











目次
こんにちは。大友(@yomon8)です。
はじめに
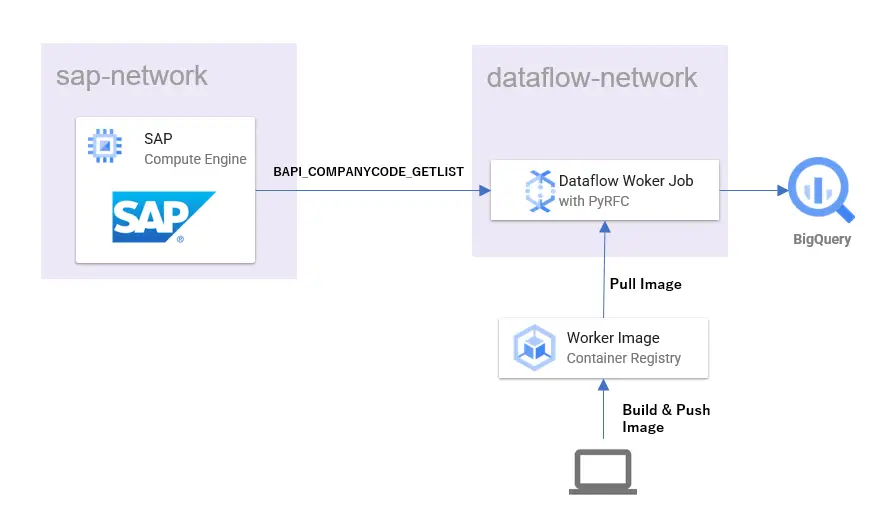
タイトルの通り、DataflowでERPのデータをBigQueryにロードする方法です。
かれこれ、この類いの記事は3作目になります。
というのも普段BigQuery使っていて、その凄さ便利さを感じていることからも色々なデータを持って来られるようになりたいという思い、そして私の中ではSAPへ上手く繋ぐことができるなら、どんなものにも繋げられるという感覚があり、SAP接続というのが個人的なベンチマークのようになっていたりします。新しい方法見つけるとSAPで試してみると言う流れとなり、類似の記事も3作目となりました。
似たような記事を以下でも書いています。ただ、この時にはDataflow+Java構成でSAP JCoを利用してSAPに接続を行っていました。
https://www.beex-inc.com/blog/saperp-load-bigquery
最近の流れではPythonは外せないと思いながらも当時のDataflowでは中々難しかったと思います。なので苦し紛れにこんな記事を書いてたりもしました。
https://www.beex-inc.com/blog/sap-erp-pandas-bigquery
今回記事を書こうと思ったのは、Dataflow Runner v2から利用できるようになったカスタムコンテナを利用すれば、今までのような外部ライブラリ等の依存関係をコンテナに閉じ込められるので、Pythonでもシンプルに実装できるのではと考えたからです。
やりたいこと
今まではWorkerにて外部のライブラリを利用するには、GCSなどを経由したファイルのやりとりが必要でした。
Workerの起動処理やセットアップ処理内でGCSに配置したファイルをダウンロードして読み込んだりという方法になるのですが、デプロイから処理が完了するまで軽いジョブでも1回の試行に10分程度かかるので試行錯誤をするとすぐに時間を溶かしてしまう大変な処理でした。
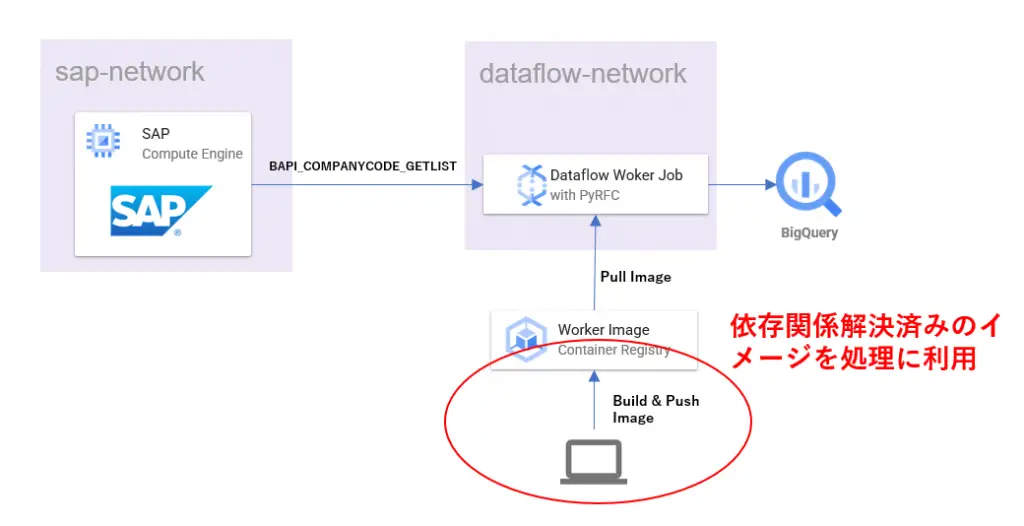
ローカルで全イメージをビルド確認済みのコンテナイメージをGCR(Google Container Registry)を通してカスタムイメージとして利用できることは、開発効率上大きなプラスになります。
準備
上記の記事で書いてあることの繰り返しは極力省いて書いていきます。
作業環境
最低限以下が必要です。
・検証用のGoogle Cloud プロジェクト(CloudShellより作業)
・CALが使えるSユーザ
リポジトリ
今回利用するコードは以下に公開しております。
https://github.com/beex-inc/sap-dataflow-python-sample
インフラ構築
インフラ構築はTerraformとSAP CALで終わらせてしまいます。
ネットワーク構築(Terraform)
CloudShellから以下を実行します。
git clone https://github.com/beex-inc/sap-dataflow-python-sample.gitcd sap-dataflow-python-sample/make setup-infra以下のように表示されるので、自身のプロジェクト名を入力します。
var.gcp_project: <input-your-project-name>以下のように表示されるので、問題無ければYesを入力します。
Enter a value: yesこれでネットワーク環境が展開されます。

SAP構築(CAL)
CAL(SAP Cloud Appliance Library)を利用します。Google CloudでのCALの利用は以下の記事に記載しているので詳細はこちらを参照してください。
https://www.beex-inc.com/blog/sap-cal-gcp/
今回はこちらを利用します。

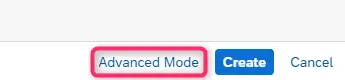
