目次
データドリブンへ向けて
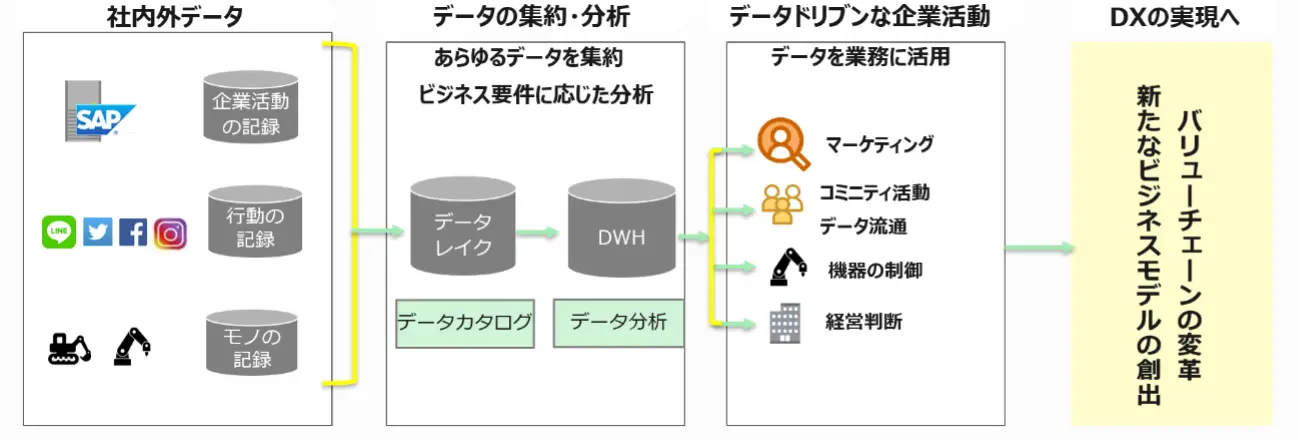
DXを進めるにあたって最も重要なテーマのひとつが、データドリブン(データ駆動)の実現です。
データドリブン(データ駆動)とは、マーケティングの世界ではしばしば使われていた言葉ですが、データに基づき次のアクションを起こしていくことを指します。換言すれば、ひとつのデータで終了するのではなく、得られた結果から更にデータを分析していくことです。
代表的な取り組みとしては、製造業における生産設備からのセンサーデータの活用による、より精度の高い生産状況の把握や予防保守を講じることや、Web利用データを解析することでユーザーの興味・関心など先に洗い出し、効果的なシナリオを策定した上で、最適なマーケティング活動を行うといった例が挙げられます。
また、企業経営におけるデータドリブンとは、経験と勘に頼った経営判断を下すのではなく、売上情報等の従来からある業務システムからのレポート以外のデータ、IoTデータ、機械学習や人工知能により得られた分析結果も合わせて活用することで、より正確に現在の経営状況を捉えた上で判断を下すことを意味します。つまり「主観にとらわれない、データに基づく意思決定」の実現と言えます。
この実現には、より広範囲なデータ(Bigdata)の蓄積/可視化を行う新たなデータプラットフォームが不可欠です。
企業には基幹システム上に格納された定型業務データだけでなく、周辺業務システムやファイルサーバに多種多様なデータが存在しますが、これらのデータを集約し、直接関係がある組織内の人だけでなく、組織外の人にも活用できるようにすることが「DX Ready」な状態には必要です。
また、IoTやAIといったテクノロジーを活用することで従来のアナログ情報をデジタル化し、保存・活用が可能な状態にすること、システム間・組織間で分断されていた情報を統合すること、更には企業内だけではなく外部に存在する第3者のデータも取り込み、活用できる仕組みを整えることが重要です。
その際には構造・非構造データを可視化できる状態で保存し、必要な人がデータをそこから抜き出し活用できる「Data Lake」の仕組みの整備を検討いただくことをお勧めいたします。
図1 データドリブンによるDXの実現
クラウドを利用したデータプラットフォーム
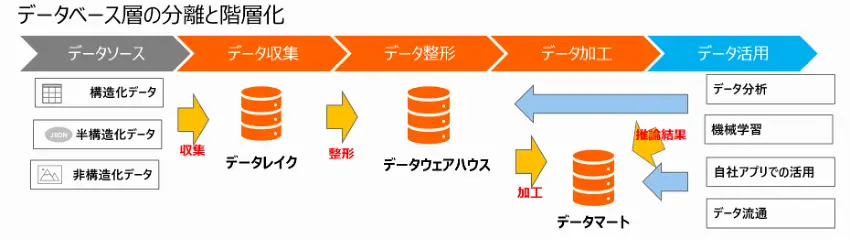
データドリブンの実現には、従来の構造化データだけではなく、半構造や非構造などのデータを扱う必要がり、これら多様で変化が激しいデータを分析するには新たなデータプラットフォームが求められます。
これを実現化する基盤として、クラウドを利用したデータベース層をデータレイクとデータウェアハウスへ分離と階層化した新たなデータプラットフォームの構築をBeeXは推奨しています。
図2 データプラットフォーム
