでデータを確認したい
オンプレシステム要件による制約
- オンプレ上SQL Serverは複数バージョンが混在
- テーブル構成が異なる連携対象DBが複数ある
オンプレ・EC2間データ連携
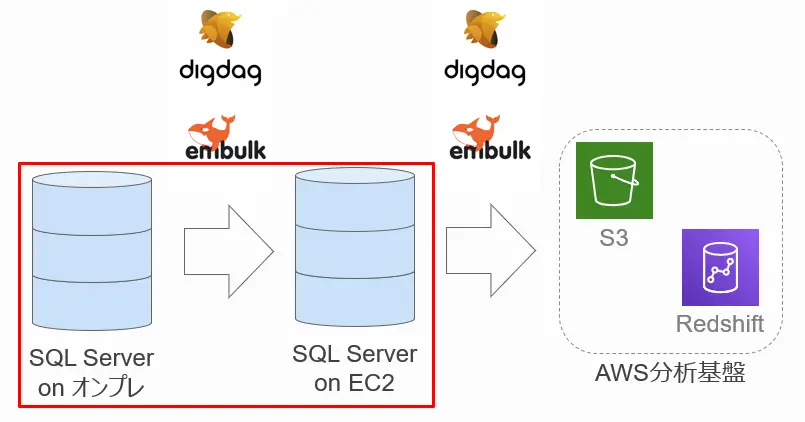
当初オンプレのSQL ServerとEC2のSQL Serverとのデータ連携は、SQL Server機能のログシッピングを使用して行う構成で考えていました。しかし、オンプレへの負荷増大やSQL ServerのEditionの問題で、ログシッピングやトランザクションレプリケーション等のSQL Server機能だけでのデータ連携が難しいことがわかりました。
そのため、OSSのEmbulk・DigdagとSQL Serverのトランザクションレプリケーションを併用し、極力オンプレへの負荷を抑えてデータ連携ができるように設計しました。
EmbulkやDigdagの詳細な説明については本記事の最後に記載しますが、大量データをまとめて転送するためのツールがEmbulkで、そのEmbulkの実行を制御するためのツールがDigdagです。
Embulk・Digdagはプラグインアーキテクチャを採用しており、プラグインをインストールすることで複数のデータソースからのデータ取得・加工・出力が可能になります。今回はSQL Serverのインプットとアウトプットを行うプラグインを使用しています。
データ連携方法
オンプレ上のSQL Serverのデータには
- データに対して都度変更が入る更新系テーブル
- データの追加が頻繁に発生する追加系テーブル
の2種類あり、その種類によって
- データに対して都度変更が入る更新系テーブル → トランザクションレプリケーション
- データの追加が頻繁に発生する追加系テーブル → Embulk・Digdag
という風にデータの連携方法を分割しました。
そうすることによって、Embulkの設定(ymlファイル)をシンプルにすることができ、またEmbulkコマンドはPowerShell等のバッチでラップし、Digdagの実装に汎用性を持たせられるようにしています。
データ連携スケジュール
データの連携(Embulkの実行)はDigdagで制御されますが、その設定としては数秒~数時間等柔軟に設定することが可能です。(Scheduling workflow)
今回は数分ごとに実行されるように実装していますが、どのぐらいの時間で設定するかはEC2のスペックによるため、実際に動作確認して頻度を決定したほうが良いです。
EC2・AWS間データ連携
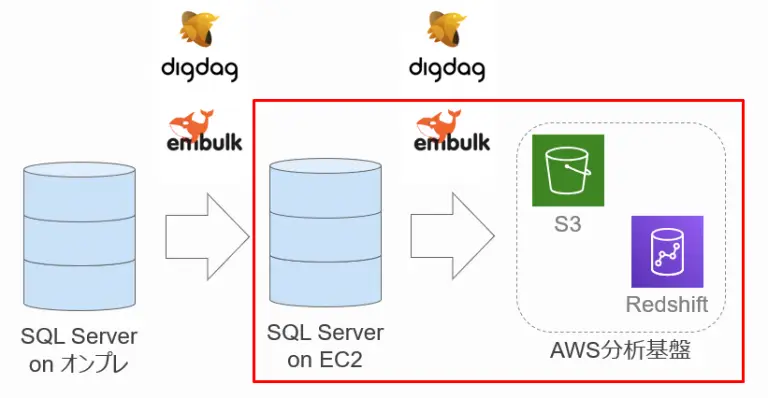
データ連携方法
EC2上のSQL ServerからAWSへのデータ連携もEmbulkとDigdagを使用して行っています。
その際のEC2・AWS間のデータ連携にはEmbulkのプラグイン(embulk-output-s3_parquet)を使用しました。
このプラグインはデータをParquet形式に変換してファイルとしてS3にアップロードしてくれるという便利なプラグインです。
データ連携スケジュール
AWSへのアップロードはリアルタイム性を求められていないため、Digdagから日次でアップロードされるように実装しました。
ハマったポイント
今回の構成を構築する上でハマったポイントは3つあります。
Parquetファイルのサイズには注意
前述したEmbulkプラグインでAWSにアップロードする場合、Parquetファイルの分割数がCPUのコア数に依存するため、一度に大量のデータをアップロードした場合はファイルサイズが膨らみ、Redshiftからのクエリが失敗する可能性があります。
ただ、Parquet変換と同時にファイル圧縮もされるため、一度に数百億レコードなどでなければほぼ問題ないと思います。
一部Embulkが対応していないデータ型がある
バイナリ型等、Embulkプラグインで一部対応していないデータ型があるので、その点は注意が必要です。
EmbulkではSelect文を実行しているので、設定次第では取得できるのかもしれませんが、基本的には分析に必要な最低限のテーブル・カラムに絞ってデータを連携したほうが良いです。
オンプレ側DBへのデータ投入順の意識が必要
EmbulkはオンプレからSelect文でデータを取得し、アウトプット先にINSERTしていますが、その際対象テーブルの実行順を意識していないとデータのFKキー制約でデータ追加が失敗することがあります。
今回はEC2上のSQL ServerにFKキー制約は不要だったため、FKキー制約自体を削除することで対応しました。
意識した点
制約条件やOSSを使用した構成など考えなければいけない点は多かったですが、特に意識した点としてはEmbulkの定義ファイルの自動化です。
というのも、Embulkはymlファイルを記述するだけでデータ連携が簡単にできますが、今回のようにRDBに対して使用する場合はテーブルごとに定義ファイルを作成する必要があります。
これが1つのDBの連携なら良いですが、2つ3つと増えていくとその分運用負荷が高くなってしまい、カラムの追加などが一度に発生してしまうと対応の漏れが発生する可能性があります。
そうならないために、必要なパラメータを1つのファイルに集約し、そのファイルを元にEmbulkの定義ファイルを配布するように自動化も構築に併せて行いました。
使用したOSS
最後に今回使用したOSSについて少し紹介します。
Embulk