作成の際に画面右下の「Advanced Mode」を選択するとネットワークを選択できるようになります。
ネットワークの設定等はこちらの記事と同じなので、詳細な手順を確認したい場合は参照してみてください。
Dataflowジョブのビルド&デプロイ
次はDataflowのデプロイを行っていきます。
GCSバケット作成
デプロイ用のGCSバケットを作成しておきます。名前は任意で問題ありません。ここでは「otomo-deploy」として作成します。
CloudShellから以下のコマンドで作成します。
gsutil mb gs://otomo-deploySAP NWRFC SDKのダウンロード&展開
以下のSAPノート(Sユーザが必要)にダウンロードリンクの記載があります。
https://launchpad.support.sap.com/#/notes/2573790
ダウンロードしたファイルをCloudShellにアップロードして解凍します。
# zipファイルをリポジトリトップに解凍する
$ unzip /uploadpath/nwrfc750P_8-70002752.zip -d .
# nwrfcsdkというディレクトリが作成されている
$ ls -1
Dockerfile
Dockerfile.worker
main.py
Makefile
nwrfcsdk
setup.py
SIGNATURE.SMF
spec
terraformWorkerイメージのビルド&デプロイ
今回はMakefileにコマンド類を纏めています。
以下のようにPROJECTを引数に make build-worker-imageを実行することでWorkerのイメージが作成され、GCRにPushされます。Push先は「gcr.io/<your-project-name>/sap-companycode-load-sample-job-worker」というURLとなります。
$ make build-worker-image PROJECT=<your-project-name>ここが一番重要なポイントです。ビルドに使われているのは Dockerfile.workerというファイルです。
SAP NWRFC SDKをコピーしてきて、読み込みに必要な環境変数を設定しているのがわかると思います。この辺りが以前は辛かったところになります。
今回使っているのはPyRFCというライブラリですが、先程ダウンロードしてきたSAP NWRFC SDKを利用しています。SAP NWRFC SDKのファイルは読み込むだけでも環境変数が必要だったりとバリデーションがかかるのが大変なところです。
例えばPyRFCの場合はLD_LIBRARY_PATHにあるライブラリを後から読み込むのに、トリッキーなテクニックを何個も使わないといけなかったりします。そういった不安定なテクニックも、ワーカーにカスタムイメージが使えるようになったので今後は不要です。
FROM python:3.7-slim
RUN apt update && apt install -y build-essential
# Install Beam SDK
RUN pip install --no-cache-dir --upgrade pip setuptools wheel
RUN pip install --no-cache-dir apache-beam[gcp]==2.31.0
# Copy files from official SDK image, including script/dependencies
COPY --from=apache/beam_python3.7_sdk:2.31.0 /opt/apache/beam /opt/apache/beam
# for nwrfcsdk
RUN mkdir -p /opt/sap
COPY nwrfcsdk/ "/opt/sap/nwrfcsdk"
ENV SAPNWRFC_HOME="/opt/sap/nwrfcsdk"
ENV LD_LIBRARY_PATH="/opt/sap/nwrfcsdk/lib"