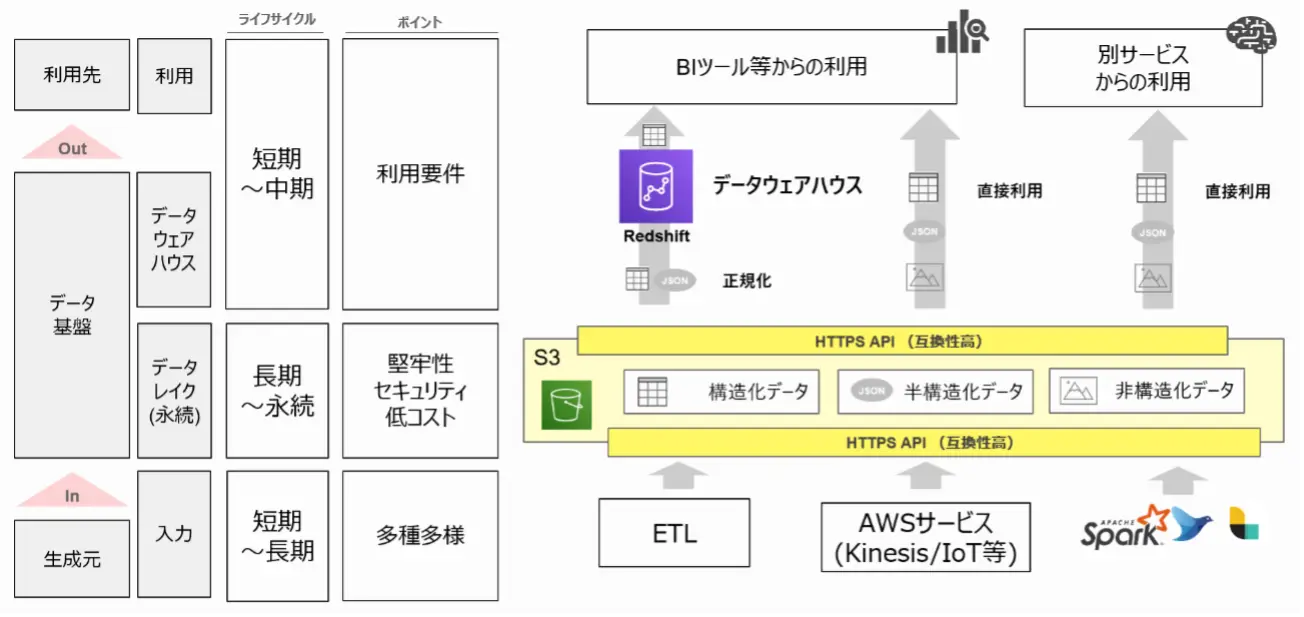
データレイクとデータウェアハウスの分離/階層化のメリットは以下が挙げられます。
1.様々なデータの集約と影響範囲の分離
ビジネスの状況に応じてデータは求められる形式や着眼点が変化していくため、データソースの数やデータフォーマットなどが変化します。これらに対応するためにデータベースの層を分離し、データレイクを配置することで変化に強い基盤とします。例えば、データ提供先のデータ要件が変更になった場合も、加工のプロセスを変更することで、データウェアハウスには変更を加えずに対応することができます。
2.リソースの分離
それぞれのデータベースやプロセスの実行環境を分離することで、パフォーマンスを最大化することができます。すべてを同じデータベースで管理した場合、データウェアハウスへの書き込み処理によってデータマートの速度が低下する可能性などがあります。データベースを分離・階層化することで、相互のパフォーマンス影響を防ぎます。
図3 AWSを利用したデータプラットフォーム像
SAPデータ連携
前述のデータドリブン経営の実現には、基幹業務システムに蓄積されるデータの活用が欠かせません。
基幹業務システムには、企業活動の過去と現在に行われた業務プロセスとその結果、そして将来の計画が記録されています。これは企業の状態・事実を示す重要な生データであるとともに、このデータを単なる記録の集合体・記録の蓄積に留めず、業績の把握、意思決定、戦略策定に利用できる「分析可能なデータ」として、抽出・集計・可視化することが必要です。
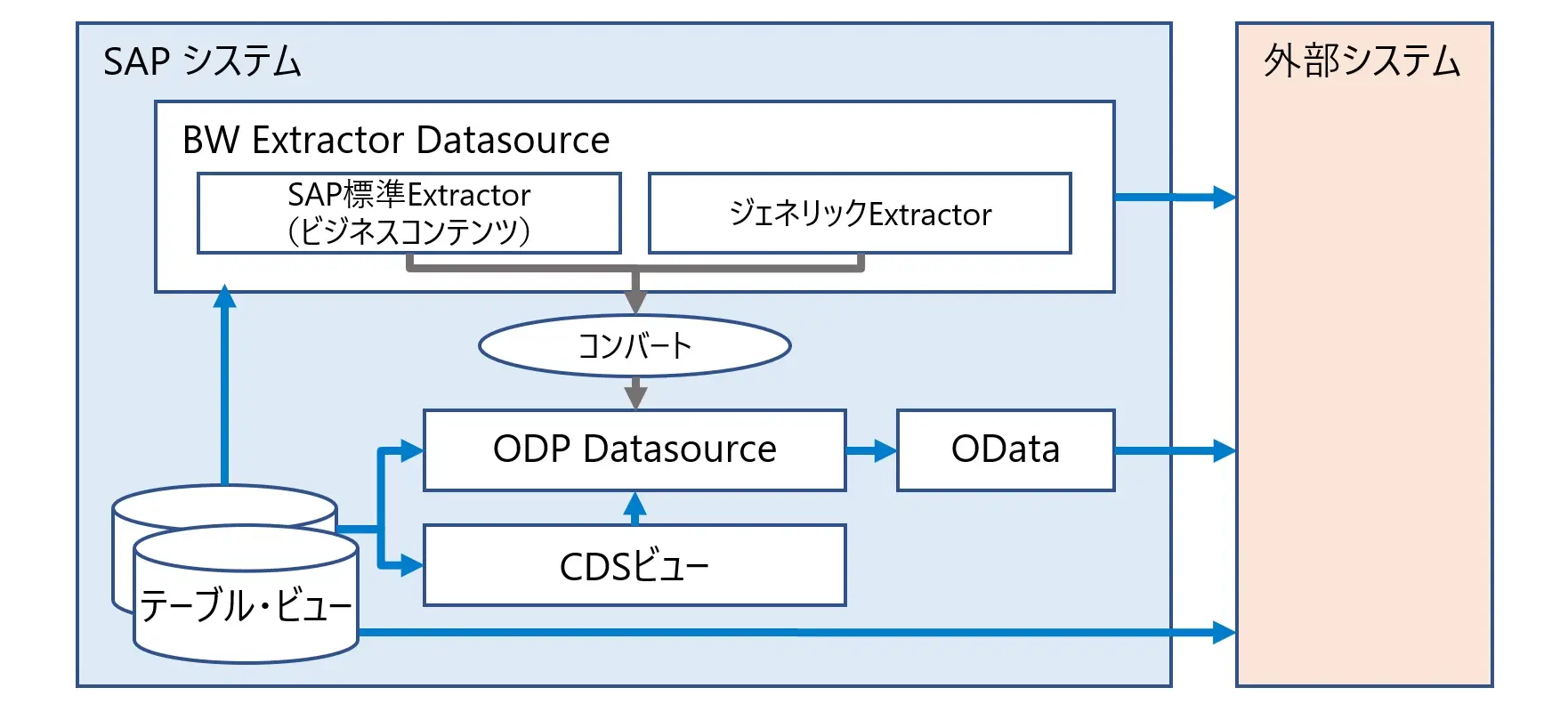
基幹業務システムの代表であるSAP ERP・S/4HANAは、そのカバーする業務領域の広さと業務間の連動性や、処理性能、拡張性を担う高度な設計と機能実装により、業務データは、データベース上の数多くのテーブルに分散保持されており、また、独自の項目名、テーブル間の関連性を持っています。
この為、SAPシステムのデータ抽出・活用には、分析要件・抽出要件に該当するデータの所在(どのテーブルのどの項目に格納されているか)を特定することが必要となり、一定のSAP ERP・S/4HANAのシステム的、技術的な知識が求められます。
これには、従来よりSAP BWとのデータ連携用に用意されているExtractor、ビジネスコンテンツの利用が効果的であり、データ抽出・分析要件を業務的な視点から、システム的・技術的な視点、具体的な実装に変換することが可能となります。
(標準で用意されているビジネスコンテンツ(データソース)に対し、企業固有のデータ要件に準じた項目追加・拡張を行うこともでき、また独自のデータソースを実装することも可能です)
データ連携にExtractor、ビジネスコンテンツを用いた実装が行えない場合でも、この仕様・技術文書を参照することで、抽出元の情報が得られるため、データ所在の特定に役立ちます。