Embulkはシャチがトレードマークのバルク転送ツールです。
Treasure Data社の古橋さんという方がメインで開発され、2015年にリリースされています。類似ツールとしてFluentdがあります。
特徴としては、並列分散処理等の大量データの一括ロードが可能な仕組みが導入されており、また必要な機能のプラグインをインストールすることでCSVやMySQL・SQLServer等の複数のデータソースの形式に対応しています。
Digdag

Digdagはモグラがトレードマークのワークフローツールです。
Treasure Data社によって2016年にOSS化されました。類似ツールとしてAirbnb(エアビーアンドビー)が開発したAirflowなどがあります。
特徴としては、ワークフローファイルに実行したいタスクを定義し、コマンドやGUIで実行することで簡単に処理が開始できます。そのため複雑なプログラミング知識等がなくても処理の実装が容易です。
またローカルにDigdagサーバを起動することで、ワークフローの管理やタスクの実行状況の確認、実行ログの可視化等をすることが可能です。
おわりに
今回はOSSのEmbulkとDigdagを使用して、オンプレ上のSQL ServerからEC2上のSQL Server、AWSへのアップロードを行う際の構成とハマったポイント等についてご紹介させていただきました。
既存のデータベースから必要なデータのみ抽出してAWSなどのクラウドに連携する際の一つの構成案としてご参考いただければ幸いです。
- カテゴリー

この記事をシェアする