RUN pip install cython
RUN pip install pyrfc==2.4.2
# Set the entrypoint to Apache Beam SDK launcher.
ENTRYPOINT ["/opt/apache/beam/boot"]ポイント
環境変数「SAPNWRFC_HOME」はpyrfcのインストール時に必要です。
環境変数「LD_LIBRARY_PATH」はPythonコード内からpyrfcを利用するのに必要です。
FlexTemplateイメージのビルド&デプロイ
次はFlexTemplateと言って、パラメータ等を柔軟に設定できる新しいテンプレート機能をビルド&デプロイします。こちらもMakefileに纏めているのでコマンドは以下の通りシンプルです。こちらもビルドされたイメージは「gcr.io/<your-project-name>/sap-companycode-load-sample-job-flextemplate」というURLにPushされます。
$ make build-flextemplate-image PROJECT=<your-project-name>FlexTemplateはジョブのLauncherとして機能します。Googleより提供されているベースイメージを元にしてイメージを作成していきます。マニュアルではこの辺りに記載があります。
FROM gcr.io/dataflow-templates-base/python3-template-launcher-base
ARG WORKDIR=/dataflow/template
ARG BEAM_VERSION=2.31.0
RUN mkdir -p ${WORKDIR}
WORKDIR ${WORKDIR}
COPY main.py ${WORKDIR}/main.py
COPY setup.py ${WORKDIR}/setup.py
COPY spec/python_command_spec.json ${WORKDIR}/python_command_spec.json
ENV FLEX_TEMPLATE_PYTHON_PY_FILE="${WORKDIR}/main.py"
ENV FLEX_TEMPLATE_PYTHON_SETUP_FILE="${WORKDIR}/setup.py"
ENV DATAFLOW_PYTHON_COMMAND_SPEC="${WORKDIR}/python_command_spec.json"
RUN pip install --no-cache-dir --upgrade pip setuptools wheel
RUN pip install --no-cache-dir apache-beam[gcp]==${BEAM_VERSION}「main.py」ファイルもコピーされているのがわかると思いますが、これがジョブのソースコード本体です。「BAPI_COMPANYCODE_GETLIST」の情報をBigQueryにロードするものですが、本記事の本題ではないので、ざっくり作っています。参考までに。
import logging
from contextlib import contextmanager
import apache_beam as beam
from apache_beam.options.pipeline_options import (
PipelineOptions,
SetupOptions,
StandardOptions,
GoogleCloudOptions,
WorkerOptions,
)
class SapLoadJobOptions(PipelineOptions):
@classmethod
def _add_argparse_args(cls, parser) -> None:
parser.add_argument("--job-project", default=None, help="Job Project")
parser.add_argument("--job-name", default=None, help="Job Nmae")
parser.add_argument("--base-bucket", default=None, help="GCP Base Bucket")
parser.add_argument("--sap-ashost", default=None, help="SAP AS host name or IP")
parser.add_argument("--sap-user", default=None, help="SAP user")
parser.add_argument("--sap-passwd", default=None, help="SAP password")
parser.add_argument("--sap-sysnr", default=None, help="SAP System Number")
parser.add_argument("--sap-client", default=None, help="SAP Client Number")
parser.add_argument("--sap-lang", default=None, help="SAP Lang")
parser.add_argument("--bq-dataset", default=None, help="Dest BigQuery Dataset")
parser.add_argument("--bq-table", default=None, help="Dest BigQuery Table")
class SapCompanyCodeDoFn(beam.DoFn):
def __init__(self, user, passwd, ashost, sysnr, client, lang):
self.user = user
self.passwd = passwd
self.ashost = ashost
self.client = client