データの所在を特定したのちは、具体的な実装方式の検討となりますが、これには、フィルタ値の指定や差分抽出といったデータ抽出条件が指定できるのか、そして抽出処理の状態・結果の確認が可能な管理機能を有しているか、なども考慮する必要があります。
この点の対応としては、SAP社提供ソリューションの利用の他、SAPシステムがもつ機能を利用した個別開発や、クラウドベンダーやソリューションベンダーが提供するツールの利用が想定できます。
図4 SAPデータ連携
1.SAPソリューション(SAP Data Services)の利用
SAP Data Servicesは、データ抽出、データ編集、データ投入の機能を備えたETLツールです。SAPシステムの他、各種RDB、業務アプリケーションパッケージからのデータ抽出に対応しています。また、各種ファイルフォーマット、非構造化データといった幅広いデータフォーマットに対応している製品です。SAP社が提供する製品でありますので、当然、ERP等のSAPシステムとの親和性が高く、また、データ抽出元となるSAPシステムおよび、ETLツールであるData Services自体のソフトウェアバージョンアップやパッチレベルの変化や不具合発生時に、メーカーサポート・調査がデータ抽出元システムとETL両面で得られることが挙げられます。
2.個別開発
特定のテーブルやビューで、抽出・分析要件が満たせる場合、データダウンロードプログラムや、データ読み込みを行うRFC対応汎用モジュールの利用、開発が想定できます。RFC連携の実装サンプル、基礎検証としては、当社ブログを参照ください。
- SAP ERPのデータをBigQueryにロードする(Dataflow利用)
- SAP ERPのデータをBigQueryに簡易ETLする(Pandas利用)
- Dataflowのカスタムコンテナ+FlexTemplate使ってSAPからPyRFCでデータを抜き出してみる
また、上記ブログでは触れておりませんが、SAPシステムが持つODataインターフェース経由でAWS Lambdaを用いたデータ抽出の検証や、ODPデータソースからのデータ抽出プログラムの実装検証も行っています。
3.サードパーティーツールの利用
BWとの連携に使用されるExtractorや、ODataを用いたSAPデータ連携ソリューションの利用がこちらの方式です。
今回はQlik、AWS、Google社より提供されているソリューションをご紹介いたします。
■Qlik Replicate
SAP ERPとBW間の連携に従来から利用されてきたExtractorの差分データ抽出に対応し、SAP標準のビジネスコンテンツを活用したSAPデータの外部連携を行うことができます。これにより、開発効率性・保守性を高めながら、Google BigQuery、Microsoft Synapse、Amazon RedshiftにSAPデータをリアルタイム転送することができます。