self.sysnr = sysnr
self.lang = lang
@contextmanager
def _open_connection(self):
from pyrfc import Connection
conn = Connection(
user=self.user,
passwd=self.passwd,
ashost=self.ashost,
sysnr=self.sysnr,
client=self.client,
lang=self.lang,
)
try:
yield conn
finally:
if conn != None:
conn.close()
def process(self, element):
with self._open_connection() as conn:
res = conn.call("BAPI_COMPANYCODE_GETLIST")
for r in res["COMPANYCODE_LIST"]:
yield r
def main():
options = SapLoadJobOptions()
options.view_as(
WorkerOptions
).sdk_container_image = f"gcr.io/{options.job_project}/{options.job_name}-worker"
gcp_options = options.view_as(GoogleCloudOptions)
gcp_options.staging_location = f"gs://{options.base_bucket}/dataflow/staging"
gcp_options.temp_location = f"gs://{options.base_bucket}/dataflow/temp"
setup_options = options.view_as(SetupOptions)
setup_options.save_main_session = True
options.view_as(StandardOptions).runner = "DataflowRunner"
with beam.Pipeline(options=options) as p:
logging.warn(options)
(
p
| "dummy" >> beam.Create([None])
| "Read SAP CompanyCode via BAPI"
>> beam.ParDo(
SapCompanyCodeDoFn(
user=options.sap_user,
passwd=options.sap_passwd,
ashost=options.sap_ashost,
sysnr=options.sap_sysnr,
client=options.sap_client,
lang=options.sap_lang,
)
)
# | "logging" >> beam.Map(lambda x: logging.warn(x))
| "Write to BQ"
>> beam.io.WriteToBigQuery(
project=options.job_project,
dataset=options.bq_dataset,
table=options.bq_table,
schema={
"fields": [
{"name": "COMP_CODE", "type": "STRING"},
{"name": "COMP_NAME", "type": "STRING"},
]
},
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE,
)
)
res = p.run()
res.wait_until_finish()
if __name__ == "__main__":
logging.getLogger().setLevel(logging.INFO)
main()ポイント
Workerのイメージは「WorkerOption.sdk_container_image」を利用して指定します。(参照URL)
options.view_as(WorkerOptions).sdk_container_image = f"gcr.io/{options.job_project}/{options.job_name}-worker"パスワードを引数で渡してしまっていますが、本来ならSecret Manager等を利用してください。
parser.add_argument("--sap-passwd", default=None, help="SAP password")FlexTemplateの定義のアップロード
WorkerとLauncherTempalteのイメージがビルドできたので、最後にFlexTemplateの定義情報をアップロードします。引数には先程作成したGCSバケットを指定します。
make build PROJECT=<your-project-name> GCS_BUCKET_NAME=otomo-deployここでアップロードされる主な情報の一つが「spec/template_metadata.json」に記載された以下の情報です。この記載がDataflow APIからのジョブを起動する際に指定可能なパラメータとなります。
{
"description": "CompanyCode Data transfer from SAP by SAPRFC.",
"name": "SAP CompanyCode Loader",
"parameters": [
{
"name": "base-bucket",
"label": "GCS Base Bucket Name",
"helpText": "GCS Base Bucket Name",
"regexes": [
".*"
]
},
{
"name": "job-name",
"label": "Job Name",
"helpText": "Job Name",
"regexes": [
".*"
]
},
{
"name": "job-project",