■Amazon Appflow
SAP S/4HANA、SAP ERPシステムなどからAmazon S3へデータ抽出を行い、AWSのネイティブサービスやサードパーティのソリューションを活用しデータレイクを構築することができます。セキュリティとプライバシーを担保するために、Amazon Appflow SAP OData Connectorは AWS Private Linkをサポートしており、パブリックエンドポイントとの通信はインターネットを経由せず AWSネットワーク内から出ることなくご利用頂く事が可能です。
2022年8月12日にはAmazon AppFlow SAP OData ConnectorがSAP ODP Changed-Data Captureに対応しました。これにより、SAP Operational Data Provisioning(ODP)フレームワークが提供するChanged-Data Capture(CDC)機能を使って、SAP S/4HANAをはじめとするSAP ERP/BWアプリケーションから SAP Operational Delta Queue(ODQ)を含む完全および差分データ転送をシームレスに実行することが可能になります。
- Amazon AppFlowを用いてSAP ERPとBWからデータ抽出
- Amazon AppFlow SAP OData Connector が SAP ODP Changed-Data Capture に対応
■Google Cloud Data Fusion
Google Cloudで提供されるサーバーレス、フルマネージドなデータ統合サービスであり、様々なデータソースに対応し、各データの組み合わせ・統合を行うことが可能です。SAPデータソース用には専用プラグインが提供されています。SAPの抽出元は、透過テーブル、ビュー、CDSビュー、HANAビューに対応した「SAP テーブル バッチソース プラグイン」の他、SAP ODataプラグイン、SAP ODPプラグインも用意されています。
BeeXは、SAP Analytics Cloud、SAP BW・BW/4HANA、Business Objects BI Platform、Data ServicesといったSAPアナリティクスソリューションの導入を行っており、お客様のデータ活用・付加価値創造をご支援させて頂いております。
また、SAPデータのみならず、「DX Ready」のサービスカテゴリとして、データ分析基盤構築サービスを行っております。
下記のサービス紹介ページのご参照ならびに、データウェアハウス、データレイクの導入や、刷新をご検討される際には、是非ご相談、お声がけ頂けますと幸いです。
- カテゴリー

この記事をシェアする