"label": "Job Project",
"helpText": "Job Project",
"regexes": [
".*"
]
},
{
"name": "sap-ashost",
"label": "SAP AS Host",
"helpText": "SAP AS Host",
"regexes": [
".*"
]
},
{
"name": "sap-user",
"label": "SAP User",
"helpText": "SAP User",
"regexes": [
"[A-z0-9_-]+"
]
},
----------省略-----------------ポイント
「main.py」の「SapLoadJobOptions」クラスと整合性を取った設定にしています。
Dataflowジョブの実行
SAPの事前準備
CALで立ち上げたSAPインスタンスに以下の確認だけしておきます。
startsapで起動
IPアドレス確認
idadminのパスワード確認(マニュアルに記載されてます)
Dataflowジョブ起動
今度もMakefileに準備してあるので、最低限の引数で起動できるようにしてあります。
make start-job PROJECT=<your-project-name> GCS_BUCKET_NAME=otomo-deploy SAP_ASHOST=<sap ip> SAP_PASSWD=<idadmin password>実行してみると以下のようなコマンドが実行されているのがわかります。「–parameters」で指定されているのがFlexTemplateの定義で指定したパラメータであることが確認できます。
gcloud dataflow flex-template run "sap-companycode-load-sample-job-`date +%Y%m%d-%H%M%S`" \
--project=<your-project-name> \
--region=asia-northeast1 \
--subnetwork=regions/asia-northeast1/subnetworks/sapbq-dataflow-subnetwork \
--template-file-gcs-location="gs://otomo-deploy/dataflow/template/sap-companycode-load-sample-job.json" \
--staging-location="gs://otomo-deploy/dataflow/staging" \
--additional-experiments=use_runner_v2 \
--disable-public-ips \
--parameters base-bucket="otomo-deploy" \
--parameters job-project=<your-project-name> \
--parameters job-name=sap-companycode-load-sample-job \
--parameters sap-ashost=<sap ip address> \
--parameters sap-user=idadmin \
--parameters sap-passwd=<idadmin password> \
--parameters sap-sysnr=00 \
--parameters sap-lang=EN \
--parameters sap-client=800 \
--parameters bq-dataset=sap_sample_dataset \
--parameters bq-table=company_code ポイント
カスタムテンプレートが利用可能なのはDataflow Runner v2からです。
--additional-experiments=use_runner_v2Dataflowの画面からジョブが実行されていることが確認できます。
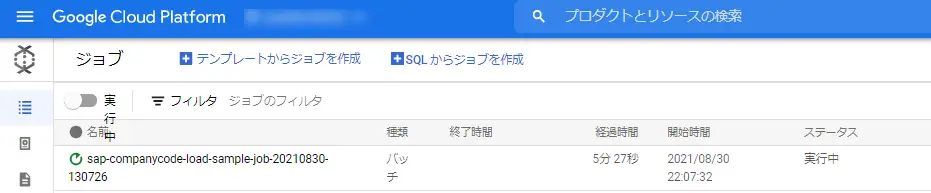
成功しました。
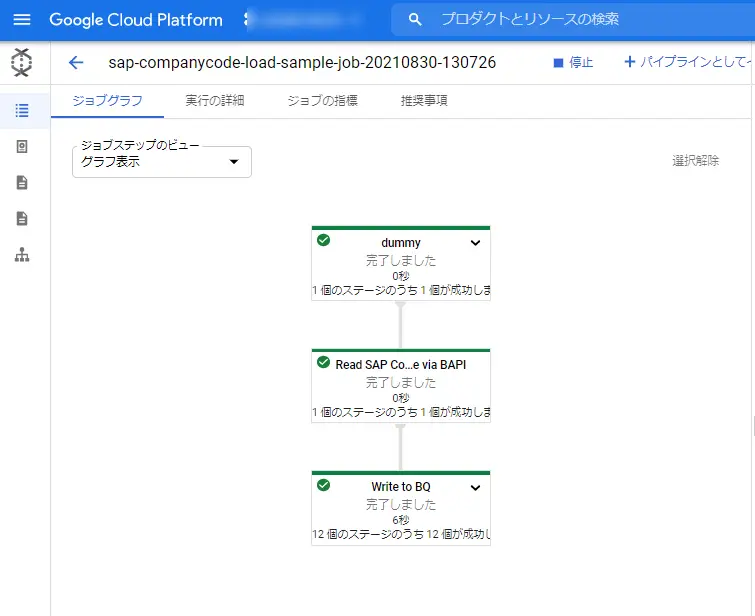
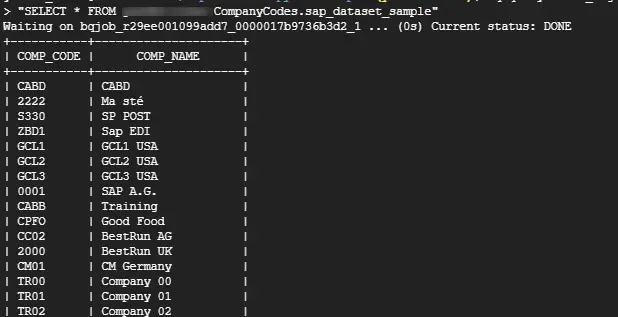
BigQueryデータ確認
BigQuery側のデータを確認してみます。
bq query --use_legacy_sql=false \
"SELECT * FROM your-project-name.CompanyCodes.sap_dataset_sample"データが確認できました。
掃除
CALの画面からSAPインスタンスを削除後、以下のコマンドでネットワークも削除できます。
make destroy-infra最後に
自分の理解力の無さなのか、Dataflowの新機能触ると毎回理解するまでに時間かかります。ただ、一度理解してしまえば便利なのもDataflowです。カスタムコンテナが使いこなせるようになると、(マネージドで便利な部分は残しながらも)ブラックボックス部分が減るので柔軟な処理が可能になると思いました。
特にGoogle Cloudのサービス以外との接続には、この仕組みが必要になることもあると思います。そんな時にこの記事の内容が誰かの役に立てばよいなと思っています。
- カテゴリー

この記事をシェアする

![[re:Invent 2023 レポート] Platform engineering with Amazon EKS](/media/QNVy79WE7NMY0dHNto1OhQTZHvqMMJFdtfHzTkFo.png)
![[re:Invent 2023 レポート] Expert 400 Session - Break down data silos using realtime synchronization with Flink CDC (Problem and Architecture)](/media/cEgRjcxTrlxSmwt9w64QDztKEal3sVblaQuB54QD.png)



